Mas todas essas soluções não tinham o que eu precisava:
- Instalação centralizada
- Resultados da pesquisa levando em consideração os direitos de acesso
- Pesquisa por conteúdo de documento
- Morfologia
E decidi fazer o meu.
Vou divulgar ponto a ponto o que tenho no formulário para evitar a diferença de interpretação e mal-entendido.
Instalação centralizada - execução cliente-servidor. Todas as soluções acima têm um problema fundamental - cada usuário faz seu próprio índice de pesquisa local, que, no caso de grandes volumes de armazenamento, atrasa a indexação, o perfil do usuário na máquina aumenta e geralmente é inconveniente no caso de um novo funcionário chegar ou se mudar para uma nova máquina.
Resultados da pesquisa levando em consideração os direitos - tudo é simples aqui - os resultados devem corresponder aos direitos do funcionário ao recurso de arquivo. Caso contrário, verifica-se que mesmo que o funcionário não tenha direitos sobre o recurso, ele pode ler tudo do cache de pesquisa. Vai ficar estranho, concorda? Pesquise pelo conteúdo do documento - pesquise pelo texto do documento, tudo é óbvio aqui, parece-me, e não pode haver discrepâncias.
A morfologia é ainda mais simples. Especificou no pedido “faca” e recebeu tanto “faca” como “facas”, “faca” e “faca”. É desejável que funcione para russo e inglês.
Já decidimos a formulação do problema, podemos prosseguir para a implementação.
Como mecanismo de busca, escolhi o sistema Sphinx, e a linguagem de desenvolvimento da interface foi C # e .net, e como resultado o projeto foi batizado de Vidocq (Vidocq) em homenagem ao nome do detetive francês. Bem, tipo, ele encontra tudo e é isso.
Arquitetonicamente, o aplicativo se parece com isto: O
robô de pesquisa rastreia recursivamente um recurso de arquivo e processa arquivos de acordo com uma determinada lista de extensões. O processamento consiste em obter o conteúdo do arquivo, comprimir o texto - aspas, vírgulas, espaços extras, etc. são retirados do texto, o conteúdo é colocado no banco de dados (MS SQL), a data de colocação é marcada e o robô segue em frente.
O indexador Sphins trabalha diretamente com a base recebida, formando seu próprio índice e retornando um ponteiro para o arquivo encontrado e um fragmento de texto encontrado como resposta.
Foi desenvolvido um formulário em C # que se comunicava com o Sphinx por meio do conector MySQL. O Sphinx fornece um array de arquivos de acordo com a solicitação, então o array é filtrado pelo direito de acesso do usuário que está pesquisando, a saída é formatada e mostrada ao usuário.
Precisamos armazenar as seguintes informações sobre o arquivo:
- ID do arquivo
- Nome do arquivo
- O caminho para o arquivo
- Conteúdo do arquivo
- Expansão
- Data adicionada à base
Isso tudo é feito em uma tabela e o robô de pesquisa adicionará tudo a ela. A data de adição é necessária para que quando o robô na próxima rodada compare a data da modificação do arquivo com a data em que foi colocado no banco de dados, e se as datas forem diferentes, atualize as informações sobre o arquivo.
Em seguida, configure o próprio mecanismo de pesquisa. Não vou descrever toda a configuração, ela estará disponível no arquivo do projeto, mas vou cobrir apenas os pontos principais.
A solicitação principal que forma a base dos
documentos de origem: documents_base
{
sql_query = \
select \
DocumentId as 'Id', \
DocumentPath as 'Path', \
DocumentTitle as 'Title', \
DocumentExtention as 'Extension', \
DocumentContent as 'Content' \
from \
VidocqDocs
}Configurando a morfologia por meio de um lematizador.
index documents
{
source = documents
path = D:/work/VidocqSearcher/Sphinx/data/index
morphology = lemmatize_ru_all, lemmatize_en_all
}Depois disso, você pode definir o indexador na base e verificar o trabalho.
d:\work\VidocqSearcher\Sphinx\bin\indexer.exe documents --config D:\work\VidocqSearcher\Sphinx\bin\main.conf –rotateAqui, o caminho para o indexador é seguido pelo nome do índice no qual colocar o processado, o caminho para a configuração e o sinalizador –rotate significa que a indexação será realizada em tempo real, ou seja, com o serviço de pesquisa em execução. Depois que a indexação for concluída, o índice será substituído pelo atualizado.
Verificamos o trabalho no console. Como interface, você pode usar um cliente MySQL, obtido, por exemplo, do kit do servidor web.
mysql -h 127.0.0.1 -P 9306após esse pedido, selecione o id dos documentos; deve retornar uma lista de documentos indexados, se, é claro, você iniciou o próprio serviço Sphinx e fez tudo certo.
Ok, o console é ótimo, mas não vamos forçar os usuários a digitar comandos, certo?
Esbocei um formulário como este
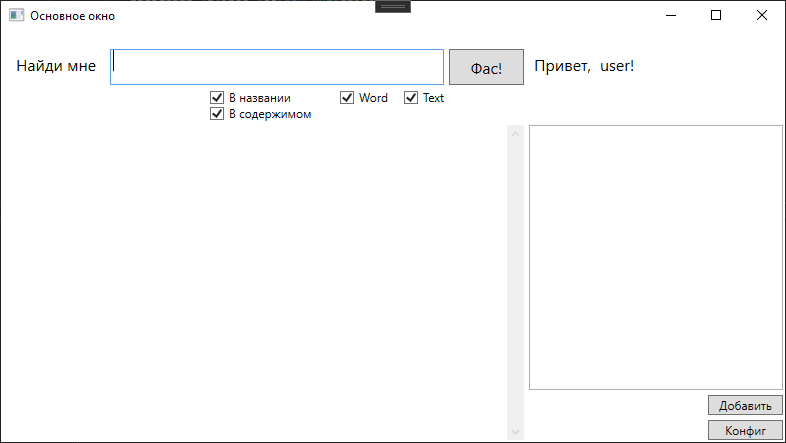
E aqui com os resultados da pesquisa

Quando você clica em um resultado específico, um documento é aberto.
Como implementado.
using MySql.Data.MySqlClient;
string connectionString = "Server=127.0.0.1;Port=9306";
var query = "select id, title, extension, path, snippet(content, '" + textBoxSearch.Text.Trim() + "', 'query_mode=1') as snippet from documents " +
"where ";
if (checkBoxTitle.IsChecked == true && checkBoxContent.IsChecked == true)
{
query += "match ('@(title,content)" + textBoxSearch.Text.Trim() + "')";
}
if (checkBoxTitle.IsChecked == false && checkBoxContent.IsChecked == true)
{
query += "match ('@content" + textBoxSearch.Text.Trim() + "')";
}
if (checkBoxTitle.IsChecked == true && checkBoxContent.IsChecked == false)
{
query += "match ('@title" + textBoxSearch.Text.Trim() + "')";
}
if (checkBoxWord.IsChecked == true && checkBoxText.IsChecked == true)
{
query += "and extension in ('.docx', '.doc', '.txt');";
}
if (checkBoxWord.IsChecked == true && checkBoxText.IsChecked == false)
{
query += "and extension in ('.docx', '.doc');";
}
if (checkBoxWord.IsChecked == false && checkBoxText.IsChecked == true)
{
query += "and extension in ('.txt');";
}Sim, existe um código bydloc, mas este é um MVP.
Na verdade, um pedido para a Esfinge é formado aqui, dependendo das caixas de seleção definidas. As caixas de seleção indicam o tipo de arquivo a ser pesquisado e a área de pesquisa.
Em seguida, a solicitação vai para a Esfinge e o resultado é analisado.
using (var command = new MySqlCommand(query, connection))
{
connection.Open();
using (var reader = command.ExecuteReader())
{
while (reader.Read())
{
var id = reader.GetUInt16("id");
var title = reader.GetString("title");
var path = reader.GetString("path");
var extension = reader.GetString("extension");
var snippet = reader.GetString("snippet");
bool isFileExist = File.Exists(path);
if (isFileExist == true)
{
System.Windows.Controls.RichTextBox textBlock = new RichTextBox();
textBlock.IsReadOnly = true;
string xName = "id" + id.ToString();
textBlock.Name = xName;
textBlock.Tag = path;
textBlock.GotFocus += new System.Windows.RoutedEventHandler(ShowClickHello);
snippet = System.Text.RegularExpressions.Regex.Replace(snippet, "<.*?>", String.Empty);
Paragraph paragraph = new Paragraph();
paragraph.Inlines.Add(new Bold(new Run(path + "\r\n")));
paragraph.Inlines.Add(new Run(snippet));
textBlock.Document = new FlowDocument(paragraph);
StackPanelResult.Children.Add(textBlock);
}
else
{
counteraccess--;
}
}
}
}Na mesma fase, o problema é gerado. Cada elemento do problema é uma caixa de texto rica com um evento para abrir um documento com um clique. Os itens são colocados no StackPanel e, antes disso, o arquivo é verificado para o usuário. Assim, um arquivo inacessível ao usuário não será incluído na saída.
As vantagens desta solução:
- A indexação ocorre centralmente
- Exibição precisa com base em direitos de acesso
- Pesquisa personalizável por tipo de documento
Obviamente, para a operação completa de tal solução, um archive de arquivo deve ser devidamente organizado na empresa. Idealmente, os perfis de usuário móvel e assim por diante devem ser configurados. E sim, eu conheço o SharePoint, o Windows Search e provavelmente mais algumas soluções. Em seguida, você pode discutir interminavelmente a escolha de uma plataforma de desenvolvimento, o mecanismo de pesquisa Sphinx, Manticore ou Elastic e assim por diante. Mas estava interessado em resolver o problema com as ferramentas que entendo um pouco. Atualmente está rodando em modo MVP, mas estou desenvolvendo.
Mas, em qualquer caso, estou pronto para ouvir suas sugestões sobre quais pontos podem ser melhorados ou refeitos pela raiz.