 Olá Habitantes! O livro Site Reliability Engineering gerou uma discussão acalorada. O que está operacional hoje e por que os problemas de confiabilidade são tão fundamentais? Agora, os engenheiros do Google por trás deste livro best-seller propõem passar da teoria à prática - o Site Reliability Workbook mostra como os princípios e práticas de SRE se traduzem em sua produção. A experiência do Google é complementada por casos de usuários do Google Cloud Platform. Representantes do Evernote, The Home Depot, The New York Times e outras empresas descrevem sua experiência de combate, informam quais práticas adotaram e quais não. Este livro o ajudará a adaptar a SRE às realidades de sua prática, independentemente do tamanho de sua empresa. Você aprenderá a:
Olá Habitantes! O livro Site Reliability Engineering gerou uma discussão acalorada. O que está operacional hoje e por que os problemas de confiabilidade são tão fundamentais? Agora, os engenheiros do Google por trás deste livro best-seller propõem passar da teoria à prática - o Site Reliability Workbook mostra como os princípios e práticas de SRE se traduzem em sua produção. A experiência do Google é complementada por casos de usuários do Google Cloud Platform. Representantes do Evernote, The Home Depot, The New York Times e outras empresas descrevem sua experiência de combate, informam quais práticas adotaram e quais não. Este livro o ajudará a adaptar a SRE às realidades de sua prática, independentemente do tamanho de sua empresa. Você aprenderá a:
- Garanta a confiabilidade dos serviços em nuvens e ambientes que você não controla totalmente;
- aplicar diversos métodos de criação, lançamento e monitoramento de serviços, com foco em SLO;
- transformar equipes de administração em engenheiros SRE;
- implementar métodos para iniciar o SRE do zero e com base nos sistemas existentes. Betsy Beyer, Neil Richard Murphy, David Renzin, Kent Kawahara e Stephen Thorne estão todos envolvidos em garantir a confiabilidade dos sistemas do Google.
Gerenciamento do sistema de monitoramento
Seu sistema de monitoramento é tão importante quanto qualquer outro serviço que você usa. Portanto, o monitoramento deve ser tratado com o devido cuidado.
Trate sua configuração como código Tratar a
configuração do sistema como código e armazená-la em um sistema de controle de versão é uma prática comum, com recursos como armazenamento de histórico de alterações, vinculação de alterações específicas ao sistema de gerenciamento de tarefas, reversões simplificadas, análise de código estático para erros e procedimentos forçados de inspeção de código.
Também recomendamos enfaticamente tratar a configuração de monitoramento como código (para obter mais informações sobre configuração, consulte o Capítulo 14). Um sistema de monitoramento que oferece suporte à personalização usando descrições bem formadas de objetivos e funções, em vez de sistemas que fornecem apenas interfaces da web ou APIs no estilo CRUD (http://bit.ly/1G4WdV1). Essa abordagem de configuração é padrão para muitos binários de código aberto que apenas leem um arquivo de configuração. Algumas soluções de terceiros, como grafanalib (http://bit.ly/2so5Wrx), suportam essa abordagem para componentes que são tradicionalmente personalizáveis usando a IU.
Incentive a consistência
Grandes empresas com várias equipes de projeto que usam o monitoramento precisam encontrar um equilíbrio delicado: por um lado, uma abordagem centralizada garante a consistência, mas, por outro lado, as equipes individuais podem querer ter controle total sobre o funcionamento de sua configuração.
A decisão certa depende do tipo de sua organização. Com o tempo, a abordagem do Google evoluiu para reunir todas as práticas recomendadas em uma única plataforma que funciona como um serviço centralizado. Esta é uma boa decisão para nós e existem várias razões para tal. Uma infraestrutura comum permite que os engenheiros passem de uma equipe para outra com mais rapidez e facilidade e facilita a colaboração durante a depuração. Além disso, há um serviço de painel centralizado onde os painéis de cada equipe estão abertos e acessíveis. Se você entender bem as informações fornecidas pela outra equipe, poderá corrigir rapidamente seus próprios problemas e os de outras equipes.
Sempre que possível, mantenha a cobertura básica de monitoramento o mais simples possível. Se todos os seus serviços exportam um conjunto consistente de linhas de base, você pode coletar automaticamente essas métricas em toda a sua organização e fornecer um conjunto consistente de painéis. Essa abordagem significa que há monitoramento básico para qualquer novo componente que você iniciar automaticamente. Dessa forma, muitas equipes da sua empresa - nem mesmo as de engenharia - poderão utilizar os dados de monitoramento.
Prefira laços fracos
Os requisitos de negócios mudam e seu sistema de produção ficará diferente em um ano. Assim como os serviços que você controla, seu sistema de monitoramento deve se desenvolver e evoluir com o tempo, passando por vários problemas típicos.
Recomendamos que o acoplamento entre os componentes do seu sistema de controle não seja muito forte. Você deve ter interfaces confiáveis para configurar cada componente e transferir dados de monitoramento. Diferentes componentes devem ser responsáveis por coletar, armazenar, alertar e visualizar seus dados de monitoramento. Interfaces estáveis facilitam a substituição de qualquer componente específico pela alternativa mais apropriada.
No mundo do código aberto, dividir a funcionalidade em componentes separados está se tornando popular. Dez anos atrás, sistemas de monitoramento como o Zabbix (https://www.zabbix.com/) combinavam todas as funções em um componente. O design moderno geralmente envolve separar a coleta e execução de regras (usando soluções como o servidor Prometheus (https://prometheus.io/)), armazenar séries temporais de longo prazo (InfluxDB, www.influxdata.com ), agregar alertas ( Alertmanager, bit.ly/2soB22b ) e criação de painéis (Grafana, grafana.com ).
No momento em que este artigo foi escrito, havia pelo menos dois padrões abertos populares que permitem equipar o software com as ferramentas necessárias e fornecer métricas:
- statsd — , Etsy, ;
- Prometheus — , . Prometheus OpenMetrics (https://openmetrics.io/).
Um sistema de painel separado usando várias fontes de dados fornece uma visão centralizada e unificada de seu serviço. O Google experimentou recentemente essa vantagem na prática: nosso sistema de monitoramento legado (Borgmon1) combinou painéis na mesma configuração das regras de alerta. Ao mudar para um novo sistema (Monarch, youtu.be/LlvJdK1xsl4 ), decidimos mover os painéis para um serviço separado (Viceroy, bit.ly/2sqRwad ). Viceroy não era um componente Borgmon ou Monarch, então Monarch tinha menos requisitos funcionais. Como os usuários podem usar o Viceroy para exibir gráficos com base nos dados de ambos os sistemas de monitoramento, eles foram capazes de migrar gradualmente do Borgmon para o Monarch.
Métricas significativas O
Capítulo 5 mostra como usar as métricas de qualidade de serviço (SLI) para rastrear e relatar ameaças ao seu orçamento. As métricas SLI são as primeiras métricas a verificar quando os alertas são acionados com base nas metas de qualidade de serviço (SLO). Essas métricas devem aparecer no painel do seu serviço, de preferência na página inicial.
Ao investigar a causa raiz de uma violação de SLO, você provavelmente não obterá informações suficientes dos painéis de SLO. Esses painéis mostram que há violações, mas é improvável que você saiba sobre os motivos que as levaram. Que outros dados devem ser exibidos no painel?
Acreditamos que as seguintes diretrizes são úteis ao implementar métricas: Essas métricas devem fornecer monitoramento significativo que permite investigar problemas de produção e fornecer uma ampla gama de informações sobre seus serviços.
Alterações intencionais
Ao diagnosticar alertas relacionados ao SLO, você precisa ser capaz de passar das métricas de alerta que o notificam sobre problemas que afetam os usuários para as métricas que o alertam sobre a causa raiz desses problemas. Esses motivos podem ser uma alteração deliberada recente em seu serviço. Adicione monitoramento que informa sobre quaisquer alterações na produção. Para detectar o fato de que as alterações foram feitas, recomendamos o seguinte:
- monitorar a versão de um arquivo binário;
- , ;
- , .
Se algum desses componentes não tiver versão, será necessário rastrear quando o componente foi montado ou empacotado pela última vez.
Ao tentar correlacionar problemas de serviço emergentes com uma implantação, é muito mais fácil olhar para um gráfico ou painel referenciado em um alerta do que folhear os logs de CI / CD após o fato.
Dependências
Mesmo que seu serviço não tenha mudado, qualquer uma de suas dependências pode mudar. Portanto, você também precisa controlar as respostas provenientes de dependências diretas.
É aconselhável exportar o tamanho da solicitação e resposta em bytes, tempos de resposta e códigos de resposta para cada dependência. Ao escolher uma métrica para um gráfico, mantenha estes quatro sinais de ouro em mente (consulte a seção"The Four Golden Signals," Capítulo 6 de Site Reliability Engineering ).
Você pode usar rótulos adicionais nas métricas para separá-las por código de resposta, nome do método RPC (chamada de procedimento remoto) e nome do serviço que está sendo chamado.
Idealmente, em vez de pedir a cada biblioteca cliente RPC para exportar esses rótulos, você pode usar a ferramenta da biblioteca cliente RPC de nível inferior para essa finalidade uma vez. Isso fornece mais consistência e permite monitorar facilmente novas dependências.
Existem dependências que oferecem uma API muito limitada, onde toda a funcionalidade está disponível por meio de um único método RPC chamado Get, Query ou apenas como não informativo, e o comando real é especificado como argumentos para esse método. A abordagem de um único ponto para ferramentas na biblioteca cliente não funciona para este tipo de dependência: você verá muita variabilidade na latência e uma certa porcentagem de erros que podem ou não indicar que alguma parte deste "turvo" A API caiu completamente. Se essa dependência for crítica, um bom monitoramento para ela pode ser implementado das seguintes maneiras.
- Exporte métricas separadas projetadas especificamente para essa dependência, onde as solicitações serão descompactadas para obter um sinal válido.
- Peça aos proprietários da dependência para reescrevê-la para exportar uma API estendida que oferece suporte à separação de funções entre serviços e métodos RPC individuais.
O nível de carga de trabalho
É desejável controlar e rastrear o uso de todos os recursos com os quais o serviço trabalha. Alguns recursos têm limites rígidos que você não pode exceder. Por exemplo, o tamanho da RAM, o disco rígido alocado para seu aplicativo ou a cota da CPU. Outros recursos, como descritores de arquivos abertos, encadeamentos ativos em qualquer pool de encadeamentos, tempos limite de fila ou a quantidade de logs gravados, podem não ter um limite rígido claro, mas ainda precisam ser gerenciados.
Dependendo da linguagem de programação que você está usando, você precisa controlar alguns recursos adicionais:
- em Java, heap e meta-espaço (http://bit.ly/2J9g3Ha), e métricas mais específicas dependendo do tipo de coleta de lixo usado;
- em Go, o número de goroutines.
As próprias linguagens de programação fornecem vários suportes para manter o controle desses recursos.
Além de alertá-lo sobre eventos significativos, conforme descrito no Capítulo 5, você também pode configurar alertas que são acionados quando certos recursos estão se aproximando do esgotamento crítico. Isso é útil, por exemplo, nas seguintes situações:
- quando o recurso tem um limite rígido;
- quando ocorre uma degradação do desempenho quando o limite de uso é excedido.
O monitoramento é essencial para todos os recursos, mesmo aqueles que o serviço gerencia bem. Essas métricas são vitais ao planejar recursos e capacidades.
Status de tráfego emitido
Recomenda-se adicionar métricas ou rótulos de métricas no painel que permitirão que você divida o tráfego emitido por código de status (se as métricas usadas por seu serviço para fins de SLI não contiverem essas informações). Aqui estão algumas diretrizes.
- Acompanhe todos os códigos de resposta para o tráfego HTTP, mesmo aqueles que, devido a um possível comportamento incorreto do cliente, não sejam motivo para emitir alertas.
- Se você estiver aplicando limite de tempo ou cota aos usuários, controle o número de solicitações negadas por falta de cota.
Os gráficos desses dados podem ajudá-lo a determinar quando a taxa de erro muda visivelmente durante uma mudança de produção.
Implementação de métricas alvo
Cada métrica deve servir ao seu propósito. Não fique tentado a exportar várias métricas apenas porque são fáceis de gerar. Em vez disso, pense em como eles serão usados. A arquitetura métrica (ou a falta dela) tem implicações. Idealmente, os valores métricos usados para alertar mudam abruptamente apenas quando ocorre um problema no sistema, mas durante a operação normal eles permanecem inalterados. Por outro lado, esses requisitos não são impostos às métricas de depuração - eles devem dar uma ideia do que acontece quando um alerta é acionado. Boas métricas de depuração indicarão partes potencialmente problemáticas do sistema. Ao escrever uma autópsia, considere quais métricas adicionais permitiriam diagnosticar o problema mais rapidamente.
Testando a lógica de alerta
Em um mundo ideal, o código de monitoramento e alerta deve seguir os mesmos padrões de teste do código de desenvolvimento. Atualmente, não existe um sistema amplamente aceito que permita a implementação de tal conceito. Um dos primeiros sinais é a funcionalidade de teste de unidade de regra recém-adicionada ao Prometheus.
No Google, testamos nossos sistemas de monitoramento e alerta usando uma linguagem específica de domínio que nos permite criar séries temporais sintéticas. Em seguida, verificamos os valores na série temporal derivada ou esclarecemos se um alerta específico foi acionado e tem o rótulo necessário.
O monitoramento e a emissão de alertas costumam ser um processo de várias etapas, portanto, várias famílias de testes de unidade são necessárias.
Embora essa área permaneça em grande parte subdesenvolvida, se você deseja implementar o teste de monitoramento em algum ponto, recomendamos uma abordagem em três camadas, conforme mostrado na Figura 1. 4.1.
- Arquivos binários. Certifique-se de que as variáveis métricas exportadas alterem os valores conforme o esperado sob certas condições.
- Infraestrutura de monitoramento. Certifique-se de que as regras sejam seguidas e as condições específicas sejam os alertas esperados.
- Gerenciador de alertas. Verifique se os alertas gerados são roteados para um destino predefinido com base nos valores do rótulo.
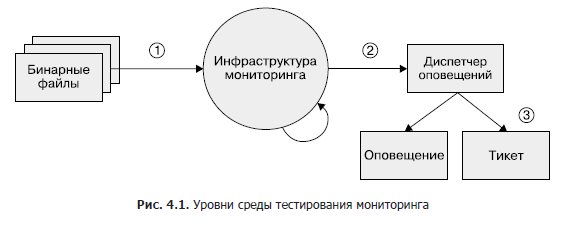
Se você não puder testar seu sistema de monitoramento com ferramentas sintéticas ou se uma etapa não puder ser testada, considere a criação de um sistema de produção que exporte métricas conhecidas, como solicitações e erros. Você pode usar este sistema para verificar séries temporais e alertas. É provável que suas regras de alerta não sejam disparadas por meses ou anos depois de configurá-las, e você precisa se certificar de que, quando a métrica ultrapassar um determinado limite, os alertas permaneçam significativos e entregues aos engenheiros pretendidos.
Resumo do capítulo
Uma vez que os engenheiros SR devem ser responsáveis pela confiabilidade dos sistemas de produção, esses especialistas muitas vezes precisam entender profundamente o sistema de monitoramento e suas funções e interagir de perto com ele. Sem esses dados, os SREs podem não saber onde procurar e como identificar o comportamento anormal do sistema ou como encontrar as informações de que precisam durante uma emergência.
Esperamos que, apontando as funções úteis do nosso ponto de vista, do sistema de monitoramento e justificando nossa escolha, possamos ajudá-lo a avaliar como o seu sistema de monitoramento atende às suas necessidades. Além disso, vamos ajudá-lo a explorar alguns dos recursos adicionais que você pode usar e revisar as alterações que provavelmente deseja fazer. Você provavelmente achará útil combinar fontes de métricas e registros em sua estratégia de monitoramento. A combinação certa de métricas e logs é altamente dependente do contexto.
Certifique-se de coletar métricas que atendem a um propósito específico. Essas são metas, como melhorar o agendamento da largura de banda, depurar ou relatar problemas que surjam.
Quando você tem monitoramento, deve ser visual e útil. Para fazer isso, recomendamos testar suas configurações. Um bom sistema de monitoramento paga dividendos. O pré-planejamento completo de quais soluções usar para melhor cobrir seus requisitos específicos, bem como melhorias iterativas contínuas para o sistema de monitoramento, é um investimento que valerá a pena.
»Mais detalhes sobre o livro podem ser encontrados no site da editora
» Índice
» Trecho
Para Habitantes desconto de 25% no cupom - Google No
ato do pagamento da versão em papel do livro, é enviado um e-book por e-mail.