
A computação em nuvem está penetrando cada vez mais em nossas vidas e provavelmente não existe uma única pessoa que não tenha usado nenhum serviço em nuvem pelo menos uma vez. No entanto, o que é uma nuvem e como ela funciona na maioria das vezes, poucas pessoas sabem mesmo no nível de uma ideia. 5G já está se tornando uma realidade e a infraestrutura de telecomunicações está começando a se mover de soluções de pilar para soluções em nuvem, como quando estava passando de soluções totalmente férreas para “pilares” virtualizados.
Hoje vamos falar sobre o mundo interno da infraestrutura em nuvem, em particular, vamos analisar o básico da parte de rede.
O que é uma nuvem? A mesma virtualização - visão de perfil?
Mais do que uma pergunta lógica. Não - isso não é virtualização, embora não fosse sem ela. Considere duas definições:
A computação em nuvem (doravante Cloud) é um modelo para fornecer acesso amigável a recursos de computação distribuídos que devem ser implantados e iniciados sob demanda com a menor latência possível e custo mínimo do provedor de serviços (tradução da definição do NIST).
Virtualização- esta é a capacidade de dividir uma entidade física (por exemplo, um servidor) em várias virtuais, aumentando assim a utilização de recursos (por exemplo, você tinha 3 servidores carregados em 25-30 por cento, após a virtualização você obtém 1 servidor carregado em 80-90 por cento). Naturalmente, a virtualização consome alguns dos recursos - você precisa alimentar o hipervisor, no entanto, como a prática tem mostrado, o jogo vale a pena. Um exemplo ideal de virtualização é o VMWare, que prepara perfeitamente as máquinas virtuais, ou por exemplo KVM, que prefiro, mas isso já é uma questão de gosto.
Nós mesmos usamos a virtualização sem perceber isso, e até mesmo os roteadores iron já usam a virtualização - por exemplo, nas versões mais recentes do JunOS, o sistema operacional é instalado como uma máquina virtual em cima do kit de distribuição Linux em tempo real (Wind River 9). Mas a virtualização não é a nuvem, mas a nuvem não pode existir sem virtualização.
A virtualização é um dos blocos de construção sobre os quais a nuvem é construída.
Não funcionará para criar uma nuvem simplesmente coletando vários hipervisores em um domínio L2, adicionando alguns playbooks yaml para registrar automaticamente vlans através de algum ansible e enchendo-os com algo como um sistema de orquestração para criar automaticamente máquinas virtuais. Mais precisamente, vai acabar acontecendo, mas o Frankenstein resultante não é a nuvem de que precisamos, embora, como outra pessoa, talvez para alguém este seja o sonho final. Além disso, se você pegar o mesmo Openstack - na verdade, ainda é Frankenstein, mas tudo bem, não vamos falar sobre isso ainda.
Mas eu entendo que a partir da definição acima não está totalmente claro o que realmente pode ser chamado de nuvem.
Portanto, o documento do NIST (Instituto Nacional de Padrões e Tecnologia) lista 5 características principais que uma infraestrutura em nuvem deve ter:
Prestação de serviços a pedido. O usuário deve ter acesso gratuito aos recursos de computador alocados a ele (como redes, discos virtuais, memória, núcleos de processador, etc.), e esses recursos devem ser fornecidos automaticamente - ou seja, sem intervenção do provedor de serviços.
Ampla disponibilidade de serviço. O acesso aos recursos deve ser fornecido por mecanismos padrão para permitir o uso de PCs e thin clients e dispositivos móveis padrão.
Combinação de recursos.Os pools de recursos devem ser capazes de fornecer recursos a vários clientes ao mesmo tempo, garantindo o isolamento do cliente e a ausência de influência mútua e contenção de recursos. As redes também estão incluídas nos pools, o que indica a possibilidade de uso de endereçamento sobreposto. Os pools devem ser escalonados sob demanda. O uso de pools permite fornecer o nível necessário de resiliência de recursos e abstração de recursos físicos e virtuais - o destinatário do serviço é simplesmente fornecido com o conjunto de recursos solicitado (onde esses recursos estão localizados fisicamente, em quantos servidores e switches - o cliente não se importa). No entanto, deve-se levar em consideração o fato de que o provedor deve garantir a reserva transparente desses recursos.
Adaptação rápida a várias condições.Os serviços devem ser flexíveis - fornecimento rápido de recursos, sua realocação, adição ou redução de recursos a pedido do cliente, e o cliente deve sentir que os recursos da nuvem são infinitos. Para facilitar a compreensão, por exemplo, você não vê um aviso de que perdeu parte do espaço em disco no Apple iCloud devido ao fato de que o disco rígido do servidor está quebrado e os discos estão quebrando. Além disso, do seu lado, as possibilidades deste serviço são quase infinitas - você precisa de 2 TB - não tem problema, você pagou e recebeu. Da mesma forma, você pode dar um exemplo com Google.Drive ou Yandex.Disk.
A capacidade de medir o serviço prestado.Os sistemas em nuvem devem controlar e otimizar automaticamente os recursos consumidos, enquanto esses mecanismos devem ser transparentes tanto para o usuário quanto para o provedor de serviços. Ou seja, você sempre pode verificar quantos recursos você e seus clientes estão consumindo.
Vale a pena considerar o fato de que esses requisitos são em sua maioria requisitos para uma nuvem pública, portanto, para uma nuvem privada (ou seja, uma nuvem lançada para as necessidades internas de uma empresa), esses requisitos podem ser ligeiramente ajustados. No entanto, eles ainda precisam ser executados, caso contrário, não obteremos todas as vantagens da computação em nuvem.
Por que precisamos de uma nuvem?
No entanto, qualquer tecnologia nova ou existente, qualquer novo protocolo é criado para algo (bem, exceto para RIP-ng, é claro). Protocolo por causa do protocolo - ninguém precisa dele (bem, exceto para RIP-ng, é claro). É lógico que a Nuvem seja criada para fornecer algum tipo de serviço ao usuário / cliente. Estamos todos familiarizados com pelo menos alguns serviços em nuvem, como Dropbox ou Google.Docs, e acredito que a maioria deles os usa com sucesso - por exemplo, este artigo foi escrito usando o serviço em nuvem Google.Docs. Mas os serviços em nuvem que conhecemos são apenas parte dos recursos da nuvem - mais precisamente, é apenas um serviço do tipo SaaS. Podemos fornecer um serviço em nuvem de três maneiras: na forma de SaaS, PaaS ou IaaS. O serviço de que você precisa depende de seus desejos e capacidades.
Vamos considerar cada um em ordem:
Software as a Service (SaaS) é um modelo para fornecer um serviço completo a um cliente, por exemplo, um serviço de correio como Yandex.Mail ou Gmail. Em tal modelo de prestação de serviço, você, como cliente, na verdade não faz nada, exceto usar os serviços - ou seja, você não precisa pensar em configurar um serviço, sua tolerância a falhas ou reserva. O principal é não comprometer sua senha, o provedor deste serviço fará o resto por você. Do ponto de vista do provedor de serviços, ele é totalmente responsável por todo o serviço - desde o hardware do servidor e sistemas operacionais do host até as configurações de banco de dados e software.
Plataforma como serviço (PaaS)- ao usar este modelo, o provedor de serviço fornece ao cliente um modelo para o serviço, por exemplo, vamos pegar um servidor web. O provedor de serviço forneceu ao cliente um servidor virtual (na verdade, um conjunto de recursos, como RAM / CPU / Storage / Nets, etc.), e até instalou o SO e o software necessário neste servidor, mas o próprio cliente configura tudo isso, e já para o desempenho do serviço o cliente responde. O provedor de serviço, como no passado, é responsável pela operabilidade do equipamento físico, hipervisores, a própria máquina virtual, sua disponibilidade de rede, etc., mas o serviço em si já está fora de sua área de responsabilidade.
Infraestrutura como serviço (IaaS)- esta abordagem já é mais interessante, na verdade, o provedor de serviços fornece ao cliente uma infraestrutura virtualizada completa - ou seja, algum tipo de conjunto (pool) de recursos, como núcleos de CPU, RAM, redes, etc. Tudo o resto é com o cliente - o que o cliente quer fazer com eles recursos dentro do pool alocado (quota) - o fornecedor não é particularmente importante. O cliente quer criar seu próprio vEPC ou até mesmo fazer uma minoperadora e fornecer serviços de comunicação - sem dúvida - faça isso. Nesse cenário, o provedor de serviços é responsável pelo fornecimento de recursos, sua tolerância a falhas e disponibilidade, bem como pelo sistema operacional que permite combinar esses recursos em pools e fornecê-los ao cliente com a capacidade de aumentar ou diminuir os recursos a qualquer momento a pedido do cliente. O cliente configura todas as máquinas virtuais e outros ouropéis por meio do portal de autoatendimento e consoles,incluindo o registro de redes (exceto para redes externas).
O que é OpenStack?
Em todas as três opções, o provedor de serviços precisa de um sistema operacional que habilite a infraestrutura em nuvem. Na verdade, em SaaS, nenhum departamento é responsável por toda a pilha dessa pilha de tecnologia - existe um departamento que é responsável pela infraestrutura - ou seja, ele fornece IaaS para outro departamento, esse departamento fornece o cliente SaaS. O OpenStack é um dos sistemas operacionais de nuvem que permite que você reúna vários switches, servidores e sistemas de armazenamento em um único pool de recursos, divida esse pool comum em subconjuntos (locatários) e forneça esses recursos aos clientes pela rede.
Pilha abertaÉ um sistema operacional em nuvem que permite controlar grandes pools de recursos de computação, armazenamento de dados e recursos de rede, cujo provisionamento e gerenciamento é realizado por meio de uma API usando mecanismos de autenticação padrão.
Em outras palavras, este é um conjunto de projetos de software livre que são projetados para criar serviços em nuvem (públicos e privados) - ou seja, um conjunto de ferramentas que permitem combinar servidor e equipamento de comutação em um único pool de recursos, gerenciar esses recursos, fornecendo o nível necessário de tolerância a falhas ...
No momento em que este artigo foi escrito, a estrutura do OpenStack se parecia com isto:

Foto tirada de openstack.org
Cada um dos componentes que compõem o OpenStack executa uma função específica. Essa arquitetura distribuída permite incluir na solução o conjunto de componentes funcionais de que você precisa. No entanto, alguns dos componentes são componentes raiz e sua remoção levará à inoperabilidade total ou parcial da solução como um todo. É comum referir-se a tais componentes:
- Dashboard - GUI baseada na web para gerenciar serviços OpenStack
- O Keystone é um serviço de identidade centralizado que fornece funcionalidade de autenticação e autorização para outros serviços, além de gerenciar credenciais e funções de usuário.
- Neutron — , OpenStack ( VM )
- Cinder —
- Nova —
- Glance —
- Swift —
- Ceilometer — ,
- Heat —
Uma lista completa de todos os projetos e seus objetivos pode ser encontrada aqui .
Cada um dos componentes do OpenStack é um serviço responsável por uma função específica e fornece uma API para gerenciar essa função e comunicar esse serviço com outros serviços do sistema operacional em nuvem para criar uma infraestrutura unificada. Por exemplo, Nova fornece gerenciamento de recursos de computação e APIs para acessar a configuração desses recursos, Glance fornece gerenciamento de imagens e APIs para gerenciá-los, Cinder fornece armazenamento em bloco e APIs para gerenciá-los, e assim por diante. Todas as funções estão interligadas de forma muito próxima.
No entanto, se você julgar, todos os serviços em execução no OpenStack são, em última análise, algum tipo de máquina virtual (ou contêiner) conectada à rede. Surge a pergunta - por que precisamos de tantos elementos?
Vamos examinar o algoritmo para criar uma máquina virtual e conectá-la à rede e ao armazenamento persistente no Openstack.
- Quando você cria uma solicitação para criar uma máquina, seja uma solicitação por meio do Horizon (Dashboard) ou uma solicitação por meio da CLI, a primeira coisa que acontece é a sua solicitação de autorização para Keystone - você pode criar uma máquina, tem ou o direito de usar esta rede, você tem o suficiente rascunho de cotas, etc.
- O Keystone autentica sua solicitação e gera um token de autenticação na mensagem de resposta, que será usado posteriormente. Depois de receber uma resposta da Keystone, a solicitação é enviada para Nova (nova api).
- Nova-api , Keystone, auth-
- Keystone auth- .
- Nova-api nova-database VM nova-scheduler.
- Nova-scheduler ( ), VM , . VM nova-database.
- nova-scheduler nova-compute . Nova-compute nova-conductor (nova-conductor nova, nova-database nova-compute, nova-database ).
- Nova-conductor nova-database nova-compute.
- nova-compute glance ID . Glace Keystone .
- Nova-compute neutron . glance, neutron Keystone, database ( ), nova-compute.
- Nova-compute cinder volume. glance, cider Keystone, volume .
- Nova-compute libvirt .
Na verdade, uma operação aparentemente simples para criar uma máquina virtual simples se transforma em um turbilhão de chamadas de API entre os elementos da plataforma de nuvem. Além disso, como você pode ver, mesmo os serviços anteriormente designados também consistem em componentes menores, entre os quais ocorre a interação. Criar uma máquina é apenas uma pequena parte do que a plataforma de nuvem oferece - há um serviço responsável por balancear o tráfego, um serviço responsável pelo armazenamento em bloco, um serviço responsável pelo DNS, um serviço responsável pelo provisionamento de servidores bare metal, etc. A nuvem permite você trata suas máquinas virtuais como um rebanho de ovelhas (em oposição à virtualização). Se algo aconteceu com sua máquina em um ambiente virtual - você a restaura de backups, etc., os aplicativos em nuvem são construídos desta forma,para que a máquina virtual não desempenhe um papel tão importante - a máquina virtual “morreu” - não importa - uma nova máquina é simplesmente criada com base no template e, como dizem, o pelotão não percebeu a perda de um soldado. Naturalmente, isso fornece a presença de mecanismos de orquestração - usando modelos Heat, você pode implantar facilmente uma função complexa composta por dezenas de redes e máquinas virtuais sem problemas.
É sempre bom ter em mente que não há infraestrutura em nuvem sem rede - cada elemento de uma forma ou de outra interage com outros elementos por meio da rede. Além disso, a nuvem possui uma rede totalmente não estática. Naturalmente, a rede underlay é ainda mais ou menos estática - novos nós e switches não são adicionados todos os dias, no entanto, o componente overlay pode e inevitavelmente mudar constantemente - novas redes serão adicionadas ou removidas, novas máquinas virtuais aparecerão e as antigas morrerão. E como você lembra da definição de nuvem, dada no início do artigo, os recursos devem ser alocados ao usuário automaticamente e com o mínimo (ou melhor sem) intervenção do provedor de serviços. Ou seja, o tipo de fornecimento de recursos de rede,que agora está na forma de um front-end na forma de sua conta pessoal acessível via http / https e o engenheiro de rede de plantão Vasily como backend - isso não é uma nuvem, mesmo que Vasily tenha oito mãos.
O Neutron, sendo um serviço de rede, fornece uma API para gerenciar a parte da rede da infraestrutura em nuvem. O serviço fornece a integridade e o gerenciamento da parte da rede Openstack, fornecendo uma camada de abstração chamada Network-as-a-Service (NaaS). Ou seja, a rede é a mesma unidade virtual mensurável que, por exemplo, núcleos virtuais da CPU ou RAM.
Mas antes de passar para a arquitetura de rede OpenStack, vamos dar uma olhada em como a rede OpenStack funciona e por que a rede é uma parte importante e integrante da nuvem.
Portanto, temos duas máquinas virtuais clientes RED e duas máquinas virtuais clientes VERDES. Suponha que essas máquinas estejam localizadas em dois hipervisores como este:
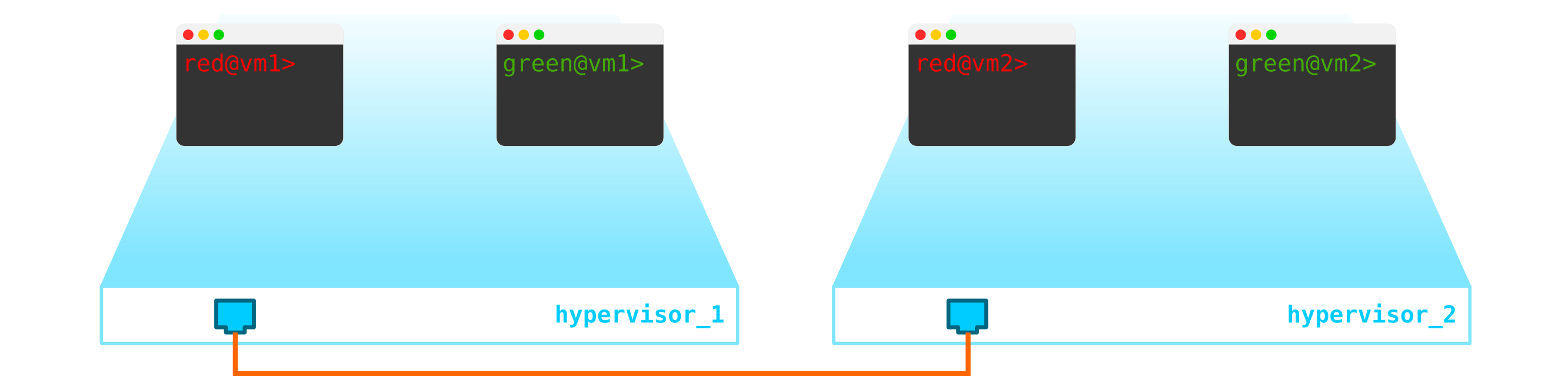
No momento, trata-se apenas da virtualização de 4 servidores e nada mais, já que até agora tudo o que fizemos foi virtualizar 4 servidores, colocando-os em dois servidores físicos. E até agora eles nem estão conectados à rede.
Para obter uma nuvem, precisamos adicionar vários componentes. Primeiro, virtualizamos a parte da rede - precisamos conectar essas 4 máquinas em pares, e os clientes querem exatamente a conexão L2. Você pode usar o switch e configurar um tronco em sua direção e gerenciar tudo usando a ponte do linux, ou para usuários openvswitch mais avançados (voltaremos a ele). Mas pode haver muitas redes, e empurrar constantemente L2 por meio de um switch não é a melhor ideia - portanto, divisões diferentes, central de serviços, meses de espera pela execução de um aplicativo, semanas de solução de problemas - no mundo moderno essa abordagem não funciona mais. E quanto mais cedo a empresa perceber isso, mais fácil será para ela seguir em frente. Portanto, entre os hipervisores, selecionaremos uma rede L3 através da qual nossas máquinas virtuais se comunicarão, e já no topo desta rede L3 construiremos redes L2 (overlay) sobrepostas virtuais,onde o tráfego de nossas máquinas virtuais será executado. GRE, Geneve ou VxLAN podem ser usados como encapsulamento. Vamos nos deter no último por enquanto, embora isso não seja particularmente importante.
Precisamos localizar o VTEP em algum lugar (espero que todos estejam familiarizados com a terminologia VxLAN). Como a rede L3 sai imediatamente dos servidores, nada nos impede de colocar o VTEP nos próprios servidores, e o OVS (OpenvSwitch) pode fazer isso perfeitamente. Como resultado, obtivemos a seguinte construção:
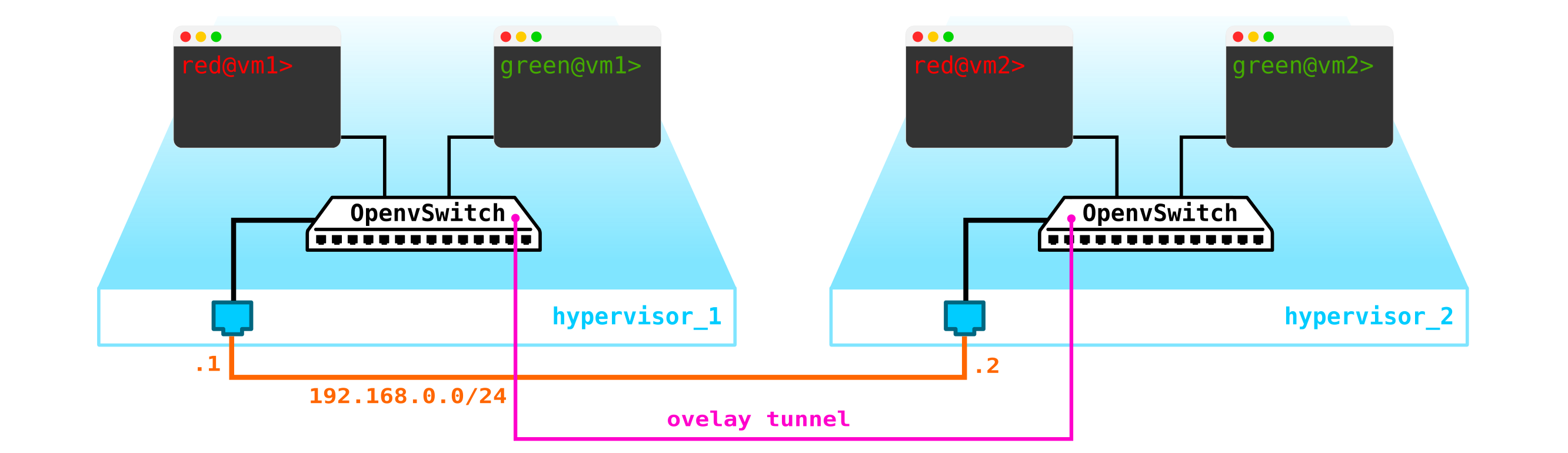
Como o tráfego entre as VMs deve ser dividido, as portas para as máquinas virtuais terão números de vlan diferentes. O número do tag desempenha um papel apenas dentro de um switch virtual, já que ao encapsular em VxLAN podemos removê-lo sem problemas, pois teremos um VNI.

Agora podemos procriar nossas máquinas e redes virtuais para eles sem problemas.
No entanto, e se o cliente tiver outra máquina, mas estiver em uma rede diferente? Precisamos de enraizamento entre redes. Analisaremos uma opção simples quando o enraizamento centralizado é usado - isto é, o tráfego é roteado por nós de rede dedicados especiais (bem, como regra, eles são combinados com nós de controle, então teremos a mesma coisa).
Parece não ser nada complicado - fazemos uma interface de ponte no nó de controle, direcionamos o tráfego para ele e, de lá, o encaminhamos para onde precisamos. Mas o problema é que o cliente RED deseja usar a rede 10.0.0.0/24 e o cliente VERDE deseja usar a rede 10.0.0.0/24. Ou seja, começa a interseção de espaços de endereço. Além disso, os clientes não querem que outros clientes sejam roteados para suas redes internas, o que é lógico. Para separar as redes e o tráfego de dados do cliente, alocaremos um namespace separado para cada um deles. O namespace é, na verdade, uma cópia da pilha de rede do Linux, ou seja, os clientes no namespace RED são completamente isolados dos clientes do namespace GREEN (bem, o roteamento entre essas redes de clientes é permitido através do namespace padrão ou já no equipamento de transporte upstream).
Ou seja, temos o seguinte esquema:
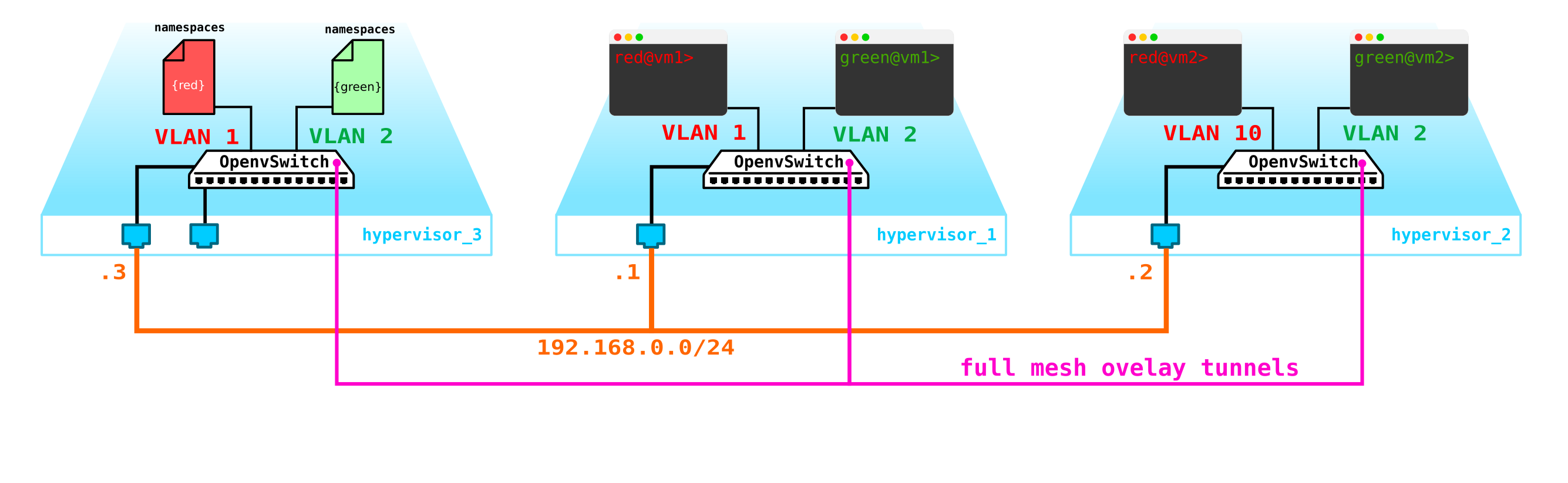
Os túneis L2 convergem de todos os nós de computação para o de controle. o nó onde a interface L3 para essas redes está localizada, cada uma em um namespace dedicado para isolamento.
No entanto, esquecemos o mais importante. A máquina virtual deve prestar um serviço ao cliente, ou seja, deve ter pelo menos uma interface externa através da qual possa ser alcançada. Ou seja, precisamos sair para o mundo exterior. Existem diferentes opções aqui. Vamos fazer a opção mais simples. Vamos adicionar clientes em uma rede, que será válido na rede do provedor e não se sobreporá a outras redes. As redes também podem se cruzar e observar diferentes VRFs no lado da rede do provedor. Essas redes também residirão no namespace de cada um dos clientes. No entanto, eles ainda irão para o mundo exterior por meio de uma interface física (ou de ligação, que é mais lógica). Para separar o tráfego do cliente, o tráfego que vai para fora será marcado com uma etiqueta VLAN atribuída ao cliente.
Como resultado, obtivemos o seguinte esquema:

Uma pergunta razoável - por que não criar gateways nos próprios nós de computação? Isso não é um grande problema, aliás, quando você liga o Roteador Distribuído (DVR), vai funcionar assim. Neste cenário, consideramos a opção mais simples com um gateway centralizado, que é o padrão no Openstack. Para funções de alta carga, eles usarão um roteador distribuído e tecnologias de aceleração, como SR-IOV e Passthrough, mas, como dizem, essa é uma história completamente diferente. Primeiro, vamos lidar com a parte básica e depois entrar em detalhes.
Na verdade, nosso esquema já está operacional, mas existem algumas nuances:
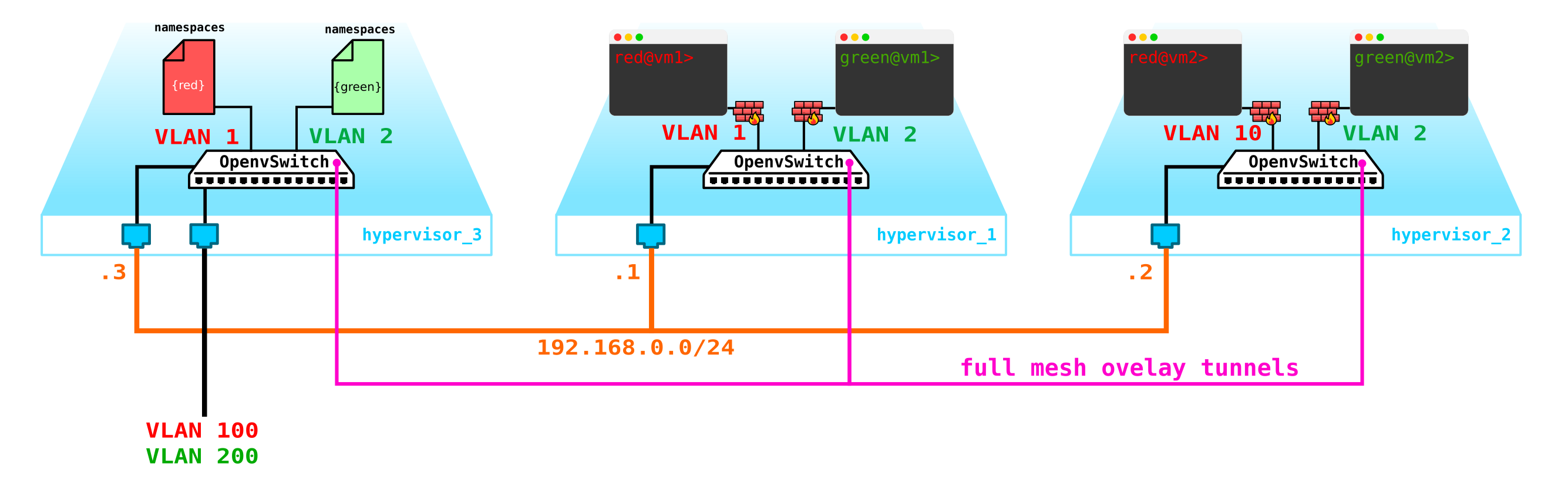
- Precisamos proteger de alguma forma nossas máquinas, ou seja, pendurar um filtro na interface do switch em direção ao cliente.
- Possibilita que uma máquina virtual obtenha automaticamente um endereço IP para que você não tenha que digitá-lo pelo console todas as vezes e registrar o endereço.
Vamos começar protegendo as máquinas. Para isso, você pode usar iptables banais, por que não.
Ou seja, agora nossa topologia ficou um pouco mais complicada:
vamos além. Precisamos adicionar um servidor DHCP. O local mais ideal para a localização dos servidores DHCP para cada um dos clientes será o nó de controle já mencionado acima, onde os namespaces estão localizados:
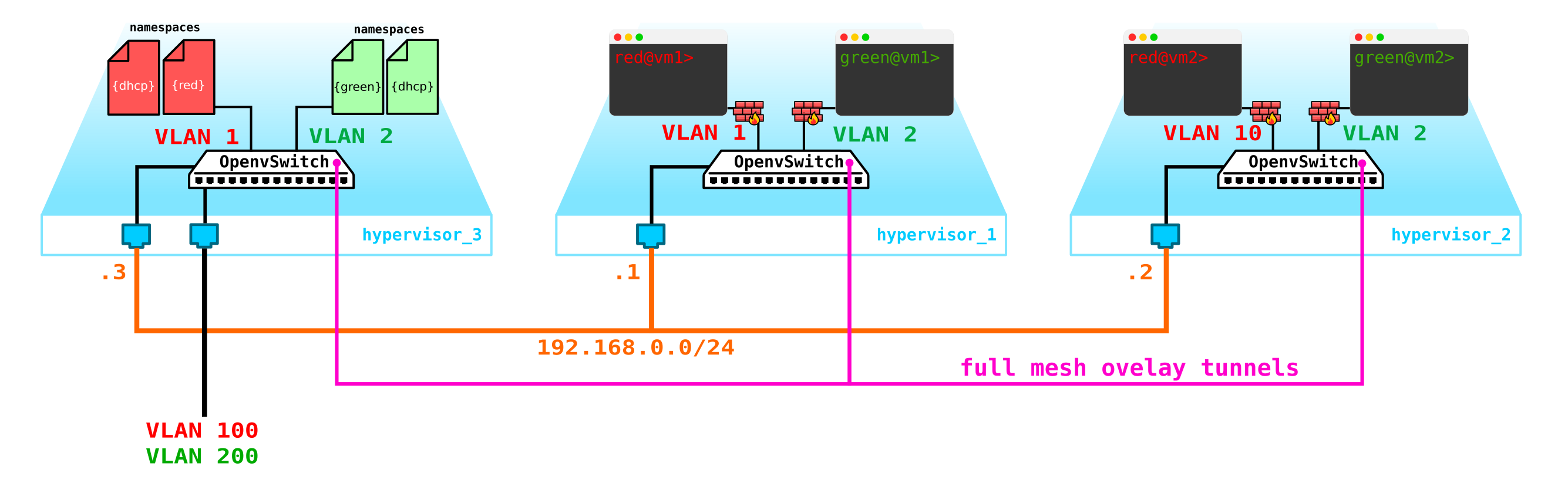
No entanto, existe um pequeno problema. E se tudo for reiniciado e todas as informações de concessão de endereço DHCP desaparecerem. É lógico que novos endereços sejam emitidos para as máquinas, o que não é muito conveniente. Existem duas saídas - use nomes de domínio e adicione um servidor DNS para cada cliente, então o endereço não será muito importante para nós (por analogia com a parte da rede em k8s) - mas há um problema com redes externas, uma vez que endereços também podem ser emitidos nelas via DHCP - você precisa sincronizar com servidores DNS na plataforma de nuvem e um servidor DNS externo, que, na minha opinião, não é muito flexível, mas bastante possível. Ou a segunda opção é usar metadados - ou seja, salvar informações sobre o endereço emitido para a máquina para que o servidor DHCP saiba qual endereço enviar para a máquina se a máquina já tiver recebido um endereço. A segunda opção é mais simples e flexível, pois permite salvar informações adicionais sobre o carro.Agora adicione os metadados do agente ao esquema:
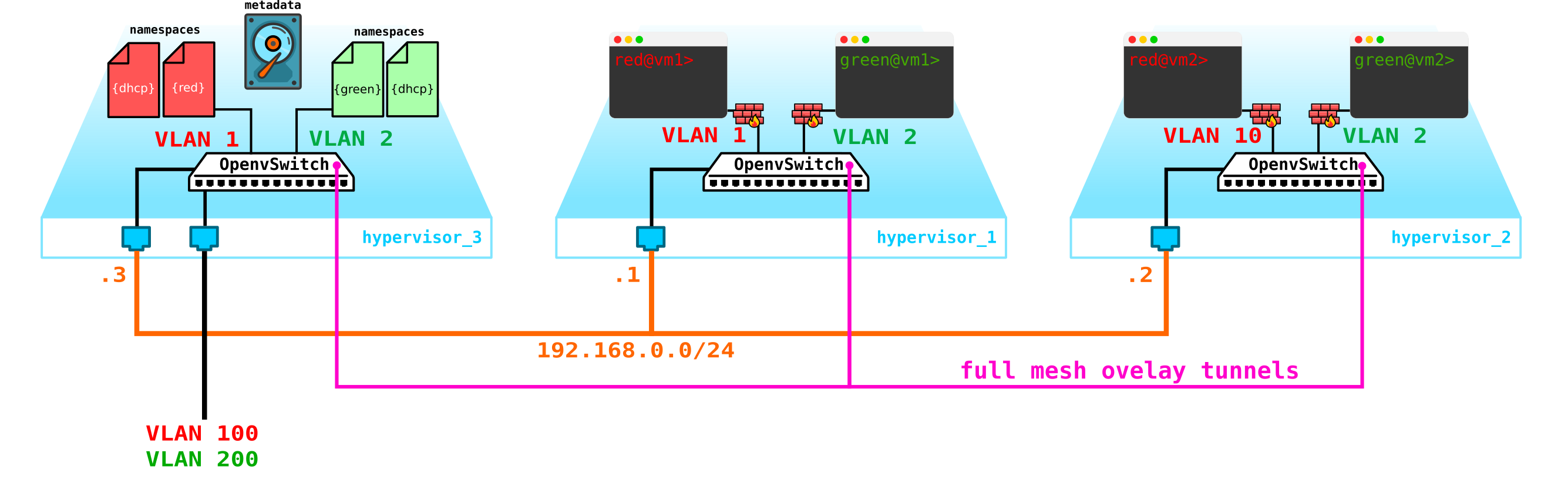
Outra questão que também deve ser santificada é a possibilidade de utilizar uma rede externa para todos os clientes, uma vez que as redes externas, se quiserem ser válidas em toda a rede, serão complexas - é preciso alocar e controlar constantemente a alocação dessas redes. A capacidade de usar uma única rede externa pré-configurada para todos os clientes será muito útil ao criar uma nuvem pública. Isso simplificará a implantação da máquina, pois não temos que verificar o banco de dados de endereços e escolher um espaço de endereço exclusivo para a rede externa de cada cliente. Além disso, podemos registrar uma rede externa com antecedência e, no momento da implantação, precisaremos apenas associar endereços externos às máquinas clientes.
E aqui o NAT vem em socorro - nós apenas tornamos possível que os clientes possam ir para o mundo exterior através do namespace padrão usando a tradução NAT. Bem, aqui está um pequeno problema. É bom se o servidor cliente atuar como um cliente e não como um servidor - ou seja, ele inicia em vez de aceitar conexões. Mas conosco será o contrário. Nesse caso, precisamos fazer o NAT de destino para que, ao receber o tráfego, o nó de controle entenda que esse tráfego é destinado à máquina virtual A do cliente A, o que significa que precisamos fazer a tradução do NAT de um endereço externo, por exemplo 100.1.1.1 para um endereço interno 10.0.0.1. Neste caso, embora todos os clientes utilizem a mesma rede, o isolamento interno é totalmente preservado. Ou seja, precisamos fazer dNAT e sNAT no nó de controle.Use uma única rede com a atribuição de endereços flutuantes ou redes externas, ou ambas ao mesmo tempo - devido ao fato de que deseja arrastar para a nuvem. Não adicionaremos endereços flutuantes ao diagrama, mas deixaremos as redes externas já adicionadas anteriormente - cada cliente tem sua própria rede externa (no diagrama, eles são designados como vlan 100 e 200 na interface externa).
Como resultado, obtivemos uma solução interessante e ao mesmo tempo bem pensada, que possui uma certa flexibilidade, mas até o momento não possui mecanismos de tolerância a falhas.
Em primeiro lugar, temos apenas um nó de controle - sua falha levará ao colapso de todos os sistemas. Para corrigir esse problema, você precisa fazer pelo menos um quorum de 3 nós. Vamos adicionar isso ao diagrama:
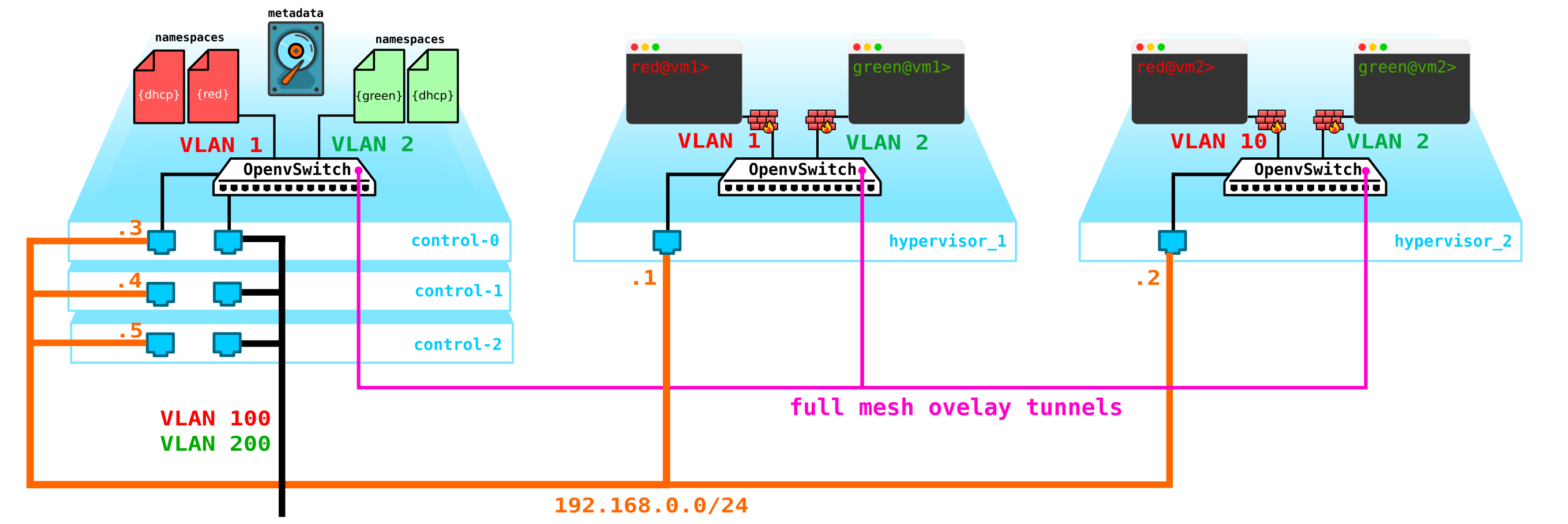
Naturalmente, todos os nós estão sincronizados e quando o nó ativo sair, outro nó assumirá suas responsabilidades.
O próximo problema são os discos da máquina virtual. No momento, eles estão armazenados nos próprios hipervisores e, em caso de problemas com o hipervisor, perdemos todos os dados - e a presença de um raid não ajudará em nada se perdermos não o disco, mas todo o servidor. Para fazer isso, precisamos fazer um serviço que funcionará como um front-end para algum armazenamento. O tipo de armazenamento não é particularmente importante para nós, mas deve proteger nossos dados contra falhas do disco e do nó e, possivelmente, de todo o gabinete. Existem várias opções aqui - claro que existem redes SAN com Fibre Channel, mas sejamos honestos - FC já é uma relíquia do passado - um análogo do E1 no transporte - sim, concordo, ainda é usado, mas apenas onde é absolutamente impossível sem ele. Portanto, eu não implantaria voluntariamente a rede FC em 2020, sabendo que existem outras alternativas mais interessantes.Embora cada um seja o seu e talvez haja quem acredite que o FC com todas as suas limitações é tudo de que precisamos - não vou discutir, cada um tem a sua opinião. No entanto, a solução mais interessante na minha opinião é usar SDS, por exemplo Ceph.
Ceph permite-lhe solução de armazenamento de construção vyskodostupnoe com um monte de opções para redundância, uma vez que a paridade de código (RAID analógico 5 ou 6) terminando com uma replicação completa de dados ao longo de vários discos baseados em servidores de localização de disco e servidores em armários e assim por diante.
Para A montagem Ceph precisa de mais 3 nós. A interação com o armazenamento também será realizada via rede usando serviços de armazenamento de bloco, objeto e arquivo. Adicione armazenamento ao esquema:
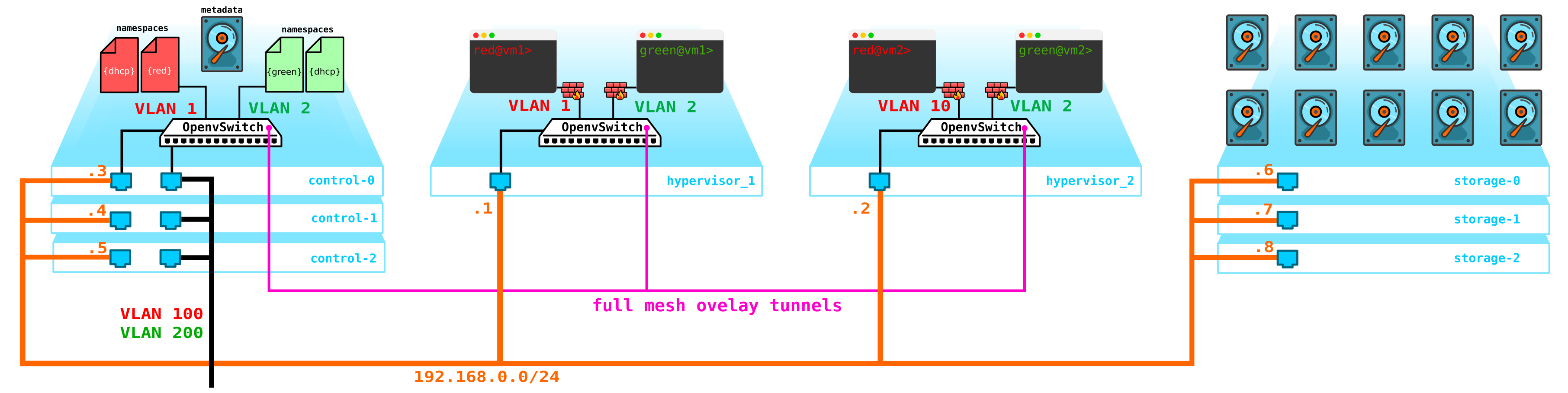
: compute — — storage+compute — ceph storage. — SDS . — — storage ( ) — CPU SDS ( , , ). compute storage.Tudo isso precisa ser gerenciado de alguma forma - precisamos de algo por meio do qual possamos criar uma máquina, rede, roteador virtual, etc. Para fazer isso, adicione um serviço ao nó de controle que funcionará como um painel - o cliente será capaz de se conectar a este portal via http / https e faça o que for necessário (bem, quase).
Como resultado, agora temos um sistema tolerante a falhas. Todos os elementos dessa infraestrutura devem ser gerenciados de alguma forma. Foi descrito anteriormente que o Openstack é um conjunto de projetos, cada um dos quais fornece alguma função específica. Como podemos ver, existem elementos mais do que suficientes que precisam ser configurados e controlados. Hoje vamos falar sobre a parte da rede.
Arquitetura de nêutrons
No OpenStack, é o Neutron o responsável por conectar as portas das máquinas virtuais a uma rede L2 comum, garantindo o roteamento do tráfego entre as VMs localizadas em diferentes redes L2, bem como o roteamento para fora, fornecendo serviços como NAT, IP flutuante, DHCP, etc. A
operação de alto nível do serviço de rede ( parte básica) pode ser descrita como segue.
Ao iniciar a VM, o serviço de rede:
- Cria uma porta para esta VM (ou portas) e notifica o serviço DHCP sobre isso;
- Um novo dispositivo de rede virtual é criado (via libvirt);
- VM se conecta à porta (portas) criada na etapa 1;
Estranhamente, mas no centro do trabalho do Neutron estão os mecanismos padrão familiares a todos que já mergulharam no Linux - são namespaces, iptables, pontes de linux, openvswitch, conntrack, etc.
Deve ser imediatamente esclarecido que o Neutron não é um controlador SDN.
O Neutron consiste em vários componentes interconectados:
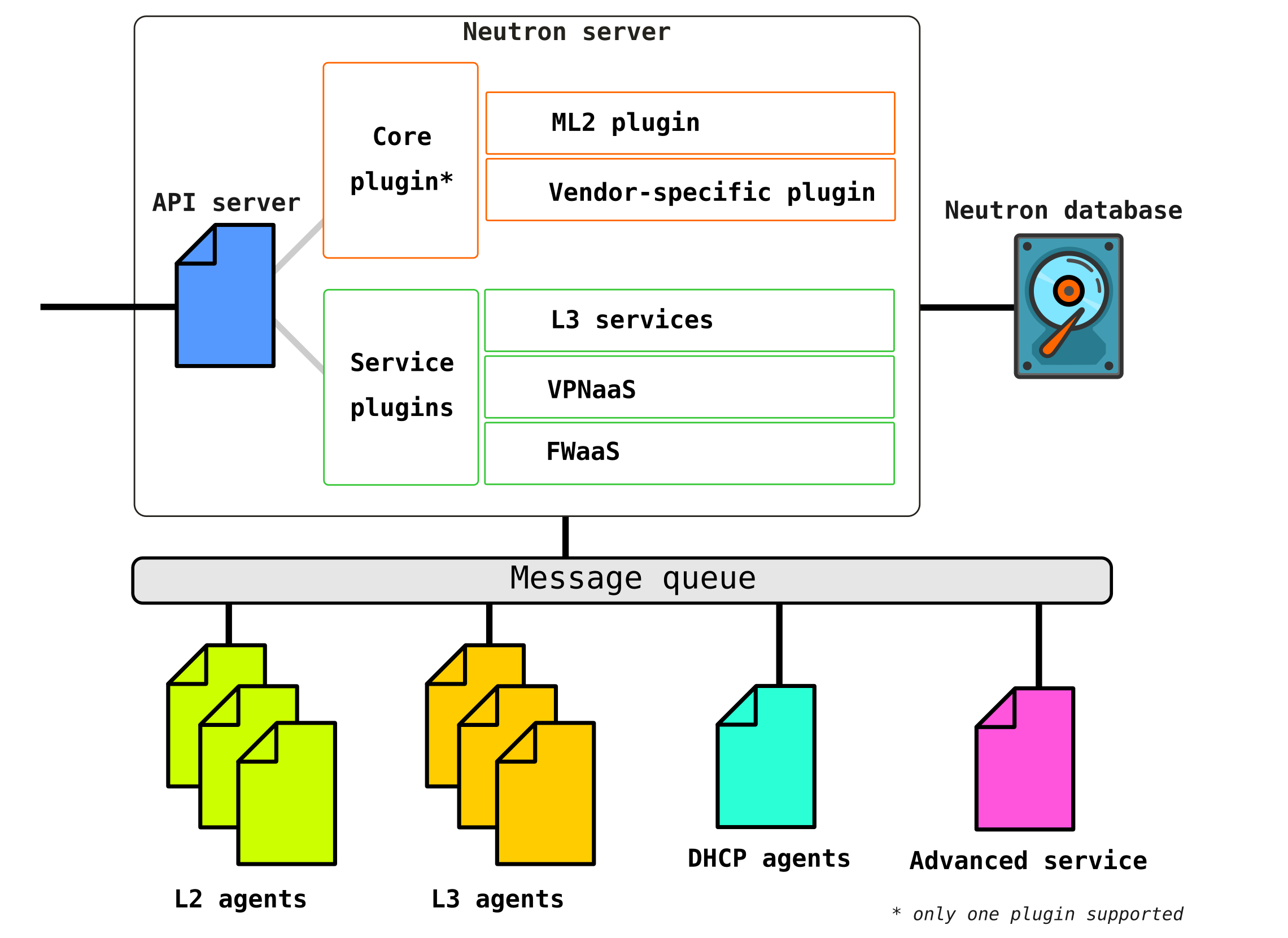
Openstack-neutron-server é um daemon que funciona com solicitações do usuário por meio de uma API. Este daemon não prescreve nenhuma conectividade de rede, mas fornece as informações necessárias para seus plug-ins, que então configuram o elemento de rede necessário. Os agentes Neutron nos nós do OpenStack se registram no servidor Neutron.
O Neutron-server é na verdade um aplicativo escrito em python, consistindo em duas partes:
- Serviço REST
- Plug-in de nêutrons (núcleo / serviço)
Um serviço REST é projetado para receber chamadas de API de outros componentes (por exemplo, uma solicitação para fornecer algumas informações, etc.).
Plug-ins são componentes / módulos de software de plug-in que são chamados sobre solicitações de API - ou seja, um serviço é atribuído por meio deles. Os plug-ins são divididos em dois tipos - serviço e raiz. Como regra, o plug-in horse é o principal responsável por gerenciar o espaço de endereço e as conexões L2 entre as VMs, e os plug-ins de serviço já fornecem funcionalidade adicional, como VPN ou FW.
A lista de plugins disponíveis para hoje pode ser vista por exemplo aqui.
Pode haver vários plugins de serviço, mas pode haver apenas um plugin Horse.
Openstack-neutron-ml2É o plugin raiz padrão do Openstack. Este plugin possui uma arquitetura modular (ao contrário de seu predecessor) e configura o serviço de rede através dos drivers conectados a ele. Vamos considerar o próprio plugin um pouco mais tarde, pois na verdade ele dá a flexibilidade que o OpenStack tem na parte da rede. O plugin raiz pode ser substituído (por exemplo, o Contrail Networking faz essa substituição).
Serviço RPC (rabbitmq-server) - Um serviço que fornece gerenciamento de fila e comunicação com outros serviços OpenStack, bem como comunicação entre agentes de serviço de rede.
Agentes de rede - agentes localizados em cada nó por meio dos quais os serviços de rede são configurados.
Os agentes são de vários tipos.
O agente principal éAgente L2 . Esses agentes são executados em cada um dos hipervisores, incluindo nós de controle (mais precisamente, em todos os nós que fornecem qualquer serviço para locatários) e sua função principal é conectar máquinas virtuais a uma rede L2 comum, bem como gerar alertas quando ocorrer algum evento (por exemplo desativar / ativar a porta).
O próximo agente, não menos importante, é o agente L3... Por padrão, este agente é executado exclusivamente no nó da rede (muitas vezes um nó da rede é combinado com um nó de controle) e fornece roteamento entre as redes de locatários (tanto entre suas redes e redes de outros locatários, e está disponível para o mundo externo, fornecendo serviços NAT e DHCP). No entanto, ao usar um DVR (roteador distribuído), a necessidade de um plug-in L3 também aparece nos nós de computação.
O agente L3 usa namespaces Linux para fornecer a cada locatário um conjunto de suas próprias redes isoladas e a funcionalidade de roteadores virtuais que roteiam o tráfego e fornecem serviços de gateway para redes da Camada 2.
Banco de dados - um banco de dados de identificadores de redes, sub-redes, portas, pools, etc.
Na verdade, o Neutron aceita solicitações de API desde a criação de quaisquer entidades de rede, autentica a solicitação e, por meio de RPC (se endereçar a algum plug-in ou agente) ou API REST (se se comunicar em SDN), envia aos agentes (por meio de plug-ins) as instruções necessárias para organizar o serviço solicitado ...
Agora vamos passar para a instalação de teste (como ele é implantado e o que contém mais tarde na parte prática) e ver onde qual componente está localizado:
(overcloud) [stack@undercloud ~]$ openstack network agent list
+--------------------------------------+--------------------+-------------------------------------+-------------------+-------+-------+---------------------------+
| ID | Agent Type | Host | Availability Zone | Alive | State | Binary |
+--------------------------------------+--------------------+-------------------------------------+-------------------+-------+-------+---------------------------+
| 10495de9-ba4b-41fe-b30a-b90ec3f8728b | Open vSwitch agent | overcloud-novacompute-1.localdomain | None | :-) | UP | neutron-openvswitch-agent |
| 1515ad4a-5972-46c3-af5f-e5446dff7ac7 | L3 agent | overcloud-controller-0.localdomain | nova | :-) | UP | neutron-l3-agent |
| 322e62ca-1e5a-479e-9a96-4f26d09abdd7 | DHCP agent | overcloud-controller-0.localdomain | nova | :-) | UP | neutron-dhcp-agent |
| 9c1de2f9-bac5-400e-998d-4360f04fc533 | Open vSwitch agent | overcloud-novacompute-0.localdomain | None | :-) | UP | neutron-openvswitch-agent |
| d99c5657-851e-4d3c-bef6-f1e3bb1acfb0 | Open vSwitch agent | overcloud-controller-0.localdomain | None | :-) | UP | neutron-openvswitch-agent |
| ff85fae6-5543-45fb-a301-19c57b62d836 | Metadata agent | overcloud-controller-0.localdomain | None | :-) | UP | neutron-metadata-agent |
+--------------------------------------+--------------------+-------------------------------------+-------------------+-------+-------+---------------------------+
(overcloud) [stack@undercloud ~]$ 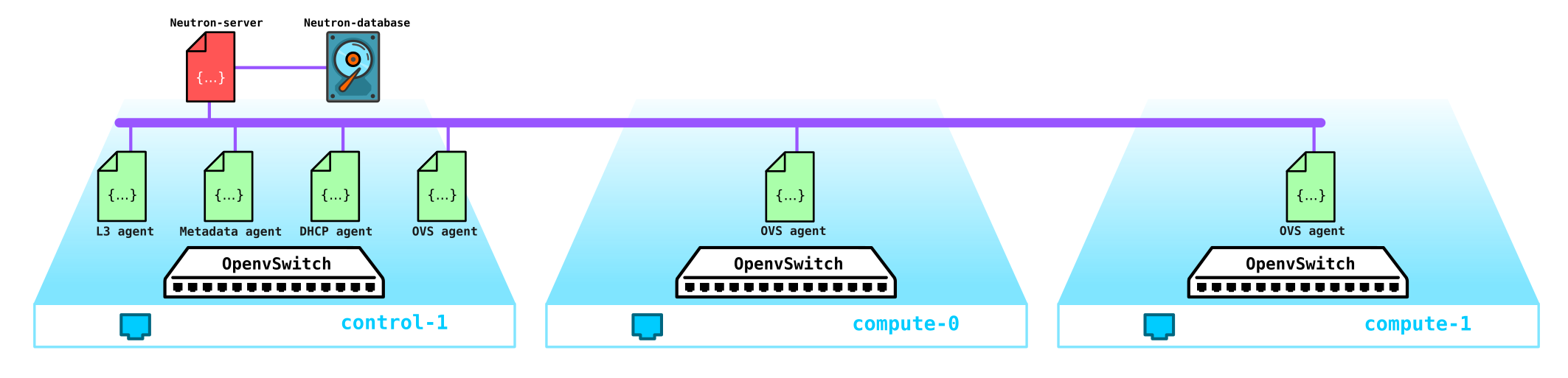
Na verdade, essa é toda a estrutura do Neutron. Agora vale a pena dedicar algum tempo ao plugin ML2.
Camada modular 2
Conforme declarado acima, o plug-in é um plug-in raiz padrão do OpenStack e tem uma arquitetura modular.
O antecessor do plug-in ML2 tinha uma estrutura monolítica, o que não permitia, por exemplo, o uso de uma mistura de várias tecnologias em uma instalação. Por exemplo, você não pode usar openvswitch e linuxbridge ao mesmo tempo - nem o primeiro nem o segundo. Por esta razão, foi criado o plugin ML2 com sua arquitetura.
ML2 tem dois componentes - dois tipos de drivers: drivers de tipo e drivers de mecanismo.
Os drivers de tipo definem as tecnologias que serão usadas para organizar a conectividade de rede, como VxLAN, VLAN, GRE. Neste caso, o driver permite o uso de diferentes tecnologias. A tecnologia padrão é o encapsulamento VxLAN para redes overlay e redes externas vlan.
Os drivers de tipo incluem os seguintes tipos de redes:
Flat - uma rede sem marcação
VLAN - uma rede marcada
Local - um tipo especial de rede para instalações multifuncionais (tais instalações são necessárias para desenvolvedores ou para treinamento)
GRE - rede sobreposta usando túneis GRE
VxLAN - rede de sobreposição usando túneis VxLAN
Os drivers de mecanismo definem os meios que fornecem a organização das tecnologias especificadas no driver de tipo - por exemplo, openvswitch, sr-iov, opendaylight, OVN, etc.
Dependendo da implementação deste driver, ou agentes controlados por Neutron serão usados, ou conexões com um controlador SDN externo serão usadas, que cuida de todos os problemas de organização de redes L2, roteamento, etc.
Exemplo Se usarmos ML2 junto com OVS, então em cada nó computacional é configurado com um agente L2 que gerencia o OVS. Porém, se usarmos, por exemplo, OVN ou OpenDayLight, então o controle OVS fica sob sua jurisdição - o Neutron através do plugin root dá comandos ao controlador, e ele já faz o que lhe foi dito.
Vamos refrescar nossa memória Abra vSwitch
No momento, um dos principais componentes do OpenStack é o Open vSwitch.
Ao instalar o OpenStack sem nenhum SDN de fornecedor adicional, como Juniper Contrail ou Nokia Nuage, OVS é o principal componente da rede em nuvem e, junto com iptables, conntrack, namespaces, permite que você organize uma rede overlay completa com multilocação. Naturalmente, esse componente pode ser substituído, por exemplo, ao usar soluções SDN proprietárias de terceiros (fornecedor).
OVS é um switch de software de código aberto projetado para uso em ambientes virtualizados como encaminhador de tráfego virtual.
No momento, OVS tem uma funcionalidade muito decente, que inclui tecnologias como QoS, LACP, VLAN, VxLAN, GENEVE, OpenFlow, DPDK, etc.
Nota: inicialmente, OVS não foi concebido como um soft switch para funções de telecomunicações de alta carga e foi mais projetado para funções de TI com menos largura de banda, como um servidor WEB ou servidor de correio. Porém, o OVS está sendo finalizado e as atuais implementações OVS melhoraram muito seu desempenho e capacidades, o que permite que seja utilizado por operadoras de telecomunicações com funções de alta carga, por exemplo, existe uma implementação OVS com suporte de aceleração DPDK.
Existem três componentes OVS importantes que você deve conhecer:
- Módulo de kernel - um componente localizado no espaço do kernel que processa o tráfego com base nas regras recebidas do controle;
- vSwitch daemon (ovs-vswitchd) — , user space, kernel —
- Database server — , , OVS, . OVSDB SDN .
Tudo isso também é acompanhado por um conjunto de utilitários de diagnóstico e gerenciamento, como ovs-vsctl, ovs-appctl, ovs-ofctl, etc.
Atualmente, o Openstack é amplamente utilizado pelas operadoras de telecomunicações para migrar funções de rede para ele, como EPC, SBC, HLR e assim por diante. Algumas funções podem viver sem problemas com OVS na forma em que está, mas por exemplo, o EPC processa o tráfego do assinante - isto é, ele passa uma grande quantidade de tráfego por si mesmo (agora os volumes de tráfego chegam a várias centenas de gigabits por segundo). Naturalmente, direcionar esse tráfego através do espaço do kernel (já que o encaminhador está localizado lá por padrão) não é uma boa ideia. Portanto, o OVS é frequentemente implantado inteiramente no espaço do usuário usando a tecnologia de aceleração DPDK para encaminhar o tráfego da NIC para o espaço do usuário, ignorando o kernel.
Nota: para uma nuvem implantada para funções de telecomunicações, é possível enviar o tráfego do nó de computação ignorando OVS diretamente para o equipamento de comutação. Os mecanismos SR-IOV e Passthrough são usados para esse propósito.
Como funciona em um layout real?
Bem, agora vamos passar para a parte prática e ver como tudo funciona na prática.
Vamos começar implantando uma instalação simples do Openstack. Como não tenho um conjunto de servidores disponíveis para experimentos, montaremos o layout em um servidor físico a partir de máquinas virtuais. Sim, claro, tal solução não é adequada para fins comerciais, mas para olhar um exemplo de como a rede funciona no Openstack, tal instalação é suficiente para os olhos. Além disso, essa instalação para fins de treinamento é ainda mais interessante - já que você pode pegar o tráfego, etc.
Como precisamos ver apenas a parte básica, não podemos usar várias redes, mas aumentar tudo usando apenas duas redes, sendo que a segunda rede neste layout será usada exclusivamente para acesso ao undercloud e ao servidor dns. Não tocaremos em redes externas por enquanto - este é um tópico para um grande artigo separado.
Então, vamos começar em ordem. Primeiro, um pouco de teoria. Vamos instalar o Openstack usando TripleO (Openstack no Openstack). A essência do TripleO é que instalamos um Openstack all-in-one (ou seja, em um nó), chamado undercloud, e então usamos os recursos do Openstack implantado para instalar um Openstack destinado à exploração, chamado overcloud. O Undercloud usará a capacidade inerente de gerenciar servidores físicos (bare metal) - o projeto Ironic - para provisionar hipervisores que atuarão como nós de computação, controle e armazenamento. Ou seja, não usamos nenhuma ferramenta de terceiros para implantar o Openstack - implantamos o Openstack com o Openstack. Mais adiante, a instalação ficará muito mais clara, então não vamos parar por aí e seguir em frente.
: Openstack, . — , , . . ceph ( ) (Storage management Storage) , , QoS , . .
Observação: como vamos executar máquinas virtuais em um ambiente virtual baseado em máquinas virtuais, primeiro precisamos habilitar a virtualização aninhada.
Você pode verificar se a virtualização aninhada está habilitada ou não assim:
[root@hp-gen9 bormoglotx]# cat /sys/module/kvm_intel/parameters/nested N [root@hp-gen9 bormoglotx]#
Se você vir a letra N, então habilitamos o suporte para virtualização aninhada de acordo com qualquer guia que você encontrar na rede, por exemplo, este .
Precisamos montar o seguinte esquema a partir das máquinas virtuais:

No meu caso, para a conectividade das máquinas virtuais que farão parte da instalação futura (e eu tenho 7 delas, mas você pode sobreviver com 4 se não tiver muitos recursos), usei o OpenvSwitch. Eu criei uma ponte ovs e conectei máquinas virtuais a ela por meio de grupos de portas. Para fazer isso, criei um arquivo xml no seguinte formato:
[root@hp-gen9 ~]# virsh net-dumpxml ovs-network-1
<network>
<name>ovs-network-1</name>
<uuid>7a2e7de7-fc16-4e00-b1ed-4d190133af67</uuid>
<forward mode='bridge'/>
<bridge name='ovs-br1'/>
<virtualport type='openvswitch'/>
<portgroup name='trunk-1'>
<vlan trunk='yes'>
<tag id='100'/>
<tag id='101'/>
<tag id='102'/>
</vlan>
</portgroup>
<portgroup name='access-100'>
<vlan>
<tag id='100'/>
</vlan>
</portgroup>
<portgroup name='access-101'>
<vlan>
<tag id='101'/>
</vlan>
</portgroup>
</network>Três portas do grupo são declaradas aqui - dois acesso e um tronco (o último era necessário para um servidor DNS, mas você pode fazer sem ele ou aumentá-lo na máquina host - isso é o que for mais conveniente para você). Em seguida, usando este modelo, declaramos nosso é via virsh net-define:
virsh net-define ovs-network-1.xml
virsh net-start ovs-network-1
virsh net-autostart ovs-network-1 Agora vamos editar a configuração das portas do hipervisor:
[root@hp-gen9 ~]# cat /etc/sysconfig/network-scripts/ifcfg-ens1f0
TYPE=Ethernet
NAME=ens1f0
DEVICE=ens1f0
TYPE=OVSPort
DEVICETYPE=ovs
OVS_BRIDGE=ovs-br1
ONBOOT=yes
OVS_OPTIONS="trunk=100,101,102"
[root@hp-gen9 ~]
[root@hp-gen9 ~]# cat /etc/sysconfig/network-scripts/ifcfg-ovs-br1
DEVICE=ovs-br1
DEVICETYPE=ovs
TYPE=OVSBridge
BOOTPROTO=static
ONBOOT=yes
IPADDR=192.168.255.200
PREFIX=24
[root@hp-gen9 ~]# Nota: neste cenário, o endereço na porta ovs-br1 não estará disponível, uma vez que não possui uma tag vlan. Para corrigir isso, emita o comando sudo ovs-vsctl set port ovs-br1 tag = 100. Porém, após uma reinicialização, essa tag irá desaparecer (se alguém souber como fazê-la permanecer no lugar, ficarei muito grato). Mas isso não é tão importante, porque precisaremos desse endereço apenas no momento da instalação e não será necessário quando o Openstack estiver totalmente implantado.Em seguida, criamos um carro com nuvem subterrânea:
virt-install -n undercloud --description "undercloud" --os-type=Linux --os-variant=centos7.0 --ram=8192 --vcpus=8 --disk path=/var/lib/libvirt/images/undercloud.qcow2,bus=virtio,size=40,format=qcow2 --network network:ovs-network-1,model=virtio,portgroup=access-100 --network network:ovs-network-1,model=virtio,portgroup=access-101 --graphics none --location /var/lib/libvirt/boot/CentOS-7-x86_64-Minimal-2003.iso --extra-args console=ttyS0Durante a instalação, você define todos os parâmetros necessários, como o nome da máquina, senhas, usuários, servidores ntp, etc., você pode configurar imediatamente as portas, mas após a instalação é mais fácil para mim entrar na máquina através do console e corrigir os arquivos necessários. Se você já tem uma imagem pronta, pode usá-la, ou faça como eu - baixe a imagem mínima do Centos 7 e use-a para instalar a VM.
Após a instalação bem-sucedida, você deve ter uma máquina virtual na qual pode instalar o undercloud
[root@hp-gen9 bormoglotx]# virsh list
Id Name State
----------------------------------------------------
6 dns-server running
62 undercloud runningPrimeiro, instalamos as ferramentas necessárias durante o processo de instalação:
sudo yum update -y
sudo yum install -y net-tools
sudo yum install -y wget
sudo yum install -y ipmitool
Instalando o Undercloud
Crie um usuário stack, defina uma senha, adicione-o ao sudoer e dê a ele a capacidade de executar comandos root via sudo sem ter que inserir uma senha:
useradd stack
passwd stack
echo “stack ALL=(root) NOPASSWD:ALL” > /etc/sudoers.d/stack
chmod 0440 /etc/sudoers.d/stackAgora especificamos o nome completo de undercloud no arquivo hosts:
vi /etc/hosts
127.0.0.1 undercloud.openstack.rnd localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6Em seguida, adicione os repositórios e instale o software de que precisamos:
sudo yum install -y https://trunk.rdoproject.org/centos7/current/python2-tripleo-repos-0.0.1-0.20200409224957.8bac392.el7.noarch.rpm
sudo -E tripleo-repos -b queens current
sudo -E tripleo-repos -b queens current ceph
sudo yum install -y python-tripleoclient
sudo yum install -y ceph-ansibleObservação: se você não planeja instalar o ceph, não precisa inserir comandos relacionados ao ceph. Usei a liberação do Queens, mas você pode usar o que quiser.Em seguida, copie o arquivo de configuração do undercloud para o diretório inicial da pilha do usuário:
cp /usr/share/instack-undercloud/undercloud.conf.sample ~/undercloud.confAgora precisamos corrigir este arquivo ajustando-o à nossa instalação.
Adicione estas linhas ao início do arquivo:
vi undercloud.conf
[DEFAULT]
undercloud_hostname = undercloud.openstack.rnd
local_ip = 192.168.255.1/24
network_gateway = 192.168.255.1
undercloud_public_host = 192.168.255.2
undercloud_admin_host = 192.168.255.3
undercloud_nameservers = 192.168.255.253
generate_service_certificate = false
local_interface = eth0
local_mtu = 1450
network_cidr = 192.168.255.0/24
masquerade = true
masquerade_network = 192.168.255.0/24
dhcp_start = 192.168.255.11
dhcp_end = 192.168.255.50
inspection_iprange = 192.168.255.51,192.168.255.100
scheduler_max_attempts = 10Portanto, vá até as configurações:
undercloud_hostname - o nome completo do servidor de undercloud deve corresponder à entrada no servidor DNS
local_ip - endereço local undercloud para provizhening rede
network_gateway - o mesmo endereço local, que servirá como gateway para acesso ao mundo externo durante a instalação nó overcloud, também corresponde ao ip local
undercloud_public_host - endereço API externo, atribuído a qualquer endereço livre da rede de provisionamento
undercloud_admin_host endereço API interno, atribuído a qualquer endereço livre da rede de provisionamento
undercloud_nameservers - servidor DNS
generate_service_certificate- esta linha é muito importante no exemplo atual, porque se não for definida como falsa, você receberá um erro durante a instalação, o problema é descrito na interface
local_interface do rastreador de bugs do Red Hat no provisionamento de rede. Esta interface será reconfigurada durante a implantação da undercloud, então você precisa ter duas interfaces na undercloud - uma para acessá-la, a outra para provisionar
local_mtu - MTU. Como temos um laboratório de testes e MTU tenho 1.500 portas OVS Svicha, é necessário colocar em valor 1450, que teria sido encapsulado em pacotes VxLAN
network_cidr - provisioning network
masquerade - o uso de NAT para acessar a rede externa
masquerade_network - uma rede que fará NAT -sya
dhcp_start - o endereço inicial do pool de endereços a partir do qual os endereços serão atribuídos a nós durante overcloud implantação
dhcp_end - o endereço final do pool de endereços a partir do qual os endereços serão atribuídos a nós durante overcloud implantação
inspection_iprange - o pool de endereços necessários para a introspecção (não deve se cruzam com a piscina acima mencionada )
scheduler_max_attempts - o número máximo de tentativas para instalar o overcloud (deve ser maior ou igual ao número de nós)
Depois que o arquivo é descrito, você pode dar o comando para implantar o undercloud:
openstack undercloud install
O procedimento leva de 10 a 30 minutos, dependendo do seu ferro. Por fim, você deve ver uma saída como esta:
vi undercloud.conf
2020-08-13 23:13:12,668 INFO:
#############################################################################
Undercloud install complete.
The file containing this installation's passwords is at
/home/stack/undercloud-passwords.conf.
There is also a stackrc file at /home/stack/stackrc.
These files are needed to interact with the OpenStack services, and should be
secured.
#############################################################################Esta saída diz que você instalou com sucesso o undercloud e agora você pode verificar o status do undercloud e prosseguir com a instalação do overcloud.
Se você olhar a saída de ifconfig, verá que uma nova interface de ponte apareceu
[stack@undercloud ~]$ ifconfig
br-ctlplane: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 192.168.255.1 netmask 255.255.255.0 broadcast 192.168.255.255
inet6 fe80::5054:ff:fe2c:89e prefixlen 64 scopeid 0x20<link>
ether 52:54:00:2c:08:9e txqueuelen 1000 (Ethernet)
RX packets 14 bytes 1095 (1.0 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 20 bytes 1292 (1.2 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0A implantação do overcloud agora será realizada por meio desta interface.
Na saída abaixo, pode-se ver que temos todos os serviços em um nó:
(undercloud) [stack@undercloud ~]$ openstack host list
+--------------------------+-----------+----------+
| Host Name | Service | Zone |
+--------------------------+-----------+----------+
| undercloud.openstack.rnd | conductor | internal |
| undercloud.openstack.rnd | scheduler | internal |
| undercloud.openstack.rnd | compute | nova |
+--------------------------+-----------+----------+Abaixo está a configuração da parte da rede da nuvem:
(undercloud) [stack@undercloud ~]$ python -m json.tool /etc/os-net-config/config.json
{
"network_config": [
{
"addresses": [
{
"ip_netmask": "192.168.255.1/24"
}
],
"members": [
{
"dns_servers": [
"192.168.255.253"
],
"mtu": 1450,
"name": "eth0",
"primary": "true",
"type": "interface"
}
],
"mtu": 1450,
"name": "br-ctlplane",
"ovs_extra": [
"br-set-external-id br-ctlplane bridge-id br-ctlplane"
],
"routes": [],
"type": "ovs_bridge"
}
]
}
(undercloud) [stack@undercloud ~]$Instalação de overcloud
No momento, temos apenas nuvem subterrânea, e não temos nós suficientes a partir dos quais a nuvem será construída. Portanto, em primeiro lugar, implantaremos as máquinas virtuais de que precisamos. Durante a implantação, a nuvem em si instalará o SO e o software necessário na máquina de overcloud - ou seja, não precisamos implantar totalmente a máquina, mas apenas criar um disco (ou discos) para ela e determinar seus parâmetros - ou seja, temos um servidor vazio sem um SO instalado nele ...
Vá para a pasta com os discos de nossas máquinas virtuais e crie discos do tamanho necessário:
cd /var/lib/libvirt/images/
qemu-img create -f qcow2 -o preallocation=metadata control-1.qcow2 60G
qemu-img create -f qcow2 -o preallocation=metadata compute-1.qcow2 60G
qemu-img create -f qcow2 -o preallocation=metadata compute-2.qcow2 60G
qemu-img create -f qcow2 -o preallocation=metadata storage-1.qcow2 160G
qemu-img create -f qcow2 -o preallocation=metadata storage-2.qcow2 160GComo atuamos a partir do root, precisamos alterar o proprietário desses discos para não ter problemas com os direitos:
[root@hp-gen9 images]# ls -lh
total 5.8G
drwxr-xr-x. 2 qemu qemu 4.0K Aug 13 16:15 backups
-rw-r--r--. 1 root root 61G Aug 14 03:07 compute-1.qcow2
-rw-r--r--. 1 root root 61G Aug 14 03:07 compute-2.qcow2
-rw-r--r--. 1 root root 61G Aug 14 03:07 control-1.qcow2
-rw-------. 1 qemu qemu 41G Aug 14 03:03 dns-server.qcow2
-rw-r--r--. 1 root root 161G Aug 14 03:07 storage-1.qcow2
-rw-r--r--. 1 root root 161G Aug 14 03:07 storage-2.qcow2
-rw-------. 1 qemu qemu 41G Aug 14 03:07 undercloud.qcow2
[root@hp-gen9 images]#
[root@hp-gen9 images]#
[root@hp-gen9 images]# chown qemu:qemu /var/lib/libvirt/images/*qcow2
[root@hp-gen9 images]# ls -lh
total 5.8G
drwxr-xr-x. 2 qemu qemu 4.0K Aug 13 16:15 backups
-rw-r--r--. 1 qemu qemu 61G Aug 14 03:07 compute-1.qcow2
-rw-r--r--. 1 qemu qemu 61G Aug 14 03:07 compute-2.qcow2
-rw-r--r--. 1 qemu qemu 61G Aug 14 03:07 control-1.qcow2
-rw-------. 1 qemu qemu 41G Aug 14 03:03 dns-server.qcow2
-rw-r--r--. 1 qemu qemu 161G Aug 14 03:07 storage-1.qcow2
-rw-r--r--. 1 qemu qemu 161G Aug 14 03:07 storage-2.qcow2
-rw-------. 1 qemu qemu 41G Aug 14 03:08 undercloud.qcow2
[root@hp-gen9 images]# Nota: se você planeja instalar o ceph para estudá-lo, crie pelo menos 3 nós com pelo menos dois discos, e no modelo indique que os discos virtuais vda, vdb, etc. serão usados.Ótimo, agora precisamos definir todas essas máquinas:
virt-install --name control-1 --ram 32768 --vcpus 8 --os-variant centos7.0 --disk path=/var/lib/libvirt/images/control-1.qcow2,device=disk,bus=virtio,format=qcow2 --noautoconsole --vnc --network network:ovs-network-1,model=virtio,portgroup=access-100 --network network:ovs-network-1,model=virtio,portgroup=trunk-1 --dry-run --print-xml > /tmp/control-1.xml
virt-install --name storage-1 --ram 16384 --vcpus 4 --os-variant centos7.0 --disk path=/var/lib/libvirt/images/storage-1.qcow2,device=disk,bus=virtio,format=qcow2 --noautoconsole --vnc --network network:ovs-network-1,model=virtio,portgroup=access-100 --dry-run --print-xml > /tmp/storage-1.xml
virt-install --name storage-2 --ram 16384 --vcpus 4 --os-variant centos7.0 --disk path=/var/lib/libvirt/images/storage-2.qcow2,device=disk,bus=virtio,format=qcow2 --noautoconsole --vnc --network network:ovs-network-1,model=virtio,portgroup=access-100 --dry-run --print-xml > /tmp/storage-2.xml
virt-install --name compute-1 --ram 32768 --vcpus 12 --os-variant centos7.0 --disk path=/var/lib/libvirt/images/compute-1.qcow2,device=disk,bus=virtio,format=qcow2 --noautoconsole --vnc --network network:ovs-network-1,model=virtio,portgroup=access-100 --dry-run --print-xml > /tmp/compute-1.xml
virt-install --name compute-2 --ram 32768 --vcpus 12 --os-variant centos7.0 --disk path=/var/lib/libvirt/images/compute-2.qcow2,device=disk,bus=virtio,format=qcow2 --noautoconsole --vnc --network network:ovs-network-1,model=virtio,portgroup=access-100 --dry-run --print-xml > /tmp/compute-2.xml No final existem os comandos --print-xml> /tmp/storage-1.xml, que cria um arquivo xml com a descrição de cada máquina na pasta / tmp /, se você não adicionar, não será possível definir as máquinas virtuais.
Agora precisamos definir todas essas máquinas em virsh:
virsh define --file /tmp/control-1.xml
virsh define --file /tmp/compute-1.xml
virsh define --file /tmp/compute-2.xml
virsh define --file /tmp/storage-1.xml
virsh define --file /tmp/storage-2.xml
[root@hp-gen9 ~]# virsh list --all
Id Name State
----------------------------------------------------
6 dns-server running
64 undercloud running
- compute-1 shut off
- compute-2 shut off
- control-1 shut off
- storage-1 shut off
- storage-2 shut off
[root@hp-gen9 ~]#Agora uma pequena nuance - tripleO usa IPMI para gerenciar os servidores durante a instalação e introspecção.
A introspecção é o processo de inspecionar o hardware a fim de obter seus parâmetros necessários para o provisionamento adicional de nós. A introspecção é realizada usando irônico - um serviço projetado para funcionar com servidores bare metal.
Mas aqui está o problema - se os servidores de ferro IPMI tiverem uma porta separada (ou porta compartilhada, mas isso não é importante), então as máquinas virtuais não têm essas portas. Aqui, uma muleta chamada vbmc vem em nosso socorro - um utilitário que permite emular uma porta IPMI. Esta nuance vale a pena prestar atenção especialmente para aqueles que desejam criar tal laboratório em um hipervisor ESXI - se, é claro, eu não sei se ele tem um análogo de vbmc, então você deve estar intrigado com esta questão antes de implantar tudo.
Instale o vbmc:
yum install yum install python2-virtualbmcSe o seu sistema operacional não conseguir encontrar o pacote, adicione o repositório:
yum install -y https://www.rdoproject.org/repos/rdo-release.rpmAgora vamos configurar o utilitário. Tudo é banal para desgraçar aqui. Agora é lógico que não há servidores na lista vbmc
[root@hp-gen9 ~]# vbmc list
[root@hp-gen9 ~]# Para que apareçam, eles devem ser declarados manualmente desta forma:
[root@hp-gen9 ~]# vbmc add control-1 --port 7001 --username admin --password admin
[root@hp-gen9 ~]# vbmc add storage-1 --port 7002 --username admin --password admin
[root@hp-gen9 ~]# vbmc add storage-2 --port 7003 --username admin --password admin
[root@hp-gen9 ~]# vbmc add compute-1 --port 7004 --username admin --password admin
[root@hp-gen9 ~]# vbmc add compute-2 --port 7005 --username admin --password admin
[root@hp-gen9 ~]#
[root@hp-gen9 ~]# vbmc list
+-------------+--------+---------+------+
| Domain name | Status | Address | Port |
+-------------+--------+---------+------+
| compute-1 | down | :: | 7004 |
| compute-2 | down | :: | 7005 |
| control-1 | down | :: | 7001 |
| storage-1 | down | :: | 7002 |
| storage-2 | down | :: | 7003 |
+-------------+--------+---------+------+
[root@hp-gen9 ~]#Acho que a sintaxe do comando é clara e sem explicação. No entanto, por enquanto, todas as nossas sessões estão no status DOWN. Para que eles passem para o status UP, você deve habilitá-los:
[root@hp-gen9 ~]# vbmc start control-1
2020-08-14 03:15:57,826.826 13149 INFO VirtualBMC [-] Started vBMC instance for domain control-1
[root@hp-gen9 ~]# vbmc start storage-1
2020-08-14 03:15:58,316.316 13149 INFO VirtualBMC [-] Started vBMC instance for domain storage-1
[root@hp-gen9 ~]# vbmc start storage-2
2020-08-14 03:15:58,851.851 13149 INFO VirtualBMC [-] Started vBMC instance for domain storage-2
[root@hp-gen9 ~]# vbmc start compute-1
2020-08-14 03:15:59,307.307 13149 INFO VirtualBMC [-] Started vBMC instance for domain compute-1
[root@hp-gen9 ~]# vbmc start compute-2
2020-08-14 03:15:59,712.712 13149 INFO VirtualBMC [-] Started vBMC instance for domain compute-2
[root@hp-gen9 ~]#
[root@hp-gen9 ~]#
[root@hp-gen9 ~]# vbmc list
+-------------+---------+---------+------+
| Domain name | Status | Address | Port |
+-------------+---------+---------+------+
| compute-1 | running | :: | 7004 |
| compute-2 | running | :: | 7005 |
| control-1 | running | :: | 7001 |
| storage-1 | running | :: | 7002 |
| storage-2 | running | :: | 7003 |
+-------------+---------+---------+------+
[root@hp-gen9 ~]#E o toque final - você precisa corrigir as regras de firewall (bem, ou desativá-lo completamente):
firewall-cmd --zone=public --add-port=7001/udp --permanent
firewall-cmd --zone=public --add-port=7002/udp --permanent
firewall-cmd --zone=public --add-port=7003/udp --permanent
firewall-cmd --zone=public --add-port=7004/udp --permanent
firewall-cmd --zone=public --add-port=7005/udp --permanent
firewall-cmd --reload
Agora vamos para a nuvem subterrânea e verificar se tudo funciona. O endereço da máquina host é 192.168.255.200, adicionamos o pacote ipmitool necessário à nuvem subterrânea durante a preparação para a implantação:
[stack@undercloud ~]$ ipmitool -I lanplus -U admin -P admin -H 192.168.255.200 -p 7001 power status
Chassis Power is off
[stack@undercloud ~]$ ipmitool -I lanplus -U admin -P admin -H 192.168.255.200 -p 7001 power on
Chassis Power Control: Up/On
[stack@undercloud ~]$
[root@hp-gen9 ~]# virsh list
Id Name State
----------------------------------------------------
6 dns-server running
64 undercloud running
65 control-1 runningComo você pode ver, lançamos com sucesso o nó de controle via vbmc. Agora desligue-o e siga em frente:
[stack@undercloud ~]$ ipmitool -I lanplus -U admin -P admin -H 192.168.255.200 -p 7001 power off
Chassis Power Control: Down/Off
[stack@undercloud ~]$ ipmitool -I lanplus -U admin -P admin -H 192.168.255.200 -p 7001 power status
Chassis Power is off
[stack@undercloud ~]$
[root@hp-gen9 ~]# virsh list --all
Id Name State
----------------------------------------------------
6 dns-server running
64 undercloud running
- compute-1 shut off
- compute-2 shut off
- control-1 shut off
- storage-1 shut off
- storage-2 shut off
[root@hp-gen9 ~]#O próximo passo é a introspecção dos nós nos quais o overcloud será instalado. Para fazer isso, precisamos preparar um arquivo json com uma descrição de nossos nós. Observe que, ao contrário da instalação em servidores vazios, o arquivo especifica a porta na qual o vbmc está sendo executado para cada uma das máquinas.
[root@hp-gen9 ~]# virsh domiflist --domain control-1
Interface Type Source Model MAC
-------------------------------------------------------
- network ovs-network-1 virtio 52:54:00:20:a2:2f
- network ovs-network-1 virtio 52:54:00:3f:87:9f
[root@hp-gen9 ~]# virsh domiflist --domain compute-1
Interface Type Source Model MAC
-------------------------------------------------------
- network ovs-network-1 virtio 52:54:00:98:e9:d6
[root@hp-gen9 ~]# virsh domiflist --domain compute-2
Interface Type Source Model MAC
-------------------------------------------------------
- network ovs-network-1 virtio 52:54:00:6a:ea:be
[root@hp-gen9 ~]# virsh domiflist --domain storage-1
Interface Type Source Model MAC
-------------------------------------------------------
- network ovs-network-1 virtio 52:54:00:79:0b:cb
[root@hp-gen9 ~]# virsh domiflist --domain storage-2
Interface Type Source Model MAC
-------------------------------------------------------
- network ovs-network-1 virtio 52:54:00:a7:fe:27Nota: existem duas interfaces no nó de controle, mas neste caso não importa, nesta instalação uma será suficiente para nós.Agora estamos preparando um arquivo json. Precisamos especificar o endereço poppy da porta através da qual o provisionamento será executado, os parâmetros do nó, dar-lhes nomes e indicar como chegar ao ipmi:
{
"nodes":[
{
"mac":[
"52:54:00:20:a2:2f"
],
"cpu":"8",
"memory":"32768",
"disk":"60",
"arch":"x86_64",
"name":"control-1",
"pm_type":"pxe_ipmitool",
"pm_user":"admin",
"pm_password":"admin",
"pm_addr":"192.168.255.200",
"pm_port":"7001"
},
{
"mac":[
"52:54:00:79:0b:cb"
],
"cpu":"4",
"memory":"16384",
"disk":"160",
"arch":"x86_64",
"name":"storage-1",
"pm_type":"pxe_ipmitool",
"pm_user":"admin",
"pm_password":"admin",
"pm_addr":"192.168.255.200",
"pm_port":"7002"
},
{
"mac":[
"52:54:00:a7:fe:27"
],
"cpu":"4",
"memory":"16384",
"disk":"160",
"arch":"x86_64",
"name":"storage-2",
"pm_type":"pxe_ipmitool",
"pm_user":"admin",
"pm_password":"admin",
"pm_addr":"192.168.255.200",
"pm_port":"7003"
},
{
"mac":[
"52:54:00:98:e9:d6"
],
"cpu":"12",
"memory":"32768",
"disk":"60",
"arch":"x86_64",
"name":"compute-1",
"pm_type":"pxe_ipmitool",
"pm_user":"admin",
"pm_password":"admin",
"pm_addr":"192.168.255.200",
"pm_port":"7004"
},
{
"mac":[
"52:54:00:6a:ea:be"
],
"cpu":"12",
"memory":"32768",
"disk":"60",
"arch":"x86_64",
"name":"compute-2",
"pm_type":"pxe_ipmitool",
"pm_user":"admin",
"pm_password":"admin",
"pm_addr":"192.168.255.200",
"pm_port":"7005"
}
]
}Agora precisamos preparar imagens irônicas. Para fazer isso, baixe-os via wget e instale:
(undercloud) [stack@undercloud ~]$ sudo wget https://images.rdoproject.org/queens/delorean/current-tripleo-rdo/overcloud-full.tar --no-check-certificate
(undercloud) [stack@undercloud ~]$ sudo wget https://images.rdoproject.org/queens/delorean/current-tripleo-rdo/ironic-python-agent.tar --no-check-certificate
(undercloud) [stack@undercloud ~]$ ls -lh
total 1.9G
-rw-r--r--. 1 stack stack 447M Aug 14 10:26 ironic-python-agent.tar
-rw-r--r--. 1 stack stack 1.5G Aug 14 10:26 overcloud-full.tar
-rw-------. 1 stack stack 916 Aug 13 23:10 stackrc
-rw-r--r--. 1 stack stack 15K Aug 13 22:50 undercloud.conf
-rw-------. 1 stack stack 2.0K Aug 13 22:50 undercloud-passwords.conf
(undercloud) [stack@undercloud ~]$ mkdir images/
(undercloud) [stack@undercloud ~]$ tar -xpvf ironic-python-agent.tar -C ~/images/
ironic-python-agent.initramfs
ironic-python-agent.kernel
(undercloud) [stack@undercloud ~]$ tar -xpvf overcloud-full.tar -C ~/images/
overcloud-full.qcow2
overcloud-full.initrd
overcloud-full.vmlinuz
(undercloud) [stack@undercloud ~]$
(undercloud) [stack@undercloud ~]$ ls -lh images/
total 1.9G
-rw-rw-r--. 1 stack stack 441M Aug 12 17:24 ironic-python-agent.initramfs
-rwxr-xr-x. 1 stack stack 6.5M Aug 12 17:24 ironic-python-agent.kernel
-rw-r--r--. 1 stack stack 53M Aug 12 17:14 overcloud-full.initrd
-rw-r--r--. 1 stack stack 1.4G Aug 12 17:18 overcloud-full.qcow2
-rwxr-xr-x. 1 stack stack 6.5M Aug 12 17:14 overcloud-full.vmlinuz
(undercloud) [stack@undercloud ~]$Enviando imagens para a nuvem:
(undercloud) [stack@undercloud ~]$ openstack overcloud image upload --image-path ~/images/
Image "overcloud-full-vmlinuz" was uploaded.
+--------------------------------------+------------------------+-------------+---------+--------+
| ID | Name | Disk Format | Size | Status |
+--------------------------------------+------------------------+-------------+---------+--------+
| c2553770-3e0f-4750-b46b-138855b5c385 | overcloud-full-vmlinuz | aki | 6761064 | active |
+--------------------------------------+------------------------+-------------+---------+--------+
Image "overcloud-full-initrd" was uploaded.
+--------------------------------------+-----------------------+-------------+----------+--------+
| ID | Name | Disk Format | Size | Status |
+--------------------------------------+-----------------------+-------------+----------+--------+
| 949984e0-4932-4e71-af43-d67a38c3dc89 | overcloud-full-initrd | ari | 55183045 | active |
+--------------------------------------+-----------------------+-------------+----------+--------+
Image "overcloud-full" was uploaded.
+--------------------------------------+----------------+-------------+------------+--------+
| ID | Name | Disk Format | Size | Status |
+--------------------------------------+----------------+-------------+------------+--------+
| a2f2096d-c9d7-429a-b866-c7543c02a380 | overcloud-full | qcow2 | 1487475712 | active |
+--------------------------------------+----------------+-------------+------------+--------+
Image "bm-deploy-kernel" was uploaded.
+--------------------------------------+------------------+-------------+---------+--------+
| ID | Name | Disk Format | Size | Status |
+--------------------------------------+------------------+-------------+---------+--------+
| e413aa78-e38f-404c-bbaf-93e582a8e67f | bm-deploy-kernel | aki | 6761064 | active |
+--------------------------------------+------------------+-------------+---------+--------+
Image "bm-deploy-ramdisk" was uploaded.
+--------------------------------------+-------------------+-------------+-----------+--------+
| ID | Name | Disk Format | Size | Status |
+--------------------------------------+-------------------+-------------+-----------+--------+
| 5cf3aba4-0e50-45d3-929f-27f025dd6ce3 | bm-deploy-ramdisk | ari | 461759376 | active |
+--------------------------------------+-------------------+-------------+-----------+--------+
(undercloud) [stack@undercloud ~]$Verifique se todas as imagens estão carregadas
(undercloud) [stack@undercloud ~]$ openstack image list
+--------------------------------------+------------------------+--------+
| ID | Name | Status |
+--------------------------------------+------------------------+--------+
| e413aa78-e38f-404c-bbaf-93e582a8e67f | bm-deploy-kernel | active |
| 5cf3aba4-0e50-45d3-929f-27f025dd6ce3 | bm-deploy-ramdisk | active |
| a2f2096d-c9d7-429a-b866-c7543c02a380 | overcloud-full | active |
| 949984e0-4932-4e71-af43-d67a38c3dc89 | overcloud-full-initrd | active |
| c2553770-3e0f-4750-b46b-138855b5c385 | overcloud-full-vmlinuz | active |
+--------------------------------------+------------------------+--------+
(undercloud) [stack@undercloud ~]$Mais um toque - você precisa adicionar um servidor dns:
(undercloud) [stack@undercloud ~]$ openstack subnet list
+--------------------------------------+-----------------+--------------------------------------+------------------+
| ID | Name | Network | Subnet |
+--------------------------------------+-----------------+--------------------------------------+------------------+
| f45dea46-4066-42aa-a3c4-6f84b8120cab | ctlplane-subnet | 6ca013dc-41c2-42d8-9d69-542afad53392 | 192.168.255.0/24 |
+--------------------------------------+-----------------+--------------------------------------+------------------+
(undercloud) [stack@undercloud ~]$ openstack subnet show f45dea46-4066-42aa-a3c4-6f84b8120cab
+-------------------+-----------------------------------------------------------+
| Field | Value |
+-------------------+-----------------------------------------------------------+
| allocation_pools | 192.168.255.11-192.168.255.50 |
| cidr | 192.168.255.0/24 |
| created_at | 2020-08-13T20:10:37Z |
| description | |
| dns_nameservers | |
| enable_dhcp | True |
| gateway_ip | 192.168.255.1 |
| host_routes | destination='169.254.169.254/32', gateway='192.168.255.1' |
| id | f45dea46-4066-42aa-a3c4-6f84b8120cab |
| ip_version | 4 |
| ipv6_address_mode | None |
| ipv6_ra_mode | None |
| name | ctlplane-subnet |
| network_id | 6ca013dc-41c2-42d8-9d69-542afad53392 |
| prefix_length | None |
| project_id | a844ccfcdb2745b198dde3e1b28c40a3 |
| revision_number | 0 |
| segment_id | None |
| service_types | |
| subnetpool_id | None |
| tags | |
| updated_at | 2020-08-13T20:10:37Z |
+-------------------+-----------------------------------------------------------+
(undercloud) [stack@undercloud ~]$
(undercloud) [stack@undercloud ~]$ neutron subnet-update f45dea46-4066-42aa-a3c4-6f84b8120cab --dns-nameserver 192.168.255.253
neutron CLI is deprecated and will be removed in the future. Use openstack CLI instead.
Updated subnet: f45dea46-4066-42aa-a3c4-6f84b8120cab
(undercloud) [stack@undercloud ~]$Agora podemos emitir o comando para introspecção:
(undercloud) [stack@undercloud ~]$ openstack overcloud node import --introspect --provide inspection.json
Started Mistral Workflow tripleo.baremetal.v1.register_or_update. Execution ID: d57456a3-d8ed-479c-9a90-dff7c752d0ec
Waiting for messages on queue 'tripleo' with no timeout.
5 node(s) successfully moved to the "manageable" state.
Successfully registered node UUID b4b2cf4a-b7ca-4095-af13-cc83be21c4f5
Successfully registered node UUID b89a72a3-6bb7-429a-93bc-48393d225838
Successfully registered node UUID 20a16cc0-e0ce-4d88-8f17-eb0ce7b4d69e
Successfully registered node UUID bfc1eb98-a17a-4a70-b0b6-6c0db0eac8e8
Successfully registered node UUID 766ab623-464c-423d-a529-d9afb69d1167
Waiting for introspection to finish...
Started Mistral Workflow tripleo.baremetal.v1.introspect. Execution ID: 6b4d08ae-94c3-4a10-ab63-7634ec198a79
Waiting for messages on queue 'tripleo' with no timeout.
Introspection of node b89a72a3-6bb7-429a-93bc-48393d225838 completed. Status:SUCCESS. Errors:None
Introspection of node 20a16cc0-e0ce-4d88-8f17-eb0ce7b4d69e completed. Status:SUCCESS. Errors:None
Introspection of node bfc1eb98-a17a-4a70-b0b6-6c0db0eac8e8 completed. Status:SUCCESS. Errors:None
Introspection of node 766ab623-464c-423d-a529-d9afb69d1167 completed. Status:SUCCESS. Errors:None
Introspection of node b4b2cf4a-b7ca-4095-af13-cc83be21c4f5 completed. Status:SUCCESS. Errors:None
Successfully introspected 5 node(s).
Started Mistral Workflow tripleo.baremetal.v1.provide. Execution ID: f5594736-edcf-4927-a8a0-2a7bf806a59a
Waiting for messages on queue 'tripleo' with no timeout.
5 node(s) successfully moved to the "available" state.
(undercloud) [stack@undercloud ~]$Como você pode ver na saída, tudo terminou sem erros. Vamos verificar se todos os nós estão disponíveis:
(undercloud) [stack@undercloud ~]$ openstack baremetal node list
+--------------------------------------+-----------+---------------+-------------+--------------------+-------------+
| UUID | Name | Instance UUID | Power State | Provisioning State | Maintenance |
+--------------------------------------+-----------+---------------+-------------+--------------------+-------------+
| b4b2cf4a-b7ca-4095-af13-cc83be21c4f5 | control-1 | None | power off | available | False |
| b89a72a3-6bb7-429a-93bc-48393d225838 | storage-1 | None | power off | available | False |
| 20a16cc0-e0ce-4d88-8f17-eb0ce7b4d69e | storage-2 | None | power off | available | False |
| bfc1eb98-a17a-4a70-b0b6-6c0db0eac8e8 | compute-1 | None | power off | available | False |
| 766ab623-464c-423d-a529-d9afb69d1167 | compute-2 | None | power off | available | False |
+--------------------------------------+-----------+---------------+-------------+--------------------+-------------+
(undercloud) [stack@undercloud ~]$ Se os nós estiverem em um estado diferente, geralmente gerenciável, algo deu errado e você precisa olhar o log para descobrir por que aconteceu. Lembre-se de que, neste cenário, estamos usando virtualização e pode haver bugs associados ao uso de máquinas virtuais ou vbmc.
Em seguida, precisamos especificar qual nó executará qual função - ou seja, indicar o perfil com o qual o nó será implantado:
(undercloud) [stack@undercloud ~]$ openstack overcloud profiles list
+--------------------------------------+-----------+-----------------+-----------------+-------------------+
| Node UUID | Node Name | Provision State | Current Profile | Possible Profiles |
+--------------------------------------+-----------+-----------------+-----------------+-------------------+
| b4b2cf4a-b7ca-4095-af13-cc83be21c4f5 | control-1 | available | None | |
| b89a72a3-6bb7-429a-93bc-48393d225838 | storage-1 | available | None | |
| 20a16cc0-e0ce-4d88-8f17-eb0ce7b4d69e | storage-2 | available | None | |
| bfc1eb98-a17a-4a70-b0b6-6c0db0eac8e8 | compute-1 | available | None | |
| 766ab623-464c-423d-a529-d9afb69d1167 | compute-2 | available | None | |
+--------------------------------------+-----------+-----------------+-----------------+-------------------+
(undercloud) [stack@undercloud ~]$ openstack flavor list
+--------------------------------------+---------------+------+------+-----------+-------+-----------+
| ID | Name | RAM | Disk | Ephemeral | VCPUs | Is Public |
+--------------------------------------+---------------+------+------+-----------+-------+-----------+
| 168af640-7f40-42c7-91b2-989abc5c5d8f | swift-storage | 4096 | 40 | 0 | 1 | True |
| 52148d1b-492e-48b4-b5fc-772849dd1b78 | baremetal | 4096 | 40 | 0 | 1 | True |
| 56e66542-ae60-416d-863e-0cb192d01b09 | control | 4096 | 40 | 0 | 1 | True |
| af6796e1-d0c4-4bfe-898c-532be194f7ac | block-storage | 4096 | 40 | 0 | 1 | True |
| e4d50fdd-0034-446b-b72c-9da19b16c2df | compute | 4096 | 40 | 0 | 1 | True |
| fc2e3acf-7fca-4901-9eee-4a4d6ef0265d | ceph-storage | 4096 | 40 | 0 | 1 | True |
+--------------------------------------+---------------+------+------+-----------+-------+-----------+
(undercloud) [stack@undercloud ~]$Indicamos o perfil de cada nó:
openstack baremetal node set --property capabilities='profile:control,boot_option:local' b4b2cf4a-b7ca-4095-af13-cc83be21c4f5
openstack baremetal node set --property capabilities='profile:ceph-storage,boot_option:local' b89a72a3-6bb7-429a-93bc-48393d225838
openstack baremetal node set --property capabilities='profile:ceph-storage,boot_option:local' 20a16cc0-e0ce-4d88-8f17-eb0ce7b4d69e
openstack baremetal node set --property capabilities='profile:compute,boot_option:local' bfc1eb98-a17a-4a70-b0b6-6c0db0eac8e8
openstack baremetal node set --property capabilities='profile:compute,boot_option:local' 766ab623-464c-423d-a529-d9afb69d1167Verificamos se fizemos tudo corretamente:
(undercloud) [stack@undercloud ~]$ openstack overcloud profiles list
+--------------------------------------+-----------+-----------------+-----------------+-------------------+
| Node UUID | Node Name | Provision State | Current Profile | Possible Profiles |
+--------------------------------------+-----------+-----------------+-----------------+-------------------+
| b4b2cf4a-b7ca-4095-af13-cc83be21c4f5 | control-1 | available | control | |
| b89a72a3-6bb7-429a-93bc-48393d225838 | storage-1 | available | ceph-storage | |
| 20a16cc0-e0ce-4d88-8f17-eb0ce7b4d69e | storage-2 | available | ceph-storage | |
| bfc1eb98-a17a-4a70-b0b6-6c0db0eac8e8 | compute-1 | available | compute | |
| 766ab623-464c-423d-a529-d9afb69d1167 | compute-2 | available | compute | |
+--------------------------------------+-----------+-----------------+-----------------+-------------------+
(undercloud) [stack@undercloud ~]$Se tudo estiver correto, damos o comando para implantar o overcloud:
openstack overcloud deploy --templates --control-scale 1 --compute-scale 2 --ceph-storage-scale 2 --control-flavor control --compute-flavor compute --ceph-storage-flavor ceph-storage --libvirt-type qemuEm uma instalação real, os templates customizados serão naturalmente usados, no nosso caso isso vai complicar muito o processo, pois será necessário explicar cada edição no template. Como foi escrito anteriormente, mesmo uma simples instalação será suficiente para vermos como funciona.
Nota: a variável --libvirt-type qemu é necessária neste caso, uma vez que usaremos virtualização aninhada. Caso contrário, você não terá máquinas virtuais em execução.
Agora você tem cerca de uma hora, ou talvez mais (dependendo das capacidades do hardware) e você só pode esperar que depois desse tempo veja a seguinte inscrição:
2020-08-14 08:39:21Z [overcloud]: CREATE_COMPLETE Stack CREATE completed successfully
Stack overcloud CREATE_COMPLETE
Host 192.168.255.21 not found in /home/stack/.ssh/known_hosts
Started Mistral Workflow tripleo.deployment.v1.get_horizon_url. Execution ID: fcb996cd-6a19-482b-b755-2ca0c08069a9
Overcloud Endpoint: http://192.168.255.21:5000/
Overcloud Horizon Dashboard URL: http://192.168.255.21:80/dashboard
Overcloud rc file: /home/stack/overcloudrc
Overcloud Deployed
(undercloud) [stack@undercloud ~]$Agora você tem uma versão quase completa da pilha aberta, na qual pode estudar, fazer experimentos etc.
Vamos verificar se tudo funciona bem. Na pilha do diretório inicial do usuário, há dois arquivos - um stackrc (para gerenciar undercloud) e o outro overcloudrc (para gerenciar overcloud). Esses arquivos devem ser especificados como fonte, pois contêm as informações necessárias para autenticação.
(undercloud) [stack@undercloud ~]$ openstack server list
+--------------------------------------+-------------------------+--------+-------------------------+----------------+--------------+
| ID | Name | Status | Networks | Image | Flavor |
+--------------------------------------+-------------------------+--------+-------------------------+----------------+--------------+
| fd7d36f4-ce87-4b9a-93b0-add2957792de | overcloud-controller-0 | ACTIVE | ctlplane=192.168.255.15 | overcloud-full | control |
| edc77778-8972-475e-a541-ff40eb944197 | overcloud-novacompute-1 | ACTIVE | ctlplane=192.168.255.26 | overcloud-full | compute |
| 5448ce01-f05f-47ca-950a-ced14892c0d4 | overcloud-cephstorage-1 | ACTIVE | ctlplane=192.168.255.34 | overcloud-full | ceph-storage |
| ce6d862f-4bdf-4ba3-b711-7217915364d7 | overcloud-novacompute-0 | ACTIVE | ctlplane=192.168.255.19 | overcloud-full | compute |
| e4507bd5-6f96-4b12-9cc0-6924709da59e | overcloud-cephstorage-0 | ACTIVE | ctlplane=192.168.255.44 | overcloud-full | ceph-storage |
+--------------------------------------+-------------------------+--------+-------------------------+----------------+--------------+
(undercloud) [stack@undercloud ~]$
(undercloud) [stack@undercloud ~]$ source overcloudrc
(overcloud) [stack@undercloud ~]$
(overcloud) [stack@undercloud ~]$ openstack project list
+----------------------------------+---------+
| ID | Name |
+----------------------------------+---------+
| 4eed7d0f06544625857d51cd77c5bd4c | admin |
| ee1c68758bde41eaa9912c81dc67dad8 | service |
+----------------------------------+---------+
(overcloud) [stack@undercloud ~]$
(overcloud) [stack@undercloud ~]$
(overcloud) [stack@undercloud ~]$ openstack network agent list
+--------------------------------------+--------------------+-------------------------------------+-------------------+-------+-------+---------------------------+
| ID | Agent Type | Host | Availability Zone | Alive | State | Binary |
+--------------------------------------+--------------------+-------------------------------------+-------------------+-------+-------+---------------------------+
| 10495de9-ba4b-41fe-b30a-b90ec3f8728b | Open vSwitch agent | overcloud-novacompute-1.localdomain | None | :-) | UP | neutron-openvswitch-agent |
| 1515ad4a-5972-46c3-af5f-e5446dff7ac7 | L3 agent | overcloud-controller-0.localdomain | nova | :-) | UP | neutron-l3-agent |
| 322e62ca-1e5a-479e-9a96-4f26d09abdd7 | DHCP agent | overcloud-controller-0.localdomain | nova | :-) | UP | neutron-dhcp-agent |
| 9c1de2f9-bac5-400e-998d-4360f04fc533 | Open vSwitch agent | overcloud-novacompute-0.localdomain | None | :-) | UP | neutron-openvswitch-agent |
| d99c5657-851e-4d3c-bef6-f1e3bb1acfb0 | Open vSwitch agent | overcloud-controller-0.localdomain | None | :-) | UP | neutron-openvswitch-agent |
| ff85fae6-5543-45fb-a301-19c57b62d836 | Metadata agent | overcloud-controller-0.localdomain | None | :-) | UP | neutron-metadata-agent |
+--------------------------------------+--------------------+-------------------------------------+-------------------+-------+-------+---------------------------+
(overcloud) [stack@undercloud ~]$Na minha instalação, mais um pequeno toque é necessário - adicionar uma rota no controlador, já que a máquina com a qual estou trabalhando está em uma rede diferente. Para fazer isso, vá para control-1 na conta heat-admin e escreva a rota
(undercloud) [stack@undercloud ~]$ ssh heat-admin@192.168.255.15
Last login: Fri Aug 14 09:47:40 2020 from 192.168.255.1
[heat-admin@overcloud-controller-0 ~]$
[heat-admin@overcloud-controller-0 ~]$
[heat-admin@overcloud-controller-0 ~]$ sudo ip route add 10.169.0.0/16 via 192.168.255.254Bem, agora você pode ir para o horizonte. Todas as informações - endereços, login e senha - estão no arquivo / home / stack / overcloudrc. O esquema final fica assim:

Aliás, em nossa instalação os endereços das máquinas foram emitidos via DHCP e, como você pode ver, eles são emitidos “ao acaso”. Você pode codificar no modelo qual endereço deve ser anexado a qual máquina durante a implantação, se necessário.
Como o tráfego flui entre as máquinas virtuais?
Neste artigo, consideraremos três opções para a passagem de tráfego
- Duas máquinas em um hipervisor em uma rede L2
- Duas máquinas em hipervisores diferentes em uma rede L2
- Duas máquinas em redes diferentes (enraizando entre redes)
Casos com acesso ao mundo externo através de uma rede externa, utilizando endereços flutuantes, bem como roteamento distribuído, serão considerados na próxima vez, por enquanto vamos focar no tráfego interno.
Para testar, vamos montar o seguinte esquema:
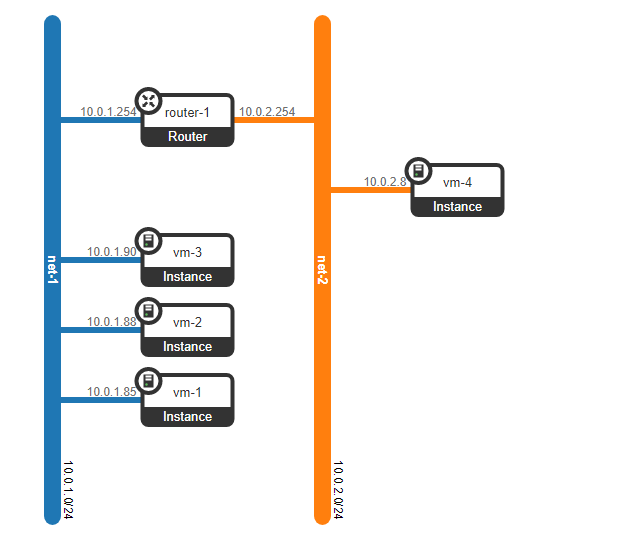
Criamos 4 máquinas virtuais - 3 em uma rede L2 - net-1 e outra 1 na rede net-2
(overcloud) [stack@undercloud ~]$ nova list --tenant 5e18ce8ec9594e00b155485f19895e6c
+--------------------------------------+------+----------------------------------+--------+------------+-------------+-----------------+
| ID | Name | Tenant ID | Status | Task State | Power State | Networks |
+--------------------------------------+------+----------------------------------+--------+------------+-------------+-----------------+
| f53b37b5-2204-46cc-aef0-dba84bf970c0 | vm-1 | 5e18ce8ec9594e00b155485f19895e6c | ACTIVE | - | Running | net-1=10.0.1.85 |
| fc8b6722-0231-49b0-b2fa-041115bef34a | vm-2 | 5e18ce8ec9594e00b155485f19895e6c | ACTIVE | - | Running | net-1=10.0.1.88 |
| 3cd74455-b9b7-467a-abe3-bd6ff765c83c | vm-3 | 5e18ce8ec9594e00b155485f19895e6c | ACTIVE | - | Running | net-1=10.0.1.90 |
| 7e836338-6772-46b0-9950-f7f06dbe91a8 | vm-4 | 5e18ce8ec9594e00b155485f19895e6c | ACTIVE | - | Running | net-2=10.0.2.8 |
+--------------------------------------+------+----------------------------------+--------+------------+-------------+-----------------+
(overcloud) [stack@undercloud ~]$ Vamos ver em quais hipervisores as máquinas criadas estão localizadas:
(overcloud) [stack@undercloud ~]$ nova show f53b37b5-2204-46cc-aef0-dba84bf970c0 | egrep "hypervisor_hostname|instance_name|hostname"
| OS-EXT-SRV-ATTR:hostname | vm-1 |
| OS-EXT-SRV-ATTR:hypervisor_hostname | overcloud-novacompute-0.localdomain |
| OS-EXT-SRV-ATTR:instance_name | instance-00000001 |(overcloud) [stack@undercloud ~]$ nova show fc8b6722-0231-49b0-b2fa-041115bef34a | egrep "hypervisor_hostname|instance_name|hostname"
| OS-EXT-SRV-ATTR:hostname | vm-2 |
| OS-EXT-SRV-ATTR:hypervisor_hostname | overcloud-novacompute-1.localdomain |
| OS-EXT-SRV-ATTR:instance_name | instance-00000002 |(overcloud) [stack@undercloud ~]$ nova show 3cd74455-b9b7-467a-abe3-bd6ff765c83c | egrep "hypervisor_hostname|instance_name|hostname"
| OS-EXT-SRV-ATTR:hostname | vm-3 |
| OS-EXT-SRV-ATTR:hypervisor_hostname | overcloud-novacompute-0.localdomain |
| OS-EXT-SRV-ATTR:instance_name | instance-00000003 |(overcloud) [stack@undercloud ~]$ nova show 7e836338-6772-46b0-9950-f7f06dbe91a8 | egrep "hypervisor_hostname|instance_name|hostname"
| OS-EXT-SRV-ATTR:hostname | vm-4 |
| OS-EXT-SRV-ATTR:hypervisor_hostname | overcloud-novacompute-1.localdomain |
| OS-EXT-SRV-ATTR:instance_name | instance-00000004 |(overcloud) [stack @ undercloud ~] $ As
máquinas vm-1 e vm-3 estão localizadas em compute-0, as máquinas vm-2 e vm-4 estão localizadas no nó compute-1.
Além disso, um roteador virtual foi criado para permitir o roteamento entre as redes especificadas:
(overcloud) [stack@undercloud ~]$ openstack router list --project 5e18ce8ec9594e00b155485f19895e6c
+--------------------------------------+----------+--------+-------+-------------+-------+----------------------------------+
| ID | Name | Status | State | Distributed | HA | Project |
+--------------------------------------+----------+--------+-------+-------------+-------+----------------------------------+
| 0a4d2420-4b9c-46bd-aec1-86a1ef299abe | router-1 | ACTIVE | UP | False | False | 5e18ce8ec9594e00b155485f19895e6c |
+--------------------------------------+----------+--------+-------+-------------+-------+----------------------------------+
(overcloud) [stack@undercloud ~]$ O roteador tem duas portas virtuais que atuam como gateways para redes:
(overcloud) [stack@undercloud ~]$ openstack router show 0a4d2420-4b9c-46bd-aec1-86a1ef299abe | grep interface
| interfaces_info | [{"subnet_id": "2529ad1a-6b97-49cd-8515-cbdcbe5e3daa", "ip_address": "10.0.1.254", "port_id": "0c52b15f-8fcc-4801-bf52-7dacc72a5201"}, {"subnet_id": "335552dd-b35b-456b-9df0-5aac36a3ca13", "ip_address": "10.0.2.254", "port_id": "92fa49b5-5406-499f-ab8d-ddf28cc1a76c"}] |
(overcloud) [stack@undercloud ~]$ Mas antes de ver como o tráfego vai, vamos dar uma olhada no que temos no momento no nó de controle (que também é um nó de rede) e no nó de computação. Vamos começar com um nó de computação.
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-vsctl show
[heat-admin@overcloud-novacompute-0 ~]$ sudo sudo ovs-appctl dpif/show
system@ovs-system: hit:3 missed:3
br-ex:
br-ex 65534/1: (internal)
phy-br-ex 1/none: (patch: peer=int-br-ex)
br-int:
br-int 65534/2: (internal)
int-br-ex 1/none: (patch: peer=phy-br-ex)
patch-tun 2/none: (patch: peer=patch-int)
br-tun:
br-tun 65534/3: (internal)
patch-int 1/none: (patch: peer=patch-tun)
vxlan-c0a8ff0f 3/4: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.19, remote_ip=192.168.255.15)
vxlan-c0a8ff1a 2/4: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.19, remote_ip=192.168.255.26)
[heat-admin@overcloud-novacompute-0 ~]$No momento, o nó tem três pontes ovs - br-int, br-tun, br-ex. Entre eles, como podemos ver, existe um conjunto de interfaces. Para facilitar a percepção, colocaremos todas essas interfaces no diagrama e veremos o que acontece.

A partir dos endereços para os quais os túneis VxLAN são gerados, você pode ver que um túnel é gerado em compute-1 (192.168.255.26), o segundo túnel examina control-1 (192.168.255.15). Mas o mais interessante é que o br-ex não tem interfaces físicas, e se você olhar quais fluxos estão configurados, você pode ver que essa ponte no momento só pode descartar tráfego.
[heat-admin@overcloud-novacompute-0 ~]$ ifconfig eth0
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 192.168.255.19 netmask 255.255.255.0 broadcast 192.168.255.255
inet6 fe80::5054:ff:fe6a:eabe prefixlen 64 scopeid 0x20<link>
ether 52:54:00:6a:ea:be txqueuelen 1000 (Ethernet)
RX packets 2909669 bytes 4608201000 (4.2 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 1821057 bytes 349198520 (333.0 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
[heat-admin@overcloud-novacompute-0 ~]$ Como você pode ver na saída, o endereço é aparafusado diretamente à porta física, e não à interface de ponte virtual.
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-appctl fdb/show br-ex
port VLAN MAC Age
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-ofctl dump-flows br-ex
cookie=0x9169eae8f7fe5bb2, duration=216686.864s, table=0, n_packets=303, n_bytes=26035, priority=2,in_port="phy-br-ex" actions=drop
cookie=0x9169eae8f7fe5bb2, duration=216686.887s, table=0, n_packets=0, n_bytes=0, priority=0 actions=NORMAL
[heat-admin@overcloud-novacompute-0 ~]$ De acordo com a primeira regra, tudo o que vem da porta phy-br-ex deve ser descartado.
Na verdade, não há nenhum outro lugar para o tráfego chegar a esta ponte, exceto a partir desta interface (junção com br-int), e a julgar pelas quedas, o tráfego BUM já chegou na ponte.
Ou seja, o tráfego desse nó só pode passar pelo túnel VxLAN e nada mais. No entanto, se você ligar o DVR, a situação mudará, mas trataremos disso em outra ocasião. Ao usar o isolamento de rede, por exemplo, usando vlans, você não terá uma interface L3 na 0ª vlan, mas várias interfaces. No entanto, o tráfego de VxLAN sairá do nó da mesma maneira, mas também encapsulado em algum tipo de vlan dedicado.
Nós descobrimos o nó de computação, vá para o nó de controle.
[heat-admin@overcloud-controller-0 ~]$ sudo ovs-appctl dpif/show
system@ovs-system: hit:930491 missed:825
br-ex:
br-ex 65534/1: (internal)
eth0 1/2: (system)
phy-br-ex 2/none: (patch: peer=int-br-ex)
br-int:
br-int 65534/3: (internal)
int-br-ex 1/none: (patch: peer=phy-br-ex)
patch-tun 2/none: (patch: peer=patch-int)
br-tun:
br-tun 65534/4: (internal)
patch-int 1/none: (patch: peer=patch-tun)
vxlan-c0a8ff13 3/5: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.15, remote_ip=192.168.255.19)
vxlan-c0a8ff1a 2/5: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.15, remote_ip=192.168.255.26)
[heat-admin@overcloud-controller-0 ~]$Na verdade, podemos dizer que está tudo igual, mas o endereço ip não está mais na interface física, e sim na bridge virtual. Isso é feito devido ao fato de que esta porta é uma porta através da qual o tráfego irá para o mundo exterior.
[heat-admin@overcloud-controller-0 ~]$ ifconfig br-ex
br-ex: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 192.168.255.15 netmask 255.255.255.0 broadcast 192.168.255.255
inet6 fe80::5054:ff:fe20:a22f prefixlen 64 scopeid 0x20<link>
ether 52:54:00:20:a2:2f txqueuelen 1000 (Ethernet)
RX packets 803859 bytes 1732616116 (1.6 GiB)
RX errors 0 dropped 63 overruns 0 frame 0
TX packets 808475 bytes 121652156 (116.0 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
[heat-admin@overcloud-controller-0 ~]$
[heat-admin@overcloud-controller-0 ~]$ sudo ovs-appctl fdb/show br-ex
port VLAN MAC Age
3 100 28:c0:da:00:4d:d3 35
1 0 28:c0:da:00:4d:d3 35
1 0 52:54:00:98:e9:d6 0
LOCAL 0 52:54:00:20:a2:2f 0
1 0 52:54:00:2c:08:9e 0
3 100 52:54:00:20:a2:2f 0
1 0 52:54:00:6a:ea:be 0
[heat-admin@overcloud-controller-0 ~]$ Esta porta está ligada à ponte br-ex e como não há tags vlan nela, esta porta é uma porta de tronco na qual todas as vlans são permitidas, agora o tráfego sai sem uma tag, conforme indicado por vlan-id 0 na saída acima.
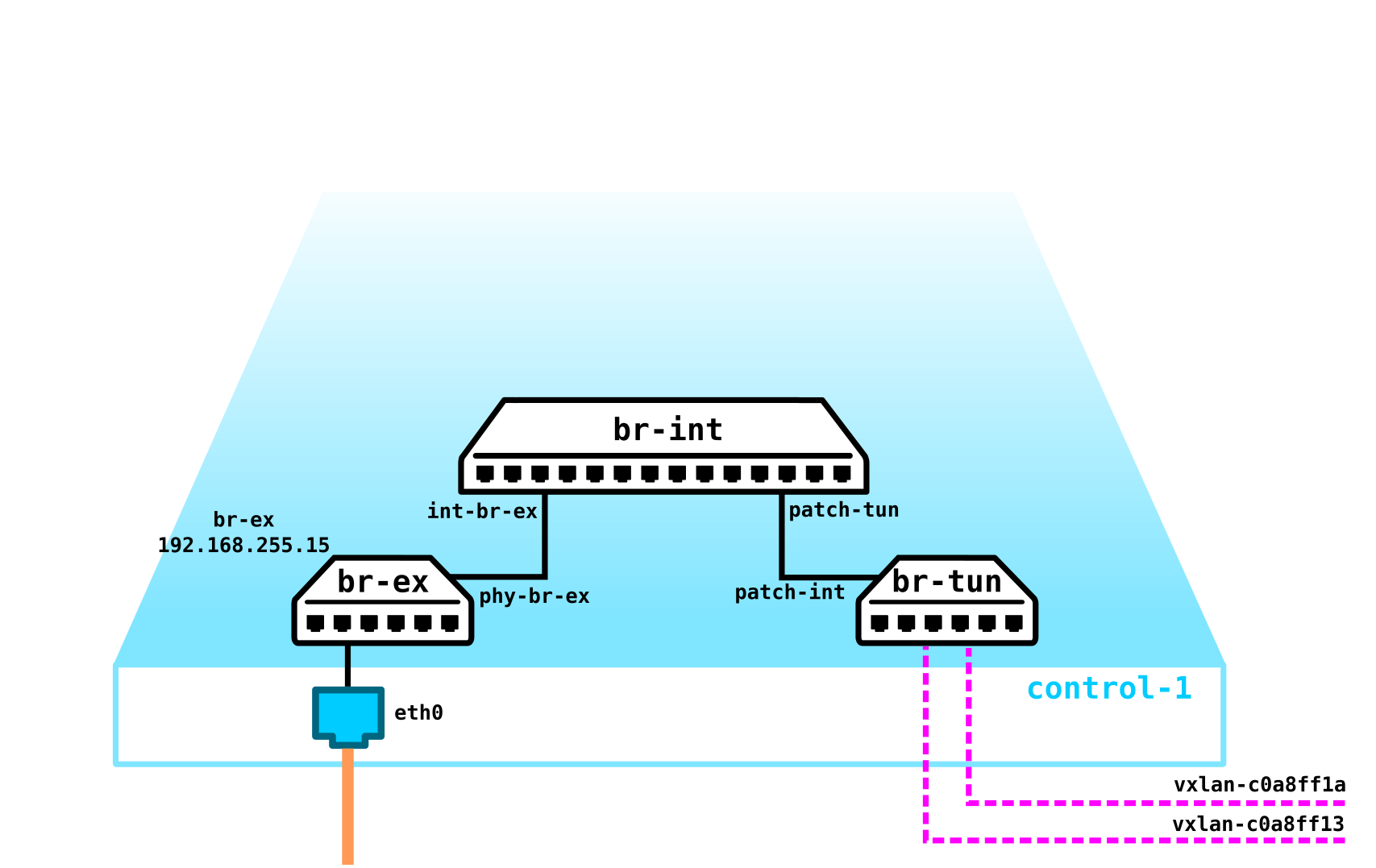
Todo o resto no momento é semelhante ao nó de computação - as mesmas pontes, os mesmos túneis indo para dois nós de computação.
Não consideraremos os nós de armazenamento neste artigo, mas para compreensão deve-se dizer que a parte de rede desses nós é banal ao ponto da desgraça. No nosso caso, há apenas uma porta física (eth0) com um endereço IP pendurado nela e é isso. Não há túneis VxLAN, pontes de túnel, etc. - não há ovs, pois não há nenhum ponto nele. Ao usar o isolamento de rede - este nó terá duas interfaces (portas físicas, baud ou apenas duas vlans - não importa - depende do que você deseja) - uma para gerenciamento, a segunda para tráfego (gravação no disco VM, leitura de disco, etc.).
Descobrimos o que temos nos nós na ausência de quaisquer serviços. Agora vamos começar 4 máquinas virtuais e ver como o esquema descrito acima muda - devemos ter portas, roteadores virtuais, etc.
Até agora, nossa rede se parece com isto:
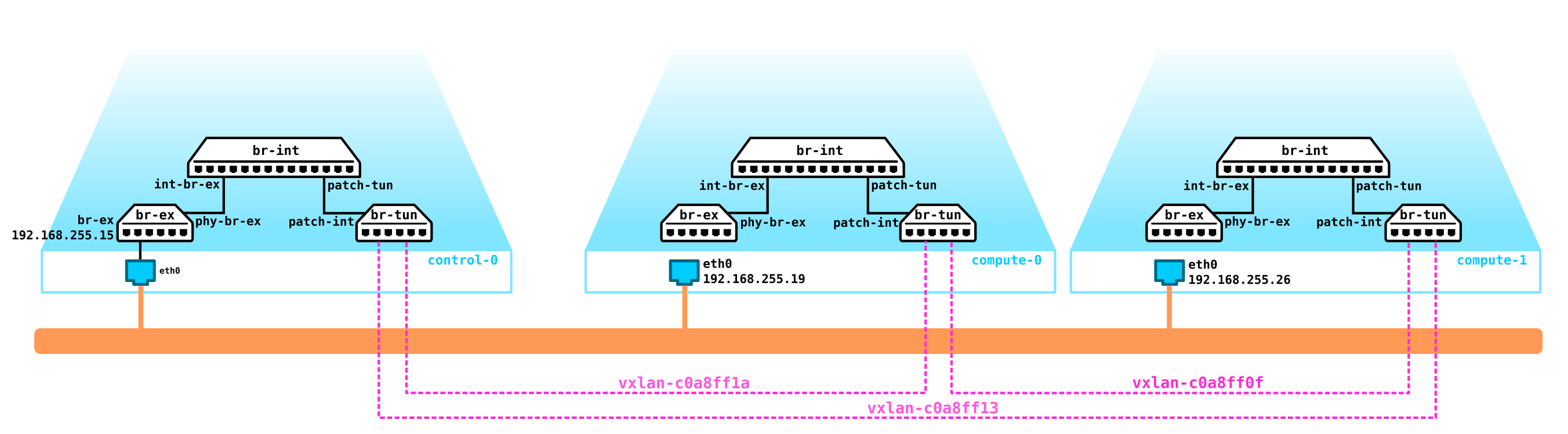
Temos duas máquinas virtuais em cada computador. Vamos ver como tudo está incluído no compute-0.
[heat-admin@overcloud-novacompute-0 ~]$ sudo virsh list
Id Name State
----------------------------------------------------
1 instance-00000001 running
3 instance-00000003 running
[heat-admin@overcloud-novacompute-0 ~]$ A máquina tem apenas uma interface virtual - tap95d96a75-a0:
[heat-admin@overcloud-novacompute-0 ~]$ sudo virsh domiflist instance-00000001
Interface Type Source Model MAC
-------------------------------------------------------
tap95d96a75-a0 bridge qbr95d96a75-a0 virtio fa:16:3e:44:98:20
[heat-admin@overcloud-novacompute-0 ~]$
Esta interface olha para a ponte linux:
[heat-admin@overcloud-novacompute-0 ~]$ sudo brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.0242904c92a8 no
qbr5bd37136-47 8000.5e4e05841423 no qvb5bd37136-47
tap5bd37136-47
qbr95d96a75-a0 8000.de076cb850f6 no qvb95d96a75-a0
tap95d96a75-a0
[heat-admin@overcloud-novacompute-0 ~]$ Como você pode ver na saída, existem apenas duas interfaces na brigada - tap95d96a75-a0 e qvb95d96a75-a0.
Vale a pena nosComo você entende, se temos uma porta qvb95d96a75-a0 na brigada, que é um par vEth, então onde está sua contraparte, que logicamente deve ser chamada de qvo95d96a75-a0. Vamos ver quais portas estão no OVS.
determos um pouco nos tipos de dispositivos de rede virtual no OpenStack: vtap - uma interface virtual conectada a uma instância (VM)
qbr - Linux bridge
qvb e qvo - vEth par conectado a uma ponte Linux e Open vSwitch bridge
br-int, br-tun, br-vlan - Abra as pontes
vSwitch patch-, int-br-, phy-br- - Abra as interfaces de patch vSwitch conectando pontes
qg, qr, ha, fg, sg - Abra as portas vSwitch usadas por dispositivos virtuais para se conectar ao OVS
[heat-admin@overcloud-novacompute-0 ~]$ sudo sudo ovs-appctl dpif/show
system@ovs-system: hit:526 missed:91
br-ex:
br-ex 65534/1: (internal)
phy-br-ex 1/none: (patch: peer=int-br-ex)
br-int:
br-int 65534/2: (internal)
int-br-ex 1/none: (patch: peer=phy-br-ex)
patch-tun 2/none: (patch: peer=patch-int)
qvo5bd37136-47 6/6: (system)
qvo95d96a75-a0 3/5: (system)
br-tun:
br-tun 65534/3: (internal)
patch-int 1/none: (patch: peer=patch-tun)
vxlan-c0a8ff0f 3/4: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.19, remote_ip=192.168.255.15)
vxlan-c0a8ff1a 2/4: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.19, remote_ip=192.168.255.26)
[heat-admin@overcloud-novacompute-0 ~]$ Como podemos ver, a porta está em br-int. Br-int atua como um switch que encerra as portas das máquinas virtuais. Além de qvo95d96a75-a0, a saída mostra a porta qvo5bd37136-47. Esta é a porta para a segunda máquina virtual. Como resultado, nosso esquema agora se parece com este: A

questão que deve interessar imediatamente a um leitor atento - por que a ponte Linux entre a porta da máquina virtual e a porta OVS? O fato é que os grupos de segurança são usados para proteger a máquina, que nada mais são do que iptables. OVS não funciona com iptables, então essa "muleta" foi inventada. No entanto, ele está sobrevivendo ao seu próprio - é substituído por conntrack em novos lançamentos.
Ou seja, em última análise, o esquema se parece com este:

Duas máquinas em um hipervisor em uma rede L2
Como essas duas VMs estão na mesma rede L2 e no mesmo hipervisor, o tráfego entre elas irá logicamente ir localmente via br-int, já que ambas as máquinas estarão na mesma VLAN:
[heat-admin@overcloud-novacompute-0 ~]$ sudo virsh domiflist instance-00000001
Interface Type Source Model MAC
-------------------------------------------------------
tap95d96a75-a0 bridge qbr95d96a75-a0 virtio fa:16:3e:44:98:20
[heat-admin@overcloud-novacompute-0 ~]$
[heat-admin@overcloud-novacompute-0 ~]$
[heat-admin@overcloud-novacompute-0 ~]$ sudo virsh domiflist instance-00000003
Interface Type Source Model MAC
-------------------------------------------------------
tap5bd37136-47 bridge qbr5bd37136-47 virtio fa:16:3e:83:ad:a4
[heat-admin@overcloud-novacompute-0 ~]$
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-appctl fdb/show br-int
port VLAN MAC Age
6 1 fa:16:3e:83:ad:a4 0
3 1 fa:16:3e:44:98:20 0
[heat-admin@overcloud-novacompute-0 ~]$ Duas máquinas em hipervisores diferentes na mesma rede L2
Agora vamos ver como o tráfego ocorre entre duas máquinas na mesma rede L2, mas localizadas em hipervisores diferentes. Para ser honesto, nada mudará muito, apenas o tráfego entre os hipervisores passará pelo túnel vxlan. Vamos ver um exemplo.
Os endereços das máquinas virtuais entre as quais observaremos o tráfego:
[heat-admin@overcloud-novacompute-0 ~]$ sudo virsh domiflist instance-00000001
Interface Type Source Model MAC
-------------------------------------------------------
tap95d96a75-a0 bridge qbr95d96a75-a0 virtio fa:16:3e:44:98:20
[heat-admin@overcloud-novacompute-0 ~]$
[heat-admin@overcloud-novacompute-1 ~]$ sudo virsh domiflist instance-00000002
Interface Type Source Model MAC
-------------------------------------------------------
tape7e23f1b-07 bridge qbre7e23f1b-07 virtio fa:16:3e:72:ad:53
[heat-admin@overcloud-novacompute-1 ~]$ Vemos a tabela de encaminhamento em br-int em compute-0:
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-appctl fdb/show br-int | grep fa:16:3e:72:ad:53
2 1 fa:16:3e:72:ad:53 1
[heat-admin@overcloud-novacompute-0 ~]O tráfego deve ir para a porta 2 - vamos ver o que é essa porta:
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-ofctl show br-int | grep addr
1(int-br-ex): addr:7e:7f:28:1f:bd:54
2(patch-tun): addr:0a:bd:07:69:58:d9
3(qvo95d96a75-a0): addr:ea:50:9a:3d:69:58
6(qvo5bd37136-47): addr:9a:d1:03:50:3d:96
LOCAL(br-int): addr:1a:0f:53:97:b1:49
[heat-admin@overcloud-novacompute-0 ~]$Este é patch-tun - ou seja, a interface para br-tun. Vamos ver o que acontece com o pacote em br-tun:
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-ofctl dump-flows br-tun | grep fa:16:3e:72:ad:53
cookie=0x8759a56536b67a8e, duration=1387.959s, table=20, n_packets=1460, n_bytes=138880, hard_timeout=300, idle_age=0, hard_age=0, priority=1,vlan_tci=0x0001/0x0fff,dl_dst=fa:16:3e:72:ad:53 actions=load:0->NXM_OF_VLAN_TCI[],load:0x16->NXM_NX_TUN_ID[],output:2
[heat-admin@overcloud-novacompute-0 ~]$ O pacote é empacotado em VxLAN e enviado para a porta 2. Vamos ver para onde leva a porta 2:
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-ofctl show br-tun | grep addr
1(patch-int): addr:b2:d1:f8:21:96:66
2(vxlan-c0a8ff1a): addr:be:64:1f:75:78:a7
3(vxlan-c0a8ff0f): addr:76:6f:b9:3c:3f:1c
LOCAL(br-tun): addr:a2:5b:6d:4f:94:47
[heat-admin@overcloud-novacompute-0 ~]$Este é um túnel vxlan em compute-1:
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-appctl dpif/show | egrep vxlan-c0a8ff1a
vxlan-c0a8ff1a 2/4: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.19, remote_ip=192.168.255.26)
[heat-admin@overcloud-novacompute-0 ~]$Vá para compute-1 e veja o que acontece a seguir com o pacote:
[heat-admin@overcloud-novacompute-1 ~]$ sudo ovs-appctl fdb/show br-int | egrep fa:16:3e:44:98:20
2 1 fa:16:3e:44:98:20 1
[heat-admin@overcloud-novacompute-1 ~]$ O Mac está na tabela de encaminhamento br-int no compute-1 e, como você pode ver na saída acima, é visível através da porta 2, que é a porta para br-tun:
[heat-admin@overcloud-novacompute-1 ~]$ sudo ovs-ofctl show br-int | grep addr
1(int-br-ex): addr:8a:d7:f9:ad:8c:1d
2(patch-tun): addr:46:cc:40:bd:20:da
3(qvoe7e23f1b-07): addr:12:78:2e:34:6a:c7
4(qvo3210e8ec-c0): addr:7a:5f:59:75:40:85
LOCAL(br-int): addr:e2:27:b2:ed:14:46Bem, então vemos que em br-int em compute-1 há um destino mac:
[heat-admin@overcloud-novacompute-1 ~]$ sudo ovs-appctl fdb/show br-int | egrep fa:16:3e:72:ad:53
3 1 fa:16:3e:72:ad:53 0
[heat-admin@overcloud-novacompute-1 ~]$ Ou seja, o pacote recebido voará para a porta 3, atrás da qual a máquina virtual da instância-00000003 já está localizada.
A beleza de implantar o Openstack para aprendizado em uma infraestrutura virtual é que podemos capturar facilmente o tráfego entre os hipervisores e ver o que acontece com ele. Faremos isso agora, execute tcpdump na porta vnet para compute-0:
[root@hp-gen9 bormoglotx]# tcpdump -vvv -i vnet3
tcpdump: listening on vnet3, link-type EN10MB (Ethernet), capture size 262144 bytes
*****************omitted*******************
04:39:04.583459 IP (tos 0x0, ttl 64, id 16868, offset 0, flags [DF], proto UDP (17), length 134)
192.168.255.19.39096 > 192.168.255.26.4789: [no cksum] VXLAN, flags [I] (0x08), vni 22
IP (tos 0x0, ttl 64, id 8012, offset 0, flags [DF], proto ICMP (1), length 84)
10.0.1.85 > 10.0.1.88: ICMP echo request, id 5634, seq 16, length 64
04:39:04.584449 IP (tos 0x0, ttl 64, id 35181, offset 0, flags [DF], proto UDP (17), length 134)
192.168.255.26.speedtrace-disc > 192.168.255.19.4789: [no cksum] VXLAN, flags [I] (0x08), vni 22
IP (tos 0x0, ttl 64, id 59124, offset 0, flags [none], proto ICMP (1), length 84)
10.0.1.88 > 10.0.1.85: ICMP echo reply, id 5634, seq 16, length 64
*****************omitted*******************A primeira linha mostra que o patch com o endereço 10.0.1.85 vai para o endereço 10.0.1.88 (tráfego ICMP), e é envolvido em um pacote VxLAN com vni 22 e o pacote vai do host 192.168.255.19 (compute-0) para o host 192.168.255.26 ( compute-1). Podemos verificar se o VNI corresponde ao especificado nos ovs.
Vamos voltar a esta linha ações = carregar: 0-> NXM_OF_VLAN_TCI [], carregar: 0x16-> NXM_NX_TUN_ID [], saída: 2. 0x16 é vni hexadecimal. Vamos traduzir este número no décimo sistema:
16 = 6*16^0+1*16^1 = 6+16 = 22Ou seja, vni corresponde à realidade.
A segunda linha mostra o tráfego de retorno, bom, não faz sentido explicar ali, e está tudo claro.
Duas máquinas em redes diferentes (roteamento entre redes)
O último caso de hoje é o roteamento entre redes dentro de um projeto usando um roteador virtual. Estamos considerando um caso sem DVR (consideraremos em outro artigo), portanto o roteamento ocorre no nó da rede. Em nosso caso, o nó da rede não é uma entidade separada e está localizado no nó de controle.
Primeiro, vamos ver se o roteamento funciona:
$ ping 10.0.2.8
PING 10.0.2.8 (10.0.2.8): 56 data bytes
64 bytes from 10.0.2.8: seq=0 ttl=63 time=7.727 ms
64 bytes from 10.0.2.8: seq=1 ttl=63 time=3.832 ms
^C
--- 10.0.2.8 ping statistics ---
2 packets transmitted, 2 packets received, 0% packet loss
round-trip min/avg/max = 3.832/5.779/7.727 msComo, neste caso, o pacote deve ir para o gateway e ser roteado para lá, precisamos descobrir o endereço MAC do gateway, para o qual veremos a tabela ARP na instância:
$ arp
host-10-0-1-254.openstacklocal (10.0.1.254) at fa:16:3e:c4:64:70 [ether] on eth0
host-10-0-1-1.openstacklocal (10.0.1.1) at fa:16:3e:e6:2c:5c [ether] on eth0
host-10-0-1-90.openstacklocal (10.0.1.90) at fa:16:3e:83:ad:a4 [ether] on eth0
host-10-0-1-88.openstacklocal (10.0.1.88) at fa:16:3e:72:ad:53 [ether] on eth0Agora vamos ver para onde o tráfego deve ser enviado com o destino (10.0.1.254) fa: 16: 3e: c4: 64: 70:
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-appctl fdb/show br-int | egrep fa:16:3e:c4:64:70
2 1 fa:16:3e:c4:64:70 0
[heat-admin@overcloud-novacompute-0 ~]$ Olhamos para onde conduz a porta 2:
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-ofctl show br-int | grep addr
1(int-br-ex): addr:7e:7f:28:1f:bd:54
2(patch-tun): addr:0a:bd:07:69:58:d9
3(qvo95d96a75-a0): addr:ea:50:9a:3d:69:58
6(qvo5bd37136-47): addr:9a:d1:03:50:3d:96
LOCAL(br-int): addr:1a:0f:53:97:b1:49
[heat-admin@overcloud-novacompute-0 ~]$ Tudo é lógico, o tráfego vai para o br-tun. Vamos ver em qual túnel vxlan ele será envolvido:
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-ofctl dump-flows br-tun | grep fa:16:3e:c4:64:70
cookie=0x8759a56536b67a8e, duration=3514.566s, table=20, n_packets=3368, n_bytes=317072, hard_timeout=300, idle_age=0, hard_age=0, priority=1,vlan_tci=0x0001/0x0fff,dl_dst=fa:16:3e:c4:64:70 actions=load:0->NXM_OF_VLAN_TCI[],load:0x16->NXM_NX_TUN_ID[],output:3
[heat-admin@overcloud-novacompute-0 ~]$ A terceira porta é o túnel vxlan:
[heat-admin@overcloud-controller-0 ~]$ sudo ovs-ofctl show br-tun | grep addr
1(patch-int): addr:a2:69:00:c5:fa:ba
2(vxlan-c0a8ff1a): addr:86:f0:ce:d0:e8:ea
3(vxlan-c0a8ff13): addr:72:aa:73:2c:2e:5b
LOCAL(br-tun): addr:a6:cb:cd:72:1c:45
[heat-admin@overcloud-controller-0 ~]$ Que olha para o nó de controle:
[heat-admin@overcloud-controller-0 ~]$ sudo sudo ovs-appctl dpif/show | grep vxlan-c0a8ff1a
vxlan-c0a8ff1a 2/5: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.15, remote_ip=192.168.255.26)
[heat-admin@overcloud-controller-0 ~]$ O tráfego atingiu o nó de controle, então precisamos ir até ele e ver como o roteamento ocorrerá.
Como você deve se lembrar, o nó de controle interno parecia exatamente com o nó de computação - as mesmas três pontes, apenas br-ex tinha uma porta física através da qual o nó poderia enviar tráfego para fora. A criação da instância mudou a configuração nos nós de computação - ponte linux, iptables e interfaces foram adicionadas aos nós. A criação de redes e de um roteador virtual também deixou sua marca na configuração do nó de controle.
Portanto, é óbvio que o endereço da papoila do gateway deve estar na tabela de encaminhamento br-int no nó de controle. Vamos verificar se ele está lá e onde está:
[heat-admin@overcloud-controller-0 ~]$ sudo ovs-appctl fdb/show br-int | grep fa:16:3e:c4:64:70
5 1 fa:16:3e:c4:64:70 1
[heat-admin@overcloud-controller-0 ~]$
[heat-admin@overcloud-controller-0 ~]$ sudo ovs-ofctl show br-int | grep addr
1(int-br-ex): addr:2e:58:b6:db:d5:de
2(patch-tun): addr:06:41:90:f0:9e:56
3(tapca25a97e-64): addr:fa:16:3e:e6:2c:5c
4(tap22015e46-0b): addr:fa:16:3e:76:c2:11
5(qr-0c52b15f-8f): addr:fa:16:3e:c4:64:70
6(qr-92fa49b5-54): addr:fa:16:3e:80:13:72
LOCAL(br-int): addr:06:de:5d:ed:44:44
[heat-admin@overcloud-controller-0 ~]$ Mac é visível na porta qr-0c52b15f-8f. Se voltarmos à lista de portas virtuais no Openstack, este tipo de porta é usado para conectar vários dispositivos virtuais ao OVS. Para ser mais preciso, qr é uma porta para o roteador virtual, que é representado como um namespace.
Vamos ver quais são os namespaces no servidor:
[heat-admin@overcloud-controller-0 ~]$ sudo ip netns
qrouter-0a4d2420-4b9c-46bd-aec1-86a1ef299abe (id: 2)
qdhcp-7d541e74-1c36-4e1d-a7c4-0968c8dbc638 (id: 1)
qdhcp-67a3798c-32c0-4c18-8502-2531247e3cc2 (id: 0)
[heat-admin@overcloud-controller-0 ~]$ Até três cópias. Mas, a julgar pelos nomes, você pode adivinhar o propósito de cada um deles. Voltaremos a instâncias com IDs 0 e 1 mais tarde, por enquanto estamos interessados no namespace qrouter-0a4d2420-4b9c-46bd-aec1-86a1ef299abe:
[heat-admin@overcloud-controller-0 ~]$ sudo ip netns exec qrouter-0a4d2420-4b9c-46bd-aec1-86a1ef299abe ip route
10.0.1.0/24 dev qr-0c52b15f-8f proto kernel scope link src 10.0.1.254
10.0.2.0/24 dev qr-92fa49b5-54 proto kernel scope link src 10.0.2.254
[heat-admin@overcloud-controller-0 ~]$ Este namespace possui dois internos que criamos anteriormente. Ambas as portas virtuais são adicionadas ao br-int. Vamos verificar o endereço de massa da porta qr-0c52b15f-8f, já que o tráfego, a julgar pelo endereço poppy de destino, foi exatamente para esta interface.
[heat-admin@overcloud-controller-0 ~]$ sudo ip netns exec qrouter-0a4d2420-4b9c-46bd-aec1-86a1ef299abe ifconfig qr-0c52b15f-8f
qr-0c52b15f-8f: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 10.0.1.254 netmask 255.255.255.0 broadcast 10.0.1.255
inet6 fe80::f816:3eff:fec4:6470 prefixlen 64 scopeid 0x20<link>
ether fa:16:3e:c4:64:70 txqueuelen 1000 (Ethernet)
RX packets 5356 bytes 427305 (417.2 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 5195 bytes 490603 (479.1 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
[heat-admin@overcloud-controller-0 ~]$ Ou seja, neste caso, tudo funciona de acordo com as leis de roteamento padrão. Uma vez que o tráfego se destina ao host 10.0.2.8, ele deve sair pela segunda interface qr-92fa49b5-54 e passar pelo túnel vxlan para o nó de computação:
[heat-admin@overcloud-controller-0 ~]$ sudo ip netns exec qrouter-0a4d2420-4b9c-46bd-aec1-86a1ef299abe arp
Address HWtype HWaddress Flags Mask Iface
10.0.1.88 ether fa:16:3e:72:ad:53 C qr-0c52b15f-8f
10.0.1.90 ether fa:16:3e:83:ad:a4 C qr-0c52b15f-8f
10.0.2.8 ether fa:16:3e:6c:ad:9c C qr-92fa49b5-54
10.0.2.42 ether fa:16:3e:f5:0b:29 C qr-92fa49b5-54
10.0.1.85 ether fa:16:3e:44:98:20 C qr-0c52b15f-8f
[heat-admin@overcloud-controller-0 ~]$ Tudo é lógico, sem surpresas. Observamos onde o endereço poppy do host 10.0.2.8 em br-int é visível:
[heat-admin@overcloud-controller-0 ~]$ sudo ovs-appctl fdb/show br-int | grep fa:16:3e:6c:ad:9c
2 2 fa:16:3e:6c:ad:9c 1
[heat-admin@overcloud-controller-0 ~]$
[heat-admin@overcloud-controller-0 ~]$ sudo ovs-ofctl show br-int | grep addr
1(int-br-ex): addr:2e:58:b6:db:d5:de
2(patch-tun): addr:06:41:90:f0:9e:56
3(tapca25a97e-64): addr:fa:16:3e:e6:2c:5c
4(tap22015e46-0b): addr:fa:16:3e:76:c2:11
5(qr-0c52b15f-8f): addr:fa:16:3e:c4:64:70
6(qr-92fa49b5-54): addr:fa:16:3e:80:13:72
LOCAL(br-int): addr:06:de:5d:ed:44:44
[heat-admin@overcloud-controller-0 ~]$ Como esperado, o tráfego vai para br-tun, vamos ver para qual túnel o tráfego vai a seguir:
[heat-admin@overcloud-controller-0 ~]$ sudo ovs-ofctl dump-flows br-tun | grep fa:16:3e:6c:ad:9c
cookie=0x2ab04bf27114410e, duration=5346.829s, table=20, n_packets=5248, n_bytes=498512, hard_timeout=300, idle_age=0, hard_age=0, priority=1,vlan_tci=0x0002/0x0fff,dl_dst=fa:16:3e:6c:ad:9c actions=load:0->NXM_OF_VLAN_TCI[],load:0x63->NXM_NX_TUN_ID[],output:2
[heat-admin@overcloud-controller-0 ~]$
[heat-admin@overcloud-controller-0 ~]$ sudo ovs-ofctl show br-tun | grep addr
1(patch-int): addr:a2:69:00:c5:fa:ba
2(vxlan-c0a8ff1a): addr:86:f0:ce:d0:e8:ea
3(vxlan-c0a8ff13): addr:72:aa:73:2c:2e:5b
LOCAL(br-tun): addr:a6:cb:cd:72:1c:45
[heat-admin@overcloud-controller-0 ~]$
[heat-admin@overcloud-controller-0 ~]$ sudo sudo ovs-appctl dpif/show | grep vxlan-c0a8ff1a
vxlan-c0a8ff1a 2/5: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.15, remote_ip=192.168.255.26)
[heat-admin@overcloud-controller-0 ~]$ O tráfego vai para o túnel para compute-1. Bem, no compute-1 tudo é simples - de br-tun o pacote vai para br-int e de lá para a interface da máquina virtual:
[heat-admin@overcloud-controller-0 ~]$ sudo sudo ovs-appctl dpif/show | grep vxlan-c0a8ff1a
vxlan-c0a8ff1a 2/5: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.15, remote_ip=192.168.255.26)
[heat-admin@overcloud-controller-0 ~]$
[heat-admin@overcloud-novacompute-1 ~]$ sudo ovs-appctl fdb/show br-int | grep fa:16:3e:6c:ad:9c
4 2 fa:16:3e:6c:ad:9c 1
[heat-admin@overcloud-novacompute-1 ~]$ sudo ovs-ofctl show br-int | grep addr
1(int-br-ex): addr:8a:d7:f9:ad:8c:1d
2(patch-tun): addr:46:cc:40:bd:20:da
3(qvoe7e23f1b-07): addr:12:78:2e:34:6a:c7
4(qvo3210e8ec-c0): addr:7a:5f:59:75:40:85
LOCAL(br-int): addr:e2:27:b2:ed:14:46
[heat-admin@overcloud-novacompute-1 ~]$ Vamos verificar se esta é realmente a interface correta:
[heat-admin@overcloud-novacompute-1 ~]$ brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.02429c001e1c no
qbr3210e8ec-c0 8000.ea27f45358be no qvb3210e8ec-c0
tap3210e8ec-c0
qbre7e23f1b-07 8000.b26ac0eded8a no qvbe7e23f1b-07
tape7e23f1b-07
[heat-admin@overcloud-novacompute-1 ~]$
[heat-admin@overcloud-novacompute-1 ~]$ sudo virsh domiflist instance-00000004
Interface Type Source Model MAC
-------------------------------------------------------
tap3210e8ec-c0 bridge qbr3210e8ec-c0 virtio fa:16:3e:6c:ad:9c
[heat-admin@overcloud-novacompute-1 ~]$Na verdade, analisamos todo o pacote. Acho que você notou que o tráfego passou por diferentes túneis vxlan e saiu com diferentes VNIs. Vamos ver que tipo de VNI eles são e, em seguida, coletar um dump na porta de controle do nó e garantir que o tráfego seja exatamente como descrito acima.
Portanto, o túnel para computar-0 tem as seguintes ações = carregar: 0-> NXM_OF_VLAN_TCI [], carregar: 0x16-> NXM_NX_TUN_ID [], saída: 3. Convertendo 0x16 em notação decimal:
0x16 = 6*16^0+1*16^1 = 6+16 = 22O túnel para computar-1 tem o seguinte VNI: actions = load: 0-> NXM_OF_VLAN_TCI [], load: 0x63-> NXM_NX_TUN_ID [], output: 2. Convertendo 0x63 em notação decimal:
0x63 = 3*16^0+6*16^1 = 3+96 = 99Bem, agora vamos ver o despejo:
[root@hp-gen9 bormoglotx]# tcpdump -vvv -i vnet4
tcpdump: listening on vnet4, link-type EN10MB (Ethernet), capture size 262144 bytes
*****************omitted*******************
04:35:18.709949 IP (tos 0x0, ttl 64, id 48650, offset 0, flags [DF], proto UDP (17), length 134)
192.168.255.19.41591 > 192.168.255.15.4789: [no cksum] VXLAN, flags [I] (0x08), vni 22
IP (tos 0x0, ttl 64, id 49042, offset 0, flags [DF], proto ICMP (1), length 84)
10.0.1.85 > 10.0.2.8: ICMP echo request, id 5378, seq 9, length 64
04:35:18.710159 IP (tos 0x0, ttl 64, id 23360, offset 0, flags [DF], proto UDP (17), length 134)
192.168.255.15.38983 > 192.168.255.26.4789: [no cksum] VXLAN, flags [I] (0x08), vni 99
IP (tos 0x0, ttl 63, id 49042, offset 0, flags [DF], proto ICMP (1), length 84)
10.0.1.85 > 10.0.2.8: ICMP echo request, id 5378, seq 9, length 64
04:35:18.711292 IP (tos 0x0, ttl 64, id 43596, offset 0, flags [DF], proto UDP (17), length 134)
192.168.255.26.42588 > 192.168.255.15.4789: [no cksum] VXLAN, flags [I] (0x08), vni 99
IP (tos 0x0, ttl 64, id 55103, offset 0, flags [none], proto ICMP (1), length 84)
10.0.2.8 > 10.0.1.85: ICMP echo reply, id 5378, seq 9, length 64
04:35:18.711531 IP (tos 0x0, ttl 64, id 8555, offset 0, flags [DF], proto UDP (17), length 134)
192.168.255.15.38983 > 192.168.255.19.4789: [no cksum] VXLAN, flags [I] (0x08), vni 22
IP (tos 0x0, ttl 63, id 55103, offset 0, flags [none], proto ICMP (1), length 84)
10.0.2.8 > 10.0.1.85: ICMP echo reply, id 5378, seq 9, length 64
*****************omitted*******************O primeiro pacote é um pacote vxlan do host 192.168.255.19 (compute-0) para o host 192.168.255.15 (control-1) com vni 22, dentro do qual um pacote ICMP é compactado do host 10.0.1.85 para o host 10.0.2.8. Como calculamos acima, vni corresponde ao que vimos nas saídas.
O segundo pacote é um pacote vxlan do host 192.168.255.15 (control-1) para o host 192.168.255.26 (compute-1) com vni 99, dentro do qual um pacote ICMP é empacotado do host 10.0.1.85 para o host 10.0.2.8. Como calculamos acima, vni corresponde ao que vimos nas saídas.
Os próximos dois pacotes são o tráfego de retorno de 10.0.2.8, não de 10.0.1.85.
Ou seja, como resultado, obtivemos o seguinte esquema de nó de controle:

Gosta de tudo? Esquecemos dois namespaces:
[heat-admin@overcloud-controller-0 ~]$ sudo ip netns
qrouter-0a4d2420-4b9c-46bd-aec1-86a1ef299abe (id: 2)
qdhcp-7d541e74-1c36-4e1d-a7c4-0968c8dbc638 (id: 1)
qdhcp-67a3798c-32c0-4c18-8502-2531247e3cc2 (id: 0)
[heat-admin@overcloud-controller-0 ~]$ Como falamos sobre a arquitetura da plataforma em nuvem, seria bom se as máquinas recebessem endereços automaticamente de um servidor DHCP. Estes são dois servidores DHCP para nossas duas redes 10.0.1.0/24 e 10.0.2.0/24.
Vamos verificar se é assim. Há apenas um endereço neste namespace - 10.0.1.1 - o endereço do próprio servidor DHCP, e também está incluído no br-int:
[heat-admin@overcloud-controller-0 ~]$ sudo ip netns exec qdhcp-67a3798c-32c0-4c18-8502-2531247e3cc2 ifconfig
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 1 bytes 28 (28.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 1 bytes 28 (28.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
tapca25a97e-64: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 10.0.1.1 netmask 255.255.255.0 broadcast 10.0.1.255
inet6 fe80::f816:3eff:fee6:2c5c prefixlen 64 scopeid 0x20<link>
ether fa:16:3e:e6:2c:5c txqueuelen 1000 (Ethernet)
RX packets 129 bytes 9372 (9.1 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 49 bytes 6154 (6.0 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0Vamos ver se os processos que contêm qdhcp-67a3798c-32c0-4c18-8502-2531247e3cc2 em seus nomes no nó de controle:
[heat-admin@overcloud-controller-0 ~]$ ps -aux | egrep qdhcp-7d541e74-1c36-4e1d-a7c4-0968c8dbc638
root 640420 0.0 0.0 4220 348 ? Ss 11:31 0:00 dumb-init --single-child -- ip netns exec qdhcp-7d541e74-1c36-4e1d-a7c4-0968c8dbc638 /usr/sbin/dnsmasq -k --no-hosts --no-resolv --pid-file=/var/lib/neutron/dhcp/7d541e74-1c36-4e1d-a7c4-0968c8dbc638/pid --dhcp-hostsfile=/var/lib/neutron/dhcp/7d541e74-1c36-4e1d-a7c4-0968c8dbc638/host --addn-hosts=/var/lib/neutron/dhcp/7d541e74-1c36-4e1d-a7c4-0968c8dbc638/addn_hosts --dhcp-optsfile=/var/lib/neutron/dhcp/7d541e74-1c36-4e1d-a7c4-0968c8dbc638/opts --dhcp-leasefile=/var/lib/neutron/dhcp/7d541e74-1c36-4e1d-a7c4-0968c8dbc638/leases --dhcp-match=set:ipxe,175 --local-service --bind-dynamic --dhcp-range=set:subnet-335552dd-b35b-456b-9df0-5aac36a3ca13,10.0.2.0,static,255.255.255.0,86400s --dhcp-option-force=option:mtu,1450 --dhcp-lease-max=256 --conf-file= --domain=openstacklocal
heat-ad+ 951620 0.0 0.0 112944 980 pts/0 S+ 18:50 0:00 grep -E --color=auto qdhcp-7d541e74-1c36-4e1d-a7c4-0968c8dbc638
[heat-admin@overcloud-controller-0 ~]$ Existe tal processo, e com base nas informações apresentadas na saída acima, podemos, por exemplo, ver o que temos em aluguel no momento:
[heat-admin@overcloud-controller-0 ~]$ cat /var/lib/neutron/dhcp/7d541e74-1c36-4e1d-a7c4-0968c8dbc638/leases
1597492111 fa:16:3e:6c:ad:9c 10.0.2.8 host-10-0-2-8 01:fa:16:3e:6c:ad:9c
1597491115 fa:16:3e:76:c2:11 10.0.2.1 host-10-0-2-1 *
[heat-admin@overcloud-controller-0 ~]$Como resultado, obtemos esse conjunto de serviços no nó de controle:

Bem, tenha em mente - são apenas - 4 máquinas, 2 redes internas e um roteador virtual ... Não temos redes externas aqui agora, montes de projetos diferentes, cada um com suas próprias redes (sobrepostos ) e desligamos o roteador distribuído e, no final, havia apenas um nó de controle na bancada de teste (para tolerância a falhas, deve haver um quorum de três nós). É lógico que no comércio tudo é "um pouco" mais complicado, mas neste exemplo simples entendemos como isso deve funcionar - se você tem 3 ou 300 namespaces, claro, é importante, mas do ponto de vista do funcionamento de toda a estrutura, nada mudará muito ... mas contanto que você não fure algum tipo de vendedor SDN. Mas essa é uma história completamente diferente.
Espero que tenha sido interessante. Se houver comentários / acréscimos bem, ou em algum lugar eu menti abertamente (eu sou um ser humano e minha opinião sempre será subjetiva) - escreva o que precisa ser corrigido / adicionado - iremos corrigir / adicionar tudo.
Concluindo, gostaria de dizer algumas palavras sobre a comparação do Openstack (vanilla e fornecedor) com uma solução em nuvem da VMWare - muitas vezes me perguntaram essa pergunta nos últimos anos e, para ser honesto, estou cansado disso, mas ainda assim. Na minha opinião, essas duas soluções são muito difíceis de comparar, mas podemos dizer inequivocamente que existem desvantagens em ambas as soluções e, ao escolher uma solução, é preciso pesar os prós e os contras.
Se o OpenStack é uma solução voltada para a comunidade, então a VMWare tem o direito de fazer apenas o que quiser (leia - o que é lucrativo para ela) e isso é lógico - porque é uma empresa comercial acostumada a ganhar dinheiro com seus clientes. Mas há um grande e gordo MAS - você pode sair do OpenStack da Nokia, por exemplo, e mudar para uma solução de, por exemplo, Juniper (Contrail Cloud), mas dificilmente você conseguirá sair do VMWare. Para mim, essas duas soluções se parecem com isto - Openstack (fornecedor) é uma gaiola simples na qual você é colocado, mas você tem a chave e pode sair a qualquer momento. VMWare é uma gaiola dourada, o dono tem a chave da gaiola e isso vai custar caro.
Não estou fazendo campanha nem para o primeiro produto nem para o segundo - você escolhe o que precisa. Mas se eu tivesse essa escolha, então eu escolheria ambas as soluções - VMWare para nuvem de TI (cargas baixas, gerenciamento conveniente), OpenStack de algum fornecedor (Nokia e Juniper fornecem soluções turnkey muito boas) - para nuvens de telecomunicações. Eu não usaria o Openstack para TI puro - é como atirar em um pardal com um canhão, mas não vejo nenhuma contra-indicação para usá-lo, exceto para redundância. No entanto, usar VMWare em telecomunicações - como transportar entulho em um Ford Raptor - é bonito por fora, mas o motorista precisa fazer 10 viagens em vez de uma.
Na minha opinião, a maior desvantagem do VMWare é seu completo fechamento - a empresa não dará nenhuma informação sobre como ele funciona, por exemplo, vSAN ou o que está no núcleo do hipervisor - simplesmente não é lucrativo para ele - ou seja, você nunca se tornará um especialista em VMWare - sem o suporte do fornecedor, você está condenado (muitas vezes encontro especialistas em VMWare que ficam perplexos com perguntas banais). Para mim, VMWare é comprar um carro com capô trancado - sim, talvez você tenha especialistas que podem trocar a correia dentada, mas só quem lhe vendeu esta solução pode abrir o capô. Pessoalmente, não gosto de soluções nas quais não me encaixo. Você dirá que pode não ter que ir para debaixo do capô. Sim, isso é possível, mas vou olhar para você quando precisar montar uma grande função na nuvem de 20-30 máquinas virtuais, 40-50 redes,metade quer sair, e a outra metade pede aceleração SR-IOV, caso contrário, você precisará de mais algumas dezenas dessas máquinas - caso contrário, o desempenho não será suficiente.
Existem outros pontos de vista, então cabe a você decidir o que escolher e, o mais importante, você é responsável por sua escolha mais tarde. Esta é apenas a minha opinião - uma pessoa que viu e tocou em pelo menos 4 produtos - Nokia, Juniper, Red Hat e VMWare. Ou seja, tenho algo com o que comparar.