Diremos por que essa ferramenta apareceu e o que ela pode fazer.

Falta de algoritmos
Um dos principais desafios do aprendizado de máquina é a redução da dimensionalidade dos dados. Os cientistas de dados reduzem o número de variáveis isolando entre elas os valores que têm o maior impacto no resultado. Após esta operação, o modelo de aprendizado de máquina requer menos memória, funciona mais rápido e melhor. O exemplo abaixo mostra que a eliminação de recursos duplicados aumenta a precisão da classificação de 0,903 para 0,943.
>>> from sklearn.linear_model import SGDClassifier
>>> from ITMO_FS.embedded import MOS
>>> X, y = make_classification(n_samples=300, n_features=10, random_state=0, n_informative=2)
>>> sel = MOS()
>>> trX = sel.fit_transform(X, y, smote=False)
>>> cl1 = SGDClassifier()
>>> cl1.fit(X, y)
>>> cl1.score(X, y)
0.9033333333333333
>>> cl2 = SGDClassifier()
>>> cl2.fit(trX, y)
>>> cl2.score(trX, y)
0.9433333333333334Existem duas abordagens para a redução de dimensionalidade - design e seleção de recursos. Em áreas como bioinformática e medicina, esta última é frequentemente utilizada, pois permite destacar características significativas preservando a semântica, ou seja, não altera o significado original das características. No entanto, as bibliotecas de aprendizado de máquina Python mais comuns - scikit-learn, pytorch, keras, tensorflow - carecem de um conjunto completo de métodos de seleção de recursos.
Para resolver este problema, os alunos e pós-graduados da Universidade ITMO desenvolveram uma biblioteca aberta - ITMO_FS. Uma equipe está trabalhando nisso sob a liderança de Ivan Smetannikov, Professor Associado da Faculdade de Tecnologias da Informação e Programação, Chefe Adjunto do Laboratório de Aprendizado de Máquina. Desenvolvedor líder - Nikita Pilnenskiy, graduada em Mestrado em Aprendizado de Máquina e Análise de Dados . Agora ele vai para a pós-graduação.
« , . , , , (-) .
, , , . , , , ».
—
ITMO_FS é implementado em Python e é compatível com scikit-learn, que é considerado a principal ferramenta de análise de dados de fato. Seus seletores de recursos usam os mesmos parâmetros:
data: array-like (2-D list, pandas.Dataframe, numpy.array);
targets: array-like (1-D list, pandas.Series, numpy.array).A biblioteca oferece suporte a todas as abordagens clássicas para seleção de recursos - filtros, invólucros e métodos embutidos. Entre eles estão algoritmos como filtros baseados em correlações de Spearman e Pearson, Critério de Ajuste, QPFS, filtro de hill climbing e outros .

A biblioteca também oferece suporte a conjuntos de treinamento, combinando algoritmos de seleção de recursos com base nas medidas de significância usadas neles. Essa abordagem permite obter resultados preditivos mais elevados com um baixo investimento de tempo.
Quais são os análogos
Não existem muitas bibliotecas de algoritmos de seleção de recursos, especialmente em Python. Um dos maiores é considerado o desenvolvimento de engenheiros da Arizona State University (ASU). Ele suporta um grande número de algoritmos, mas quase não foi atualizado recentemente.
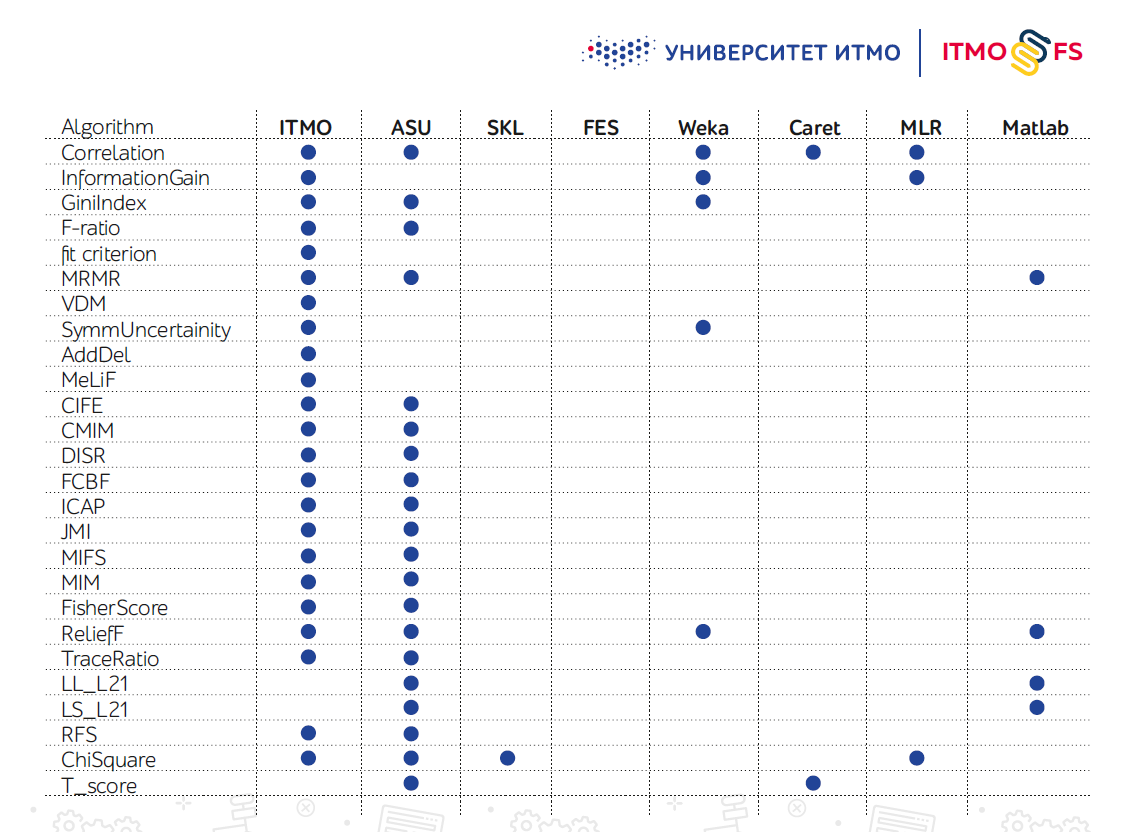
O próprio Scikit-learn também possui vários mecanismos de seleção de recursos, mas na prática eles não são suficientes.
"Em geral, nos últimos cinco a sete anos, o foco mudou para algoritmos de conjunto para seleção de recursos, mas eles não estão particularmente representados em tais bibliotecas, que também queremos corrigir."
- Ivan Smetannikov
Perspectivas de projeto
Os autores de ITMO_FS planejam integrar seu produto ao scikit-learn adicionando-o à lista de bibliotecas oficialmente compatíveis. No momento, a biblioteca já contém o maior número de algoritmos de seleção de recursos entre todas as bibliotecas, mas sua adição continua. Mais adiante no roteiro está a adição de novos algoritmos, incluindo nossos próprios desenvolvimentos.
Em planos mais distantes, existem tarefas para introduzir a biblioteca no sistema de meta-aprendizagem, adicionar algoritmos para trabalho direto com dados matriciais (preenchimento de lacunas, geração de dados espaciais de metaatributos, etc.), bem como uma interface gráfica. Paralelamente, serão realizados hackathons utilizando a biblioteca para despertar o interesse de mais desenvolvedores no produto e obter feedback.
Espera-se que o ITMO_FS encontre aplicação nos campos da medicina e da bioinformática - em problemas como o diagnóstico de vários cancros, a construção de modelos preditivos de características fenotípicas (por exemplo, a idade de uma pessoa) e a síntese de medicamentos.
Onde posso baixar
Se você estiver interessado no projeto ITMO_FS, pode baixar a biblioteca e testá-la na prática - aqui está o repositório no GitHub . Uma versão inicial da documentação está disponível em readthedocs . Lá você também pode ver as instruções de instalação (com suporte do pip). Agradecemos qualquer feedback.
Materiais adicionais de nosso blog em Habré:
- Podcast: o que espera os aspirantes a cientistas em ML
- Podcast: Quantum Hacking e Compartilhamento de Chaves