Atributos com meta informação
Título (atributo de título)
O título descreve resumidamente a essência da regra. Este campo de texto tem até 256 caracteres. Aqui você deve dar a descrição mais curta e ampla. Siga estas diretrizes:
- Não use construções como "Detecta ..." como título. E sem isso, é claro que a regra detecta algo.
- Use títulos extensos com até 50 caracteres.
- Escreva quaisquer explicações e comentários importantes no campo de descrição (iremos considerá-lo mais adiante).
Descrição detalhada e explicações adicionais para a regra (atributo de descrição)
Se o título contém uma breve descrição da regra para uma compreensão geral de seu propósito, então no campo de descrição você pode especificar todas as nuances e características que o autor coloca nesta regra. Ele também descreve resumidamente o ataque que se propõe a ser detectado usando esta regra. O comprimento máximo desse campo é 65.535 caracteres.
Identificador único da regra e identificadores de regras relacionadas (id, relativo)
Como os valores específicos dos atributos de título e descrição podem ser arbitrários, incluindo os mesmos para duas regras diferentes (nunca faça isso), eles não são adequados para identificar uma regra de maneira exclusiva. É necessário um identificador mais formal e exclusivo. O identificador exclusivo universal (UUID) é usado na grande maioria dos produtos para resolver esse problema. Os autores da Sigma aconselham os desenvolvedores de regras a seguir o mesmo caminho, no entanto, qualquer esquema de geração de identificador pode ser usado para regras privadas. No repositório público, o referido UUID é selecionado como o esquema para a criação de identificadores. Seguimos a mesma abordagem na regra de exemplo na primeira parte do artigo. Se você quiser publicar sua regra no futuro ou enviar uma solicitação para adicioná-la ao repositório oficial,então, recomendamos que você siga o mesmo esquema para criar um identificador de regra.
O identificador exclusivo pode ser gerado de diferentes maneiras. No Windows, a maneira mais fácil é executar o seguinte código do PowerShell:
PS C:\> "id: $(New-Guid)"
id: b2ddd389-f676-4ac4-845a-e00781a48e5fEm um sistema operacional baseado em kernel Linux, você pode usar o utilitário uuidgen:
$ echo “id: `uuidgen`”
id: b2ddd389-f676-4ac4-845a-e00781a48e5fSe você fizer alterações significativas em uma regra, seu identificador deve ser alterado. Situações nas quais criar um novo identificador:
- mudando a lógica da regra;
- herança de uma regra de uma existente, preservando a original (também é verdadeiro para a situação de melhoria de regra);
- regras de fusão.
Para os casos de herança e fusão de regras, existe um identificador especial relacionado com quatro valores possíveis do tipo (o atributo type).
Vamos considerar situações hipotéticas nas quais podemos achar útil usar o identificador relacionado. Para maior clareza, em vez de identificadores longos no formato UUID, vamos simplesmente escrever X, Y, Z.
No primeiro caso, a nova regra (id: X) é derivada da existente (id: Y). Isso pode acontecer se tivermos aprimorado a lógica de trabalho em uma nova regra, mas por algum motivo quisermos manter a regra antiga. Portanto, nossa regra tem uma regra pai que é salva e pode ser usada no futuro:

O segundo caso é semelhante ao primeiro, exceto por um fato: a regra antiga não é preservada. Ou seja, reescrevemos a regra radicalmente, e foi necessária a atribuição de um novo identificador, e o antigo está obsoleto (obsoleto) e não será mais usado. Então, tínhamos uma regra (id: Y) que reescrevemos e decidimos que não precisamos mais dela. A nova regra recebeu um identificador (id: X). Na regra Sigma, uma situação semelhante será semelhante a esta:

No terceiro caso, considere uma situação em que uma nova regra apareceu como resultado da fusão de duas ou mais regras existentes. A nova regra (id: X) é o resultado da fusão de duas regras (id: Y, Z). É importante observar que ambas as regras pai que estavam envolvidas na mesclagem são preservadas e podem ser usadas posteriormente. Em uma regra Sigma, uma situação semelhante pode ser parecida com esta:

Embora a ordem das regras não seja definida durante a mesclagem, nos comentários nós as numeramos para maior clareza.
O quarto tipo é renomear. Como o nome sugere, esse tipo de associação entre identificadores é aplicado ao renomear uma regra antiga. Na verdade, esse tipo não é usado na prática. Como exemplo de uso, os autores citam um caso de alteração do esquema de criação de identificadores (lembre-se que UUID não é o único esquema de nomenclatura possível).
Status de regra pronta (atributo de status)
De acordo com a especificação, uma regra pode estar em um dos três estados:
- estável - a regra pode ser usada em uma infraestrutura real para detectar ataques, nenhuma modificação é necessária;
- teste - a regra é quase estável, mas um pequeno ajuste é necessário;
- experimental - tal regra pode gerar um grande número de falsos positivos, mas ao mesmo tempo revela eventos interessantes.
Normalmente, antes de executar uma regra em uma infraestrutura real, a regra tem o status experimental, uma vez que ainda não se sabe exatamente com que freqüência irá gerar erros. Além disso, após vários meses de teste, se a regra for bem escrita e não gerar erros (ou se houver erros insignificantes), ela será transferida para a categoria estável. Caso contrário, as correções são feitas e verificadas novamente. Não existem regras com o status de teste no repositório oficial Sigma.
A licença sob a qual a regra é distribuída (o atributo de licença)
A licença sob a qual a regra é distribuída. Este campo veio do mundo do software livre. Raramente é especificado, mas, se especificado, deve estar em conformidade com a especificação SPDX ID.
Criadores de regras (atributo de autor)
Este campo lista todos os autores da regra. É considerado uma boa forma indicar não apenas a pessoa que escreveu a regra em si, mas também o autor da ideia original de detecção.
Links para estudos que ajudaram a desenvolver a regra (atributo de referências)
Ao escrever regras do Sigma, é comum incluir links para artigos originais, tweets e pesquisas que ajudaram ou inspiraram a criação da regra. Além de expressar respeito pelo trabalho de outra pessoa, esses links posteriormente ajudam a entender como a regra funciona.
Campos de eventos que são úteis para mostrar análises quando uma regra é acionada (atributo de campos)
Como o autor da regra tem um conhecimento profundo do algoritmo de ataque e dos eventos que são gerados durante sua execução, ele pode selecionar uma lista de campos de eventos que ajudarão o operador do SOC ou outro funcionário da equipe de segurança da informação a entender o incidente.
Casos de falsos positivos da regra (atributo falsepositives)
O campo falsepositives é bastante incomum para regras de detecção. Não afeta o curso da validação do evento de forma alguma, mas faz duas coisas úteis:
- Ajude o usuário a determinar se um determinado gatilho de regra é um erro.
- Lembre o desenvolvedor da regra mais uma vez que sua regra pode ser acionada falsamente. Esses pensamentos podem ajudar o desenvolvedor a escrever uma regra mais precisa.
Várias tags e tags (atributo de tags)
Normalmente, este campo é usado para tags MITER ATT & CK e CAR. É altamente recomendável que você classifique sua regra imediatamente, uma vez que tal marcação permite integrar as regras Sigma com outros projetos de segurança da informação. Porém, o formato não limita os autores das regras apenas a esses rótulos, você pode colocar qualquer um.
Coleções de regras
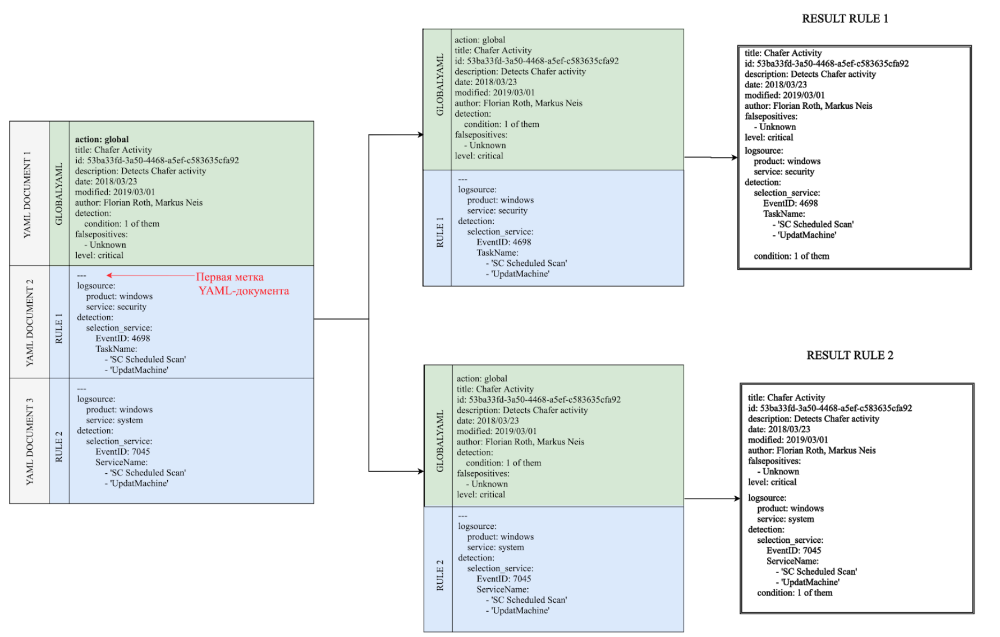
De acordo com o padrão YAML, um arquivo (em seu fluxo de terminologia) pode conter vários documentos YAML. Isso é conseguido graças à tag de documento YAML - três hífens (“---"). Para o formato Sigma, esses documentos podem ser regras Sigma independentes ou documentos de ação.
No primeiro caso, tudo é simples: um arquivo contém regras Sigma completas que separados uns dos outros por um rótulo de documento YAML (exemplo de regras / proxy / proxy_ursnif_malware.yml ) O
segundo caso é mais complicado: um documento YAML é tratado como um documento de ação se o atributo de ação de nível superior tiver um dos três valores a seguir:
- global — , YAML- . action- . : , Sigma- ;
- reset — , action-;
- repeat — repeat .
Observação : o atributo de ação pode aparecer em qualquer lugar da regra.
O caso de uso mais comum para uma coleção de regras é definir várias regras Sigma para eventos semelhantes, como Windows Security EventID 4688 e Sysmon EventID 1. Ambos os eventos aparecem como resultado da criação do processo, eles apenas têm origens diferentes. A coleção de regras Sigma para um determinado cenário pode conter três documentos de ação:
- Um documento de ação global que define campos de metadados comuns e indicadores de detecção.
- Regra que define a origem do Log de Eventos de Segurança do Windows e EventID = 4688 do evento.
- Uma regra que define a origem do Log de Eventos do Windows Sysmon e EventID = 1 do evento.
Uma solução alternativa poderia ser:
- Um documento de ação global que define campos de metadados comuns.
- Windows Security Event Log ( EventID=4688) .
- Action- repeat, logsource EventID , . 2.
action-
Nesta seção, iremos detalhar exatamente como o Sigma gera regras de resumo com base nos valores do atributo de ação. Os documentos YAML que contêm um atributo de ação com o valor global são considerados documentos globais neste arquivo e seus campos serão adicionados a todos os outros documentos.
Nota : se o documento atual contiver o atributo de ação com o valor de redefinição, os campos globais do documento não serão adicionados a ele.
A lógica para trabalhar com documentos globais é a seguinte: assim que o analisador encontra um documento global (um documento que contém um atributo de ação com o valor global), ele adiciona seus campos a um buffer especial e prossegue para o próximo documento. Vamos chamar esse buffer especial de GLOBALYAML, será útil no futuro referir-se a ele nos diagramas.
Importante: Visto que os limites do documento são definidos pela marca “---”, é importante colocar essas marcas corretamente no arquivo.
No exemplo abaixo, o primeiro documento YAML contém um atributo de ação com o valor global. Os limites deste documento se estendem até a primeira marca de documento. Portanto, todo o primeiro documento é gravado no buffer global. Os campos deste buffer são então adicionados a cada documento subsequente. Como resultado, obtemos duas regras na saída. Esquema 1. Processamento de uma regra simples com a definição correta dos rótulos do documento YAML Mas se você excluir ou esquecer o primeiro rótulo, todos os campos do DOCUMENTO YAML 2 serão incluídos no documento global. Como resultado, obtemos apenas uma regra com um conjunto incorreto de identificadores de pesquisa na saída. Portanto, é muito importante rotular corretamente os documentos YAML em tais regras compostas.

Esquema 2. Processamento da regra anterior - caso se esqueça de colocar a primeira etiqueta do documento YAML
. Deve-se notar que o documento global não vem necessariamente no início. Se você olhar os dois esquemas anteriores, nem sempre é YAML DOCUMENT 1. Além disso, não precisa estar no singular. O diagrama a seguir ilustra isso claramente. Esquema 3. Processamento de uma regra contendo várias opções para definir um documento YAML global Portanto, consideramos as questões relacionadas ao posicionamento correto de rótulos de documentos YAML. Também vimos que você pode definir o documento YAML global de diferentes maneiras usando o atributo action com o valor global. A seguir, vamos examinar o esquema para transformar uma regra usando os dois valores restantes do atributo de ação - redefinir e repetir.


Esquema 4. Processamento de uma regra contendo os atributos de ação com os valores de redefinição e repetição
O que mais precisa ser dito sobre o projeto Sigma
Sigma não é apenas um conjunto de regras formatadas que abordamos nesta série.
Em nossas publicações, nos concentramos em descrever o formato e a sintaxe das regras. Mas as regras são apenas metade do projeto, a segunda são os back-ends usados pelo conversor sigmac. Convencionalmente, esses conversores podem ser considerados "adaptadores" com uma entrada universal e uma saída específica. É a presença de tais "adaptadores" que torna o formato de descrição universal tão útil. Nesta situação, não importa qual dos sistemas suportados você usa, o Sigma permite que você descreva a ideia e o algoritmo de detecção, enquanto um ou outro backend para o conversor sigmac é responsável pela sintaxe específica do sistema de destino e o mapeamento dos campos.
No entanto, não presuma que, baixando as regras e convertendo-as na sintaxe do sistema de destino necessário, você resolverá todos os problemas associados ao preenchimento de conhecimento do seu sistema. Discutiremos brevemente por que o Sigma não é uma solução pronta para o uso no momento e por que é necessário entender a sintaxe das regras.
Desafios Sigma Atuais
Sigma é um projeto em desenvolvimento ativo e, como qualquer projeto em crescimento, Sigma tem seus próprios desafios. Pessoalmente, vejo-os como pontos de desenvolvimento e áreas de crescimento. Bem, como este é um projeto de código aberto, a união de forças pode fazer uma contribuição significativa para o desenvolvimento de certas partes do projeto. Vou listar o que no momento me refiro às principais chamadas do framework:
- . .
- , Windows- (. ). , .
- Wiki , . .
- experimental — , .
- .
- , .
Por experiência própria, direi que quando conheci o projeto Sigma e participei do OSCD, o primeiro item da lista acabou sendo o mais significativo. Descobriu-se que as diferenças entre a sintaxe no MaxPatrol SIEM e no Sigma não terminam apenas na semântica das palavras-chave e no desenho de regras de correlação. Algumas de nossas ideias não podem ser descritas em termos da sintaxe Sigma, uma vez que, neste estágio, não há possibilidade de correlação de eventos. O mecanismo de correlação permite que você pesquise valores comuns de campos de eventos e relacione esses eventos entre si. Isso é útil quando queremos estabelecer com precisão a relação entre os eventos. Por exemplo, para rastrear eventos em uma sessão de usuário. Para fazer isso, você precisa vincular eventos pelo valor do campo LogonID ou seu equivalente.
Deve-se observar que as detecções pontuais ou detecções baseadas em eventos não diretamente relacionados são descritas com muito sucesso usando o Sigma.
Uma maneira de ajudar a resolver essas e outras questões é participar ativamente de um dos OSCD Sprints. E como as tarefas são muitas, todos poderão encontrar o que lhe interessa.
Novo sprint em breve, junte-se a nós!
Expressamos nossa gratidão aos organizadores do primeiro sprint pela alta qualidade do andamento do evento e pela atitude atenciosa para com os participantes. Quais são os únicos postais personalizados preenchidos à mão e enviados a cada participante! De nossa parte, planejamos continuar participando de novos sprints e fazer uma contribuição viável para o repositório Sigma.
Depois de ler nossa série de artigos e se familiarizar com o formato das regras, você poderá aplicar sua experiência em benefício de toda a comunidade de segurança da informação.
Certifique-se de entrar no segundo sprint. Participe individualmente e monte equipes, vamos tornar o mundo mais seguro juntos!
Contatos da Iniciativa OSCD:
Autor : Anton Kutepov, especialista do departamento de serviços especializados e desenvolvimento de Tecnologias Positivas (PT Expert Security Center)