Muito na vida de um projeto depende de quão bem pensado o modelo de objeto e a estrutura básica no início.
A abordagem geralmente aceita tem sido e continua sendo várias opções para combinar o esquema "estrela" com a terceira forma normal. Como regra, de acordo com o princípio: dados iniciais - 3NF, vitrines - estrela. Essa abordagem testada pelo tempo, apoiada por muitas pesquisas, é a primeira (e às vezes a única) coisa em que uma pessoa experiente em DWH pensa ao pensar sobre como um repositório analítico deve ser.
Por outro lado, os negócios em geral e os requisitos dos clientes em particular tendem a mudar rapidamente e os dados crescem tanto para dentro quanto para fora. E é aqui que a principal desvantagem da estrela se manifesta - flexibilidade limitada .
E se em sua vida tranquila e aconchegante como um desenvolvedor DWH, de repente:
- a tarefa surgiu “fazer pelo menos algo rápido, e então veremos”;
- surgiu um projeto de rápido desenvolvimento, com conexão de novas fontes e retrabalho do modelo de negócios pelo menos uma vez por semana;
- apareceu um cliente que não imagina qual seria a aparência do sistema e quais funções ele deveria desempenhar no final, mas está pronto para experimentos e refinamento consistente do resultado desejado com uma abordagem consistente para ele;
- o gerente de projeto apareceu com a boa notícia: "E agora temos o Agile!"
Ou se você está apenas curioso para saber de que outra forma pode criar armazenamento - bem-vindo sob o gato!

O que significa flexibilidade?
Primeiro, vamos definir quais propriedades o sistema deve ter para ser chamado de “flexível”.
Separadamente, deve-se observar que as propriedades descritas devem se referir especificamente ao sistema , e não ao processo de seu desenvolvimento. Portanto, se você quiser ler sobre Agile como metodologia de desenvolvimento, é melhor ler outros artigos. Por exemplo, ali mesmo, em Habré, há uma grande quantidade de materiais interessantes ( visão geral e prática , e problemática ).
Isso não significa que o processo de desenvolvimento e a estrutura do CD não estejam de forma alguma conectados. Em geral, deve ser muito mais fácil desenvolver armazenamento ágil de arquitetura flexível. No entanto, na prática, existem mais opções com o desenvolvimento ágil do DWH clássico por Kimball e DataVault por cascata do que felizes coincidências de flexibilidade em suas duas hipóstases em um projeto.
Portanto, quais recursos o armazenamento flexível deve ter? Existem três pontos aqui:
- A entrega antecipada e a revisão rápida significam que, idealmente, o primeiro resultado do negócio (por exemplo, os primeiros relatórios de trabalho) deve ser recebido o mais cedo possível, ou seja, antes mesmo de todo o sistema ser totalmente projetado e implementado. Além disso, cada revisão subsequente deve levar o mínimo de tempo possível.
- — , . — , , . , , — .
- Adaptação constante aos requisitos de negócios em mudança - a estrutura geral do objeto deve ser projetada não apenas levando em consideração a possível expansão, mas com a expectativa de que a direção desta próxima expansão pode nem mesmo sonhar com você no estágio de design.
E sim, o cumprimento de todos esses requisitos em um sistema é possível (claro, em certos casos e com algumas reservas).
Abaixo, considerarei duas das metodologias de design ágil mais populares para HD - modelo âncora e armazenamento de dados.... Atrás dos colchetes estão técnicas excelentes como EAV, 6NF (em sua forma pura) e tudo relacionado a soluções NoSQL - não porque sejam de alguma forma piores, e nem mesmo porque neste caso o artigo ameaçaria adquirir o volume da média dissera. É que tudo isso se refere a soluções de uma classe ligeiramente diferente - seja a técnicas que você pode aplicar em casos específicos, independentemente da arquitetura geral do seu projeto (como EAV), ou a outros paradigmas de armazenamento de informação globalmente (como bancos de dados de gráficos e outras opções NoSQL).
Problemas da abordagem "clássica" e suas soluções em metodologias ágeis
Por abordagem "clássica", quero dizer uma boa e velha estrela (independentemente da implementação específica das camadas subjacentes, perdoem-me os seguidores de Kimball, Inmon e CDM).
1. Cardinalidade rígida de empates
Este modelo é baseado em uma separação clara de dados em dimensões (Dimensão) e fatos (Fato) . E isso, droga, é lógico - afinal, a análise de dados na grande maioria dos casos se resume apenas à análise de certos indicadores numéricos (fatos) em certas seções (dimensões).
Nesse caso, os links entre objetos são colocados na forma de links entre tabelas por uma chave estrangeira. Isso parece bastante natural, mas imediatamente leva à primeira limitação da flexibilidade - uma definição rígida da cardinalidade das conexões .
Isso significa que, no estágio de design das tabelas, você deve definir precisamente para cada par de objetos relacionados se eles podem ser muitos para muitos ou apenas um para muitos e "em que direção". Depende diretamente de qual das tabelas terá uma chave primária e qual terá uma chave externa. Mudar essa atitude quando novos requisitos são recebidos provavelmente levará a um redesenho da base.
Por exemplo, ao projetar o objeto "caixa registradora", você, apoiando-se nos juramentos do departamento de vendas, estabeleceu a possibilidade de uma promoção atuar em várias posições de cheque (mas não vice-versa):
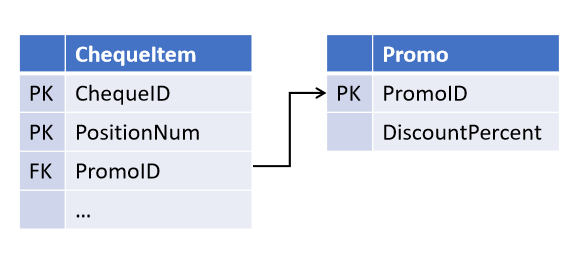
E depois de um tempo, os colegas introduziram uma nova estratégia de marketing, na qual várias promoções podem atuar simultaneamente na mesma posição . E agora você precisa modificar as tabelas selecionando o link em um objeto separado.
(Todos os objetos derivados, nos quais ocorre uma verificação promocional, agora também precisam ser melhorados).
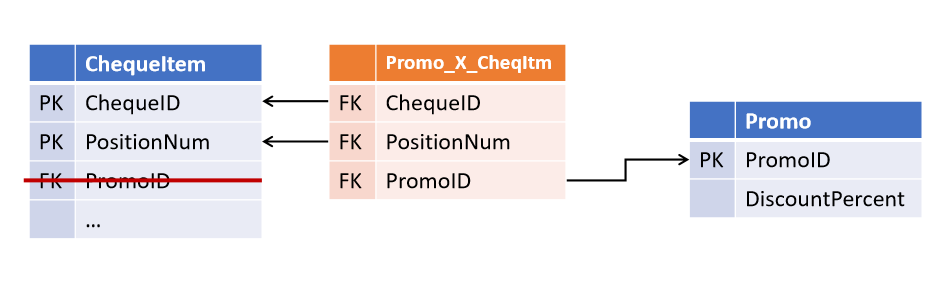
Links no Data Vault e no modelo âncora Acabou
sendo bastante simples evitar tal situação: você
Esta abordagem foi proposta por Dan Linstedt como parte do paradigma Data Vault e é totalmente suportada por Lars Rönnbäck no Modelo Âncora .
Como resultado, obtemos a primeira característica distintiva das metodologias ágeis:
Os relacionamentos entre objetos não são armazenados nos atributos de entidades pai, mas são um tipo separado de objeto.Os Data Vault são table-ligament chamados Link , e os modelos Anchor - o Tie . À primeira vista, eles são muito semelhantes, embora suas diferenças não se limitem ao nome (que será discutido a seguir). Em ambas as arquiteturas, as tabelas de link podem vincular qualquer número de entidades (não necessariamente 2).
À primeira vista, essa redundância fornece flexibilidade significativa para modificações. Essa estrutura torna-se tolerante não apenas para alterar a cardinalidade dos links existentes, mas também para adicionar novos - se agora a posição do cheque também tiver um link para o caixa que a digitou, a aparência de tal link se tornará simplesmente um add-on sobre as tabelas existentes sem afetar quaisquer objetos existentes e processos.

2. Duplicação de dados
O segundo problema, resolvido por arquiteturas flexíveis, é menos óbvio e é inerente principalmente às medições do tipo SCD2 (dimensões que mudam lentamente do segundo tipo), embora não apenas para elas.
Em um armazenamento clássico, uma dimensão geralmente é uma tabela que contém uma chave substituta (como PK) e um conjunto de chaves de negócios e atributos em colunas separadas.

Se a dimensão tiver uma versão, os limites de tempo da versão serão adicionados ao conjunto padrão de campos e várias versões aparecerão por linha na origem na loja (uma para cada alteração nos atributos com versão).
Se uma dimensão contiver pelo menos um atributo versionado com mudança frequente, o número de versões de tal dimensão será impressionante (mesmo se os outros atributos não forem versionados ou nunca mudarem), e se houver vários desses atributos, o número de versões pode crescer exponencialmente de seu número. Essa dimensão pode ocupar uma quantidade significativa de espaço em disco, embora a maioria dos dados armazenados nela sejam simplesmente valores duplicados de atributos inalterados de outras linhas.

Ao mesmo tempo, a desnormalização também é usada com muita frequência - alguns dos atributos são armazenados intencionalmente como um valor, e não uma referência a um diretório ou outra dimensão. Essa abordagem acelera o acesso aos dados, reduzindo o número de junções ao acessar uma dimensão.
Como regra, isso leva ao fato de quea mesma informação é armazenada simultaneamente em vários lugares . Por exemplo, as informações sobre a região de residência e pertencentes à categoria do cliente podem ser armazenadas simultaneamente nas dimensões "Cliente" e os fatos "Compra", "Entrega" e "Chamadas para o call center", bem como na tabela de ligação "Cliente - Gerente de cliente".
Em geral, o acima se aplica a medições regulares (sem versão), mas nas versões podem ter uma escala diferente: o aparecimento de uma nova versão de um objeto (especialmente em retrospectiva) leva não apenas à atualização de todas as tabelas relacionadas, mas ao aparecimento em cascata de novas versões de objetos relacionados - quando a Tabela 1 é usada para construir a Tabela 2 e a Tabela 2 é usada para construir a Tabela 3, etc. Mesmo que nenhum dos atributos da Tabela 1 participe da construção da Tabela 3 (e outros atributos da Tabela 2 obtidos de outras fontes estejam envolvidos), uma atualização de versão desta construção levará pelo menos a custos indiretos adicionais, e no máximo - a versões desnecessárias na Tabela 3. que nada tem a ver com isso e mais ao longo da cadeia.

3. Complexidade não linear de revisão
Além disso, cada novo mart, construído sobre o outro, aumenta o número de locais nos quais os dados podem "divergir" ao fazer alterações no ETL. Isso, por sua vez, leva a um aumento na complexidade (e duração) de cada revisão subsequente.
Se o que foi dito acima diz respeito a sistemas com processos ETL raramente modificados, você pode viver em tal paradigma - você só precisa ter certeza de que as novas modificações são introduzidas corretamente em todos os objetos relacionados. Se as revisões ocorrerem com frequência, a probabilidade de “perder” acidentalmente várias conexões aumenta significativamente.
Se, além disso, levarmos em conta que ETL “versionado” é muito mais complicado do que “não versionado”, torna-se muito difícil evitar erros com revisões frequentes de toda esta economia.
Armazenamento de objetos e atributos no Data Vault e no modelo âncora
A abordagem proposta pelos autores de arquiteturas ágeis pode ser formulada da seguinte forma:
É necessário separar o que muda do que permanece inalterado. Ou seja, mantenha as chaves separadas dos atributos.Ao mesmo tempo, não se deve confundir um atributo sem versão com um inalterado : o primeiro não armazena o histórico de sua mudança, mas pode mudar (por exemplo, quando um erro de entrada é corrigido ou novos dados são recebidos); o segundo nunca muda.
Os pontos de vista sobre o que exatamente pode ser considerado imutável no Data Vault e no Modelo de âncora são diferentes.
Do ponto de vista da arquitetura do Data Vault , todo o conjunto de chaves pode ser considerado inalterado - natural (TIN da organização, código do produto no sistema de origem, etc.) e substituto. Ao mesmo tempo, os atributos restantes podem ser divididos em grupos por origem e / ou frequência de alterações, e uma tabela separada com um conjunto independente de versões pode ser mantida para cada grupo .
No paradigmaModelo âncora é considerado chave substituta de entidade imutável apenas . Todo o resto (incluindo chaves naturais) é apenas um caso especial de seus atributos. Ao mesmo tempo, todos os atributos por padrão são independentes uns dos outros , portanto, uma tabela separada deve ser criada para cada atributo .
No Data Vault, as tabelas que contêm chaves de entidade são chamadas de Hubs . Os hubs sempre contêm um conjunto fixo de campos:
- Chaves naturais de entidade
- Chave substituta
- Link para a fonte
- Tempo de adição de registro
As entradas nos hubs nunca são alteradas e não têm versão . Externamente, os hubs são muito semelhantes às tabelas do tipo de mapa de ID usadas em alguns sistemas para gerar substitutos, no entanto, é recomendado usar não uma sequência inteira como substitutos no Data Vault, mas um hash de um conjunto de chaves de negócios. Essa abordagem simplifica o carregamento de links e atributos de fontes (você não precisa se juntar ao hub para obter um substituto, você só precisa calcular o hash da chave natural), mas pode causar outros problemas (relacionados, por exemplo, a colisões, maiúsculas e minúsculas e caracteres não imprimíveis em chaves de string, etc.) .p.), portanto, não é geralmente aceito.
Todos os outros atributos da entidade são armazenados em tabelas especiais chamadas Satélites... Um hub pode ter vários satélites armazenando diferentes conjuntos de atributos.
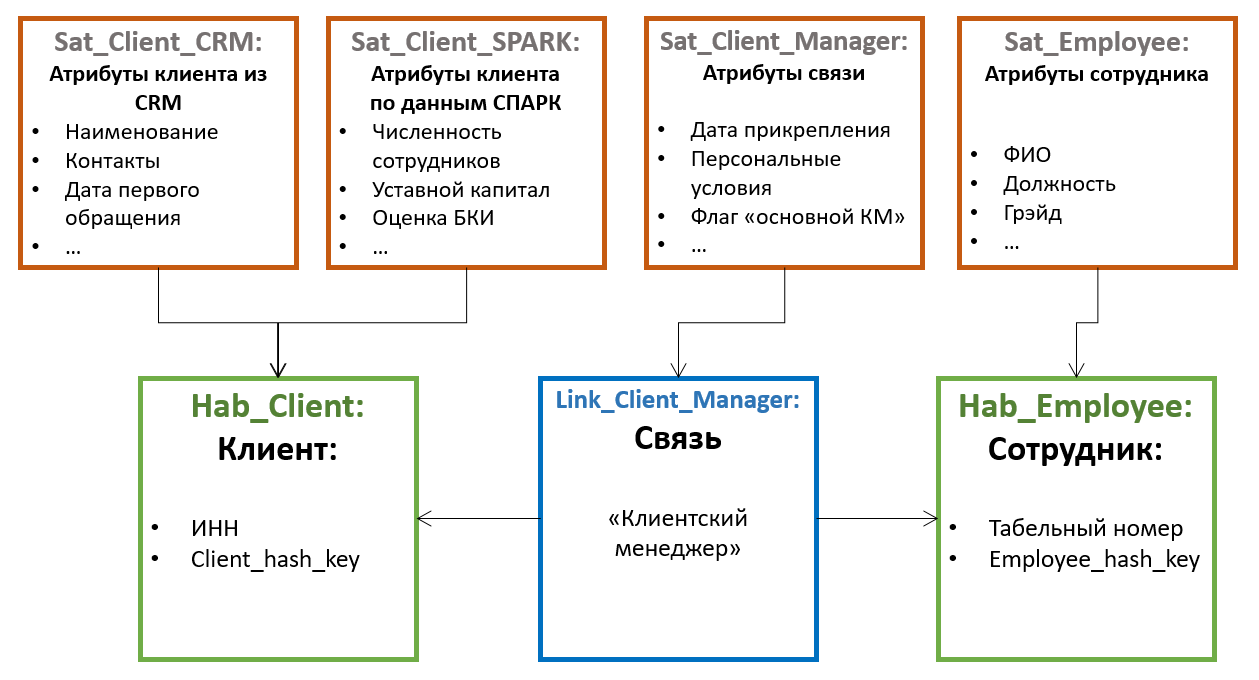
A distribuição de atributos entre os satélites é baseada no princípio da mudança conjunta - um satélite pode armazenar atributos não versionados (por exemplo, data de nascimento e SNILS para um indivíduo), em outro - raramente mudando os versionados (por exemplo, sobrenome e número do passaporte), no terceiro - frequentemente alteração (por exemplo, endereço de entrega, categoria, data do último pedido, etc.). Neste caso, o versionamento é realizado no nível de satélites individuais, e não da entidade como um todo; portanto, é aconselhável distribuir os atributos de forma que a interseção das versões dentro de um satélite seja mínima (o que reduz o número total de versões armazenadas).
Além disso, para otimizar o processo de carregamento de dados, os atributos obtidos de várias fontes são frequentemente colocados em satélites separados.
Os satélites se comunicam com o hub usando uma chave estrangeira (que corresponde a uma cardinalidade 1 para muitos). Isso significa que vários valores de atributo (por exemplo, vários números de telefone de contato para o mesmo cliente) são suportados por esta arquitetura “padrão”.
No modelo âncora, as tabelas que contêm chaves são chamadas de âncora . E eles mantêm:
- Surrogate keys apenas
- Link para a fonte
- Tempo de adição de registro
Chaves naturais são consideradas atributos comuns do ponto de vista do Modelo Âncora . Esta opção pode parecer mais difícil de entender, mas oferece muito mais espaço para a identificação de objetos.

Por exemplo, se os dados sobre a mesma entidade podem vir de sistemas diferentes, cada um dos quais usa sua própria chave natural. No Cofre de dados, isso pode levar a estruturas bastante complicadas de vários hubs (um por fonte + a versão mestre unificadora), enquanto no modelo Âncora, a chave natural de cada fonte cai em seu próprio atributo e pode ser usada durante o carregamento independentemente de todas as outras.
Mas há um ponto insidioso aqui: se atributos de sistemas diferentes são combinados em uma entidade, muito provavelmente há algunsregras de "colagem" , segundo as quais o sistema deve entender que os registros de diferentes fontes correspondem a uma instância de uma entidade.
No Data Vault, essas regras provavelmente determinarão a formação do "hub substituto" da entidade mestre e não afetarão de forma alguma os hubs que armazenam as chaves naturais das fontes e seus atributos originais. Se em algum ponto as regras de emenda mudarem (ou uma atualização dos atributos pelos quais ela é feita) vier, será o suficiente para reformar os hubs substitutos.
No modelo Âncora, entretanto, tal entidade provavelmente será armazenada em uma única âncora.... Isso significa que todos os atributos, independentemente da fonte de onde vêm, serão vinculados ao mesmo substituto. Separar registros mesclados erroneamente e, em geral, acompanhar a relevância da mesclagem em tal sistema pode ser significativamente mais difícil, especialmente se as regras são complexas o suficiente e mudam frequentemente, e o mesmo atributo pode ser obtido de fontes diferentes (embora seja definitivamente possível, uma vez que cada a versão do atributo retém um link para sua fonte).
Em qualquer caso, se o seu sistema deve implementar a funcionalidade de desduplicação, mesclar registros e outros elementos de MDM, vale a pena dar uma olhada nos aspectos de armazenamento de chaves naturais em metodologias ágeis. O design mais complicado do Data Vault provavelmente se mostrará mais seguro em termos de erros de mesclagem.
O modelo de âncora também fornece um tipo adicional de objeto denominado Nó; na verdade, é um tipo especial de âncora degenerado que pode conter apenas um atributo. Os nós devem ser usados para armazenar livros de referência simples (por exemplo, gênero, estado civil, categoria de serviço ao cliente, etc.). Ao contrário de Anchor, Node não tem tabelas de atributos associadas, e seu único atributo (nome) é sempre armazenado na mesma tabela com a chave. Os nós são vinculados às tabelas Anchors por Tie, assim como as âncoras estão entre si.
Não há uma opinião inequívoca sobre o uso de nós. Por exemplo, Nikolai Golov , que está promovendo ativamente o uso do Modelo de Âncora na Rússia, acredita (não sem razão) que, para nenhum livro de referência, é impossível dizer com certeza que sempre será estático e de nível único, portanto, é melhor usar uma Âncora de pleno direito para todos os objetos de uma vez.
Outra diferença importante entre o Data Vault e o modelo Anchor é a presença de atributos para os links :
No Data Vault, os Links são os mesmos objetos completos que os Hubs e podem terpróprios atributos . No modelo Âncora, os Links são usados apenas para conectar Âncoras e não podem ter seus próprios atributos . Essa diferença fornece abordagens significativamente diferentes para modelar fatos , que serão discutidos abaixo.
Armazenando fatos
Antes disso, falamos principalmente sobre modelagem de medidas. Os fatos são um pouco menos diretos.
No Data Vault, um objeto típico para armazenar fatos é um Link , aos Satélites do qual são adicionados indicadores reais.
Essa abordagem parece intuitiva. Oferece fácil acesso aos indicadores analisados e geralmente é semelhante a uma tabela de fatos tradicional (apenas os indicadores são armazenados não na própria tabela, mas na “adjacente”). Mas também existem armadilhas: uma das modificações típicas do modelo - expandir a chave do fato - exige a adição de uma nova chave estrangeira ao Link . E isso, por sua vez, "quebra" a modularidade e potencialmente causa a necessidade de melhorias em outros objetos.
No modelo âncoraUm link não pode ter seus próprios atributos, então essa abordagem não funcionará - absolutamente todos os atributos e indicadores devem ser vinculados a uma âncora específica. A conclusão disso é simples - cada fato também precisa de sua própria âncora . Para parte do que estamos acostumados a tomar como fatos, pode parecer natural - por exemplo, o fato de uma compra é perfeitamente reduzido ao objeto “pedido” ou “cheque”, uma visita a um site - a uma sessão, etc. Mas também há fatos para os quais não é tão fácil encontrar um “objeto de transporte” natural - por exemplo, restos de mercadorias em depósitos no início de cada dia.
Consequentemente, não há problemas com a modularidade ao expandir a chave de fato no modelo Âncora (é suficiente apenas adicionar um novo Link à Âncora correspondente), mas o design do modelo para exibir fatos é menos ambíguo, Âncoras "artificiais" podem aparecer que refletem o modelo de objeto de negócios não é óbvio.
Como a flexibilidade é alcançada
A construção resultante em ambos os casos contém significativamente mais tabelas do que a dimensão tradicional. Mas pode ocupar significativamente menos espaço em disco com o mesmo conjunto de atributos com versão que uma dimensão tradicional. Naturalmente, não há mágica aqui - é tudo sobre normalização. Ao distribuir atributos entre satélites (no Data Vault) ou tabelas separadas (modelo âncora), reduzimos (ou eliminamos completamente) a duplicação de valores de alguns atributos ao alterar outros .
Para o Data Vault, o ganho dependerá da distribuição de atributos entre os satélites e, para o modelo âncora , será quase diretamente proporcional ao número médio de versões por objeto de medição.
No entanto, ganhar espaço é uma vantagem importante, mas não a principal, de armazenar atributos separadamente. Junto com o armazenamento de links separadamente, essa abordagem torna o repositório um design modular . Isso significa que a adição de atributos individuais e áreas de assunto totalmente novas em tal modelo parece um add- on sobre um conjunto existente de objetos, sem alterá-los. E é exatamente isso que torna as metodologias descritas flexíveis.
Também se assemelha à transição da produção de peças para a produção em massa - se na abordagem tradicional cada mesa de modelo é única e requer atenção separada, então em metodologias flexíveis já é um conjunto de “detalhes” típicos. Por um lado, existem mais tabelas, os processos de carregamento e obtenção de dados devem parecer mais complicados. Por outro lado, eles se tornam típicos . Isso significa que eles podem ser automatizados e gerenciados por metadados . A pergunta “como vamos fazer?”, Cuja resposta poderia ocupar uma parte significativa do desenho de melhorias, agora simplesmente não vale a pena (assim como a questão do impacto das mudanças de modelo nos processos de trabalho).
Isso não significa que os analistas não sejam necessários em tal sistema - alguém ainda tem que trabalhar por meio de um conjunto de objetos com atributos e descobrir onde e como carregar tudo isso. Mas a quantidade de trabalho, bem como a probabilidade e o custo de um erro, são significativamente reduzidos. Tanto na fase de análise como durante o desenvolvimento do ETL, que em uma parte essencial pode ser reduzido à edição de metadados.
Lado escuro
Todos os itens acima tornam as duas abordagens realmente flexíveis, tecnologicamente avançadas e adequadas para refinamento iterativo. Claro, há também um “barril de pomada”, que acho que você já está adivinhando.
A decomposição de dados, que é a base da modularidade de arquiteturas flexíveis, leva a um aumento no número de tabelas e, consequentemente, à sobrecarga de joins durante a busca. Para obter simplesmente todos os atributos de uma dimensão, uma seleção é suficiente no repositório clássico e uma arquitetura flexível exigirá várias junções. Além disso, se para relatórios todas essas junções puderem ser escritas com antecedência, os analistas que estão acostumados a escrever SQL manualmente sofrerão duplamente.
Existem vários fatos que tornam esta situação mais fácil:
Ao trabalhar com grandes dimensões, todos os seus atributos quase nunca são usados simultaneamente. Isso significa que pode haver menos junções do que parece quando você olha o modelo pela primeira vez. No Data Vault, você também pode levar em consideração a frequência de compartilhamento esperada ao distribuir atributos entre os satélites. Ao mesmo tempo, os próprios hubs ou âncoras são necessários principalmente para gerar e mapear substitutos no estágio de carregamento e raramente são usados em solicitações (especialmente para âncoras).
Todas as junções são por chave.Além disso, uma maneira mais “concisa” de armazenar dados reduz a sobrecarga de varredura de tabelas onde são necessários (por exemplo, ao filtrar por valor de atributo). Isso pode levar ao fato de que buscar em um banco de dados normalizado com um monte de junções será ainda mais rápido do que varrer uma dimensão pesada com muitas versões por linha.
Por exemplo, aqui neste artigo há um teste de desempenho comparativo detalhado do Modelo Âncora com uma seleção de uma única tabela.
Muito depende do motor. Muitas plataformas modernas têm mecanismos de otimização de junção interna. Por exemplo, MS SQL e Oracle são capazes de “pular” junções a tabelas se seus dados não forem usados em qualquer lugar exceto para outras junções e não afetam a seleção final (tabela / eliminação de junções), enquanto MPP Vertica éA experiência dos colegas da Avito , provou ser um excelente motor para o modelo Anchor, levando em consideração algumas otimizações manuais do plano de consulta. Por outro lado, manter o modelo âncora, por exemplo, na Click House, que tem suporte de junção limitado, não parece uma boa ideia por enquanto.
Além disso, existem técnicas especiais para ambas as arquiteturas para tornar os dados mais fáceis de acessar (tanto de uma perspectiva de desempenho de consulta quanto para usuários finais). Por exemplo, tabelas Point-In-Time no Data Vault ou funções de tabela especiais no Modelo Âncora.
Total
A principal essência das arquiteturas consideradas flexíveis é a modularidade do seu “design”.
É esta propriedade que permite:
- , ETL, , . ( ) .
- ( ) 2-3 , ( ).
- , - .
- Devido à decomposição em elementos padrão, os processos ETL em tais sistemas parecem do mesmo tipo, sua escrita se presta a algoritmos e, em última análise, automação .
O preço dessa flexibilidade é o desempenho . Isso não significa que seja impossível atingir um desempenho aceitável em tais modelos. Na maioria das vezes, você só precisa de mais esforço e atenção aos detalhes para atingir as métricas que deseja.
Formulários
Tipos de entidade de cofre de dados

Leia mais sobre o Data Vault:
site de Dan Listadt
Tudo sobre o Data Vault em russo
Sobre o Data Vault em Habré
Tipos de entidade modelo âncora

Mais sobre o Modelo Âncora:
Site dos criadores do Modelo Âncora
Um artigo sobre a experiência de implementação do Modelo Âncora no Avito
Uma tabela de resumo com características comuns e diferenças das abordagens consideradas:
