Caminho de pesquisa
A jornada começou pesquisando a aplicação de técnicas de modelagem de linguagem no processamento de linguagem natural para aprender o código Python. Nós nos concentramos no script de conclusão IntelliCode atual, conforme mostrado na imagem abaixo.

A principal tarefa é encontrar o fragmento (membro) mais provável do tipo, levando em consideração o fragmento de código anterior à chamada do fragmento (membro). Em outras palavras, dado o trecho de código original C, o vocabulário V e o conjunto de todos os métodos possíveis M ⊂ V, gostaríamos de definir:
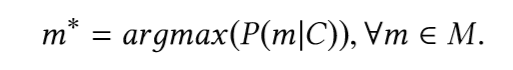
Para encontrar esse fragmento, precisamos construir um modelo que possa prever a probabilidade de fragmentos disponíveis.
Abordagens modernas anteriores baseadas em redes neurais recorrentes ( RNN ) usavam apenas a natureza sequencial do código-fonte, tentando transmitir técnicas de linguagem natural sem usar as características exclusivas da sintaxe da linguagem de programação e da semântica do código. A natureza do problema de completamento de código o tornou um candidato promissor para memória de curto prazo de longo prazo ( LSTM) Ao preparar os dados para treinar o modelo, usamos uma árvore de sintaxe abstrata parcial (AST) correspondente a trechos de código contendo expressões de acesso de membro (membro) e chamadas de função de módulo para capturar a semântica transportada pelo código remoto.
O treinamento de redes neurais profundas é uma tarefa que consome muitos recursos e requer clusters de computação de alto desempenho. Usamos a estrutura de treinamento paralelo distribuído de Horovod com o otimizador Adam , mantendo uma cópia de todo o modelo neural em cada trabalhador, processando diferentes minilotes do conjunto de dados de treinamento em paralelo. Usamos o Azure Machine Learningpara treinamento de modelo e ajuste de hiperparâmetros, pois seu serviço de cluster de GPU sob demanda facilitou o dimensionamento de nosso treinamento conforme necessário e também ajudou a preparar e gerenciar clusters de VM, agendar tarefas, coletar resultados e lidar com falhas. A tabela mostra os modelos de arquitetura que testamos, bem como sua respectiva precisão e tamanho do modelo.

Escolhemos a fabricação de Implementação Preditiva por causa do tamanho do modelo menor e uma melhoria de 20% na precisão do modelo em relação ao modelo de produção anterior durante a avaliação do modelo offline; o tamanho do modelo é crítico para implantações de produção.
A arquitetura do modelo é mostrada na figura abaixo:

Para implantar o LSTM na produção, tivemos que melhorar a velocidade de inferência do modelo e a área de cobertura da memória para atender aos requisitos de conclusão de código durante a edição. Nosso orçamento de memória era de cerca de 50 MB e precisávamos manter a velocidade média de saída abaixo de 50 milissegundos. O IntelliCode LSTM foi treinado com TensorFlow e escolhemos o ONNX Runtime para inferência para obter o melhor desempenho. O ONNX Runtime funciona com estruturas populares de aprendizado profundo e facilita a integração em uma variedade de ambientes de serviço, fornecendo APIs que abrangem várias linguagens, incluindo Python, C, C ++, C #, Java e JavaScript - usamos APIs C # que são compatíveis com .NET Core para integrar no Microsoft Python Language Server .
A quantização é uma abordagem eficaz para reduzir o tamanho do modelo e melhorar o desempenho quando a queda na precisão causada pela aproximação de números de dígitos baixos é aceitável. Com a quantização INT8 pós-treinamento fornecida pelo ONNX Runtime, a melhoria resultante foi significativa: a pegada da memória e o tempo de inferência foram reduzidos para cerca de um quarto dos valores pré-quantizados em comparação com o modelo original, com uma redução aceitável de 3% na precisão do modelo. Você pode encontrar informações detalhadas sobre design de arquitetura de modelo, ajuste de hiperparâmetros, precisão e desempenho no artigo de pesquisa que publicamos na conferência KDD 2019.
O estágio final de liberação para produção foi a realização de experimentos A / B online comparando o novo modelo LSTM com o modelo de trabalho anterior. Os resultados do experimento A / B online na tabela abaixo mostraram uma melhoria de aproximadamente 25% na precisão das recomendações de primeiro nível (precisão do primeiro item de conclusão recomendado na lista de conclusão) e uma melhoria de 17% na classificação inversa média (MRR), o que nos convenceu de que o novo modelo LSTM é significativamente melhor. o modelo anterior.

Desenvolvedores Python: experimente os add-ons IntelliCode e envie-nos seus comentários!
Graças ao grande esforço da equipe, concluímos a implementação em fases do primeiro modelo de aprendizado profundo para todos os usuários do IntelliCode Python no Visual Studio Code . Na versão mais recente da extensão IntelliCode para Visual Studio Code, também integramos o tempo de execução ONNX e LSTM para trabalhar com a nova extensão Pylance , que é escrita inteiramente em TypeScript. Se você é um desenvolvedor Python, instale a extensão IntelliCode e compartilhe sua opinião conosco.