int main()
{
int n = 500000000;
int *a = new int[n + 1];
for (int i = 0; i <= n; i++)
a[i] = i;
for (int i = 2; i * i <= n; i++)
{
if (a[i]) {
for (int j = i*i; j <= n; j += i) {
a[j] = 0;
}
}
}
delete[] a;
return 0;
}É um aplicativo simples, especialmente para experimentos, que busca números primos usando a peneira de Eratóstenes . Vamos rodar a solução 20 vezes e calcular o tempo do usuário de cada execução.
Descrição da bancada de teste
i7-8750H @ 2,20
32 RAM
O:
Ubuntu 18.04.4
5.3.0-53-generic
32 RAM
O:
Ubuntu 18.04.4
5.3.0-53-generic
Dispersão do tempo de execução antes das otimizações:
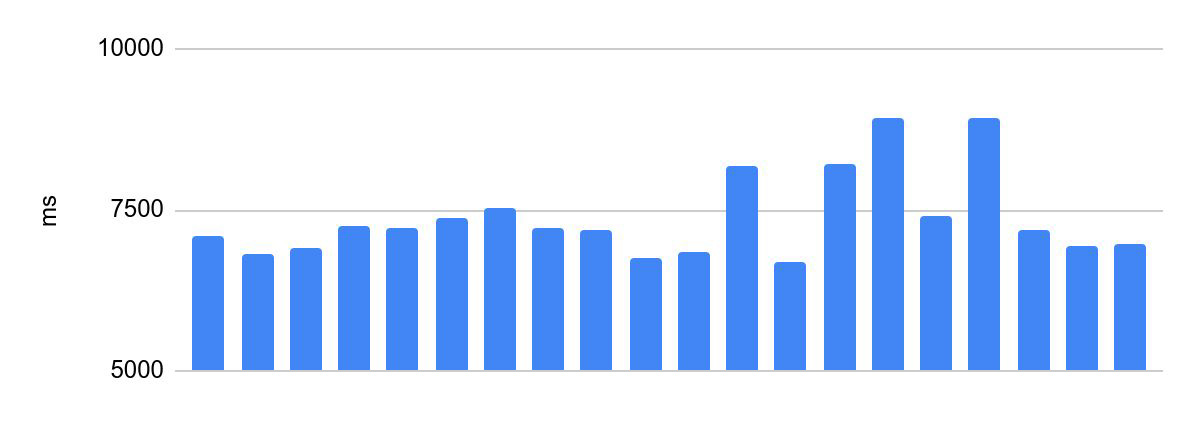
A diferença entre a execução mais rápida e a mais lenta é de 2230 ms.
Isso é inaceitável para a programação de Olimpíadas. O tempo de execução do código do participante é um dos critérios para o sucesso da sua solução e uma das condições do concurso, a distribuição dos prémios depende disso. Portanto, há um requisito importante para tais sistemas - o mesmo tempo de verificação para o mesmo código. A seguir, chamaremos isso de consistência da execução do código.
Vamos tentar alinhar o tempo de execução.
Isolamento do núcleo
Vamos começar com o óbvio. Os processos competem por núcleos e você precisa isolar de alguma forma o núcleo para a execução da solução. Além disso, com o Hyper Threading ativado, o sistema operacional define um núcleo do processador físico como dois núcleos lógicos separados. Para um isolamento justo do núcleo, precisamos desabilitar o Hyper Threading. Isso pode ser feito nas configurações do BIOS.
O kernel Linux pronto para uso oferece suporte a um sinalizador de inicialização para isolar os kernels isolcpus. Adicione este sinalizador a GRUB_CMDLINE_LINUX_DEFAULT nas configurações do grub: / etc / default / grub. Por exemplo:
GRUB_CMDLINE_LINUX_DEFAULT="... isolcpus=0,1"
Execute update-grub e reinicie o sistema.
Tudo parece conforme o esperado - os primeiros dois kernels não são usados pelo sistema:

Vamos começar com um kernel isolado. A configuração CPU Affinity permite que você vincule um processo a um núcleo específico. Existem várias maneiras de fazer isso. Por exemplo, vamos executar a solução em um contêiner porto (o kernel é selecionado usando o argumento cpu_set):
portoctl exec test command='sudo stress.sh' cpu_set=0Offtop: usamos QEMU-KVM para executar soluções em produção. O contentor do porto é utilizado ao longo deste artigo para facilitar a sua visualização.
Lançamento com um kernel dedicado à solução, sem carga nos kernels vizinhos:

A diferença é de 375 ms. Melhorou, mas ainda é muito.
Desempenho de Tyunim
Vamos tentar nosso teste de estresse. Qual? Nossa tarefa é carregar todos os núcleos com vários threads. Isto pode ser feito de várias maneiras:
- Escreva um aplicativo simples que criará muitos threads e começará a contar algo em cada um deles.
- :
cat /dev/zero | pbzip2 -c > /dev/null. pbzip2 — bzip2. - stress
stress --cpu 12.
Lançamento com um núcleo dedicado à solução, com carga nos núcleos vizinhos:

A diferença é de 1354 ms: um segundo a mais do que sem carga. Obviamente, a carga afetou o tempo de execução, apesar de estarmos rodando em um kernel isolado. Percebe-se que em determinado momento o tempo de execução diminuiu. À primeira vista, isso é contra-intuitivo: com o aumento da carga, o desempenho também aumenta.
Na produção, esse comportamento (quando o tempo de execução começa a flutuar sob carga) pode ser muito doloroso de disparar. Qual é a carga neste caso? Um fluxo de decisões dos participantes, mais frequentemente em grandes competições e olimpíadas.
A razão é que o Intel Turbo Boost é ativado sob carga - uma tecnologia para aumentar a frequência. Desative-o. Para o meu stand, também desliguei o SpeedStep... Para o processador AMD, Turbo Core Cool'n'Quiet deve ser desligado. Tudo isso é feito na BIOS, a ideia principal é desabilitar o que controla automaticamente a frequência do processador.
Executando em um núcleo isolado com Turbo Boost desabilitado e

carregando em núcleos vizinhos: Parece bom, mas a diferença ainda é de 252ms. E isso ainda é muito.
Offtop: observe como o tempo médio de execução caiu cerca de 25%. Na vida cotidiana, as tecnologias deficientes são boas.
Nós nos livramos da competição por núcleos, estabilizamos a frequência do núcleo - agora nada os afeta. Então, de onde vem a diferença?
NUMA
Acesso à memória não uniforme ou Arquitetura de memória não uniforme, "arquitetura de memória não uniforme". Em sistemas NUMA (isto é, convencionalmente, em qualquer computador multiprocessador moderno), cada processador possui memória local, que é considerada parte do total. Cada processador pode acessar sua memória local e a memória local de outros processadores (memória remota). O desnível é que o acesso à memória local é notavelmente mais rápido.
O tempo de atuação "anda" justamente por causa de tais desníveis. Vamos consertar ligando nossa execução a um nó específico numa. Para fazer isso, adicione um nó à configuração do contêiner porto:
portoctl exec test command='stress.sh' cpu_set="node 0" cpu_set=0Executando em um núcleo isolado com Turbo Boost desabilitado, configuração NUMA e carga em núcleos vizinhos:
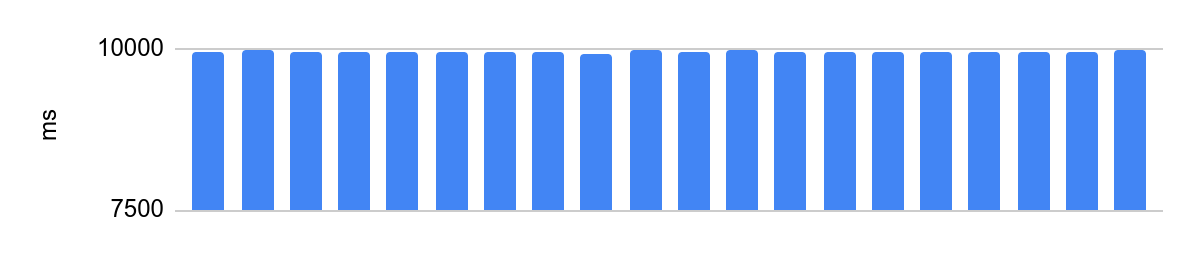
A diferença é 48 ms, e o tempo médio de execução depois que desabilitamos as otimizações do processador é de 10 segundos. 48ms a 10s é equivalente a 0,5% de erro, muito bom.
Spoiler importante
Um pouco mais sobre isolcpus
O sinalizador isolcpus tem um problema: alguns threads do sistema ainda podem ser agendados para um kernel isolado.
Portanto, na produção, usamos um kernel corrigido com funcionalidade estendida deste sinalizador. Assim, selecionamos o kernel, levando em consideração o flag, no momento do agendamento das threads.
, 3.18. kthread_run, . CPU, isolcpus.
— slave_cpus , .
— slave_cpus , .
Planos para o futuro
Pools
Se uma máquina decisiva for mais poderosa do que a outra, nenhuma quantidade de ajustes de isolamento de núcleo ajudará - como resultado, ainda teremos uma grande diferença no tempo de execução. Portanto, você precisa pensar sobre ambientes heterogêneos. Até agora, simplesmente não suportávamos a heterogeneidade - toda a frota de máquinas de decisão é equipada com o mesmo hardware. Mas, em um futuro próximo, começaremos a dividir hardware diferente em pools homogêneos, e cada competição será realizada dentro do mesmo pool com o mesmo hardware.
Mudança para a nuvem
Um novo desafio para o sistema será a necessidade de lançar no Yandex.Cloud. Pelos padrões de hoje, os servidores de ferro não são confiáveis, uma mudança é necessária, mas é importante manter a consistência na execução dos pacotes. Aqui, as possibilidades técnicas ainda estão sendo investigadas. Existe uma ideia de que, em casos extremos, as máquinas em nuvem podem executar soluções que não requerem um tempo de execução estrito. Assim, vamos reduzir a carga nas máquinas de ferro e elas só vão lidar com soluções que apenas requeiram consistência. Existe outra opção: primeiro verifique o pacote na nuvem e, caso não tenha cumprido o limite de tempo, verifique novamente no hardware real.
Coletando estatísticas
Mesmo depois de todos os ajustes, os processadores serão inevitavelmente limitados. Para reduzir o efeito negativo, vamos executar as soluções em paralelo, comparar os resultados e, se forem diferentes, lançar uma nova verificação. Além disso, se uma das máquinas decisivas está constantemente se degradando, isso é uma desculpa para colocá-la fora de serviço e resolver os motivos.
conclusões
O concurso tem uma peculiaridade - pode parecer que tudo se resume a simplesmente executar o código e obter o resultado. Neste artigo, revelei apenas um pequeno aspecto desse processo. Existe algo assim em cada camada do serviço.