Suponha que tenhamos um registro de documentos com os quais os operadores ou contadores trabalham no VLSI , como este: Tradicionalmente, tal exibição usa tanto a classificação direta (nova a partir de baixo) quanto reversa (nova a partir do topo) por data e identificador ordinal atribuído quando o documento é criado - ou ... Já discuti os problemas típicos que surgem neste caso no artigo Antipadrões do PostgreSQL: Navegando no Registro . Mas e se o usuário por algum motivo quiser ser "atípico" - por exemplo, classificar um campo "assim" e outro "daquele jeito" -

ORDER BY dt, idORDER BY dt DESC, id DESC
ORDER BY dt, id DESC? Mas não queremos criar o segundo índice, pois retarda a inserção e o volume extra no banco de dados.
É possível resolver esse problema de forma eficaz usando apenas o índice
(dt, id)?
Vamos primeiro esboçar como nosso índice é ordenado:
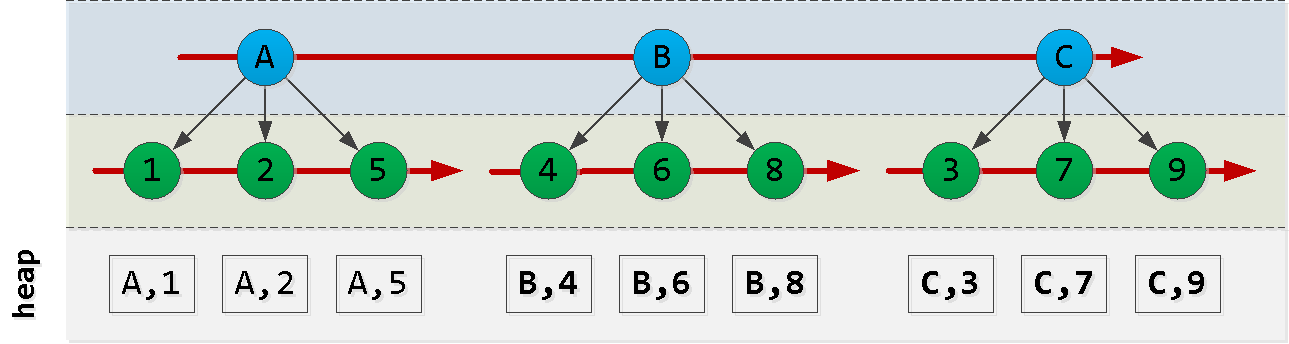
Observe que a ordem em que as entradas de id são criadas não necessariamente corresponde à ordem de dt, portanto, não podemos confiar nela e teremos que inventar algo.
Agora, suponha que estamos no ponto (A, 2) e queremos ler as "próximas" 6 entradas na classificação : Aha! Selecionamos alguma "peça" do primeiro nó , outra "peça" do último nó e todos os registros dos nós entre eles ( ). Cada um desses blocos é lido pelo índice com bastante sucesso , apesar da ordem não muito adequada. Vamos tentar construir uma consulta como esta:
ORDER BY dt, id DESC
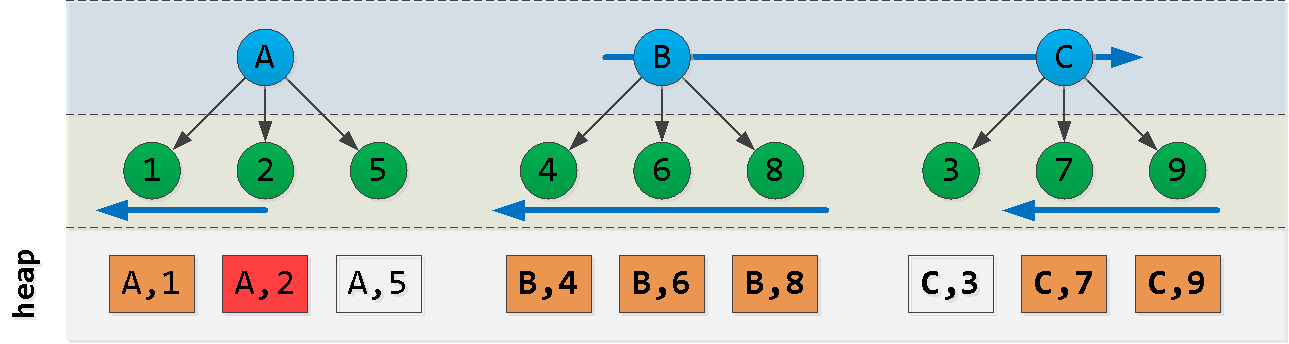
ACB(dt, id)
- primeiro lemos do bloco A "à esquerda" do registro inicial - obtemos os
Nregistros - além disso, lemos
L - N"à direita" do valor A - encontre no último bloco a chave máxima C
- filtre todos os registros da seleção anterior com esta chave e subtraia "à direita"
Agora, vamos tentar descrever no código e verificar o modelo:
CREATE TABLE doc(
id
serial
, dt
date
);
CREATE INDEX ON doc(dt, id); --
-- ""
INSERT INTO doc(dt)
SELECT
now()::date - (random() * 365)::integer
FROM
generate_series(1, 10000);Para não calcular o número de registros já lidos e a diferença entre ele e o número de destino, vamos forçar o PostgreSQL a fazer isso usando um "hack"
UNION ALLe LIMIT:
(
... LIMIT 100
)
UNION ALL
(
... LIMIT 100
)
LIMIT 100Agora vamos coletar os seguintes 100 registros com classificação de destino a partir do último valor conhecido:
(dt, id DESC)
WITH src AS (
SELECT
'{"dt" : "2019-09-07", "id" : 2331}'::json -- ""
)
, pre AS (
(
( -- 100 "" "" A
SELECT
*
FROM
doc
WHERE
dt = ((TABLE src) ->> 'dt')::date AND
id < ((TABLE src) ->> 'id')::integer
ORDER BY
dt DESC, id DESC
LIMIT 100
)
UNION ALL
( -- 100 "" "" A -> B, C
SELECT
*
FROM
doc
WHERE
dt > ((TABLE src) ->> 'dt')::date
ORDER BY
dt, id
LIMIT 100
)
)
LIMIT 100
)
-- C ,
, maxdt AS (
SELECT
max(dt)
FROM
pre
WHERE
dt > ((TABLE src) ->> 'dt')::date
)
( -- "" C
SELECT
*
FROM
pre
WHERE
dt <> (TABLE maxdt)
ORDER BY
dt, id DESC -- , B
LIMIT 100
)
UNION ALL
( -- "" C 100
SELECT
*
FROM
doc
WHERE
dt = (TABLE maxdt)
ORDER BY
dt, id DESC
LIMIT 100
)
LIMIT 100;Vamos ver o que aconteceu em termos de:

[veja explain.tensor.ru]
- Então, usando a primeira chave,
A = '2019-09-07'lemos 3 registros. - Eles terminaram de ler outro 97 por
BeCdevido ao acerto exato emIndex Scan. - Entre todos os registros, 18 foram filtrados pela chave máxima
C. - Lemos 23 registros (em vez de 18 pesquisados
Bitmap Scan) usando a chave de máximo. - Todos reclassificaram e cortaram os 100 registros de destino.
- ... e tudo demorou menos de um milissegundo!
O método certamente não é universal e com índices em um número maior de campos ele se tornará algo realmente terrível, mas se você realmente deseja dar ao usuário uma classificação "não padrão" sem "reduzir" a base em
Seq Scanuma grande tabela, você pode usá-lo com cuidado.