Vamos ver quais soluções esse problema tem.
Distribuição de objetos "por capacidade"
Para não mergulhar em abstrações desinteressantes, vamos considerá-lo usando o exemplo de uma tarefa específica - o monitoramento . Tenho certeza de que você mesmo poderá relacionar os métodos propostos às suas tarefas específicas.
Objetos de monitoramento "equivalentes"
Um exemplo são nossos coletores de métricas para Zabbix , que historicamente têm uma arquitetura comum com coletores de log PostgreSQL. Na verdade
, cada objeto de monitoramento (host) gera para o zabbix quase estavelmente o mesmo conjunto de métricas com a mesma frequência o tempo todo:
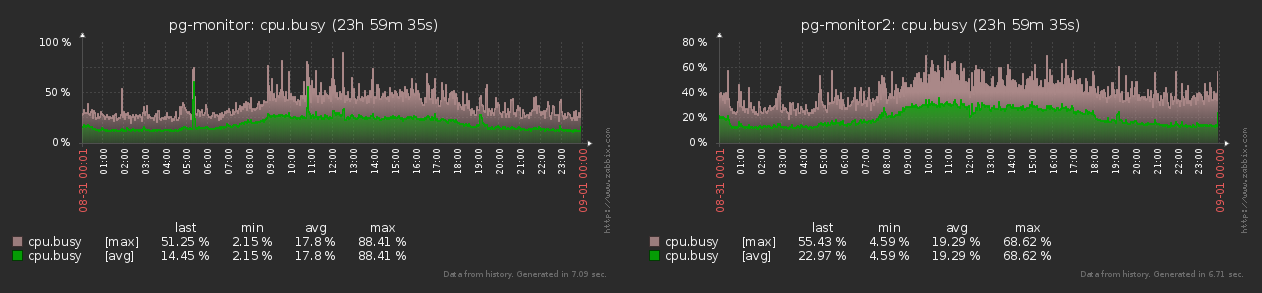
Como você pode ver no gráfico, a diferença entre os valores mín-máx do número de métricas geradas não excede 15% . Portanto, podemos considerar todos os objetos iguais nos mesmos "papagaios" .
Forte "desequilíbrio" entre objetos
Ao contrário do modelo anterior, os hosts monitorados estão longe de ser homogêneos para os coletores de log .
Por exemplo, um host pode gerar um milhão de planos por dia no log, outras dezenas de milhares e alguns - mesmo apenas alguns. E os próprios planos são muito diferentes em termos de volume e complexidade e em termos de distribuição ao longo do dia. Acontece que a carga "treme" fortemente , às vezes:

Bem, como a carga pode mudar tanto, então você precisa aprender como administrá-la ...
Coordenador
Nós imediatamente entendemos que obviamente precisamos escalar o sistema coletor, uma vez que um nó separado com toda a carga algum dia não conseguirá mais suportar. E para isso precisamos de um coordenador - alguém que administrará todo o zoológico.
Acontece algo assim:

Cada trabalhador sua carga "em papagaios" e como uma porcentagem da CPU redefine periodicamente o mestre, aqueles - para o coletor. E ele, com base nesses dados, pode emitir um comando como "colocar um novo host em um trabalhador descarregado # 4" ou "o hostA deve ser transferido para o trabalhador # 3" .
Aqui você também precisa se lembrar que, ao contrário dos objetos de monitoramento, os próprios coletores não têm "potência" igual - por exemplo, em um você pode ter 8 núcleos de CPU, e no outro - apenas 4, e até mesmo uma frequência menor. E se você carregá-los com tarefas "igualmente", o segundo começará a "calar a boca" e o primeiro ficará inativo. Daí segue ...
Tarefas do coordenador
Na verdade, há apenas uma tarefa - garantir a distribuição mais uniforme de toda a carga (em% cpu) entre todos os trabalhadores disponíveis. Se pudermos resolver isso perfeitamente, então a uniformidade da distribuição da% cpu-load sobre os coletores será obtida “automaticamente”.
É claro que mesmo que cada objeto gere a mesma carga, com o tempo, alguns deles podem "morrer" e alguns novos aparecem. Portanto, você precisa ser capaz de gerenciar toda a situação de forma dinâmica e manter um equilíbrio constante .
Balanceamento dinâmico
Podemos resolver um problema simples (zabbix) de maneira bastante trivial:
- calculamos a capacidade relativa de cada coletor "em tarefas"
- divida todas as tarefas entre eles proporcionalmente
- nós distribuímos uniformemente entre os trabalhadores

Mas o que fazer no caso de objetos "fortemente desiguais", como para um coletor de logs? ..
Avaliação de uniformidade
Acima, usamos o termo " distribuição maximamente uniforme " o tempo todo , mas como você pode comparar formalmente duas distribuições, qual delas é "mais uniforme"?
Para avaliar a uniformidade em matemática, existe há muito o que se chama de desvio padrão . Quem tem preguiça de ler:
S[X] = sqrt( sum[ ( x - avg[X] ) ^ 2 of X ] / count[X] )Como o número de trabalhadores em cada um dos coletores também pode diferir para nós, a distribuição da carga deve ser normalizada não apenas entre eles, mas também entre os coletores como um todo .
Ou seja, a distribuição da carga pelos trabalhadores dos dois catadores
[ (10%, 10%, 10%, 10%, 10%, 10%) ; (20%) ]também não é muito boa, já que o primeiro acaba sendo 10% , e o segundo - 20% , o que, por assim dizer, é o dobro em termos relativos.
Portanto, apresentamos uma única distância métrica para uma estimativa geral de "uniformidade":
d([%wrk], [%col]) = sqrt( S[%wrk] ^ 2 + S[%col] ^ 2 )Modelagem
Se tivéssemos alguns objetos, poderíamos "decompor" pela força bruta entre os trabalhadores de forma que a métrica fosse mínima . Mas temos milhares de objetos, então esse método não funcionará. Mas sabemos que o coletor pode "mover" um objeto de um trabalhador para outro - vamos modelar essa opção usando o método gradiente descendente .
É claro que podemos não encontrar o mínimo “ideal” da métrica, mas o local é certo. E a carga em si pode variar tanto ao longo do tempo que não há absolutamente nenhuma necessidade de buscar um "ideal" por um tempo infinito .
Ou seja, só temos que determinar qual objeto e para qual trabalhador é mais eficiente "mover". E vamos torná-lo uma modelagem exaustiva e trivial:
- ( host, worker)
- host worker' «»
«» . - « »
- d «»
Alinhamos todos os pares em ordem crescente da métrica . Idealmente, devemos sempre implementar a transferência do primeiro par, pois ela fornece a métrica alvo mínima. Infelizmente, na realidade, o próprio processo de transferência "custa recursos", portanto, você não deve executá-lo para o mesmo objeto com mais freqüência do que um determinado intervalo de "resfriamento" .
Nesse caso, podemos pegar o segundo, terceiro, ... par por classificação - se apenas a métrica alvo diminuiria em relação ao valor atual.
Se não há onde diminuir - aqui é um mínimo local!
Exemplo na foto:

Não é necessário iniciar as iterações "por completo". Por exemplo, você pode fazer uma análise de carga média em um intervalo de 1 minuto e, após a conclusão, fazer uma única transferência.
Micro-otimizações
É claro que um algoritmo com complexidade
T() x W()não é muito bom. Mas nele você não deve esquecer de aplicar algumas otimizações mais ou menos óbvias que podem acelerá-lo significativamente.
Zero "papagaios"
Se um objeto / tarefa / host gerou uma carga de "0 peças" no intervalo medido , então não é algo que pode ser movido para algum lugar - nem mesmo precisa ser considerado e analisado.
Autotransferência
Ao gerar pares, não há necessidade de avaliar a eficiência de transferência de um objeto para o mesmo trabalhador , onde ele já está localizado. Afinal, já será
T x (W - 1)- uma bagatela, mas legal!
Carga indiscernível
Uma vez que estamos modelando a transferência da carga e o objeto é apenas uma ferramenta, não adianta tentar transferir a% cpu "idêntica" - os valores das métricas permanecerão exatamente os mesmos, embora para uma distribuição diferente de objetos.
Ou seja, basta avaliar um único modelo para a tupla (wrkSrc, wrkDst,% cpu) . Bem, e você pode considerar “igual”, por exemplo, valores de% cpu que correspondem até 1 casa decimal.
Implementação de exemplo de JavaScript
var col = {
'c1' : {
'wrk' : {
'w1' : {
'hst' : {
'h1' : 5
, 'h2' : 1
, 'h3' : 1
}
, 'cpu' : 80.0
}
, 'w2' : {
'hst' : {
'h4' : 1
, 'h5' : 1
, 'h6' : 1
}
, 'cpu' : 20.0
}
}
}
, 'c2' : {
'wrk' : {
'w1' : {
'hst' : {
'h7' : 1
, 'h8' : 2
}
, 'cpu' : 100.0
}
, 'w2' : {
'hst' : {
'h9' : 1
, 'hA' : 1
, 'hB' : 1
}
, 'cpu' : 50.0
}
}
}
};
// ""
let $iv = (obj, fn) => Object.values(obj).forEach(fn);
let $mv = (obj, fn) => Object.values(obj).map(fn);
// initial reparse
for (const [cid, c] of Object.entries(col)) {
$iv(c.wrk, w => {
w.hst = Object.keys(w.hst).reduce((rv, hid) => {
if (typeof w.hst[hid] == 'object') {
rv[hid] = w.hst[hid];
return rv;
}
// ,
if (w.hst[hid]) {
rv[hid] = {'qty' : w.hst[hid]};
}
return rv;
}, {});
});
c.wrk = Object.keys(c.wrk).reduce((rv, wid) => {
// ID -
rv[cid + ':' + wid] = c.wrk[wid];
return rv;
}, {});
}
//
let S = col => {
let wsum = 0
, wavg = 0
, wqty = 0
, csum = 0
, cavg = 0
, cqty = 0;
$iv(col, c => {
$iv(c.wrk, w => {
wsum += w.cpu;
wqty++;
});
csum += c.cpu;
cqty++;
});
wavg = wsum/wqty;
wsum = 0;
cavg = csum/cqty;
csum = 0;
$iv(col, c => {
$iv(c.wrk, w => {
wsum += (w.cpu - wavg) ** 2;
});
csum += (c.cpu - cavg) ** 2;
});
return [Math.sqrt(wsum/wqty), Math.sqrt(csum/cqty)];
};
// -
let distS = S => Math.sqrt(S[0] ** 2 + S[1] ** 2);
//
let iterReOrder = col => {
let qty = 0
, max = 0;
$iv(col, c => {
c.qty = 0;
c.cpu = 0;
$iv(c.wrk, w => {
w.qty = 0;
$iv(w.hst, h => {
w.qty += h.qty;
});
w.max = w.qty * (100/w.cpu);
c.qty += w.qty;
c.cpu += w.cpu;
});
c.cpu = c.cpu/Object.keys(c.wrk).length;
c.max = c.qty * (100/c.cpu);
qty += c.qty;
max += c.max;
});
$iv(col, c => {
c.nrm = c.max/max;
$iv(c.wrk, w => {
$iv(w.hst, h => {
h.cpu = h.qty/w.qty * w.cpu;
h.nrm = h.cpu * c.nrm;
});
});
});
// ""
console.log(S(col), distS(S(col)));
//
let wrk = {};
let hst = {};
for (const [cid, c] of Object.entries(col)) {
for (const [wid, w] of Object.entries(c.wrk)) {
wrk[wid] = {
wid
, cid
, 'wrk' : w
, 'col' : c
};
for (const [hid, h] of Object.entries(w.hst)) {
hst[hid] = {
hid
, wid
, cid
, 'hst' : h
, 'wrk' : w
, 'col' : c
};
}
}
}
// worker
let move = (col, hid, wid) => {
let w = wrk[wid]
, h = hst[hid];
let wsrc = col[h.cid].wrk[h.wid]
, wdst = col[w.cid].wrk[w.wid];
wsrc.cpu -= h.hst.cpu;
wsrc.qty -= h.hst.qty;
wdst.qty += h.hst.qty;
// "" CPU
if (h.cid != w.cid) {
let csrc = col[h.cid]
, cdst = col[w.cid];
csrc.qty -= h.hst.qty;
csrc.cpu -= h.hst.cpu/Object.keys(csrc.wrk).length;
wsrc.hst[hid].cpu = h.hst.cpu * csrc.nrm/cdst.nrm;
cdst.qty += h.hst.qty;
cdst.cpu += h.hst.cpu/Object.keys(cdst.wrk).length;
}
wdst.cpu += wsrc.hst[hid].cpu;
wdst.hst[hid] = wsrc.hst[hid];
delete wsrc.hst[hid];
};
// (host, worker)
let moveCheck = (orig, hid, wid) => {
let w = wrk[wid]
, h = hst[hid];
// -
if (h.wid == w.wid) {
return;
}
let col = JSON.parse(JSON.stringify(orig));
move(col, hid, wid);
return S(col);
};
// (hsrc,hdst,%cpu)
let checked = {};
// ( -> )
let moveRanker = col => {
let currS = S(col);
let order = [];
for (hid in hst) {
for (wid in wrk) {
// ( 0.1%) ""
let widsrc = hst[hid].wid;
let idx = widsrc + '|' + wid + '|' + hst[hid].hst.cpu.toFixed(1);
if (idx in checked) {
continue;
}
let _S = moveCheck(col, hid, wid);
if (_S === undefined) {
_S = currS;
}
checked[idx] = {
hid
, wid
, S : _S
};
order.push(checked[idx]);
}
}
order.sort((x, y) => distS(x.S) - distS(y.S));
return order;
};
let currS = S(col);
let order = moveRanker(col);
let opt = order[0];
console.log('best move', opt);
//
if (distS(opt.S) < distS(currS)) {
console.log('move!', opt.hid, opt.wid);
move(col, opt.hid, opt.wid);
console.log('after move', JSON.parse(JSON.stringify(col)));
return true;
}
else {
console.log('none!');
}
return false;
};
// -
while(iterReOrder(col));Como resultado, a carga em nossos reservatórios é distribuída quase igualmente em cada momento do tempo, nivelando prontamente os picos emergentes: