
Uma consulta executada em paralelo pode usar menos CPU e ser executada mais rapidamente do que uma consulta em execução sequencialmente?
Sim! Para demonstração, usarei duas tabelas com um tipo de coluna
integer.

Observação - o script TSQL na forma de texto está no final do artigo.
Gerando dados de demonstração
#BuildIntInserimos 5.000 inteiros aleatórios na
tabela (para que você tenha os mesmos valores que o meu, eu uso RAND com semente e um loop WHILE). Insira 5.000.000 de registros na

tabela
#Probe.

Plano sequencial
Agora vamos escrever uma consulta para contar o número de correspondências de valores nessas tabelas. Usamos a dica MAXDOP 1 para garantir que a consulta não seja executada em paralelo.
Seu plano de execução e estatísticas são os seguintes:

Esta consulta leva 891 ms e usa 890 ms de CPU.
Plano paralelo
Agora vamos executar a mesma consulta com MAXDOP 2. A

consulta leva 221 ms e usa 436 ms de CPU. O tempo de execução diminuiu quatro vezes e o uso da CPU caiu pela metade!
Bitmap mágico
A razão pela qual a execução de consulta paralela é muito mais eficiente é o operador Bitmap.
Vamos dar uma olhada no plano de execução real para a consulta paralela:

E compará-lo com o plano sequencial:

o princípio do operador Bitmap está bem documentado, então aqui vou fornecer apenas uma breve descrição com links para a documentação no final do artigo.
Hash Join
A junção de hash é feita em duas etapas:
- A fase de "construção" (Inglês - construir). Todas as linhas de uma das tabelas são lidas e uma tabela hash é criada para as chaves de junção.
- A fase de "verificação" (inglês - sonda). Todas as linhas da segunda tabela são lidas, o hash é calculado pela mesma função hash usando as mesmas chaves de conexão e um depósito correspondente é encontrado na tabela hash.
Naturalmente, devido a possíveis colisões de hash, ainda é necessário comparar os valores reais das chaves.
Nota do tradutor: para mais detalhes sobre como o hash join funciona, consulte o artigo Visualizando e lidando com o Hash Match Join
Bitmap em planos sequenciais
Muitas pessoas não sabem que o Hash Match, mesmo em solicitações sequenciais, sempre usa um bitmap. Mas, dessa forma, você não o verá explicitamente, porque é parte da implementação interna do operador Hash Match.
HASH JOIN no estágio de construção e criação de uma tabela hash define um (ou mais) bits no bitmap. Você pode então usar o bitmap para corresponder com eficiência aos valores de hash sem a sobrecarga de acessar a tabela de hash.
Com um plano sequencial, um hash é calculado para cada linha da segunda tabela e verificado em relação a um bitmap. Se os bits correspondentes no bitmap forem definidos, pode haver uma correspondência na tabela de hash, portanto, a tabela de hash é verificada a seguir. Por outro lado, se nenhum dos bits correspondentes ao valor hash for definido, então podemos ter certeza de que não há correspondências na tabela hash e podemos descartar imediatamente a string verificada.
O custo relativamente baixo de construir um bitmap é compensado pela economia de tempo em não verificar strings para as quais não há correspondência exata na tabela hash. Essa otimização costuma ser eficaz porque a verificação do bitmap é muito mais rápida do que a verificação da tabela de hash.
Bitmap em planos paralelos
Em um plano paralelo, o bitmap é exibido como uma instrução Bitmap separada.
Ao passar do estágio de construção para o estágio de verificação, o bitmap é passado para o operador HASH MATCH do lado da segunda tabela (sonda). No mínimo, o bitmap é passado para o lado da sonda antes do JOIN e do operador de troca (paralelismo).
Aqui, o bitmap pode excluir strings que não satisfaçam a condição de junção antes de serem passadas para a instrução de troca.
Obviamente, não há instruções de troca em planos sequenciais; portanto, mover o bitmap para fora do HASH JOIN não oferece nenhum benefício adicional sobre o bitmap "incorporado" dentro da instrução HASH MATCH.
Em algumas situações (embora apenas em um plano paralelo), o otimizador pode mover o Bitmap ainda mais para baixo no plano no lado da sonda da conexão.
A ideia aqui é que quanto mais cedo as linhas forem filtradas, menos sobrecarga será necessária para mover os dados entre as instruções e pode até ser possível eliminar algumas operações.
Além disso, o otimizador geralmente tenta colocar filtros simples o mais próximo possível das folhas: é mais eficiente filtrar as linhas o mais cedo possível. No entanto, devo mencionar que o bitmap de que estamos falando é adicionado após a conclusão da otimização.
A decisão de adicionar este tipo (estático) de bitmap ao plano após a otimização é feita com base na seletividade esperada do filtro (portanto, estatísticas precisas são importantes).
Movendo um filtro de bitmap
Vamos voltar ao conceito de mover o filtro de bitmap para o lado da prova da conexão.
Em muitos casos, o filtro de bitmap pode ser movido para uma instrução Scan ou Seek. Quando isso acontece, o predicado do plano se parece com isto:

Ele se aplica a todas as linhas que correspondem ao predicado de busca (para Index Seek) ou todas as linhas para Index Scan ou Table Scan. Por exemplo, a captura de tela acima mostra um filtro de bitmap aplicado à Verificação de tabela para uma tabela heap.
Indo mais fundo ...
Se um filtro de bitmap for construído em uma única coluna ou expressão do tipo inteiro ou bigint e for aplicado a uma única coluna do tipo inteiro ou bigint, o operador Bitmap pode ser movido ainda mais adiante, ainda mais longe do que os operadores Buscar ou Verificar.
O predicado ainda aparecerá nas instruções Scan ou Seek como no exemplo acima, mas agora será marcado com o atributo INROW, o que significa que o filtro é movido para o mecanismo de armazenamento e aplicado às linhas conforme são lidas.
Com essa otimização, as linhas são filtradas antes que o Processador de Consultas as veja. Apenas as strings que correspondem ao HASH MATCH JOIN são enviadas do Storage Engine.
As condições sob as quais essa otimização é aplicada dependem da versão do SQL Server. Por exemplo, no SQL Server 2005, além das condições especificadas anteriormente, a coluna de teste deve ser definida como NOT NULL. Essa limitação foi relaxada no SQL Server 2008.
Você pode estar se perguntando como as otimizações INROW afetam o desempenho. Mover o operador o mais próximo possível de Buscar ou Varredura será tão eficiente quanto filtrar no Mecanismo de Armazenamento? Vou responder a essa pergunta interessante em outros artigos. E aqui também veremos MERGE JOIN e NESTED LOOP JOIN.
Outras opções de JOIN
Usar loops aninhados sem índices é uma má ideia. Precisamos varrer completamente uma das tabelas para cada linha da outra tabela - um total de 5 bilhões de comparações. É provável que essa solicitação demore muito tempo.
Unir juntar
Esse tipo de junção física requer entrada classificada, portanto, um MERGE JOIN forçado faz com que uma classificação esteja presente antes dela. O plano sequencial é semelhante a este:
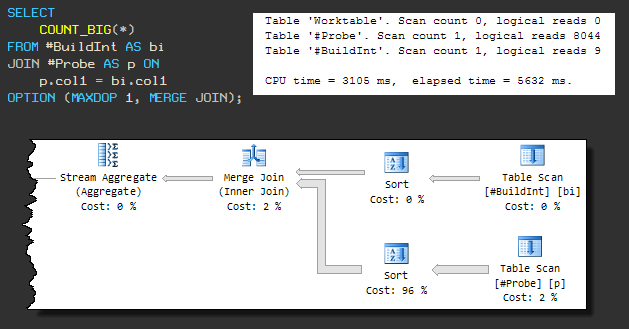
A consulta agora usa 3105ms de CPU e o tempo total de execução é de 5632ms .
O aumento no tempo de execução geral se deve ao fato de que uma das operações de classificação está usando tempdb (embora o SQL Server tenha memória suficiente para a classificação).
O vazamento em tempdb ocorre porque o algoritmo de concessão de memória padrão não reserva memória suficiente. Até que prestemos atenção a isso, é claro que a solicitação não será concluída em menos de 3.105 ms.
Vamos continuar a forçar o MERGE JOIN, mas permitir o paralelismo (MAXDOP 2):

Como no HASH JOIN paralelo que vimos anteriormente, o filtro de bitmap está localizado no outro lado do MERGE JOIN mais perto da Varredura da Tabela e é aplicado usando a otimização INROW.
Com 468 ms de CPU e 240 ms de tempo decorrido, um MERGE JOIN com classificações adicionais é quase tão rápido quanto um HASH JOIN paralelo ( 436 ms / 221 ms ).
Mas o MERGE JOIN paralelo tem uma desvantagem: ele reserva 330 KB de memória com base no número esperado de linhas a serem classificadas. Como esses tipos de bitmaps são usados após a otimização de custos, não há ajuste na estimativa, embora apenas 2.488 linhas passem pela classificação inferior.
Uma instrução de bitmap pode aparecer em um plano com MERGE JOIN apenas com uma instrução de bloqueio subsequente (por exemplo, Sort). O operador de bloqueio deve receber todos os valores necessários como entrada antes de gerar a primeira linha de saída. Isso garante que o bitmap esteja completamente cheio antes que as linhas da tabela JOIN sejam lidas e comparadas a ele.
Não é necessário que a instrução de bloqueio esteja do outro lado de MERGE JOIN, mas é importante em que lado o bitmap é usado.
Com índices
Se índices adequados estiverem disponíveis, a situação é diferente. A distribuição de nossos dados "aleatórios" é tal que
#BuildIntum índice único pode ser criado na tabela . E a tabela #Probecontém duplicatas, então você tem que conviver com um índice não único:

Essa mudança não afetará o HASH JOIN (tanto em série quanto em paralelo). HASH JOIN não pode usar índices, portanto, os planos e o desempenho permanecem os mesmos.
Unir juntar
MERGE JOIN não precisa mais realizar uma operação de junção de muitos para muitos e não requer mais um operador Sort na entrada.
A ausência de um operador de classificação de bloqueio significa que o bitmap não pode ser usado.
Como resultado, vemos um plano sequencial, independentemente do parâmetro MAXDOP, e o desempenho é pior do que o plano paralelo antes de adicionar os índices: 702 ms de CPU e 704 ms de tempo decorrido:

No entanto, há uma melhoria notável em relação ao plano sequencial MERGE JOIN original ( 3105 ms / 5632 ms ). Isso ocorre devido à eliminação da classificação e ao melhor desempenho de junção um para muitos.
Junção de loops aninhados
Como você pode esperar, o NESTED LOOP tem um desempenho significativamente melhor. Semelhante ao MERGE JOIN, o otimizador decide não usar simultaneidade:

Este é o plano mais eficiente até agora - apenas 16 ms de CPU e 16 ms de tempo gasto.
Obviamente, isso pressupõe que os dados necessários para concluir a solicitação já estejam na memória. Caso contrário, cada pesquisa na tabela de sondagem gerará E / S aleatória.
No meu laptop, o desempenho do cache frio NESTED LOOP levou 78 ms de CPU e 2152 ms, tempo decorrido. Nas mesmas circunstâncias, MERGE JOIN usou CPU de 686 ms e 1471 ms . HASH JOIN - 391 ms CPU e905 ms .
MERGE JOIN e HASH JOIN se beneficiam de E / S grande e possivelmente sequencial usando leitura antecipada.
Recursos adicionais
Parallel Hash Join (Craig Freedman)
Query Execution Bitmap Filters (SQL Server Query Processing Team)
Bitmaps no Microsoft SQL Server 2000 (artigo MSDN)
Interpretando planos de execução contendo filtros de bitmap (documentação do SQL Server)
Noções básicas sobre Hash Joins (documentação do SQL Server)
Script de teste
USE tempdb;
GO
CREATE TABLE #BuildInt
(
col1 INTEGER NOT NULL
);
GO
CREATE TABLE #Probe
(
col1 INTEGER NOT NULL
);
GO
-- Load 5,000 rows into the build table
SET NOCOUNT ON;
SET STATISTICS XML OFF;
DECLARE @I INTEGER = 1;
INSERT #BuildInt
(col1)
VALUES
(CONVERT(INTEGER, RAND(1) * 2147483647));
WHILE @I < 5000
BEGIN
INSERT #BuildInt
(col1)
VALUES
(RAND() * 2147483647);
SET @I += 1;
END;
-- Load 5,000,000 rows into the probe table
SET NOCOUNT ON;
SET STATISTICS XML OFF;
DECLARE @I INTEGER = 1;
INSERT #Probe
(col1)
VALUES
(CONVERT(INTEGER, RAND(2) * 2147483647));
BEGIN TRANSACTION;
WHILE @I < 5000000
BEGIN
INSERT #Probe
(col1)
VALUES
(CONVERT(INTEGER, RAND() * 2147483647));
SET @I += 1;
IF @I % 25 = 0
BEGIN
COMMIT TRANSACTION;
BEGIN TRANSACTION;
END;
END;
COMMIT TRANSACTION;
GO
-- Demos
SET STATISTICS XML OFF;
SET STATISTICS IO, TIME ON;
-- Serial
SELECT
COUNT_BIG(*)
FROM #BuildInt AS bi
JOIN #Probe AS p ON
p.col1 = bi.col1
OPTION (MAXDOP 1);
-- Parallel
SELECT
COUNT_BIG(*)
FROM #BuildInt AS bi
JOIN #Probe AS p ON
p.col1 = bi.col1
OPTION (MAXDOP 2);
SET STATISTICS IO, TIME OFF;
-- Indexes
CREATE UNIQUE CLUSTERED INDEX cuq ON #BuildInt (col1);
CREATE CLUSTERED INDEX cx ON #Probe (col1);
-- Vary the query hints to explore plan shapes
SELECT
COUNT_BIG(*)
FROM #BuildInt AS bi
JOIN #Probe AS p ON
p.col1 = bi.col1
OPTION (MAXDOP 1, MERGE JOIN);
GO
DROP TABLE #BuildInt, #Probe;
Consulte Mais informação: