Esta não é uma análise sistemática e nem uma tabela. Uma visão individual, também do ponto de vista de um geofísico. Mas estou sempre curioso para ler o Gartner MQ, eles formulam alguns pontos perfeitamente. Então, aqui estão as coisas às quais prestei atenção em termos técnicos, de mercado e filosóficos.
Isso não é para pessoas que estão profundamente em ML, mas para pessoas que estão interessadas no que geralmente está acontecendo no mercado.
O próprio mercado de DSML se aninha logicamente entre os serviços de desenvolvedor de BI e Cloud AI.
Primeiras citações e termos de que gostou:
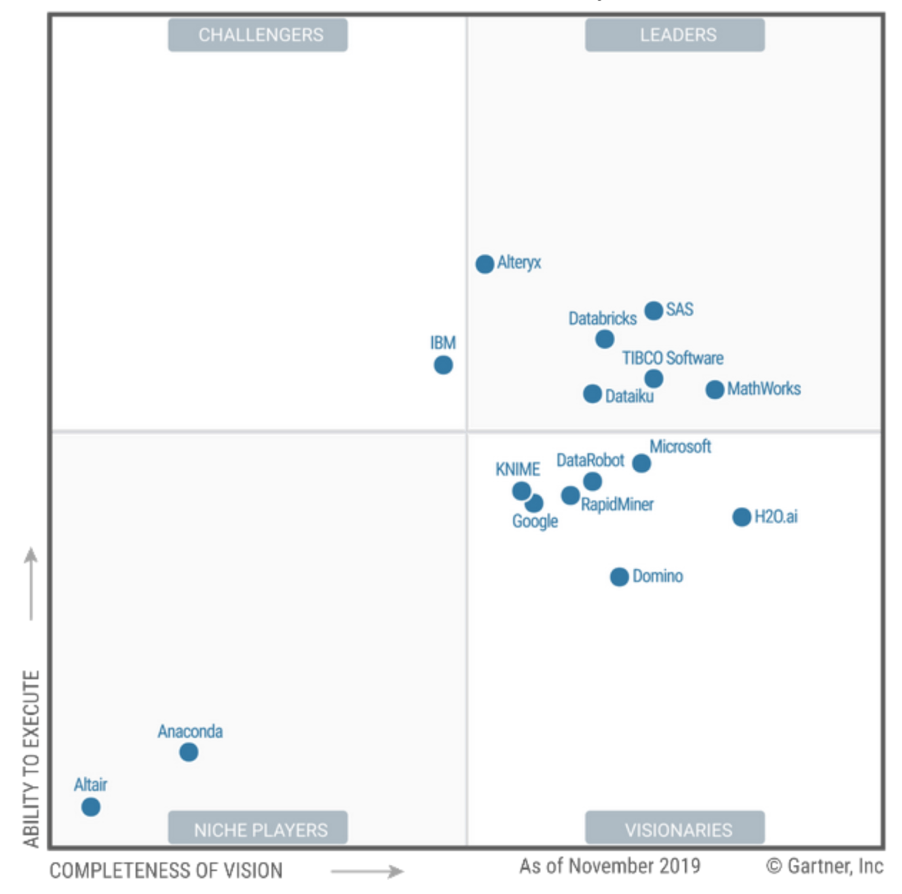
- “Um líder pode não ser a melhor escolha” - O líder de mercado não é necessariamente o que você precisa. Muito urgente! Como consequência da falta de um cliente funcional, procuram sempre a solução “melhor” e não a “adequada”.
- A operacionalização do modelo é abreviada como MOPs. E pugs são difíceis para todos! - (tema legal do pug faz o modelo funcionar).
- O ambiente de notebook é um conceito importante onde código, comentários, dados e resultados são reunidos. Isso é muito claro, promissor e pode reduzir significativamente a quantidade de código de IU.
- «Rooted in OpenSource» — – .
- «Citizen Data Scientists» — , , , . .
- «Democratise» — “ ”. «democratise the data» «free the data», . «Democratise» — long tail . — !
- «Exploratory Data Analysis – EDA» — . . . , . ,
- "Reprodutibilidade" - a preservação máxima de todos os parâmetros do ambiente, entradas e saídas, para que você possa repetir o experimento uma vez realizado. O termo mais importante para um ambiente de teste experimental!
Então:
Alteryx
A interface legal é apenas um brinquedo. A escalabilidade, é claro, é um pouco restrita. Assim, a comunidade Citizen de engenheiros em torno da mesma com tsatski para jogar. Analytics tem tudo em uma garrafa. Fez-me lembrar do Coscad Spectral Correlation Análise de Dados suíte que foi programado na década de 90.
Anaconda
Uma comunidade em torno de especialistas em Python e R. O código aberto é grande, respectivamente. Descobriu-se que meus colegas estão constantemente usando. Eu não sabia.
DataBricks
Consiste em três projetos de código aberto - os desenvolvedores do Spark levantaram muito dinheiro desde 2013. Tenho que ler o wiki diretamente:
“Em setembro de 2013, a Databricks anunciou que havia levantado US $ 13,9 milhões da Andreessen Horowitz. A empresa levantou $ 33 milhões adicionais em 2014, $ 60 milhões em 2016, $ 140 milhões em 2017, $ 250 milhões em 2019 (fevereiro) e $ 400 milhões em 2019 (outubro) ”!!!Algumas ótimas pessoas que Spark viu. Não estou familiarizado, desculpe!
E os projetos são:
- Delta Lake - ACID on Spark foi lançado recentemente (o que sonhamos com Elasticsearch) - ele o transforma em um banco de dados: um esquema rígido, ACID, auditoria, versões ...
- ML Flow - rastreamento, embalagem, gerenciamento e armazenamento de modelos.
- Koalas - Pandas DataFrame API no Spark - Pandas - Python API para trabalhar com tabelas e dados em geral.
Você pode ver sobre o Spark, que de repente não sabe ou esqueceu: link . Vidosiki olhou com exemplos de pica-paus de consultoria um pouco chatos, mas detalhados: DataBricks para Data Science ( link ) e para Data Engineering ( link ).
Resumindo, o Databricks puxa o Spark. Quem quiser usar o Spark normalmente na nuvem pega DataBricks sem hesitar, como pretendia :) O Spark é o principal diferencial aqui.
Eu descobri que o Spark Streaming não é um falso realtime ou microbatching. E se você precisa de tempo real real, é no Apache STORM. Ainda assim, todo mundo diz e escreve que o Spark é mais legal do que o MapReduce. O slogan é este.
DATAIKU
Coisa legal de ponta a ponta. Há muita publicidade. Não entende como ele difere do Alteryx?
DataRobot
A Paxata para preparar dados é legal é uma empresa separada que foi comprada pela Data Robots em dezembro de 2019. Levantou 20 MUSD e vendeu. Tudo em 7 anos.
Preparando dados em Paxata, não Excel - veja aqui: link .
Existem spoofs automáticos e propostas de junção entre dois conjuntos de dados. Uma grande coisa - para classificar os dados, ainda mais ênfase nas informações de texto ( link ).
O Catálogo de Dados é um ótimo catálogo de conjuntos de dados "ativos" de que ninguém precisa.
Também interessante é como os diretórios são formados no Paxata ( link ).
«According to analyst firm Ovum, the software is made possible through advances in predictive analytics, machine learning and the NoSQL data caching methodology.[15] The software uses semantic algorithms to understand the meaning of a data table's columns and pattern recognition algorithms to find potential duplicates in a data-set.[15][7] It also uses indexing, text pattern recognition and other technologies traditionally found in social media and search software.»
O produto principal do Data Robot está aqui . Seu slogan é de modelo a aplicativo corporativo! Consultoria descoberta para a indústria do petróleo em conexão com a crise, mas muito banal e desinteressante: link . Assistiu a seus vídeos em Mops ou MLops ( link ). Este é um Frankenstein composto de 6-7 aquisições de vários produtos.
Claro, fica claro que uma grande equipe de cientistas de dados deve ter esse ambiente para trabalhar com modelos, caso contrário, eles produzirão muitos deles e nunca implantarão nada. E em nossa realidade de upstream de óleo e gás - um modelo poderia ser criado com sucesso e isso já é um grande progresso!
O próprio processo lembrava muito o trabalho de projetar sistemas em geologia-geofísica, por exemplo, Petrel... Todo mundo faz e modifica modelos. Colete dados no modelo. Então fizemos um modelo de referência e o colocamos em produção! Existem muitas semelhanças entre, digamos, um modelo geológico e um modelo de ML.
Dominó
Ênfase em plataforma aberta e colaboração. Os usuários comerciais são permitidos gratuitamente. O Data Lab deles se assemelha muito a um sharepoint. (E a partir do nome dá fortemente IBM). Todos os experimentos estão vinculados ao conjunto de dados original. Como é familiar :) Como na nossa prática - alguns dados foram arrastados para o modelo, depois foram limpos e colocados em ordem no modelo, e tudo isso já está lá no modelo e você não consegue encontrar as extremidades nos dados iniciais.
Domino tem virtualização de infraestrutura legal. Montei a máquina com tantos núcleos por segundo e fui contar. Como isso foi feito não está totalmente claro de imediato. Docker em todos os lugares. Muita liberdade! Todos os espaços de trabalho das versões mais recentes podem ser conectados. Execute experimentos em paralelo. Rastreamento e seleção dos bem-sucedidos.
O mesmo que DataRobot - os resultados são publicados para usuários de negócios na forma de aplicativos. Para “stakeholders” especialmente talentosos. E o uso real dos modelos também é monitorado. Tudo pelos Pugs!
Eu não entendia completamente como modelos complexos entram em produção. Alguma API é fornecida para alimentá-los com dados e obter resultados.
H2O
O Driveless AI é um sistema muito compacto e direto para ML Supervisionado. Tudo em uma caixa. Não está claro sobre o back-end imediatamente.
O modelo é empacotado automaticamente em um servidor REST ou aplicativo Java. Esta é uma ótima idéia. Muito foi feito para interpretar e explicar. Interpretação e explicação dos resultados do trabalho do modelo (O que, em sua essência, não deve ser explicado, senão uma pessoa pode calcular o mesmo?).
Pela primeira vez, um estudo de caso sobre dados não estruturados e PNL é considerado em detalhes . Imagem arquitetônica de alta qualidade. No geral gostei das fotos.
Existe uma grande estrutura H2O de código aberto que não é totalmente clara (um conjunto de algoritmos / bibliotecas?). Laptop visual próprio sem programação como Júpiter ( link) Também li sobre os modelos Pojo e Mojo - H2O embrulhados na realidade. O primeiro é na testa, o segundo é com otimização. H20 são os únicos (!) Para quem o Gartner escreveu analítica de texto e PNL em seus pontos fortes, bem como em seus esforços de explicabilidade. É muito importante!
Ibid: Alto desempenho, otimização e padrão da indústria para integração de ferro e nuvem.
E é lógico em fraqueza - Driverles AI é fraco e estreito em comparação com seu próprio código aberto. A preparação de dados é manca em comparação com a mesma Paxata! E ignore os dados industriais - stream, gráfico, geo. Bem, nem tudo pode estar certo.
KNIME
Gostei de 6 casos de negócios muito específicos e interessantes na página inicial. OpenSource forte.
O Gartner passou de líderes a visionários. Ganhar pouco dinheiro é um bom sinal para os usuários, visto que o Leader nem sempre é a melhor escolha.
A palavra-chave é como em H2O - aumentada, significa ajudar os cientistas de dados cidadãos pobres. Esta é a primeira vez que alguém é repreendido por seu desempenho em uma análise! Interessante? Ou seja, há tanto poder de computação que o desempenho não pode ser um problema sistêmico? O Gartner tem um artigo separado sobre essa palavra “Aumentado” , que eu não consegui acessar.
E KNIME parece ser o primeiro não americano na revisão! (E nossos designers realmente gostaram de sua landing page. Pessoas estranhas.
MathWorks
MatLab é um velho amigo honorário conhecido por todos! Caixas de ferramentas para todas as áreas da vida e situações. Algo muito diferente. Na verdade, muita, muita, muita matemática para todas as ocasiões em geral!
Produto complementar Simulink para projeto de sistemas. Eu cavei nas caixas de ferramentas para Digital Twins - Eu não entendo nada sobre isso, mas um Muito tem sido escrito aqui. Para a indústria do petróleo . Em geral, este é um produto fundamentalmente diferente das profundezas da matemática e da engenharia. Para selecionar kits de ferramentas matemáticas específicos. De acordo com o Gartner, todos eles têm problemas como engenheiros inteligentes - sem colaboração - cada um remexe em seu modelo, sem democracia, sem explorabilidade.
RapidMiner
Eu encontrei e ouvi muito antes (junto com o Matlab) no contexto de um bom código aberto. Enterrado um pouco no TurboPrep, como sempre. Estou interessado em como obter dados limpos de dados sujos.
Novamente, você pode ver que as pessoas são boas em materiais de marketing de 2018 e péssimos falantes de inglês na demonstração de recursos.
E pessoas de Dortmund desde 2001 com um forte passado alemão)

Não entendi no site o que exatamente está disponível no código aberto - você precisa se aprofundar. Bons vídeos sobre implantação e conceitos de AutoML.
Também não há nada de especial no backend do RapidMiner Server. Provavelmente será compacto e funcionará bem no local, pronto para uso. Empacotado em Docker. Ambiente compartilhado apenas no servidor RapidMiner. E há Radoop, dados de hadup, contando rimas do Spark no fluxo de trabalho do Studio.
Empurrou-os para baixo conforme esperado pelos jovens vendedores "vendedores de palitos listrados". O Gartner, no entanto, prevê o sucesso futuro no espaço empresarial. Você pode levantar dinheiro lá. Os alemães sabem quão sagrado e sagrado :) Não mencione SAP !!!
Eles fazem muito pelos Cidadãos! Mas na página você pode ver como o Gartner diz que eles têm dificuldade em inovar em vendas e não estão lutando por uma cobertura ampla, mas por lucratividade.
Deixou SAS e Tibco fornecedores típicos de BI para mim ... E ambos estão no topo, o que confirma minha crença de que o DataScience normal cresce logicamente a
partir do BI, e não das nuvens e da infraestrutura do Hadoop. De negócios, ou seja, não de TI. Como na Gazpromneft, por exemplo: link , um ambiente DSML maduro surge de uma prática sólida de BI. Mas talvez ela tenha um preconceito e preconceito sobre MDM e outras coisas, quem sabe.
SAS
Não há muito a dizer. Apenas coisas óbvias.
TIBCO
A estratégia é lida na lista de compras em uma página Wiki de uma página inteira. Sim, longa história, mas 28 !!! Charles. subornei BI Spotfire (2007) na minha juventude techno. E também relatórios de Jaspersoft (2014), então até três fornecedores de análise preditiva Insightful (S-plus) (2008), Statistica (2017) e Alpine Data (2017), processamento de eventos e streaming Streambase System (2013), MDM Orchestra Networks (2018 ) e a plataforma in-memory Snappy Data (2019).
Oi Frankie!
