É conveniente processar texto em linguagem natural usando Python, uma vez que é uma ferramenta de programação de alto nível, possui uma infraestrutura bem desenvolvida e se provou no campo de análise de dados e aprendizado de máquina. Várias bibliotecas e estruturas foram desenvolvidas pela comunidade para resolver problemas de PNL em Python. Em nosso trabalho, usaremos a ferramenta web interativa para desenvolvimento de scripts python Jupyter Notebook, a biblioteca NLTK para análise de texto e a biblioteca wordcloud para construção de uma nuvem de palavras.
A rede contém uma quantidade bastante grande de material sobre o tema da análise de texto, mas em muitos artigos (incluindo os de língua russa) propõe-se analisar o texto em inglês. A análise do texto em russo apresenta alguns detalhes sobre o uso do kit de ferramentas da PNL. Como exemplo, considere a análise de frequência do texto da história "Tempestade de neve" de A. Pushkin.
A análise de frequência pode ser dividida aproximadamente em várias etapas:
- Carregando e navegando dados
- Limpeza e pré-processamento de texto
- Remover palavras de parada
- Traduzir palavras para a forma básica
- Calculando as estatísticas de ocorrência de palavras no texto
- Visualização da popularidade da palavra na nuvem
O script está disponível em github.com/Metafiz/nlp-course-20/blob/master/frequency-analisys-of-text.ipynb , fonte - github.com/Metafiz/nlp-course-20/blob/master/pushkin -metel.txt
Carregando dados
Abrimos o arquivo usando a função interna aberta, especificamos o modo de leitura e a codificação. Lemos todo o conteúdo do arquivo e, como resultado, obtemos o texto da string:
f = open('pushkin-metel.txt', "r", encoding="utf-8")
text = f.read()
O comprimento do texto - o número de caracteres - pode ser obtido com a função len padrão:
len(text)
Uma string em python pode ser representada como uma lista de caracteres, portanto, acesso ao índice e operações de fatiamento também são possíveis para trabalhar com strings. Por exemplo, para visualizar os primeiros 300 caracteres do texto, basta executar o comando:
text[:300]
Pré-processamento (pré-processamento) de texto
Para realizar a análise de frequência e determinar o assunto do texto, é recomendável limpar o texto de sinais de pontuação, caracteres de espaço em branco extras e números. Você pode fazer isso de várias maneiras - usando funções de string integradas, usando expressões regulares, usando processamento de lista ou de outra maneira.
Primeiro, vamos converter caracteres em um único caso, por exemplo, inferior:
text = text.lower()
Usamos o conjunto de caracteres de pontuação padrão do módulo de string:
import string
print(string.punctuation)
string.punctuation é uma string. O conjunto de caracteres especiais a serem removidos do texto pode ser expandido. É necessário analisar o texto fonte e identificar os caracteres que devem ser retirados. Vamos adicionar quebras de linha, tabulações e outros caracteres que são encontrados em nosso texto fonte para sinais de pontuação (por exemplo, o caractere com o código \ xa0):
spec_chars = string.punctuation + '\n\xa0«»\t—…'
Para remover caracteres, usamos o processamento elemento por elemento da string - dividimos a string de texto original em caracteres, deixamos apenas os caracteres que não estão incluídos no conjunto spec_chars e combinamos novamente a lista de caracteres em uma string:
text = "".join([ch for ch in text if ch not in spec_chars])
Você pode declarar uma função simples que remove o conjunto de caracteres especificado do texto de origem:
def remove_chars_from_text(text, chars):
return "".join([ch for ch in text if ch not in chars])
Ele pode ser usado para remover caracteres especiais e para remover números do texto original:
text = remove_chars_from_text(text, spec_chars)
text = remove_chars_from_text(text, string.digits)
Tokenizando o texto
Para processamento posterior, o texto limpo deve ser dividido em suas partes componentes - tokens. A análise de texto em linguagem natural usa decomposição de símbolos, palavras e frases. O processo de particionamento é chamado de tokenização. Para nossa tarefa de análise de frequência, é necessário dividir o texto em palavras. Para fazer isso, você pode usar o método pronto da biblioteca NLTK:
from nltk import word_tokenize
text_tokens = word_tokenize(text)
A variável text_tokens é uma lista de palavras (tokens). Para calcular o número de palavras no texto pré-processado, você pode obter o comprimento da lista de tokens:
len(text_tokens)
Para exibir as primeiras 10 palavras, vamos usar a operação de fatia:
text_tokens[:10]
Para usar as ferramentas de análise de frequência da biblioteca NLTK, você precisa converter a lista de tokens para a classe Text, que está incluída nesta biblioteca:
import nltk
text = nltk.Text(text_tokens)
Vamos deduzir o tipo do texto variável:
print(type(text))
As operações de fatia também são aplicáveis a uma variável desse tipo. Por exemplo, esta ação produzirá os primeiros 10 tokens do texto:
text[:10]
Calculando as estatísticas de ocorrência de palavras no texto
A classe FreqDist (distribuições de frequência) é usada para calcular as estatísticas de distribuição de frequência de palavras no texto:
from nltk.probability import FreqDist
fdist = FreqDist(text)
Tentar exibir a variável fdist exibirá um dicionário contendo tokens e suas frequências - o número de vezes que essas palavras aparecem no texto:
FreqDist({'': 146, '': 101, '': 69, '': 54, '': 44, '': 42, '': 39, '': 39, '': 31, '': 27, ...})
Você também pode usar o método most_common para obter uma lista de tuplas com os tokens mais comuns:
fdist.most_common(5)
[('', 146), ('', 101), ('', 69), ('', 54), ('', 44)]
A frequência de distribuição das palavras em um texto pode ser visualizada por meio de um gráfico. A classe FreqDist contém um método de plot integrado para plotar tal plot. É necessário indicar o número de tokens, cujas frequências serão mostradas no gráfico. Com o parâmetro cumulativo = Falso, o gráfico ilustra a lei de Zipf : se todas as palavras de um texto suficientemente longo são ordenadas em ordem decrescente de frequência de seu uso, então a frequência da enésima palavra em tal lista será aproximadamente inversamente proporcional ao seu número ordinal n.
fdist.plot(30,cumulative=False)
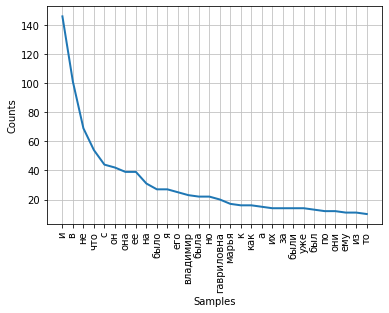
Pode-se notar que, no momento, as frequências mais altas têm conjunções, preposições e outras partes do discurso de serviço que não carregam uma carga semântica, mas apenas expressam relações semântico-sintáticas entre as palavras. Para que os resultados da análise de frequência reflitam o assunto do texto, é necessário remover essas palavras do texto.
Remover palavras de parada
As palavras irrelevantes (ou palavrões), via de regra, incluem preposições, conjunções, interjeições, partículas e outras classes gramaticais frequentemente encontradas no texto, são de serviço e não carregam carga semântica - são redundantes.
A biblioteca NLTK contém listas de palavras de interrupção prontas para vários idiomas. Vamos fazer uma lista de cem palavras para o idioma russo:
from nltk.corpus import stopwords
russian_stopwords = stopwords.words("russian")
Deve-se observar que as palavras irrelevantes são sensíveis ao contexto - para textos de assuntos diferentes, as palavras irrelevantes podem ser diferentes. Como no caso dos caracteres especiais, é necessário analisar o texto fonte e identificar palavras irrelevantes que não estão incluídas no conjunto padrão.
A lista de palavras irrelevantes pode ser estendida usando o método de extensão padrão:
russian_stopwords.extend(['', ''])
Depois de remover as palavras de parada, a frequência de distribuição de tokens no texto é a seguinte:
fdist_sw.most_common(10)
[('', 23),
('', 20),
('', 17),
('', 9),
('', 9),
('', 8),
('', 7),
('', 6),
('', 6),
('', 6)]
Como você pode ver, os resultados da análise de frequência se tornaram mais informativos e refletem com mais precisão o tópico principal do texto. Porém, vemos nos resultados tokens como "vladimir" e "vladimira", que são, na verdade, uma palavra, mas em formas diferentes. Para corrigir essa situação, é necessário trazer as palavras do texto-fonte às suas bases ou à sua forma original - para realizar a lematização ou a lematização.
Visualização da popularidade da palavra na nuvem
Ao final do nosso trabalho, visualizamos os resultados da análise de frequência do texto na forma de uma "nuvem de palavras".
Para isso, precisamos das bibliotecas wordcloud e matplotlib:
from wordcloud import WordCloud
import matplotlib.pyplot as plt
%matplotlib inline
Para construir uma nuvem de palavras, uma string deve ser passada ao método como entrada. Para converter a lista de tokens após o pré-processamento e remoção de palavras de parada, usaremos o método de junção, especificando um espaço como separador:
text_raw = " ".join(text)
Vamos chamar o método para construir a nuvem:
wordcloud = WordCloud().generate(text_raw)
Como resultado, obtemos uma "nuvem de palavras" para o nosso texto:

olhando para ela, você pode ter uma ideia geral do assunto e dos personagens principais do trabalho.