
Estamos de volta ao ar e dando continuidade à série de anotações do cientista de dados e hoje apresento minha lista de verificação totalmente subjetiva para escolher um modelo de aprendizado de máquina.
Estas são as 10 propriedades principais do problema e apenas pontos (sem ordem nelas), do ponto de vista dos quais eu começo escolhendo um modelo e, em geral, modelando uma tarefa de análise de dados.
Não é necessário que você tenha o mesmo - tudo é subjetivo aqui, mas eu compartilho minha experiência de vida.
Qual é o nosso objetivo em geral? Interpretabilidade e precisão - espectro

Fonte
Talvez a pergunta mais importante que um cientista de dados enfrenta antes de iniciar a modelagem seja: o
que exatamente é uma tarefa de negócios?
Ou pesquisa, se estamos falando de academia, etc.
Por exemplo, precisamos de análises com base em um modelo de dados, ou vice-versa, estamos interessados apenas em previsões qualitativas da probabilidade de um e-mail ser spam.
O equilíbrio clássico que vi é o espectro entre a interpretabilidade do método e sua precisão (como no gráfico acima).
Mas, na verdade, você não precisa apenas dirigir Catboost / Xgboost / Random Forest e escolher um modelo, mas entender o que a empresa deseja, quais dados temos e como isso será aplicado.
Na minha prática, isso definirá imediatamente um ponto no espectro de interpretabilidade e precisão (o que quer que isso signifique aqui). E com base nisso, já se pode pensar em métodos de modelagem do problema.
O tipo da própria tarefa
Além disso, depois de entender o que a empresa deseja, precisamos entender a que tipo de problema matemático de aprendizado de máquina o nosso pertence, por exemplo
- Análise exploratória - análise pura dos dados disponíveis e furar um pau
- Clustering - coleta dados em grupos de acordo com alguns atributos comuns
- Regressão - você precisa retornar um resultado inteiro ou há uma probabilidade de um evento
- Classificação - você precisa retornar um rótulo de classe
- Multi-rótulo - você precisa retornar um ou mais rótulos de classe para cada entrada
Dados de exemplo : há duas classes e um conjunto de registros sem rótulo:

E você precisa construir um modelo que marcará esses mesmos dados:

Ou, opcionalmente, não há rótulos e você precisa selecionar os grupos:

Como aqui:
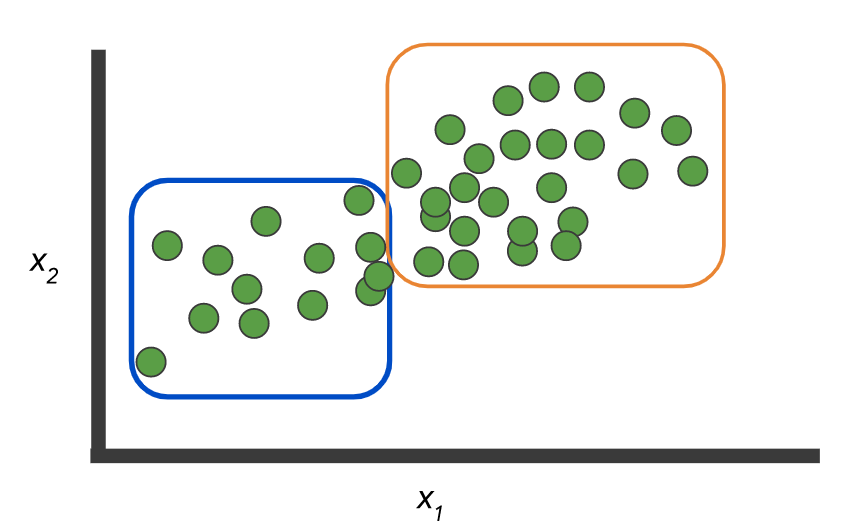
Fotos daqui .
Mas o próprio exemplo ilustra a diferença entre os dois conceitos: classificação, quando N> 2 classes - multi classe vs. multi label
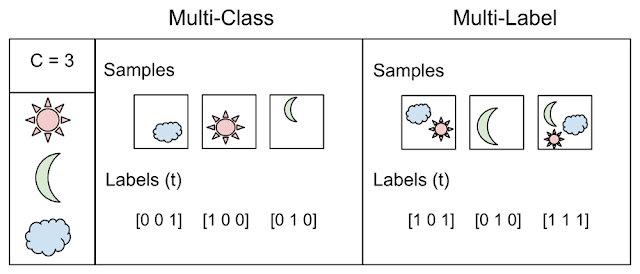
Retirado daqui
Você ficará surpreso, mas muitas vezes vale a pena falar diretamente com a empresa sobre esse ponto - isso pode realmente economizar muito tempo e esforço. Sinta-se à vontade para fazer desenhos e dar exemplos simples (mas não excessivamente simplistas).
Precisão e como é determinada
Vou começar com um exemplo simples: se você for um banco e emitir um empréstimo, perdemos cinco vezes mais com um empréstimo malsucedido do que com um bem-sucedido.
Portanto, a questão de medir a qualidade do trabalho é primordial! Ou imagine que você tem um desequilíbrio significativo nos dados, classe A = 10% e classe B = 90%, então um classificador que simplesmente retorna B é sempre 90% preciso! Provavelmente, não era isso que você queria ver ao treinar o modelo.
Portanto, é fundamental definir uma métrica de pontuação do modelo, incluindo:
- classe de peso - como no exemplo acima, o crédito ruim é 5 e o crédito bom é 1
- matriz de custos - é possível confundir baixo e médio risco - isso não importa, mas baixo risco e alto risco já é um problema
- A métrica deve refletir o equilíbrio? como ROC AUC
- Geralmente contamos probabilidades ou os rótulos de classe são corretos?
- Ou talvez a classe geralmente seja "uma" e tenhamos precisão / recall e outras regras do jogo?
Em geral, a escolha de uma métrica é determinada pela tarefa e sua formulação - e é para aqueles que definem essa tarefa (geralmente empresários) que todos esses detalhes precisam ser esclarecidos e esclarecidos, caso contrário, haverá falhas na saída.
Pós-análise do modelo
Freqüentemente, é necessário conduzir análises com base no próprio modelo. Por exemplo, qual é a contribuição de diferentes recursos para o resultado original: como regra, a maioria dos métodos pode produzir algo semelhante a este:
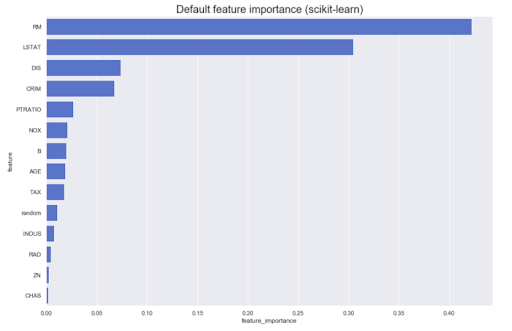
No entanto, e se precisarmos saber a direção - grandes valores do atributo A aumentam o pertencimento à classe Z, ou vice-versa? Vamos chamá-los de importância de recurso direcionado - eles podem ser obtidos a partir de alguns modelos, por exemplo, linear (por meio de coeficientes em dados normalizados)
Para uma série de modelos baseados em árvores e boosting - por exemplo, o método SHapley Additive ExPlanations é adequado.
SHAP
Este é um dos métodos de análise de modelo que permite examinar os bastidores do modelo.
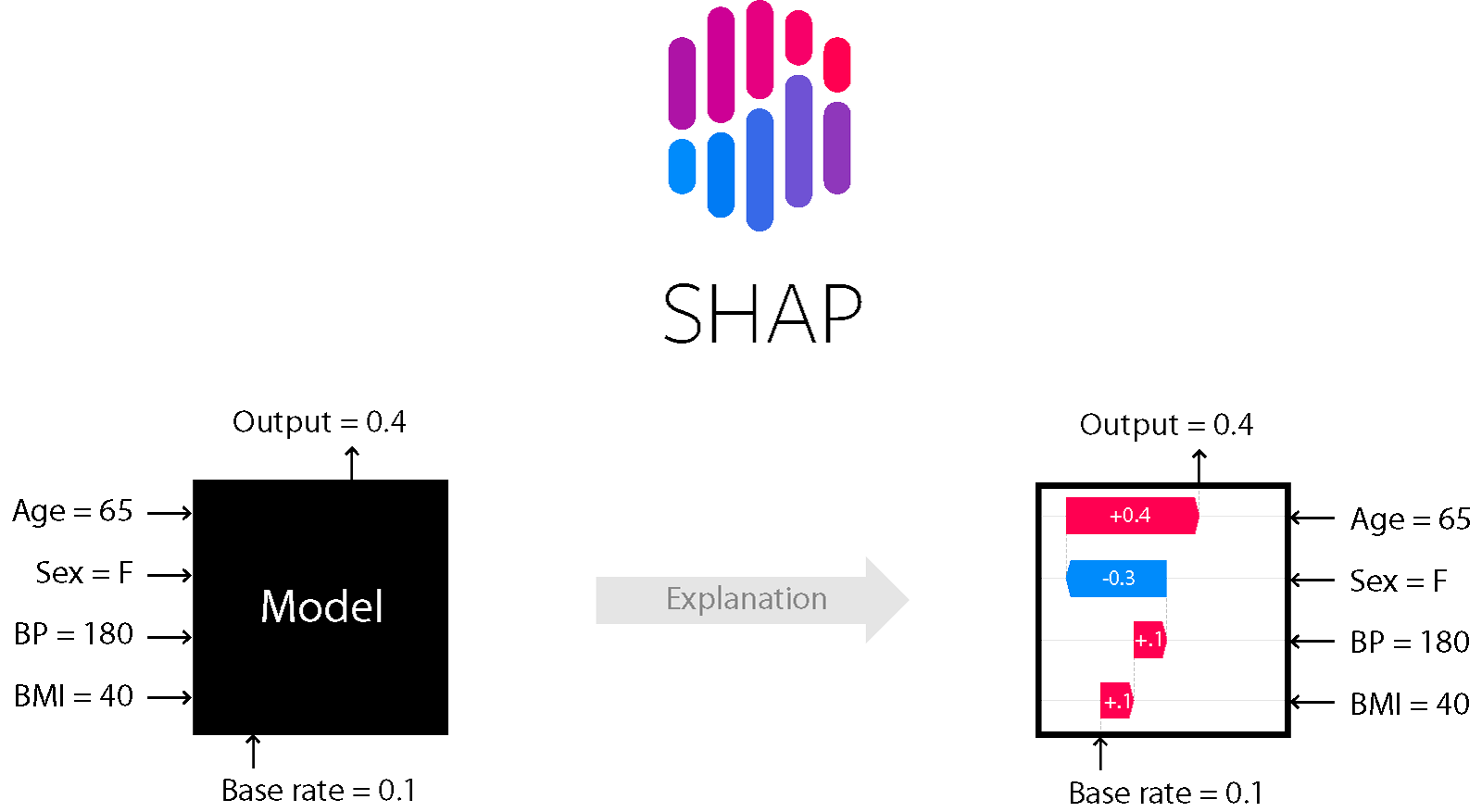
Ele permite que você avalie a direção do efeito:

Além disso, para árvores (e métodos baseados nelas), é preciso. Leia mais sobre isso aqui .
Nível de ruído - estabilidade, dependência linear, detecção de outlier, etc.
A resistência ao ruído e todas essas alegrias da vida é um tópico à parte e você precisa analisar cuidadosamente o nível de ruído, bem como selecionar os métodos apropriados. Se você tiver certeza de que haverá valores discrepantes nos dados, será necessário limpá-los com alta qualidade e aplicar métodos resistentes a ruído (alta polarização, regularização, etc.).
Além disso, os sinais podem ser colineares e os sinais sem sentido podem estar presentes - diferentes modelos reagem de maneiras diferentes a isso. Vamos dar um exemplo no clássico conjunto de dados German Credit Data (UCI) e três modelos de aprendizagem simples (relativamente):
- Classificador de regressão Ridge: regressão clássica com regularizador de Tikhonov
- Árvores de decisão
- CatBoost de Yandex
Regressão de cume
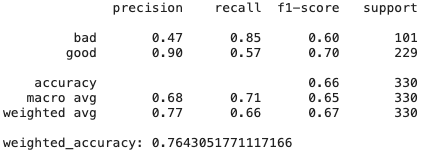
# Create Ridge regression classifier
ridge_clf = RidgeClassifier(class_weight=class_weight, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(pd.get_dummies(X), y, test_size=0.33, random_state=42)
# Train model
ridge_model = ridge_clf.fit(X_train, y_train)
y_pred = ridge_model.predict(X_test)
print(classification_report(y_test,y_pred))
print("weighted_accuracy:",weighted_accuracy(y_test,y_pred))
Árvores de decisão
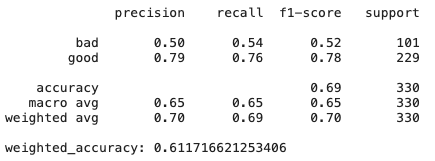
# Create Ridge regression classifier
dt_clf = DecisionTreeClassifier(class_weight=class_weight, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(pd.get_dummies(X), y, test_size=0.33, random_state=42)
# Train model
dt_model = dt_clf.fit(X_train, y_train)
y_pred = dt_model.predict(X_test)
print(classification_report(y_test,y_pred))
print("weighted_accuracy:", weighted_accuracy(y_test,y_pred))
CatBoost

# Create boosting classifier
catboost_clf = CatBoostClassifier(class_weights=class_weight, random_state=42, cat_features = X.select_dtypes(include=['category', object]).columns)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)
# Train model
catboost_model = catboost_clf.fit(X_train, y_train, verbose=False)
y_pred = catboost_model.predict(X_test)
print(classification_report(y_test,y_pred))
print("weighted_accuracy:",weighted_accuracy(y_test,y_pred))
Como podemos ver, simplesmente o modelo de regressão de crista, que possui alta polarização e regularização, apresenta resultados ainda melhores do que CatBoost - existem muitos recursos que não são muito úteis e colineares, portanto, métodos resistentes a eles apresentam bons resultados.
Mais sobre o DT - e se você alterar um pouco o conjunto de dados? A importância do recurso pode variar, pois as árvores de decisão geralmente são métodos confidenciais, mesmo para embaralhamento de dados.
Conclusão: às vezes mais fácil é melhor e mais eficaz.
Escalabilidade
Você realmente precisa do Spark ou redes neurais com bilhões de parâmetros?
Em primeiro lugar, você precisa avaliar sensatamente a quantidade de dados, já vimos o uso massivo de faísca em tarefas que cabem facilmente na memória de uma máquina.
Spark complica a depuração, adiciona sobrecarga e complica o desenvolvimento - você não deve usá-lo onde não precisa dele. Clássicos .
Em segundo lugar, é claro, você precisa avaliar a complexidade do modelo e relacioná-lo à tarefa. Se seus concorrentes apresentarem resultados excelentes e tiverem o RandomForest em execução, pode valer a pena pensar duas vezes se você precisar de uma rede neural com bilhões de parâmetros.
E, claro, você precisa levar em consideração que, se você realmente tiver grandes dados, o modelo deve ser capaz de trabalhar com eles - como aprender com lotes ou ter algum tipo de mecanismo de aprendizagem distribuído (e assim por diante). E no mesmo local, não perca muito velocidade com o aumento da quantidade de dados. Por exemplo, sabemos que os métodos do kernel requerem um quadrado de memória para cálculos em espaço duplo - se você espera um aumento de 10 vezes no tamanho dos dados, deve pensar duas vezes se caberá nos recursos disponíveis.
Disponibilidade de modelos prontos
Outro detalhe importante é a busca por modelos já treinados que possam ser pré-treinados, ideal se:
- Não há muitos dados, mas eles são muito específicos para nossa tarefa - por exemplo, textos médicos.
- O tópico em geral é relativamente popular - por exemplo, destacando tópicos de texto - muitos trabalhos em PNL.
- Sua abordagem permite, em princípio, o pré-aprendizado - como, por exemplo, com algum tipo de rede neural.
Modelos pré-treinados como GPT-2 e BERT podem simplificar significativamente a solução do seu problema e, se já existirem modelos treinados, recomendo fortemente que você não ignore e use essa chance.
Interações de recursos e modelos lineares
Alguns modelos têm melhor desempenho quando não há interações complexas entre recursos - por exemplo, toda a classe de modelos lineares - Modelos de aditivos generalizados. Existe uma extensão desses modelos para o caso de interação de dois recursos denominados GA2M - Generalized Additive Models with Pairwise Interactions.
Como regra, tais modelos apresentam bons resultados com esses dados, são perfeitamente regularizados, interpretáveis e robustos a ruídos. Portanto, definitivamente vale a pena prestar atenção a eles.
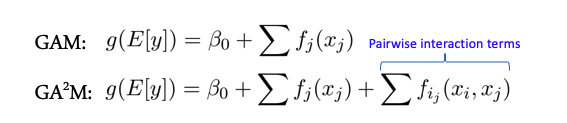
No entanto, se os sinais interagem ativamente em grupos de mais de 2, esses métodos não mostram mais resultados tão bons.
Suporte de pacote e modelo
Muitos algoritmos e modelos interessantes de artigos são projetados como um módulo ou pacote para python, R, etc. Vale a pena pensar duas vezes antes de usar e confiar em tal solução a longo prazo (digo isso, como uma pessoa que escreveu muitos artigos sobre ML com esse código). A probabilidade de que em um ano o suporte seja zero é muito alta, pois o autor provavelmente agora precisa se envolver em outros projetos, não há tempo e nem incentivos para investir no desenvolvimento do módulo ou repositório.
Nesse sentido, as bibliotecas a la scikit learn são boas precisamente porque na verdade elas têm um grupo garantido de entusiastas por perto e se algo estiver seriamente quebrado, mais cedo ou mais tarde serão consertadas.
Preconceitos e justiça
Junto com a tomada de decisão automática, as pessoas insatisfeitas com essas decisões ganham vida - imagine que temos algum tipo de sistema de classificação para solicitações de bolsa de estudos ou pesquisa em uma universidade. Nossa universidade será incomum - há apenas dois grupos de alunos: historiadores e matemáticos. Se, de repente, o sistema, com base em seus dados e lógica, distribuiu de repente todas as concessões aos historiadores e não as concedeu a nenhum matemático, isso não ofenderá os matemáticos. Eles chamarão esse sistema de tendencioso. Agora só o preguiçoso não fala sobre isso, e empresas e pessoas estão processando umas às outras.
Convencionalmente, imagine um modelo simplificado que simplesmente conta as citações de artigos e permite que os historiadores citem uns aos outros ativamente - a média é 100 citações, mas não há matemática, eles têm uma média de 20 - e eles escrevem muito pouco, então o sistema reconhece todos os historiadores como "bons" porque a taxa de citação é alta 100> 60 (média) e matemáticos, como "ruins" porque todos eles têm uma taxa de citação muito inferior à média de 20 <60. Tal sistema dificilmente pode parecer adequado para alguém.
Os clássicos agora apresentam a lógica de tomada de decisão e modelos de treinamento que combatem essa abordagem enviesada. Assim, para cada decisão, você tem uma explicação (condicionalmente) por que ela foi tomada e como você realmente fez um esforço para garantir que o modelo não fizesse besteira (ELI5 GDPR).

Leia mais do Google aqui, ou no artigo aqui .
Em geral, muitas empresas iniciaram essas atividades, especialmente à luz do lançamento do GDPR - tais medidas e verificações podem ajudar a evitar problemas no futuro.
Se algum tópico interessou mais do que outros - escreva nos comentários, iremos mais fundo. (DFS)!
