- Boa noite, meu nome é Masha, trabalho no departamento de análise de dados da Eddila e hoje temos uma palestra sobre testes com você.

Primeiro, discutiremos com você quais tipos de teste existem em geral e tentarei convencê-lo de por que você precisa escrever testes. A seguir falaremos sobre o que temos em Python para trabalhar diretamente com testes, com sua escrita e módulos auxiliares. No final, contarei um pouco sobre a IC - uma parte inevitável da vida em uma grande empresa.
Eu gostaria de começar com um exemplo. Vou tentar explicar com exemplos muito assustadores por que vale a pena escrever testes.
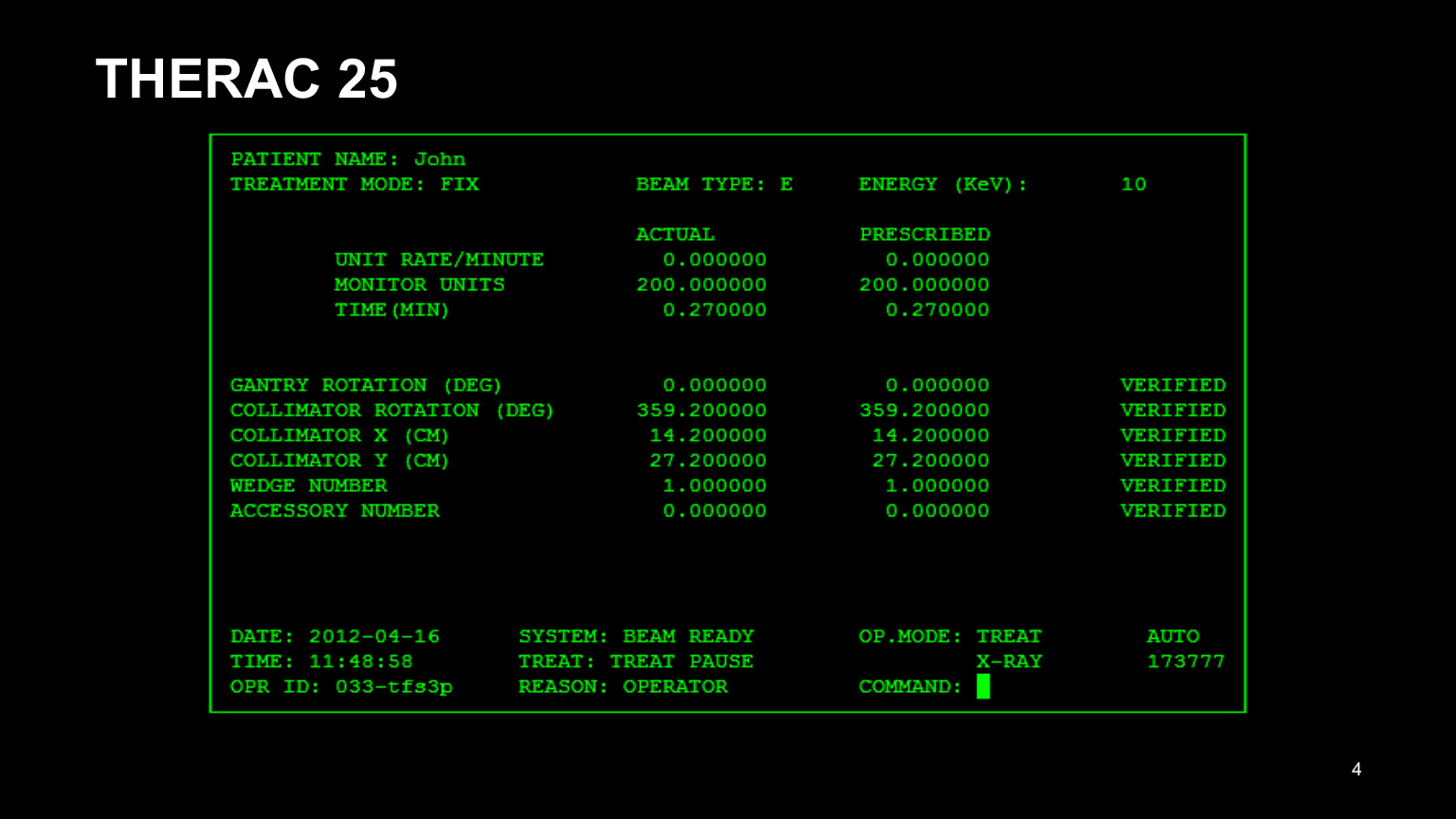
Aqui está a interface do programa THERAC 25. Esse era o nome do dispositivo para terapia de radiação de pacientes com câncer, e tudo deu muito errado com ele. Em primeiro lugar, ele tinha uma interface ruim. Olhando para ele já dá para perceber que ele não é muito bom: era inconveniente para os médicos dirigirem em todos esses números. Como resultado, eles copiaram os dados do prontuário do paciente anterior e tentaram editar apenas o que precisava ser editado.
É claro que eles se esqueceram de corrigir a metade e se enganaram. Como resultado, os pacientes foram tratados incorretamente. A IU também vale a pena ser testada, nunca há muitos testes.
Mas, além da interface ruim, havia muitos outros problemas no back-end. Eu identifiquei dois que me pareceram os mais flagrantes:
- . , . , . , .
- C . THERAC , — , . . , , , - , - — .
Valeria a pena escrever testes. Porque acabou com cinco mortes registradas, e não está claro quantas pessoas mais sofreram por receber drogas em excesso.

Há outro exemplo de que, em algumas situações, escrever testes pode economizar muito dinheiro. Este é o Mars Climate Orbiter - um dispositivo que deveria medir a atmosfera de Marte, para ver o que estava acontecendo lá com o clima.
Mas o módulo, que estava no solo, dava comandos no sistema SI, no sistema métrico. E o módulo em órbita de Marte pensou que era um sistema britânico de medidas, interpretou incorretamente.
Como resultado, o módulo entrou na atmosfera no ângulo errado e desabou. 125 milhões de dólares acabaram de ir para o lixo, embora pareça que é possível simular a situação em testes e evitar isso. Mas não deu certo.
Agora vou falar sobre motivos mais prosaicos pelos quais você deve escrever testes. Vamos falar sobre cada item separadamente:
- Os testes garantem que o código funciona e o acalmam um pouco. Nos casos em que você escreveu testes, pode ter certeza de que o código funciona - se, é claro, você o escreveu bem. Durma melhor. É muito importante.
- . . , , , . , . , .
, - , — , - . , . , , . , , , git blame, , , , . - . , . , . , , . - - , - - . , , , . - .
- , . ? , , , , : , . 500 -, . . .
- : — . , , . , , .
, , , . , , . - . — , . , , . , .
: - . , , . , , , - , .
Agora gostaria de falar um pouco sobre quais são as classificações dos tipos de teste. Existem muitos deles. Mencionarei apenas alguns.
O processo de teste é dividido em teste de caixa preta, teste de branco e cinza.
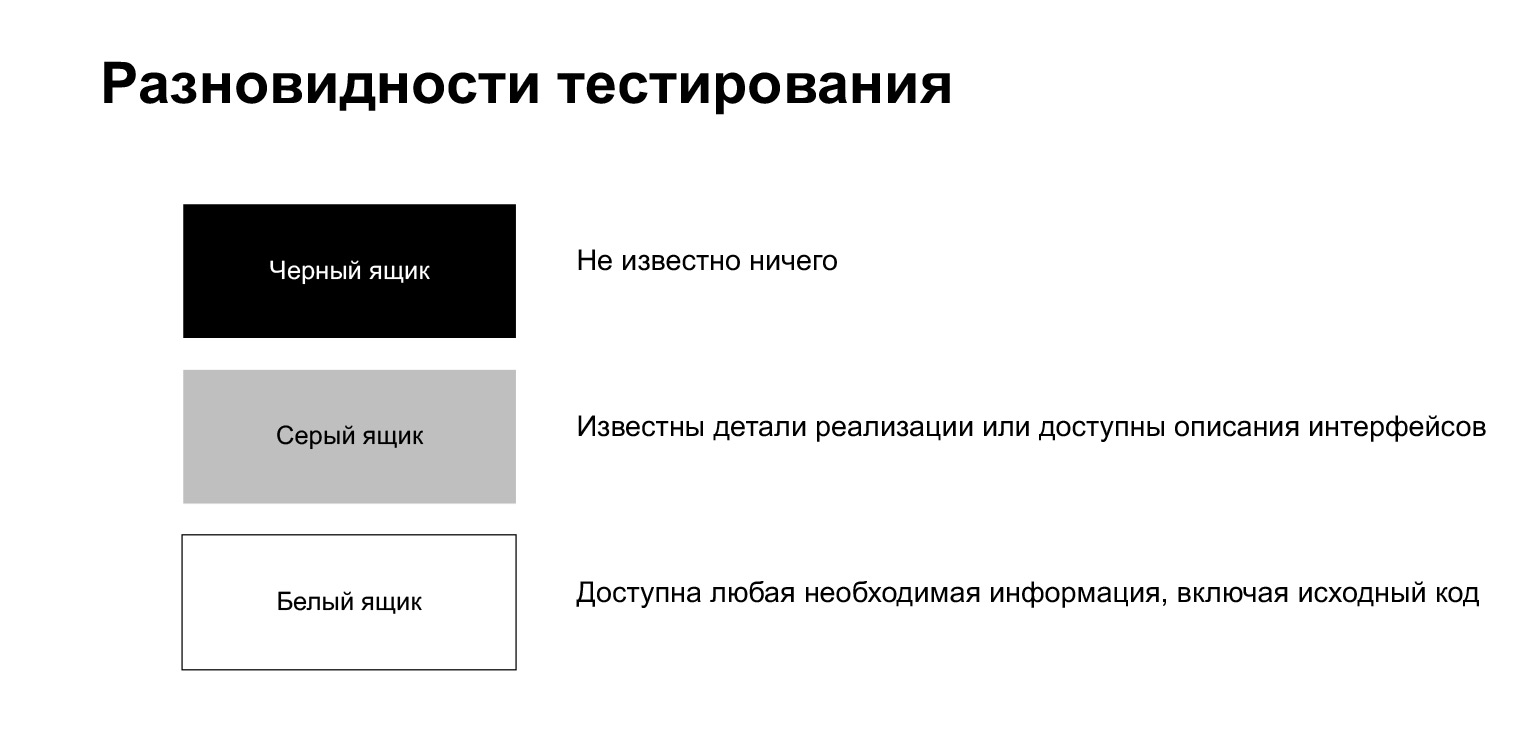
O teste de caixa preta é um processo em que o testador não sabe nada sobre o que está dentro. Ele, como um usuário comum, faz algo sem conhecer nenhuma especificação de implementação.
O teste de caixa branca significa que o testador tem acesso a todas as informações de que precisa, incluindo o código-fonte. Estamos nessa situação quando escrevemos um teste em nosso próprio código.
O teste da caixa cinza é algo intermediário. É quando você conhece alguns detalhes da implementação, mas não tudo.
Além disso, o processo de teste pode ser dividido em manual, semiautomático e automático. O teste manual é feito por uma pessoa. Digamos que ele clica em botões do navegador, clica em algum lugar, olha para ver o que está quebrado ou não quebrado. O teste semiautomático ocorre quando um testador executa scripts de teste. Podemos dizer que estamos em tal situação quando executamos e executamos nossos testes localmente. O teste automatizado não envolve a participação humana: os testes devem ser executados automaticamente, não manualmente.
Além disso, os testes podem ser divididos por nível de detalhe. Aqui, eles geralmente são divididos em testes de unidade e integração. Pode haver discrepâncias. Existem pessoas que chamam qualquer teste de unidade de autoteste. Mas uma divisão mais clássica é algo assim.
Os testes de unidade verificam o funcionamento de componentes individuais do sistema e os testes de integração verificam o pacote de alguns módulos. Às vezes, também há testes de sistema que verificam a operação de todo o sistema como um todo. Mas parece que esta é mais uma grande variante dos testes de integração.
Os testes para nosso código são testes de unidade e integração. Existem pessoas que acreditam que apenas testes de integração devem ser escritos. Eu não sou um desses, acho que tudo deve ser com moderação, e ambos os testes de unidade, quando você está testando um componente, e os testes de integração, quando você está testando algo grande, são úteis.
Por que eu acho isso? Porque os testes de unidade geralmente são mais rápidos. Quando você precisar ajustar algo, ficará muito irritado ao clicar no botão "executar teste" e esperar três minutos para que o banco de dados inicie, as migrações são feitas, algo mais acontece. Para esses casos, os testes de unidade são úteis. Eles podem ser executados de forma rápida e conveniente, um de cada vez. Mas depois de corrigir os testes de unidade, ótimo, vamos corrigir os testes de integração.
Os testes de integração também são uma coisa muito necessária, uma grande vantagem é que eles são mais sobre o sistema. Outra grande vantagem: eles são mais resistentes à refatoração de código. Se for mais provável que você reescreva alguma função pequena, é improvável que mude o pipeline geral com a mesma frequência.

Existem muitas outras classificações diferentes. Repassarei rapidamente o que escrevi aqui, mas não me deterei em detalhes, são palavras que você pode ouvir em outro lugar.
Os testes de fumaça são testes de funcionalidade crítica, os primeiros e mais simples testes. Se eles quebrarem, você não precisará mais testar, mas será necessário corrigi-los. Digamos que o aplicativo tenha iniciado, não travou - ótimo, o teste de fumaça passou.
Existem testes de regressão - testes para funcionalidades antigas. Digamos que você lance uma nova versão e deve verificar se nada estava quebrado na antiga. Essa é a tarefa dos testes de regressão.
Existem testes de compatibilidade, testes de instalação. Eles verificam se tudo funciona corretamente para você em diferentes sistemas operacionais e diferentes versões de sistemas operacionais, em diferentes navegadores e diferentes versões de navegadores.
Os testes de aceitação são testes de aceitação. Já falei sobre eles, eles falam sobre se sua mudança pode ser colocada em produção ou não.
Também há testes alfa e beta. Ambos os conceitos estão mais relacionados ao produto. Normalmente, quando você tem uma versão mais ou menos finalizada do lançamento, mas nem tudo está consertado lá, você pode dar para pessoas externas condicionalmente ou para pessoas externas, voluntários, para que eles encontrem bugs para você, relatem-nos e você possa lançar uma versão muito boa. Quanto menos acabada é a versão alfa, mais acabada é a beta. No teste beta, quase tudo deve estar bem agora.
Depois, há testes de desempenho e estresse, teste de carga. Eles verificam, por exemplo, como seu aplicativo está lidando com a carga. Existe algum código. Você calculou quantos usuários, solicitações isso terá, qual RPS, quantas solicitações virão por segundo. Simulamos essa situação, lançamos, olhamos - aguenta, não segura. Se não segurar, pense no que fazer a seguir. Talvez para otimizar o código ou aumentar a quantidade de hardware, existem diferentes soluções.
Os testes de estresse são quase os mesmos, apenas a carga é maior do que o esperado. Se os testes de desempenho fornecerem a carga que você espera, nos testes de estresse você poderá aumentar a carga até que ela quebre.
Os linters estão separados aqui. Falarei sobre linters um pouco mais tarde, são testes de formatação de código, um guia de estilo. Em Python, temos sorte de ter PEP8, um guia de estilo simples que todos deveriam seguir. E quando você escreve algo, geralmente acha difícil seguir o código. Suponha que você tenha esquecido de colocar uma linha em branco, ou fez uma linha extra, ou deixou uma linha muito longa. Isso atrapalha, porque você se acostuma com o fato de que seu código é escrito no mesmo estilo. Os linters permitem que você capture automaticamente essas coisas.
Com a teoria, tudo, então irei falar sobre o que tem em Python.

Aqui está uma lista de algumas das bibliotecas. Não vou entrar em detalhes sobre todos eles, mas vou falar sobre a maioria deles. Claro, vamos falar sobre unittest e pytest. Essas são bibliotecas usadas diretamente para escrever testes. Mock é uma biblioteca auxiliar para a criação de objetos fictícios. Também falaremos sobre ela. doctest é um módulo para testar a documentação, flake8 é um linter, também vamos dar uma olhada neles. Não vou falar sobre pilama e tox. Se você estiver interessado, pode ver por si mesmo. Pylama também é um linter, até mesmo um metalinter, pois combina várias embalagens, muito convenientes e boas. E a biblioteca tox é necessária se você precisar testar seu código em diferentes ambientes - por exemplo, com diferentes versões de Python ou com diferentes versões de bibliotecas. Tox ajuda muito nesse sentido.
Mas antes de falar sobre diferentes bibliotecas, vou começar com a banalidade. Sinta-se à vontade para usar assert em seu código. Não é uma pena. Muitas vezes ajuda a entender o que está acontecendo.

Suponha que haja uma função que calcula estatísticas ordinais, duas afirmações são escritas nela. Assert deve ser escrito em uma função nos casos em que é um absurdo completamente extremo que não deveria estar no código. Esses são casos muito extremos, provavelmente você nem mesmo os encontrará na produção. Ou seja, se você bagunçar o código, provavelmente ele falhará em seus testes.
Assert ajuda quando você está prototipando, você não tem código de produção ainda, você pode colocar assert em qualquer lugar - na função chamada, em qualquer lugar. Isso não é bom para projetos sérios, mas muito bom no estágio de prototipagem.
Digamos que você queira desativar o assert por algum motivo - por exemplo, você deseja que ele nunca seja acionado na produção. Python tem uma opção especial para isso.

Eu vou te dizer o que é doctest. Este é um módulo, uma biblioteca padrão do Python para documentação de teste. Por que isso é bom? A documentação escrita em código tende a falhar com frequência. Há uma função de brinquedo muito pequena aqui, você pode ver tudo. Mas quando você tem um código grande, muitos parâmetros, e adicionou algo no final, então com uma probabilidade muito alta você se esquecerá de corrigir as docstrings. Doctest evita essas coisas. Você conserta algo, não atualize aqui, execute o doctest e ele irá travar para você. Assim, você se lembrará do que exatamente não corrigiu, vá e corrija.
Com o que se parece? O Doctest procura essas árvores de Natal em docstrings, então as executa e compara o que é obtido.

Aqui está um exemplo de execução do doctest. Começamos, vemos que temos dois testes e um deles caiu - completamente no case. Ótimo, vimos algumas informações boas e claras sobre o erro.

Link do slide
O doctest tem algumas diretivas úteis que podem ser úteis. Não vou falar de todos eles, mas alguns que me pareciam os mais comuns, coloquei no slide. A diretiva SKIP permite que você não execute o teste no exemplo marcado. A diretiva IGNORE_EXCEPTION_DETAIL ignora o teste EXCEPTION. ELLIPSIS permite que você escreva reticências em vez de em qualquer lugar na saída. FAIL_FAST para após o primeiro teste com falha. Todo o resto pode ser lido na documentação, há muito. É melhor eu mostrar um exemplo.

Este exemplo possui uma diretiva ELLIPSIS e uma diretiva IGNORE_EXCEPTION_DETAIL. Você vê a estatística K-th ordinal na diretiva ELLIPSIS e esperamos que algo aconteça que comece com nove e termine com nove. Pode haver qualquer coisa no meio. Esse teste não falhará.
Abaixo está a diretiva IGNORE_EXCEPTION_DETAIL, ela apenas verificará o que veio no AssertionError. Veja, nós escrevemos blá, blá, blá. O teste será aprovado, não comparará blá, blá, blá com o iterável esperado como primeiro argumento. Ele apenas comparará AssertionError a AssertionError. São coisas úteis que você pode usar.

Então o plano é este: vou falar sobre o unittest, depois sobre o pytest. Direi imediatamente que provavelmente não conheço os prós do unittest, exceto que ele faz parte da biblioteca padrão. Não vejo uma situação que me obrigaria a usar o unittest agora. Mas há projetos que o utilizam, em qualquer caso é útil saber como é a sintaxe e o que é.
Outro ponto: os testes escritos em unittest sabem como executar o pytest imediatamente. Ele não se importa. (…)
Unittest é assim. Há uma aula que começa com a palavra teste. Dentro, uma função que começa com a palavra teste. A classe de teste herda de unittest.TestCase. Devo dizer imediatamente que um teste aqui está escrito corretamente e outro teste está incorreto.
O teste superior, onde a declaração normal é escrita, falhará, mas terá uma aparência estranha. Vamos dar uma olhada.

Comando de partida. Você pode escrever unittest main no próprio código, você pode chamá-lo de Python.

Executamos esse teste e vemos que ele escreveu um AssertionError, mas não escreveu onde caiu - ao contrário do próximo teste, que usou self.assertEqual. Está claramente escrito aqui: três não é igual a dois.

Deve ser consertado, é claro. Mas então essa saída mágica não era visível na tela.
Vamos dar outra olhada. No primeiro caso, escrevemos assert, no segundo, self.assertEqual. Infelizmente, esta é a única forma de teste de unidade. Existem funções especiais - self.assertEqual, self.assertnotEqual e mais 100.500 funções que você precisa usar se quiser ver uma mensagem de erro adequada.
Por que isso acontece? Porque assert é uma instrução que recebe um bool e possivelmente uma string, mas neste caso bool. E ele vê que tem verdadeiro ou falso, e ele não tem nenhum lugar para tomar os lados direito e esquerdo. Portanto, o unittest tem funções especiais que exibem corretamente as mensagens de erro.
Isso não é muito conveniente na minha opinião. Mais precisamente, não é nada conveniente, porque esses são alguns métodos especiais que estão apenas nesta biblioteca. Eles são diferentes do que estamos acostumados na linguagem comum.

Você não precisa se lembrar disso - falaremos sobre pytest mais tarde e espero que você escreva principalmente nele. O Unittest tem um zoológico de funções para usar se você quiser testar algo e obter boas mensagens de erro.
A seguir, vamos falar sobre como escrever fixtures no unittest. Mas, para fazer isso, primeiro preciso dizer o que são luminárias. Essas são funções que são chamadas antes ou depois da execução do teste. Eles são necessários se o teste precisar realizar uma configuração especial - crie um arquivo temporário após o teste, exclua o arquivo temporário; criar um banco de dados, excluir um banco de dados; crie um banco de dados, escreva algo nele. Em geral, tanto faz. Vamos ver como fica no unittest.

Unittest possui métodos especiais setUp e tearDown para escrever um fixture. Por que eles ainda não foram escritos de acordo com o PEP8 é um grande mistério para mim. (...)
SetUp é o que é feito antes do teste, tearDown é o que é feito depois do teste. Parece-me que este é um design extremamente inconveniente. Por quê? Porque, em primeiro lugar, minha mão não se levanta para escrever esses nomes: Eu já vivo em um mundo onde ainda existe PEP8. Em segundo lugar, você tem um arquivo temporário, sobre o qual não há nada nos argumentos do próprio teste. De onde ele veio? Não está muito claro por que existe e do que se trata.
Quando temos uma pequena classe que gruda na tela, é legal, pode ser capturada com um olhar. E quando você tem esse lençol enorme, você é torturado para procurar o que era e por que ele é assim, por que ele se comporta assim.
Há outro recurso não tão conveniente com acessórios em unittest. Suponha que temos uma classe de teste que precisa de um arquivo temporário e outra classe de teste que precisa de um banco de dados. Excelente. Você escreveu uma classe, fez setUp, tearDown, criou / excluiu um arquivo temporário. Nós escrevemos outra classe, nela também escrevemos setUp, tearDown, criamos / deletamos um banco de dados nela.
Questão. Há um terceiro grupo de testes que precisa de ambos. O que fazer com tudo isso? Eu vejo duas opções. Ou pegue e copie e cole o código, mas não é muito conveniente. Ou crie uma nova classe, herde das duas anteriores, chame super. Em geral, isso funcionará também, mas parece um exagero para testes.

Portanto, quero que sua familiaridade com o unittest permaneça assim, em um nível teórico. A seguir, falaremos sobre uma maneira mais conveniente de escrever testes, uma biblioteca mais conveniente, isto é pytest.
Primeiro, tentarei explicar por que o teste pytest é conveniente.

Link do slide
Primeiro ponto: no pytest, os afirmações geralmente funcionam, aqueles com os quais você está acostumado, e fornecem informações de erro normais. Segundo: há uma boa documentação para pytest, onde um monte de exemplos são desmontados e tudo o que você quiser, tudo que você não entende pode ser visto.
Terceiro, os testes são apenas funções que começam com test_. Ou seja, você não precisa de uma classe extra, apenas escreva uma função regular, chame-a de test_ e ela será executada por meio de pytest. Isso é conveniente porque quanto mais fácil for escrever testes, maior será a probabilidade de você escrever o teste em vez de pontuá-lo.
O Pytest tem vários recursos úteis. Você pode escrever testes parametrizados, é conveniente escrever fixtures de níveis diferentes, também existem algumas sutilezas que você pode usar: xfail, raises, skip e alguns outros. Existem muitos plug-ins no pytest, além disso, você pode escrever o seu próprio.

Vamos ver um exemplo. É assim que os testes escritos em pytest se parecem. O significado é o mesmo do unittest, mas parece muito mais conciso. O primeiro teste é geralmente de duas linhas.

Execute o comando python -m pytest. Excelente. Passaram dois testes, está tudo bem, podemos ver o que passaram e em que horas.

Agora vamos interromper um teste e fazer com que tenhamos informações sobre o erro. Imprimir declaração 3 == 2 e erro. Ou seja, vemos: apesar de termos escrito um assert normal, exibimos corretamente as informações sobre o erro, embora antes disso em unittest disséssemos que o assert aceita um bool em uma string ou bool, por isso é problemático exibir informações sobre o erro.
Alguém pode se perguntar por que tudo isso funciona? Porque no pytest eles tentaram e arrumaram a parte feia da interface. O Pytest primeiro analisa seu código e ele aparece como uma espécie de estrutura de árvore, uma árvore de sintaxe abstrata. Nessa estrutura, você tem operadores nos vértices e operandos nas folhas. Assert é um operador. Ele fica no topo da árvore, e neste momento, antes de dar tudo ao intérprete, você pode substituir este assert por uma função interna que faz introspecção e entende o que está em seus lados esquerdo e direito. Na verdade, isso já é alimentado para o intérprete, com o assert substituído.
Não vou entrar em detalhes, tem um link, nele você pode ler como eles fizeram isso. Mas adoro que tudo funcione nos bastidores. o usuário não vê isso. Ele escreve assertivamente, como está acostumado, que a própria biblioteca faz o resto. Você nem mesmo precisa pensar sobre isso.
Além disso, em pytest para tipos padrão, você terá boas informações de erro de qualquer maneira. Porque o pytest sabe como exibir essas informações de erro. Mas você pode comparar tipos de dados personalizados em seu teste, por exemplo, árvores ou algo complexo, e o pytest pode não saber como exibir informações de erro para eles. Para tais casos, você pode adicionar um gancho especial - aqui está uma seção na documentação - e neste gancho escrever como as informações de erro devem ser. Tudo é muito flexível e conveniente.

Vamos ver como os acessórios ficam no pytest. Se em unittest for necessário escrever setUp e tearDown, chame aqui a função usual como quiser. Escrevemos o decorador pytest.fixture no topo - ótimo, é um acessório.
E aqui não é o exemplo mais simples. O aparelho pode apenas fazer um retorno, retornar algo, será análogo ao setUp. Nesse caso, ele fará uma espécie de tearDown, ou seja, bem aqui, após o término do teste, ele chamará o close, e o arquivo temporário será deletado.
Parece conveniente. Você tem uma função arbitrária que pode nomear como quiser. Você o passa explicitamente para o teste. Passado preenchido, você sabe o que é. Nada de especial é exigido de você. Em geral, use-o. Isso é muito mais conveniente do que o teste unitário.

Um pouco mais sobre acessórios. No pytest é muito fácil criar luminárias de escopos diferentes. Por padrão, o aparelho é criado com o nível de função. Isso significa que ele será chamado para cada teste no qual você passou. Ou seja, se houver rendimento ou algo como tearDown, isso também acontecerá após cada teste.
Você pode declarar scope = 'module' e então o fixture será executado uma vez por módulo. Digamos que você deseja criar um banco de dados uma vez e não deseja excluir e rolar todas as migrações após cada teste.
Também em fixtures é possível especificar o argumento autouse = True, e então o fixture será chamado independentemente de você ter solicitado ou não. Parece que essa opção nunca deve ser usada, ou deve ser, mas com muito cuidado, porque é uma coisa implícita. É melhor evitar o implícito.

Executamos este código - vamos ver o que aconteceu. Existe um teste que depende do aparelho, me chame uma vez, use quando necessário, me ligue sempre. Ao mesmo tempo, ligue-me uma vez para usar quando necessário um acessório de nível de módulo. Vemos que na primeira vez que chamamos fixtures me chame uma vez use quando precisar, me chame toda vez, que dá a saída, mas o fixture com autouse também foi chamado, porque não importa, é sempre chamado.
O segundo teste depende dos mesmos acessórios. Vemos que na segunda vez que me chamamos uma vez use quando necessário não foi impresso, porque está no nível do módulo, já foi chamado uma vez e não será chamado novamente.
Além disso, a partir deste exemplo, você pode ver que o pytest não tem os problemas que falamos em unittest, quando em um teste você pode precisar de um banco de dados, em outro - um arquivo temporário. Como agregá-los normalmente não está claro. Aqui está a resposta a esta pergunta no pytest. Se dois jogos forem aprovados, haverá dois jogos dentro.
Excelente, muito confortável, sem problemas. As luminárias são muito flexíveis e podem depender de outras luminárias. Não há contradição nisso, e pytest irá chamá-los na ordem correta.

Na verdade, internamente você pode herdar luminárias de outras luminárias, torná-las diferentes em escopo e autouse sem autouse. Ele mesmo os organizará na ordem correta e os chamará.
Aqui temos o primeiro teste, o teste um, que depende de rare_dependency_for_test_one, onde este fixture depende de outro fixture - e mais um. Vamos ver o que acontece no escapamento.
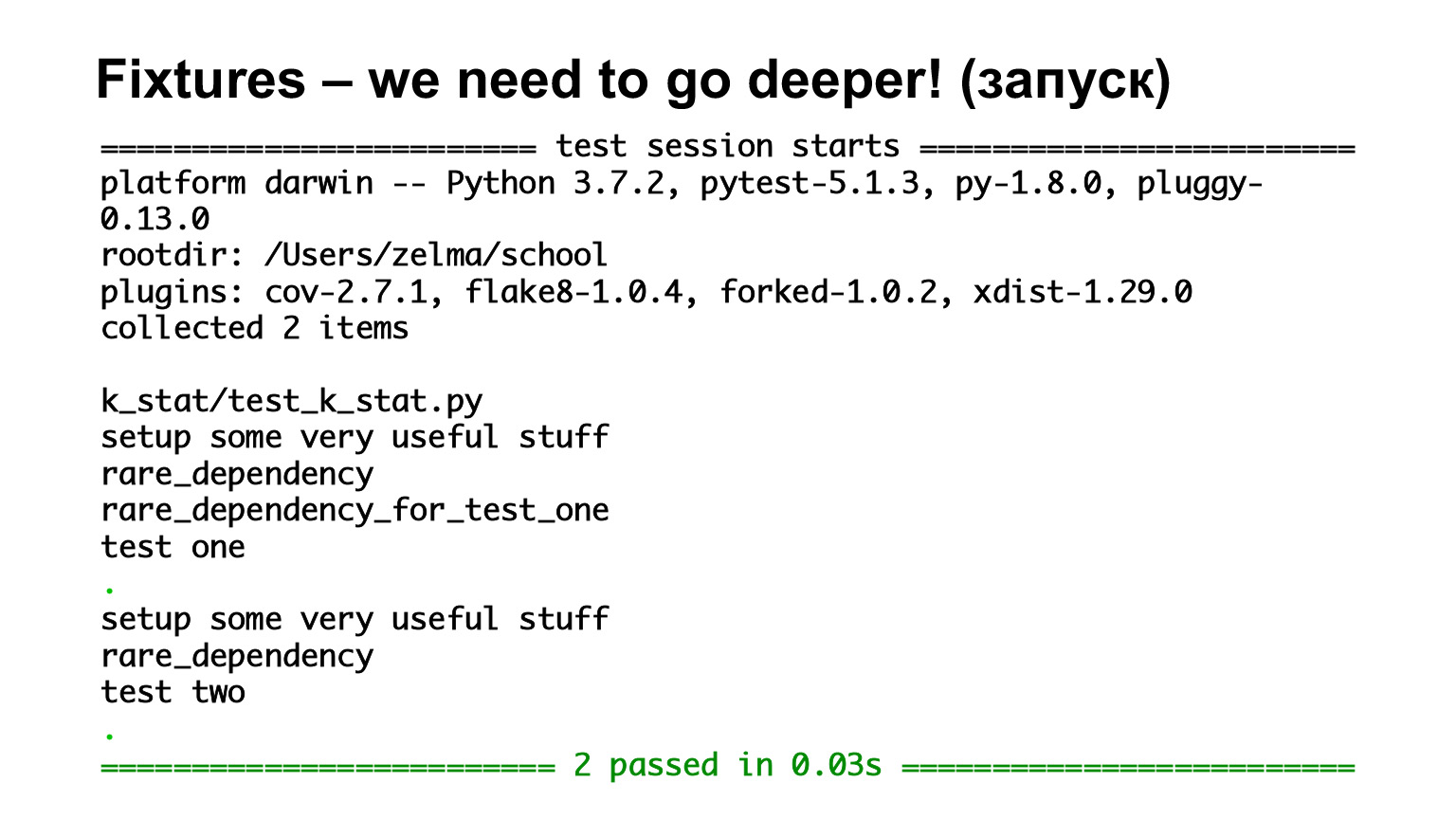
Vimos que eles são chamados por ordem de herança. Existem todos os acessórios de nível de função, portanto, todos são chamados para cada teste. O segundo teste depende de rara_dependência e rara_dependência depende de alguma_dependência_common. Olhamos para o escapamento e vemos que duas luminárias foram acionadas antes do teste.
O Pytest tem um arquivo de configuração especial conftest.py onde você pode colocar todos os acessórios, e é bom se você colocá-lo: geralmente, quando uma pessoa olha o código de outra pessoa, ela geralmente vai olhar os acessórios no conftest.
Não é obrigatório. Se houver um acessório que você só precisa neste arquivo, e você sabe com certeza que é específico, estritamente aplicável e não vai precisar dele em outro arquivo, então você pode declará-lo no arquivo. Ou crie muitos conftests e todos trabalharão em níveis diferentes.

Vamos falar sobre os recursos que estão no pytest. Como falei, é muito fácil parametrizar testes. Aqui, vemos um teste que possui três conjuntos de parâmetros: duas entradas e um que é esperado. Nós os passamos para os argumentos da função e vemos se o que passamos para a entrada corresponde ao que é esperado.

Vamos ver como fica. Vemos que existem três testes. Ou seja, pytest pensa que são três testes. Dois passaram, um caiu. O que há de bom aqui? Para o teste que caiu, vemos os argumentos, vemos em qual conjunto de parâmetros ele caiu.
Novamente, quando você tem uma função pequena e parametrizar diz três, você pode ver com seus olhos o que exatamente caiu. Mas quando há muitos conjuntos de parâmetros, você não os verá com os olhos. Em vez disso, você verá, mas será muito difícil para você. E é muito conveniente que o pytest exiba tudo dessa forma - você pode ver imediatamente em qual caso o teste falhou.

Parametrizar é uma coisa boa. E quando você escreveu um teste uma vez e depois fez muitos, muitos conjuntos de parâmetros, esta é uma boa prática. Não fazendo muitas variantes de código para testes semelhantes, mas escrevendo um teste uma vez e, em seguida, criando um grande conjunto de parâmetros, e ele funcionará.
Existem muito mais coisas úteis no pytest. Se você falar sobre eles, a palestra claramente não é suficiente, então vou mostrar, novamente, apenas alguns. O primeiro teste usa pytest.raises () para mostrar que você está esperando uma exceção. Ou seja, neste caso, se um AssertionError for gerado, o teste será aprovado. Você deve ter uma exceção lançada.
A segunda coisa útil é o xfail. É um decorador que permite que o teste falhe. Digamos que você tenha muitos testes, muito código. Você refatorou algo, o teste começou a falhar. Ao mesmo tempo, você entende que ou não é crítico ou será muito caro consertá-lo. E você fica assim: tá bom, vou pendurar um decorador nele, vai ficar verde, depois vou consertar. Ou suponha que o teste começou a inundar. É claro que se trata de um acordo com a própria consciência, mas às vezes é necessário. Além disso, xfail neste formato ficará verde, independentemente de o teste ter caído ou não. Você ainda pode passá-lo para o parâmetro Strict = True, então será uma situação um pouco diferente, o pytest esperará que o teste falhe. Se o teste for bem-sucedido, uma mensagem de erro será retornada e vice-versa.
Outra coisa útil é skipif. Há apenas um salto que não executa os testes. E há skipif. Se você passar o mouse sobre este decorador, o teste não será executado sob certas condições.
Neste caso, está escrito que se eu tiver uma plataforma Mac, então não inicie, porque o teste por algum motivo cai. Acontece. Mas, em geral, existem testes específicos da plataforma que sempre falharão em uma plataforma específica. Então isso é útil.

Vamos começar. Vimos a letra X, vimos S. X temos refere-se a xfail, S - a skipif. Ou seja, pytest mostra qual teste perdemos completamente e qual executamos, mas não olhamos para o resultado.

Existem muitas opções úteis diferentes no próprio pytest. Eu, claro, não poderei exibi-los aqui, você pode ver na documentação. Mas vou falar sobre alguns.
Aqui está uma opção útil --collect-only. Ele exibe uma lista de testes encontrados. Existe uma opção -k - filtrar por nome de teste. Esta é uma das minhas opções favoritas: se um teste falhar, especialmente se for complexo e você não souber como corrigi-lo ainda, filtre-o e execute-o.
Você quer economizar tempo e provavelmente não se divertir executando 15 outros testes - você sabe que eles passam ou falham, mas ainda não os fez. Execute o teste que trava, corrija e siga em frente.
Também existe uma opção muito boa -s, que ativa a saída de stdout e stderr em testes. Por padrão, pytest produzirá apenas stdout e stderr para testes com falha. Mas há momentos, geralmente no estágio de depuração, em que você deseja gerar algo no teste e não sabe se o teste irá falhar. Pode não cair, mas você quer ver no próprio teste o que vem lá e sai. Então execute com -s e você verá o que deseja.
-v é a opção detalhada padrão, aumenta a verbosidade.
--lf, --last-failed é uma opção que permite reiniciar apenas os testes que falharam na última execução. --sw, --stepwise também são funções úteis como -k. Se você reparar os testes sequencialmente, então você executa com --stepwise, ele passa pelos verdes e, assim que vê o teste que falhou, ele para. E quando você executa --sw novamente, ele começa com este teste que travou. Se cair novamente, parará de novo; se não cair, continuará até a próxima queda.

Link do slide
Em pytest, há um arquivo de configuração principal pytest.ini. Nele, você pode alterar o comportamento padrão do pytest. Eu dei aqui as opções que são freqüentemente encontradas no arquivo de configuração.
Testpaths são os caminhos que o pytest pesquisará para os testes. addopts é o que é adicionado à linha de comando na inicialização. Aqui eu adicionei flake8 e plug-ins de cobertura aos addopts. Veremos eles um pouco mais tarde.

Link do slide
Existem muitos plug-ins diferentes no pytest. Eu escrevi aqueles que, novamente, são usados em todos os lugares. flake8 é um linter, a cobertura é a cobertura de código por testes. Depois, há um conjunto completo de plug-ins que tornam mais fácil trabalhar com certos frameworks: pytest-flask, pytest-django, pytest-twisted, pytest-tornado. Provavelmente há algo mais.
O plugin xdist é usado se você deseja executar testes em paralelo. O plug-in de tempo limite permite limitar o tempo de execução do teste: isso é útil. Você desliga um decorador de tempo limite no teste e, se o teste demorar mais, ele falhará.

Vamos dar uma olhada. Eu adicionei cobertura e flake8 ao pytest.ini. A cobertura me deu um relatório, eu tenho um arquivo com testes lá, algo dele não chamou, mas tudo bem :)
Aqui está o arquivo k_stat.py, ele contém até cinco declarações. Isso é quase o mesmo que cinco linhas de código. E a cobertura é de 100%, mas isso porque meu arquivo é muito pequeno.
Na verdade, a cobertura geralmente não é de cem por cento e, além disso, não deve ser alcançada por todos os meios. Subjetivamente, parece que a cobertura do teste de 60-70% é suficiente e normal para o trabalho.
A cobertura é uma métrica tão grande que, mesmo sendo cem por cento, não quer dizer que você é ótimo. O fato de você ter chamado este código não significa que você verificou algo. Você também pode escrever assert True no final. Você precisa abordar a cobertura de forma razoável, para 100% de cobertura de teste existem desvanecimento e robôs, mas as pessoas não precisam fazer isso.
Em pytest.ini, conectei mais um plugin. Aqui você pode ver --flake8, este é o linter que mostra meus erros de estilo, e alguns outros, não do PEP8, mas dos pyflakes.

Aqui no escapamento está escrito o número do erro no PEP8 ou nos pyflakes. Em geral, tudo é claro. A linha é muito longa, para redefinição você precisa de duas linhas em branco, você precisa de uma linha em branco no final do arquivo. No final, diz que CitizenImport não é usado para mim. Em geral, os linters permitem que você capture erros grosseiros e erros no design do código.

Já falamos sobre o plugin de tempo limite, ele permite limitar o tempo de execução do teste. Para alguns perftests, o tempo de execução é importante. E você pode limitá-lo nos testes com time.time e timeit. Ou usando o plugin de tempo limite, que também é muito conveniente. Se o teste funcionar muito, ele pode ser traçado de maneiras diferentes, por exemplo cProfile, mas Yura falará sobre isso em sua palestra .
Se você usa um IDE e vale a pena usar ferramentas auxiliares, tenho aqui, em particular, o PyCharm, então os testes são muito fáceis de executar diretamente dele.

Resta falar sobre simulação. Digamos que temos o módulo A, queremos testá-lo e existem outros módulos que não queremos testar. Um deles vai para a rede, o outro para o banco de dados, e o terceiro é um módulo simples que não nos incomoda de forma alguma. Nesses casos, o mock vai nos ajudar. Novamente, se estivermos escrevendo um teste de integração, provavelmente apresentaremos um banco de dados de teste, escreveremos um cliente de teste e isso também está bom. É apenas um teste de integração.
Há momentos em que queremos fazer um teste de unidade, quando queremos testar apenas uma peça. Então, precisamos de uma simulação.

Mock é uma coleção de objetos que podem ser usados para substituir o objeto real. Em qualquer chamada a métodos, atributos, ele também retorna mock.

Neste exemplo, temos um módulo simples. Vamos deixá-lo e substituir alguns outros mais complexos por simulados. Agora veremos como funciona.

É mostrado aqui claramente. Nós importamos, dizemos que m é uma imitação. Chamado de volta mock. Eles disseram que m tem um método f. Chamado de volta mock. Eles disseram que m é o atributo is_alive. Ótimo, outra simulação está de volta. E vemos que m e f são chamados uma vez. Ou seja, é um objeto complicado, dentro do qual o método getattr é reescrito.

Vamos dar uma olhada em um exemplo mais claro. Digamos que haja um AliveChecker. Ele usa algum tipo de http_session, precisa de um alvo e tem uma função do_check que retorna True ou false, dependendo do que recebeu: 200 ou não 200. Este é um exemplo ligeiramente artificial. Mas suponha que dentro do do_check você possa encerrar uma lógica complexa.
Digamos que não desejemos testar nada sobre a sessão, não queremos saber nada sobre o método get. Queremos apenas testar do_check. Ótimo, vamos testar.

Você pode fazer assim. Mock http_session, aqui é chamado de pseudo_client. Nós zombamos do método get dela, dizemos que get é um mock que retorna 200. Lançamos, criamos um AliveChecker a partir disso, lançamos. Este teste funcionará.
Além disso, vamos verificar se get foi chamado uma vez e com exatamente os mesmos argumentos que foi escrito. Ou seja, chamamos do_check sem saber nada sobre qual sessão era ou quais eram seus métodos. Nós apenas os congelamos. A única coisa que sabemos é que ele retornou 200.

Outro exemplo. É muito parecido com o anterior. A única coisa aqui é side_effect em vez de return_value. Mas isso é algo que o mock faz. Nesse caso, ele lança uma exceção. A linha assert foi alterada para assert not AliveChecker.do_check (). Ou seja, vemos que o cheque não vai passar.
Estes são dois exemplos de como testar a função do_check sem saber nada sobre o que veio de cima, o que veio para esta classe.
O exemplo, é claro, parece artificial: não está totalmente claro por que verificar, 200 ou não 200, há apenas um mínimo de lógica. Mas vamos imaginar fazer algo complicado dependendo do código de retorno. E então esse teste começa a parecer muito mais significativo. Vimos que chegam 200 e então verificamos a lógica de processamento. Se não 200 - o mesmo.

Você também pode corrigir bibliotecas com simulação. Digamos que você já tenha uma biblioteca e precise alterar algo nela. Aqui está um exemplo, corrigimos o seno. Agora ele sempre retorna um dois. Excelente.
Também vemos que m foi chamado duas vezes. Mock, é claro, não sabe nada sobre as APIs internas dos métodos que você simula e, em geral, não é obrigado a combiná-las. Mas o mock permite que você verifique o que você chamou, quantas vezes e com quais argumentos. Nesse sentido, ajuda testar o código.

Quero alertá-lo contra um caso em que há um módulo e uma imensa simulação. Por favor, aborde tudo razoavelmente. Se você tem coisas simples, não as molhe. Quanto mais simulação você tem em seu teste, mais você se afasta da realidade: sua API pode não corresponder e, em geral, não é exatamente isso que você está testando. Você não precisa encharcar tudo desnecessariamente. Aborde o processo de forma inteligente.

Ainda temos a última pequena parte sobre Integração Contínua. Quando você está desenvolvendo um projeto de estimação sozinho, pode executar testes localmente e, tudo bem, eles funcionarão.
Assim que o projeto cresce e há mais de um desenvolvedor nele, ele para de funcionar. Primeiro, metade não executará testes localmente. Em segundo lugar, eles irão executá-los em suas versões. Haverá conflitos em algum lugar, tudo quebrará constantemente.
Para isso, existe a Integração Contínua, uma prática de desenvolvimento que envolve a injeção rápida de candidatos no mainstream. Mas, ao mesmo tempo, eles devem passar por algum tipo de montagem de automóveis ou autotestes em um sistema especial. Você tem o código no repositório, os commits que deseja fundir no branch principal do projeto. Nestes commits, os testes são passados em um sistema especial. Se os testes forem verdes, então o commit é feito por si mesmo ou você tem a oportunidade de despejá-lo.
Esse esquema, é claro, tem suas desvantagens, assim como tudo. No mínimo, você precisa de hardware adicional - não o fato de que o CI será gratuito. Mas em qualquer empresa mais ou menos grande, e não uma grande também, você não pode ir a lugar nenhum sem CI.
Como exemplo - uma captura de tela do TeamCity, um dos ICs. Existe uma montagem, foi concluída com sucesso. Houve muitas mudanças nele, foi lançado em tal e tal agente em tal e tal momento. Este é um exemplo de quando tudo está bem e pode ser infundido.
Existem muitos sistemas CI diferentes. Eu escrevi uma lista, se estiver interessado, dê uma olhada: AppVeyor, Jenkins, Travis, CircleCI, GoCD, Buildbot. Obrigado.
Outras palestras do vídeo-curso sobre Python estão em um post no Habré .