O fato é que todas as nossas equipes são construídas em torno de sistemas de informação, microsserviços e frentes separados, de modo que as equipes não veem a saúde geral de todo o sistema como um todo. Por exemplo, eles podem não saber como uma pequena parte no backend profundo afeta o front end. O alcance de seus interesses é limitado aos sistemas com os quais seu sistema está integrado. Se a equipe e seu serviço A quase nada têm a ver com o serviço B, esse serviço é quase invisível para a equipe.
Nossa equipe, por sua vez, trabalha com sistemas fortemente integrados entre si: são muitas as conexões entre eles, é uma infraestrutura muito grande. E o trabalho da loja online depende de todos esses sistemas (dos quais, aliás, temos um número enorme).
Acontece que nosso departamento não pertence a nenhuma equipe, mas é um pouco indiferente. Em toda essa história, nossa tarefa é entender de forma complexa como funcionam os sistemas de informação, sua funcionalidade, integrações, software, rede, hardware e como tudo isso está interligado.
A plataforma em que operam nossas lojas online é assim:
- frente
- escritorio do meio
- back-office
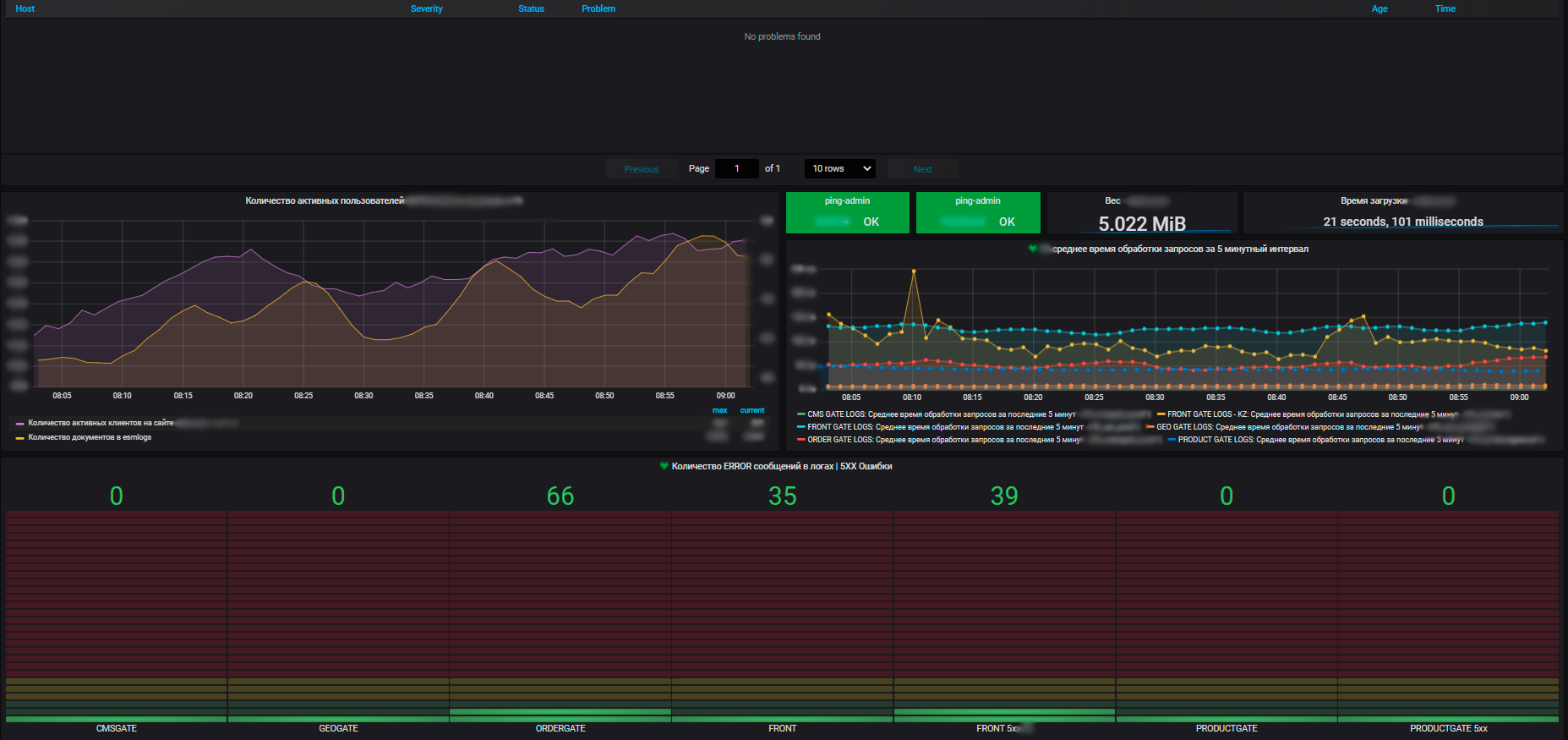
Por mais que gostaríamos, mas não existe tal coisa que todos os sistemas funcionem perfeitamente e sem falhas. O ponto, novamente, é o número de sistemas e integrações - com os que temos, alguns incidentes são inevitáveis, apesar da qualidade dos testes. Além disso, tanto dentro de um sistema separado quanto em termos de sua integração. E você precisa monitorar o estado de toda a plataforma de forma abrangente, e não qualquer parte separada dela.
O ideal é que o monitoramento da integridade de toda a plataforma seja automatizado. E chegamos ao monitoramento como uma parte inevitável desse processo. Inicialmente, ele foi construído apenas para a parte frontal, enquanto os networkers, administradores de software e hardware tinham seus próprios sistemas de monitoramento por camadas. Todas essas pessoas acompanharam o monitoramento apenas em seu próprio nível, ninguém tinha um entendimento abrangente também.
Por exemplo, se uma máquina virtual travou, na maioria dos casos, apenas o administrador responsável pelo hardware e a máquina virtual sabem disso. Nesses casos, a equipe de frente viu o próprio fato da falha do aplicativo, mas não tinha dados sobre a falha da máquina virtual. E o administrador pode saber quem é o cliente e, aproximadamente, imaginar o que está sendo executado nesta máquina virtual agora, desde que seja algum tipo de projeto grande. Ele provavelmente não sabe sobre os pequenos. Em qualquer caso, o administrador precisa ir ao dono, perguntar o que havia nesta máquina, o que precisa ser restaurado e o que alterar. E se algo muito sério quebrasse, eles começariam a andar em círculos - porque ninguém via o sistema como um todo.
Em última análise, essas histórias díspares afetam todo o front-end, os usuários e nossa função principal de negócios, as vendas online. Uma vez que não fazemos parte de uma equipa, mas sim que operamos todas as aplicações de e-commerce numa loja online, assumimos a tarefa de criar um sistema de monitorização completo para a plataforma de e-commerce.
Estrutura e pilha do sistema
Começamos destacando várias camadas de monitoramento de nossos sistemas, em cujo contexto precisamos coletar métricas. E tudo isso teve que ser combinado, o que fizemos na primeira fase. Agora, neste estágio, estamos finalizando a coleção de métricas da mais alta qualidade para todas as nossas camadas, a fim de construir uma correlação e entender como os sistemas afetam uns aos outros.
A falta de monitoramento abrangente nos estágios iniciais de lançamento de aplicativos (desde que começamos a construí-lo quando a maioria dos sistemas estava em operação) fez com que tivéssemos um débito técnico significativo para configurar o monitoramento de toda a plataforma. Não podíamos nos dar ao luxo de nos concentrar em configurar o monitoramento de um único SI e trabalhar o monitoramento para ele em detalhes, uma vez que o restante dos sistemas teria ficado sem monitoramento por algum tempo. Para resolver este problema, identificamos uma lista das métricas mais necessárias para avaliar o estado do sistema de informação por camadas e começamos a implementá-lo.
Portanto, eles decidiram comer o elefante em partes.
Nosso sistema consiste em:
- hardware;
- sistema operacional;
- Programas;
- Partes da IU no aplicativo de monitoramento;
- métricas de negócios;
- aplicativos de integração;
- segurança da informação;
- redes;
- balanceador de tráfego.
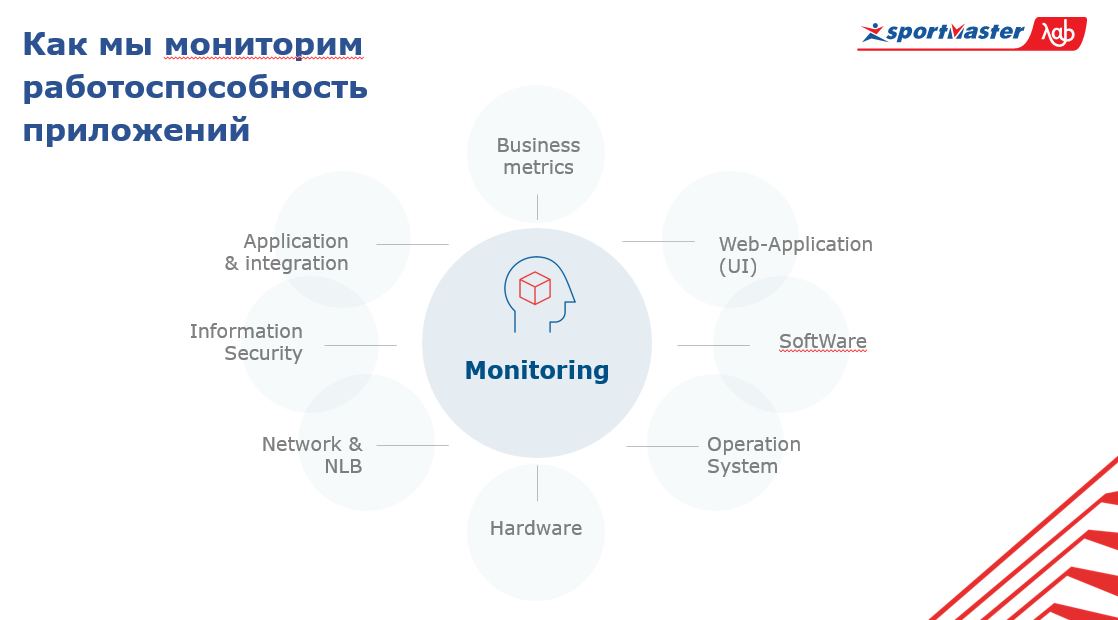
No centro desse sistema está o monitoramento de si mesmo. Para compreender de maneira geral o estado de todo o sistema, você precisa saber o que está acontecendo com os aplicativos em todas essas camadas e no contexto de todo o conjunto de aplicativos.
Então, sobre a pilha.

Usamos software de código aberto. No centro, temos o Zabbix, que usamos principalmente como um sistema de alerta. Todo mundo sabe que é ideal para monitorar infraestrutura. O que isto significa? Essas são as métricas de baixo nível que toda empresa tem que tem seu próprio data center (e a Sportmaster tem seus próprios data centers) - temperatura do servidor, status da memória, raid, métricas de dispositivo de rede.
Integramos o Zabbix com o Telegram messenger e o Microsoft Teams, que são usados ativamente em equipes. O Zabbix cobre a camada da rede real, hardware e software parcial, mas não é uma panacéia. Nós enriquecemos esses dados de alguns outros serviços. Por exemplo, em termos de nível de hardware, nos conectamos diretamente via API ao nosso sistema de virtualização e coletamos dados.
O quê mais. Além do Zabbix, usamos o Prometheus, que permite monitorar métricas em um aplicativo de ambiente dinâmico. Ou seja, podemos receber métricas do aplicativo por meio do endpoint HTTP e não nos preocupar com quais métricas carregar nele e quais não. Com base nesses dados, você pode elaborar consultas analíticas.
As fontes de dados para outras camadas, por exemplo, métricas de negócios, são divididas em três componentes.
Em primeiro lugar, estes são sistemas de negócios externos, Google Analytics, coletamos métricas de registros. Deles obtemos dados sobre usuários ativos, conversões e tudo o mais relacionado ao negócio. Em segundo lugar, é um sistema de monitoramento de IU. Deve ser descrito com mais detalhes.
Era uma vez, começamos com testes manuais e evoluiu para autotestes funcionais e de integração. Fizemos o monitoramento a partir dele, deixando apenas a funcionalidade principal, e vinculados a marcadores que são o mais estáveis possíveis e não mudam com frequência com o tempo.
A nova estrutura da equipe implica que todas as atividades do aplicativo estão bloqueadas nas equipes do produto, então paramos de fazer testes puros. Em vez disso, fizemos monitoramento de IU a partir de testes, escritos em Java, Selenium e Jenkins (usados como um sistema para iniciar e gerar relatórios).
Fizemos muitos testes, mas no final decidimos ir para a estrada principal, a métrica de nível superior. E se tivermos muitos testes específicos, será difícil manter os dados atualizados. Cada versão subsequente quebrará significativamente todo o sistema, e iremos apenas consertá-lo. Portanto, nos vinculamos a coisas muito fundamentais que raramente mudam e apenas as monitoramos.
Finalmente, em terceiro lugar, a fonte de dados é um sistema de registro centralizado. Para logs, usamos Elastic Stack e, em seguida, podemos arrastar esses dados para nosso sistema de monitoramento para métricas de negócios. Além de tudo isso, funciona o nosso próprio serviço de API de monitoramento, escrito em Python, que consulta quaisquer serviços através da API e leva dados deles para o Zabbix.
Outro atributo insubstituível do monitoramento é a visualização. Nós o construímos com base na Grafana. Dentre outros sistemas de visualização, destaca-se por poder visualizar métricas de diferentes fontes de dados no painel. Podemos coletar as métricas de nível superior da loja online, por exemplo, o número de pedidos feitos na última hora do DBMS, as métricas de desempenho do sistema operacional que executa esta loja online do Zabbix e as métricas das instâncias deste aplicativo do Prometheus. E tudo isso estará em um painel. Visual e acessível.
Deixe-me observar sobre a segurança - agora estamos finalizando o sistema, que posteriormente integraremos ao sistema de monitoramento global. Na minha opinião, os principais problemas enfrentados pelo e-commerce na área de segurança da informação estão associados a bots, parsers e força bruta. Isso deve ser monitorado porque todos eles podem afetar criticamente o desempenho de nossos aplicativos e a reputação de um ponto de vista comercial. E com a pilha escolhida, cobrimos com sucesso essas tarefas.
Outro ponto importante é que a camada de aplicação é coletada pelo Prometheus. Ele próprio também está integrado ao Zabbix. E também temos o sitepeed, um serviço que nos permite observar parâmetros como a velocidade de carregamento de nossa página, gargalos, renderização de página, carregamento de scripts, etc., também é integrado através da API. Portanto, as métricas são coletadas no Zabbix, respectivamente, também alertamos de lá. Todos os alertas até agora vão para os principais métodos de envio (por enquanto, são e-mail e telegrama, eles conectaram recentemente o MS Teams). Existem planos para bombear o alerta a tal estado que os bots inteligentes funcionem como um serviço e forneçam informações de monitoramento para todas as equipes de produto interessadas.
Para nós, não apenas as métricas dos sistemas de informação individuais são importantes, mas também as métricas gerais para toda a infraestrutura que os aplicativos usam: clusters de servidores físicos executando máquinas virtuais, balanceadores de tráfego, balanceadores de carga de rede, a própria rede, utilização de canais de comunicação. Mais métricas para nossos próprios data centers (temos vários deles e a infraestrutura é bastante significativa).
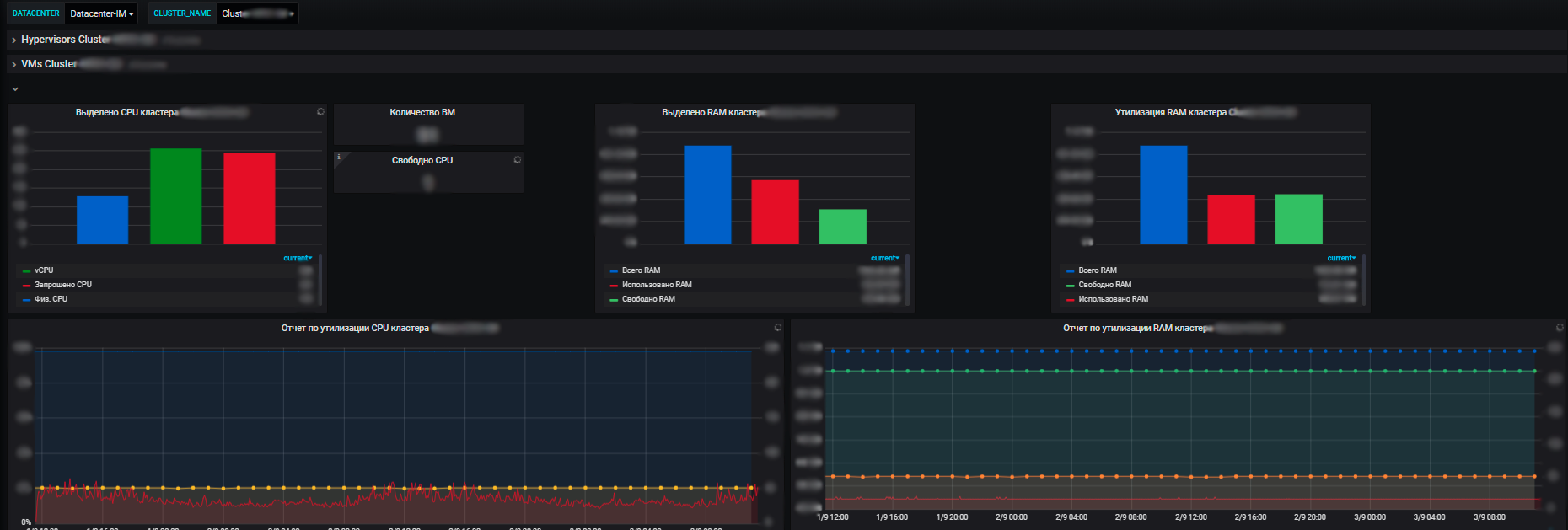
As vantagens de nosso sistema de monitoramento são que, com sua ajuda, podemos ver o estado de saúde de todos os sistemas, podemos avaliar seu impacto uns sobre os outros e sobre os recursos comuns. E, em última análise, permite o planejamento de recursos, que também é nossa responsabilidade. Gerenciamos os recursos do servidor - um pool dentro da estrutura do e-commerce, introduzimos e descomissionamos novos equipamentos, compramos novos equipamentos, conduzimos uma auditoria de utilização de recursos e assim por diante. A cada ano as equipes planejam novos projetos, desenvolvem seus sistemas e é importante para nós fornecer recursos para elas.
E com a ajuda de métricas, vemos a tendência de consumo de recursos por nossos sistemas de informação. E já com base neles podemos planejar algo. No nível da virtualização, coletamos dados e vemos informações sobre a quantidade de recursos disponíveis no contexto dos data centers. E já dentro do data center, tanto a utilização quanto a distribuição real, o consumo de recursos são visíveis. Além disso, tanto com servidores autônomos, quanto máquinas virtuais e clusters de servidores físicos, nos quais todas essas máquinas virtuais estão girando vigorosamente.
Perspectivas
Agora temos o núcleo do sistema como um todo pronto, mas ainda há pontos suficientes para trabalhar. Pelo menos essa é uma camada de segurança da informação, mas também é importante chegar à rede, desenvolver alertas e resolver o problema com correlação. Temos muitas camadas e sistemas, há muito mais métricas em cada camada. Acontece que matryoshka ao grau de matryoshka.
Nossa tarefa é, em última análise, fazer os alertas certos. Por exemplo, se houve um problema com o hardware, novamente, com uma máquina virtual, e havia um aplicativo importante e não foi feito backup do serviço de forma alguma. Descobrimos que a máquina virtual morreu. Em seguida, eles alertarão as métricas de negócios: os usuários desapareceram em algum lugar, não há conversão, a IU na interface não está disponível, software e serviços também morreram.
Nessa situação, receberemos spam de alertas, e isso não se encaixa mais no formato de um sistema de monitoramento correto. A questão da correlação surge. Portanto, idealmente, nosso sistema de monitoramento deveria dizer: “Gente, sua máquina física morreu, e com ela esta aplicação e tais métricas”, com a ajuda de um alerta ao invés de nos bombardear furiosamente com uma centena de alertas. Ela deve relatar o principal - o motivo, o que contribui para a prontidão da eliminação do problema devido à sua localização.
Nosso sistema de gerenciamento de notificações e alertas é construído em torno de um serviço de linha direta 24 horas nos sete dias da semana. Todos os alertas que são considerados indispensáveis para nós e estão incluídos na lista de verificação são enviados para lá. Cada alerta deve ter uma descrição: o que aconteceu, o que realmente significa, o que afeta. E também um link para o painel e instruções sobre o que fazer neste caso.
Isso é tudo para os requisitos para a construção do alerta. Além disso, a situação pode se desenvolver em duas direções - ou há um problema e ele precisa ser resolvido ou houve uma falha no sistema de monitoramento. Mas, em qualquer caso, você precisa descobrir.
Em média, chegam a nós cerca de uma centena de alertas por dia agora, isto tendo em conta o facto de a correlação de alertas ainda não estar devidamente configurada. E se precisamos realizar um trabalho técnico, e desligamos algo à força, seu número aumenta significativamente.
Além de monitorar os sistemas que operamos e coletar métricas que são consideradas importantes para nós, o sistema de monitoramento nos permite coletar dados para equipes de produtos. Eles podem influenciar a composição das métricas dentro dos sistemas de informação que são monitorados aqui.
Nosso colega pode vir e pedir para adicionar alguma métrica que seja útil para nós e para a equipe. Ou, por exemplo, a equipe pode não ter o suficiente das métricas básicas que temos, eles precisam rastrear alguma específica. No Grafana, criamos um espaço para cada equipe e emitimos direitos de administrador. Além disso, se uma equipe precisa de painéis, mas eles próprios não podem / não sabem como fazê-lo, nós os ajudamos.
Como estamos fora do fluxo de criação de valor da equipe, seus lançamentos e planejamento, gradualmente chegamos à conclusão de que os lançamentos de todos os sistemas são contínuos e podem ser lançados diariamente, sem coordenação conosco. E é importante para nós rastrearmos esses lançamentos, porque eles podem afetar potencialmente a operação do aplicativo e interromper algo, e isso é crítico. Para gerenciar os releases, usamos o Bamboo, de onde obtemos os dados da API e podemos ver quais releases em quais sistemas de informação saíram e seus status. E o mais importante é a que horas. Colocamos marcadores de lançamento nas principais métricas críticas, o que é visualmente muito indicativo em caso de problemas.
Dessa forma, podemos ver a correlação entre novos lançamentos e problemas emergentes. A ideia principal é entender como o sistema funciona em todas as camadas, para localizar rapidamente o problema e corrigi-lo com a mesma rapidez. Na verdade, muitas vezes acontece que a maior parte do tempo é gasta não resolvendo o problema, mas descobrindo a causa.
E nessa direção, no futuro, queremos focar na proatividade. Idealmente, gostaria de saber com antecedência sobre um problema iminente, e não após o fato, para lidar com sua prevenção, não uma solução. Às vezes há falsos positivos do sistema de monitoramento, tanto por erro humano quanto por alterações no aplicativo. E estamos trabalhando nisso, depurando e tentando alertar os usuários sobre isso antes de qualquer manipulação no sistema de monitoramento, que o usa conosco. , ou realizar esses eventos na janela técnica.
Então, o sistema foi lançado e está funcionando com sucesso desde o início da primavera ... e mostra um lucro muito real. Claro, esta não é sua versão final, vamos apresentar muitos outros recursos úteis. Mas agora, com tantas integrações e aplicativos, a automação do monitoramento é realmente indispensável.
Se você também monitora grandes projetos com um grande número de integrações, escreva nos comentários qual solução mágica você encontrou para isso.