Ao fazer isso, eles esquecem que os padrões são apenas soluções possíveis. Os padrões, como quaisquer princípios, têm limites de aplicabilidade e é importante entendê-los. A estrada para o inferno é pavimentada com a adesão cega e religiosa até mesmo a palavras autorizadas.
E a presença dos padrões necessários na estrutura não garante sua aplicação correta e consciente.

O brilho e a pobreza do Active Record
Vejamos o padrão Active Record como um antipadrão, que algumas linguagens de programação e frameworks tentam evitar de todas as maneiras possíveis.
A essência do Active Record é simples: armazenamos lógica de negócios com lógica de armazenamento de entidade. Em outras palavras, para simplificar, cada tabela no banco de dados corresponde a uma classe de entidade junto com um comportamento.
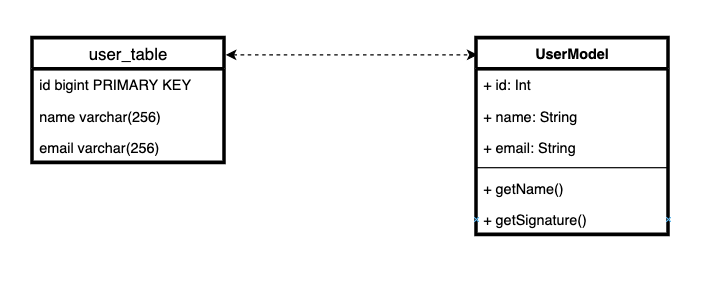
Há uma opinião bastante forte de que combinar lógica de negócios com lógica de armazenamento em uma classe é um padrão muito ruim e inutilizável. Isso viola o princípio da responsabilidade exclusiva. E por esta razão Django ORM é ruim por design.
Na verdade, pode não ser muito bom combinar lógica de armazenamento e lógica de domínio na mesma classe.
Vamos pegar os modelos de usuário e perfil, por exemplo. Este é um padrão bastante comum. Há uma placa principal e outra adicional, que armazena nem sempre dados obrigatórios, mas às vezes necessários.

Acontece que a entidade do domínio “usuário” agora está armazenada em duas tabelas, e no código temos duas classes. E toda vez que fazemos algumas correções diretamente no
user.profile, precisamos nos lembrar que este é um modelo separado e que fizemos alterações nele. E salve-o separadamente.
def create(self, validated_data):
# create user
user = User.objects.create(
url = validated_data['url'],
email = validated_data['email'],
# etc ...
)
profile_data = validated_data.pop('profile')
# create profile
profile = Profile.objects.create(
user = user
first_name = profile_data['first_name'],
last_name = profile_data['last_name'],
# etc...
)
return user
Para obter uma lista de usuários, é imperativo pensar se o atributo será obtido desses usuários
profile, a fim de selecionar imediatamente dois sinais com uma junção e não colocá-los SELECT N+1em um loop.
user = User.objects.get(email='example@examplemail.com')
user.userprofile.company_name
user.userprofile.country
As coisas ficam ainda piores se, dentro da arquitetura de microsserviço, parte dos dados do usuário são armazenados em outro serviço - por exemplo, funções e direitos no LDAP.
Ao mesmo tempo, é claro, não quero que usuários externos da API se importem com isso de alguma forma. Existe um recurso REST
/users/{user_id}e gostaria de trabalhar com ele sem pensar em como os dados são armazenados nele. Se eles estiverem armazenados em fontes diferentes, será mais difícil alterar o usuário ou obter uma lista de dados.
De modo geral, ORM! = Modelo de Domínio!

E quanto mais o mundo real difere da suposição de “uma tabela no banco de dados - uma entidade do domínio”, mais problemas com o padrão Active Record.
Acontece que toda vez que você escreve a lógica de negócios, deve se lembrar de como a essência do domínio é armazenada.
Os métodos ORM são o nível mais baixo de abstração. Eles não suportam quaisquer limitações da área de assunto, o que significa que dão a oportunidade de cometer erros. Eles também escondem do usuário quais consultas são realmente feitas no banco de dados, o que leva a consultas longas e ineficientes. O clássico, quando as consultas são feitas em loops, em vez de uma junção ou filtro.
E o que mais, além da construção de consultas (a capacidade de construir consultas), o ORM nos oferece? Deixa pra lá. Capacidade de mover para um novo banco de dados? E quem em sã consciência e memória firme mudou para um novo banco de dados e ORM o ajudou nisso? Se você perceber isso não como uma tentativa de mapear o modelo de domínio (!) No banco de dados, mas como uma biblioteca simples que permite fazer consultas ao banco de dados de forma conveniente, então tudo se encaixa.
E mesmo que seja usado nos nomes das classes
Model, e nos nomes dos arquivos - models, eles não se tornam modelos. Não se iluda. É apenas uma descrição dos rótulos Eles não vão ajudar a encapsular nada.
Mas se tudo está tão ruim, o que fazer? Padrões de arquiteturas em camadas vêm ao resgate.
Arquitetura em camadas contra-ataca!
A ideia por trás das arquiteturas em camadas é simples: separamos a lógica de negócios, a lógica de armazenamento e a lógica de uso.
Parece completamente lógico separar o armazenamento da mudança de estado. Essa. faça uma camada separada que pode receber e salvar dados do armazenamento "abstrato".
Deixamos toda a lógica de armazenamento, por exemplo, na classe de armazenamento
Repository. E os controladores (ou camada de serviço) usam-no apenas para obter e salvar entidades. Então poderemos mudar a lógica de armazenar e receber como quisermos, e este será um lugar! E quando escrevemos o código do cliente, podemos ter certeza de que não esquecemos de mais um lugar no qual precisamos salvar ou de onde devemos retirá-lo, e não repetimos o mesmo código um monte de vezes.
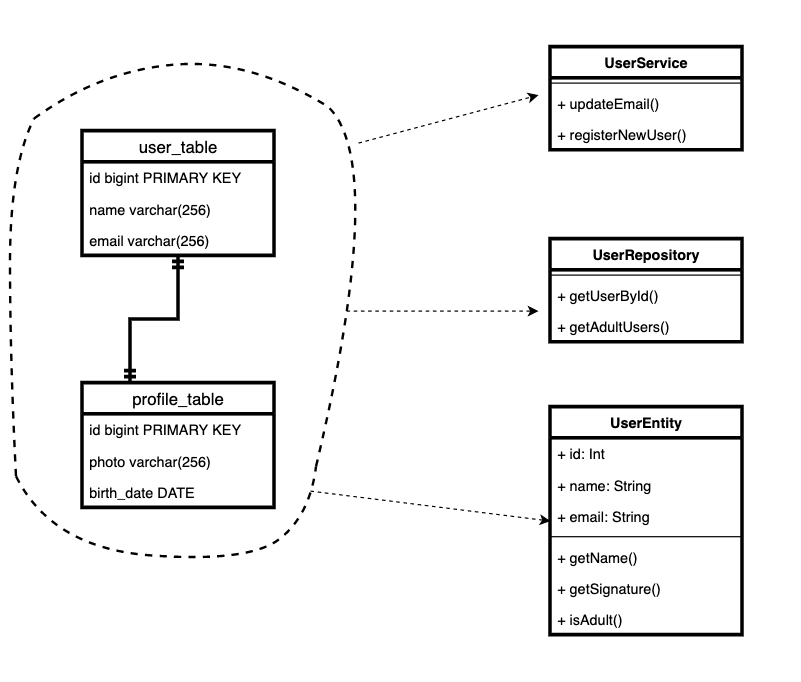
Não importa para nós se a entidade consiste em registros em tabelas ou microsserviços diferentes. Ou se entidades com comportamento diferente dependendo do tipo são armazenadas em uma tabela.
Mas essa divisão de responsabilidades não é gratuita . Deve ser entendido que camadas adicionais de abstração são criadas para evitar mudanças de código “ruins”. Obviamente, ele
Repositoryesconde o fato de que o objeto está armazenado no banco de dados SQL, portanto, devemos tentar não deixar o SQLismo sair dos limites Repository. E todas as solicitações, mesmo as mais simples e óbvias, terão que ser arrastadas pela camada de armazenamento.
Por exemplo, se for necessário obter um escritório por nome e departamento, você terá que escrever assim:
#
interface OfficeRepository: CrudRepository<OfficeEntity, Long> {
@Query("select o from OfficeEntity o " +
"where o.number = :office and o.branch.number = :branch")
fun getOffice(@Param("branch") branch: String,
@Param("office") office: String): OfficeEntity?
...
E no caso do Active Record, tudo é muito mais simples:
Office.objects.get(name=’Name’, branch=’Branch’)
Não é tão simples, mesmo que a entidade comercial esteja realmente armazenada de uma forma não trivial (em várias tabelas, em diferentes serviços, etc.). Para implementar isso bem (e corretamente) - para o qual este padrão foi criado - na maioria das vezes você tem que usar padrões como agregados, Unidade de trabalho e mapeadores de dados.
É difícil selecionar corretamente um agregado, observar corretamente todas as restrições impostas a ele e fazer o mapeamento dos dados corretamente. E apenas um desenvolvedor muito bom pode lidar com essa tarefa. Aquele que, no caso do Active Record, poderia fazer tudo "certo".
O que acontece com os desenvolvedores regulares? Aqueles que conhecem todos os padrões e estão firmemente convencidos de que se usarem uma arquitetura em camadas, seu código se tornará automaticamente sustentável e bom, ao contrário do Active Record. E eles criam repositórios CRUD para cada tabela. E eles funcionam no conceito de
uma placa - um repositório - uma entidade.
Não:
um repositório - um objeto de domínio.

Eles também acreditam cegamente que, se uma palavra for usada em uma classeEntity, ela reflete o modelo de domínio. Como uma palavraModelno Active Record.
O resultado é uma camada de armazenamento mais complexa e menos flexível que possui todas as propriedades negativas dos mapeadores Active Record e Repositório / Dados.
Mas a arquitetura em camadas não termina aí. A camada de serviço também costuma ser diferenciada.
A implementação correta de tal camada de serviço também é uma tarefa difícil. E, por exemplo, desenvolvedores inexperientes criam uma camada de serviço, que é um serviço - proxy para repositórios ou ORM (DAO). Essa. os serviços são escritos de forma que não encapsulem a lógica de negócios:
#
@Service
class AccountServiceImpl(val accountDaoService: AccountDaoService) : AccountService {
override fun saveAccount(account: Account) =
accountDaoService.saveAccount(convertClass(account, AccountEntity::class.java))
override fun deleteAccount(id: Long) =
accountDaoService.deleteAccount(id)
E há uma combinação de desvantagens tanto do Active Record quanto da camada de serviço.
Como resultado, em estruturas Java em camadas e código escrito por jovens e inexperientes amantes de padrões, o número de abstrações por unidade de lógica de negócios começa a exceder todos os limites razoáveis.
Existem camadas, mas são todas triviais e são apenas camadas para chamar a próxima camada.
A presença de padrões OOP no framework não garante sua aplicação correta e adequada.
Não há bala de prata
É bastante claro que não existe bala de prata. Soluções complexas são para problemas complexos e soluções simples são para problemas simples.
E não existem padrões bons e ruins. Em uma situação, o Active Record é bom, em outras, a arquitetura em camadas. E sim, para a grande maioria dos aplicativos de pequeno e médio porte, o Active Record funciona razoavelmente bem. E para a grande maioria dos aplicativos de pequeno e médio porte, a arquitetura em camadas (a la Spring) tem desempenho pior. E exatamente o oposto para aplicativos complexos de lógica e serviços da web.
Quanto mais simples o aplicativo ou serviço, menos camadas de abstração você precisa.
Em microsserviços, onde não há muita lógica de negócios, geralmente é inútil usar arquiteturas em camadas. Scripts transacionais comuns - scripts no controlador - podem ser perfeitamente adequados para a tarefa em questão.
Na verdade, um bom desenvolvedor difere de um mau porque não apenas conhece os padrões, mas também entende quando aplicá-los.