Existem muitas ferramentas úteis que podem ajudá-lo a monitorar a carga do servidor, desde utilitários Linux a serviços especializados.
Utilitários simples do Linux mostram o consumo atual de memória para cada processo, carga da CPU, espaço livre em disco e estatísticas de tráfego.
Além disso, existem serviços pagos e gratuitos que monitoram o estado do seu servidor 24 horas por dia, registram falhas no seu funcionamento ou disponibilidade da rede, e também verificam o desempenho das aplicações.
Conteúdo
Utilitários Linux
Uso de recursos
topo
Uma das ferramentas mais utilizadas para verificar o uso de recursos por processos. O utilitário
topproduz uma tabela simples com o consumo atual de recursos, onde os processos de maior carga são indicados no topo.
top - 14:45:52 up 29 min, 1 user, load average: 0.10, 0.09, 0.06
Tasks: 56 total, 1 running, 55 sleeping, 0 stopped, 0 zombie
Cpu(s): 0.0%us, 0.3%sy, 0.0%ni, 99.7%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 1019600k total, 393756k used, 625844k free, 11136k buffers
Swap: 0k total, 0k used, 0k free, 316748k cached
PID %MEM VIRT SWAP RES CODE DATA SHR nFLT nDRT S PR NI %CPU COMMAND
832 1.3 32364 18m 12m 896 11m 1688 1 0 S 20 0 0.0 bash
820 0.4 89456 83m 4008 488 948 3040 12 0 S 20 0 0.0 sshd
812 0.3 49948 46m 2828 488 616 2216 0 0 S 20 0 0.0 sshd
1 0.2 24192 21m 2108 152 868 1300 23 0 S 20 0 0.0 init
400 0.1 243m 242m 1420 344 216m 1084 0 0 S 20 0 0.0 rsyslogdAlgumas estatísticas gerais são fornecidas imediatamente antes da mesa, incluindo a carga média da CPU no último minuto, 5 minutos e 15 minutos. Ele também mostra o consumo de memória, consumo de arquivo de paginação e estado do processo.
A lista é atualizada em tempo real: você pode exibi-la em um segundo monitor e assisti-la constantemente.
htop
Embora o utilitário
topvenha com quase todas as distribuições, uma versão aprimorada também está disponível para download na maioria dos repositórios htop.
Instalação
htopno Ubuntu:
apt-get install htopAqui vemos quase a mesma saída, mas com cores diferentes e saída mais interativa:
CPU[| 0.7%] Tasks: 21, 3 thr; 1 running
Mem[||||||||||||| 64/995MB] Load average: 0.00 0.02 0.05
Swp[ 0/0MB] Uptime: 00:37:37
PID USER PRI NI VIRT RES SHR S CPU% MEM% TIME+ Command
2752 root 20 0 25660 1876 1364 R 0.0 0.2 0:00.06 htop
1 root 20 0 24192 2108 1300 S 0.0 0.2 0:00.55 /sbin/init
312 root 20 0 17224 640 444 S 0.0 0.1 0:00.04 upstart-udev-brid
314 root 20 0 21592 1360 760 S 0.0 0.1 0:00.04 /sbin/udevd --dae
394 messagebu 20 0 23808 688 436 S 0.0 0.1 0:00.01 dbus-daemon --sys
401 syslog 20 0 243M 1420 1084 S 0.0 0.1 0:00.07 rsyslogd -c5
402 syslog 20 0 243M 1420 1084 S 0.0 0.1 0:00.00 rsyslogd -c5A parte superior é mais clara e melhor organizada aqui.
Aqui estão algumas chaves para melhor uso
htop:
- M : processos de classificação por uso de memória
- P : classificar processos por uso de CPU
- ? : referência
- k : matar processos atuais / marcados
- F2 : configuração (aqui você pode selecionar as opções a serem exibidas)
- / : busca por processos
Várias outras opções estão listadas na ajuda e nas configurações. Vale a pena iniciar o estudo do programa a partir dessas duas seções.
Tráfego de rede
nethogs
nethogsÉ o utilitário mais simples para ver quanto tráfego está em cada serviço. No Ubuntu, o utilitário é instalado com o seguinte comando:
apt-get install nethogsEntão, ele pode ser iniciado sem as chaves. O problema é simples:
PID USER PROGRAM DEV SENT RECEIVED
3379 root /usr/sbin/sshd eth0 0.485 0.182 KB/sec
820 root sshd: root@pts/0 eth0 0.427 0.052 KB/sec
? root unknown TCP 0.000 0.000 KB/sec
TOTAL 0.912 0.233 KB/secExistem apenas algumas opções para alterar a saída:
- m : alternar entre kb / s, kb, b, mb
- r : classifica pelo tráfego recebido.
- s : classificar por tráfego enviado
- q : sair
Embora seja um utilitário simples, é ótimo para ver rapidamente quais aplicativos estão gerando tráfego.
IPTraf
IPTraf- outra forma de monitorar o tráfego da rede, com várias opções. Instalação no Ubuntu:
apt-get install iptrafEste utilitário oferece a escolha de uma das interfaces interativas:
???????????????????????????????????
? IP traffic monitor ?
? General interface statistics ?
? Detailed interface statistics ?
? Statistical breakdowns... ?
? LAN station monitor ?
???????????????????????????????????
? Filters... ?
???????????????????????????????????
? Configure... ?
???????????????????????????????????
? Exit ?
???????????????????????????????????Por exemplo, para visualizar todo o tráfego da rede, selecione o primeiro item de menu:
? TCP Connections (Source Host:Port) ?????????? Packets ??? Bytes Flags Iface ?
??192.241.xxx.xxx:22 > 369 82420 -PA- eth0 ?
??72.43.xxx.xxx:49488 > 381 19860 --A- eth0 ?
? ?
? ?Para que os endereços IP sejam resolvidos em domínios, você precisa selecionar o item 'Pesquisas DNS reversas' na configuração.
Junto com a visualização do tráfego por portas, há uma opção para visualizar o tráfego por serviço (opção 'nomes de serviço TCP / UDP'). Com as duas opções ativadas, a saída será semelhante a esta:
TCP Connections (Source Host:Port) ?????????? Packets ??? Bytes Flags Iface ?
??192.241.xxx.xxx:ssh > 151 34924 -PA- eth0 ?
??rrcs-72-43-xxx-xxx.nyc.biz.rr.co:49488 > 155 8108 --A- eth0 ?
? ?
? ?
? ?
? ?
? ?
? ?
? ?
? ?
? ?
? ?
? TCP: 1 entries ???????????????????????????????????????????????? Active ??
????????????????????????????????????????????????????????????????????????????????
? UDP (72 bytes) from 192.241.xxx.xxx:43463 to 8.8.8.8:domain on eth0 ?
? UDP (66 bytes) from 192.241.xxx.xxx:53140 to 8.8.8.8:domain on eth0 ?
? UDP (135 bytes) from 8.8.8.8:domain to 192.241.xxx.xxx:41429 on eth0 ?
? UDP (119 bytes) from 8.8.8.8:domain to 192.241.xxx.xxx:43463 on eth0 ?
? UDP (110 bytes) from google-public-dns-a.googl:domain to 192.241.xxx.xxx:531 ?Existem algumas outras interfaces que você pode explorar por conta própria.
netstat
O utilitário
netstaté uma ferramenta muito flexível e poderosa para coletar informações de rede.
Por padrão, ele
netstatfornece uma lista de soquetes abertos:
Active Internet connections (w/o servers)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 192.241.187.204:ssh ip223.hichina.com:50324 ESTABLISHED
tcp 0 0 192.241.187.204:ssh rrcs-72-43-115-18:50615 ESTABLISHED
Active UNIX domain sockets (w/o servers)
Proto RefCnt Flags Type State I-Node Path
unix 5 [ ] DGRAM 6559 /dev/log
unix 3 [ ] STREAM CONNECTED 9386
unix 3 [ ] STREAM CONNECTED 9385
. . .Se adicionar opção
-a, ele mostrará uma lista de todas as portas:
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 *:ssh *:* LISTEN
tcp 0 0 192.241.187.204:ssh rrcs-72-43-115-18:50615 ESTABLISHED
tcp6 0 0 [::]:ssh [::]:* LISTEN
Active UNIX domain sockets (servers and established)
Proto RefCnt Flags Type State I-Node Path
unix 2 [ ACC ] STREAM LISTENING 6195 @/com/ubuntu/upstart
unix 2 [ ACC ] STREAM LISTENING 7762 /var/run/acpid.socket
unix 2 [ ACC ] STREAM LISTENING 6503 /var/run/dbus/system_bus_socket
. . .Sinaliza
-tou -ufiltra conexões TCP ou UDP, respectivamente. O sinalizador -sexibe estatísticas. Para atualizar constantemente a saída, você precisa executar o comando com a tecla -c.
Espaço em disco
df
O utilitário padrão para visualizar informações sobre partições montadas é
df. Ele exibe uma lista de dispositivos conectados e informações sobre o espaço ocupado.
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/vda 31383196 1228936 28581396 5% /
udev 505152 4 505148 1% /dev
tmpfs 203920 204 203716 1% /run
none 5120 0 5120 0% /run/lock
none 509800 0 509800 0% /run/shmPor padrão, a saída é em bytes, o que não é muito conveniente. O parâmetro
-hativa a saída em megabytes e gigabytes:
Filesystem Size Used Avail Use% Mounted on
/dev/vda 30G 1.2G 28G 5% /
udev 494M 4.0K 494M 1% /dev
tmpfs 200M 204K 199M 1% /run
none 5.0M 0 5.0M 0% /run/lock
none 498M 0 498M 0% /run/shmPara visualizar todo o espaço em todos os discos, adicione a opção
--total.
du
O utilitário
dfpermite obter rapidamente uma visão geral. Para obter informações mais detalhadas, um programa duque analisa o diretório atual e quaisquer subdiretórios é mais adequado . A saída padrão é semelhante a esta:
4 ./.cache
8 ./.ssh
28 .Novamente, uma saída mais legível é ativada com uma chave
-h.
A visualização dos tamanhos dos arquivos e diretórios é habilitada por uma bandeira
-a, o total geral - pelas bandeiras -c(detalhes e quantidade) e -s(apenas quantidade).
Versões melhoradas
As versões aprimoradas de df e du são chamadas de pydf e ncdu e são instaladas no Ubuntu com os comandos
apt-get install pydfe apt-get install ncdu. Eles organizam belos resultados em pseudo-gráficos com cores:
pydf -a
dev/vda 30G 1200M 27G 3.9 [........] /
udev 493M 4096B 493M 0.0 [........] /dev
devpts 0 0 0 - [........] /dev/pts
proc 0 0 0 - [........] /proc
tmpfs 199M 204k 199M 0.1 [........] /run
none 5120k 0 5120k 0.0 [........] /run/lock
none 498M 0 498M 0.0 [........] /run/shm
. . .ncdu
--- /root ----------------------------------------------------------------------
8.0KiB [##########] /.ssh
4.0KiB [##### ] /.cache
4.0KiB [##### ] .bashrc
4.0KiB [##### ] .profile
4.0KiB [##### ] .bash_historyAqui você pode navegar no sistema de arquivos usando as teclas de seta.
Uso de memória
livre
A maneira mais fácil de ver o uso atual da RAM é com o comando
free. A saída sem opções tem a seguinte aparência:
total used free shared buffers cached
Mem: 12286456 11715372 571084 0 81912 6545228
-/+ buffers/cache: 5088232 7198224
Swap: 24571408 54528 24516880Iniciar com uma chave
-mgera uma saída em megabytes.
A linha do meio
-/+ buffers/cachemostra a quantidade de memória usada menos a soma de buffers / cache e a quantidade de memória livre mais a soma de buffers / cache.
O fato é que o Linux, como a maioria dos sistemas operacionais modernos, tenta usar a quantidade máxima de RAM disponível para buffers e cache. Portanto, a segunda linha importa, que mostra a quantidade real de RAM potencialmente disponível para os aplicativos, se você ignorar os buffers e o cache. Este espaço será liberado automaticamente se necessário para inscrições.
vmstat
O comando
vmstatexibe várias informações sobre o sistema, incluindo memória, arquivo de paginação, operações de E / S e carga da CPU.
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 2828 407616 335348 5511476 0 0 26 268 41 27 28 30 42 0 0A primeira coluna
rmostra o número de processos ativos, a segunda - o número de processos no estado de espera ininterrupta.
As colunas
sie somostram a quantidade de memória lida e gravada no arquivo de paginação, respectivamente.
O seguinte mostra o número de blocos recebidos ou enviados para o dispositivo de I / O de bloco (bi, bo), o número de interrupções por segundo incluindo temporizador (in), o número de mudanças de contexto por segundo (cs) e estatísticas de CPU: porcentagem de tempo gasto no processamento código no espaço do usuário (us), para processamento do código do kernel (sy), no estado de hibernação (id) e aguardando I / O (wa), bem como o tempo "roubado" da máquina virtual (st), ou seja, quando a CPU virtual espera que a CPU real atue quando o hipervisor estiver atendendo a outro processador virtual.
A bandeira
-S Mativa a entrega em megabytes. Executando com a opção -smostra estatísticas gerais.
Serviços de monitoramento
Se você precisa monitorar o status do servidor o tempo todo (memória, CPU, espaço livre, desempenho, tempo de resposta, etc.), então você pode usar um serviço de monitoramento gratuito ou pago. Existem muitos desses serviços, aqui está uma pequena lista em ordem alfabética:
- Anturis
- AppDynamics
- AppNeta
- Atera
- BigPanda
- CollectD
- Datadog
- eG Innovations
- Ganglia
- Icinga (adaptação gratuita do Nagios Core)
- Instrumental
- LogicMonitor
- ManageEngine OpManager
- Monitis
- Motadata
- Nagios XI (a versão gratuita é chamada de Nagios Core)
- Monitor Navicat
- NinjaRMM
- Monitor Op5
- OpenNMS
- Pandora FMS
- Panopta
- PRTG Network Monitor
- Leão marinho
- Densidade do servidor
- Site 24x7
- SolarWinds Server e Application Monitor
- Spiceworks Network Monitor (gratuito)
- Stackify
- WhatsUpGold
- Zabbix (monitor de sistema gratuito)
Alguns monitores são mais adequados para pequenas empresas, enquanto outros são mais adequados para grandes empresas. Alguns se especializam em monitorar sistemas em nuvem. Existem serviços que funcionam apenas em servidores Linux. Os sistemas diferem em escalabilidade, conjunto de recursos e nível de automação. Vários monitores são distribuídos de código aberto.
Por exemplo, considere três serviços de monitoramento relativamente populares.
SolarWinds Server e Application Monitor
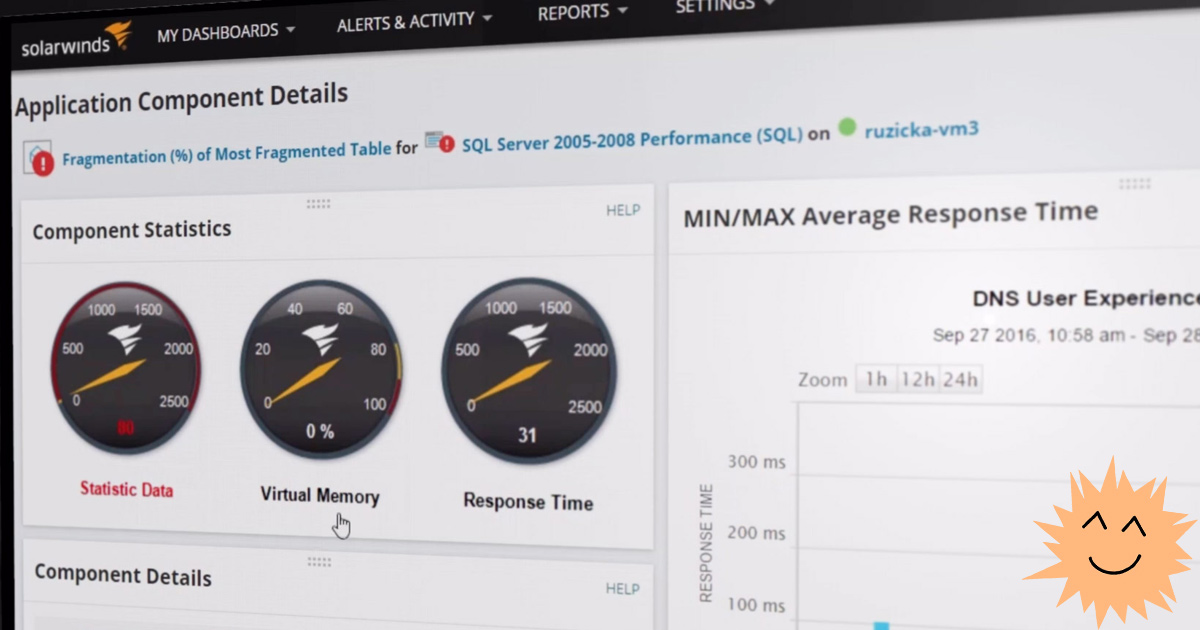
Um dos monitores de servidor mais avançados do mercado é o SolarWinds Server and Application Monitor (SAM). Embora a ferramenta seja instalada apenas no Windows Server 2016+, ela pode rastrear qualquer hardware, incluindo servidores Linux.
O monitor monitora o desempenho do servidor, relata problemas e também oferece alguns recursos de gerenciamento: permite reiniciar o servidor, disparar processos e reiniciar serviços, ou seja, é uma ferramenta não só de monitoramento, mas também de administração.

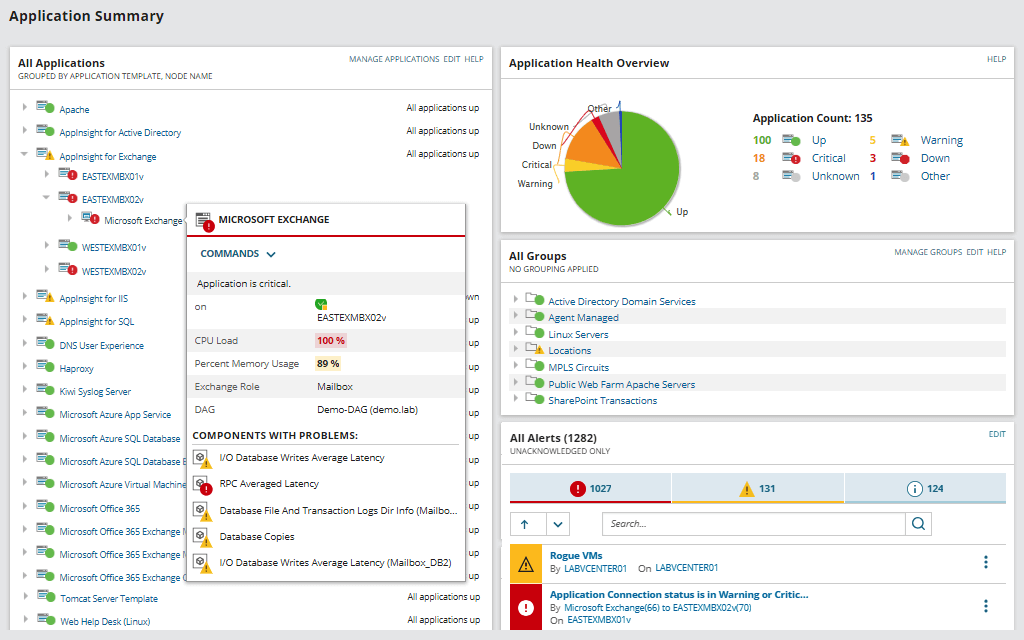
O programa é mais adequado para grandes empresas. Compatibilidade declarada com Dell PowerEdge, HP ProLiant, IBM eServer xSeries, Dell PowerEdge Blade, HP BladeSystem, Microsoft Windows Server e VMware vSphere. SAM também monitora AWS e instâncias de nuvem Azure.
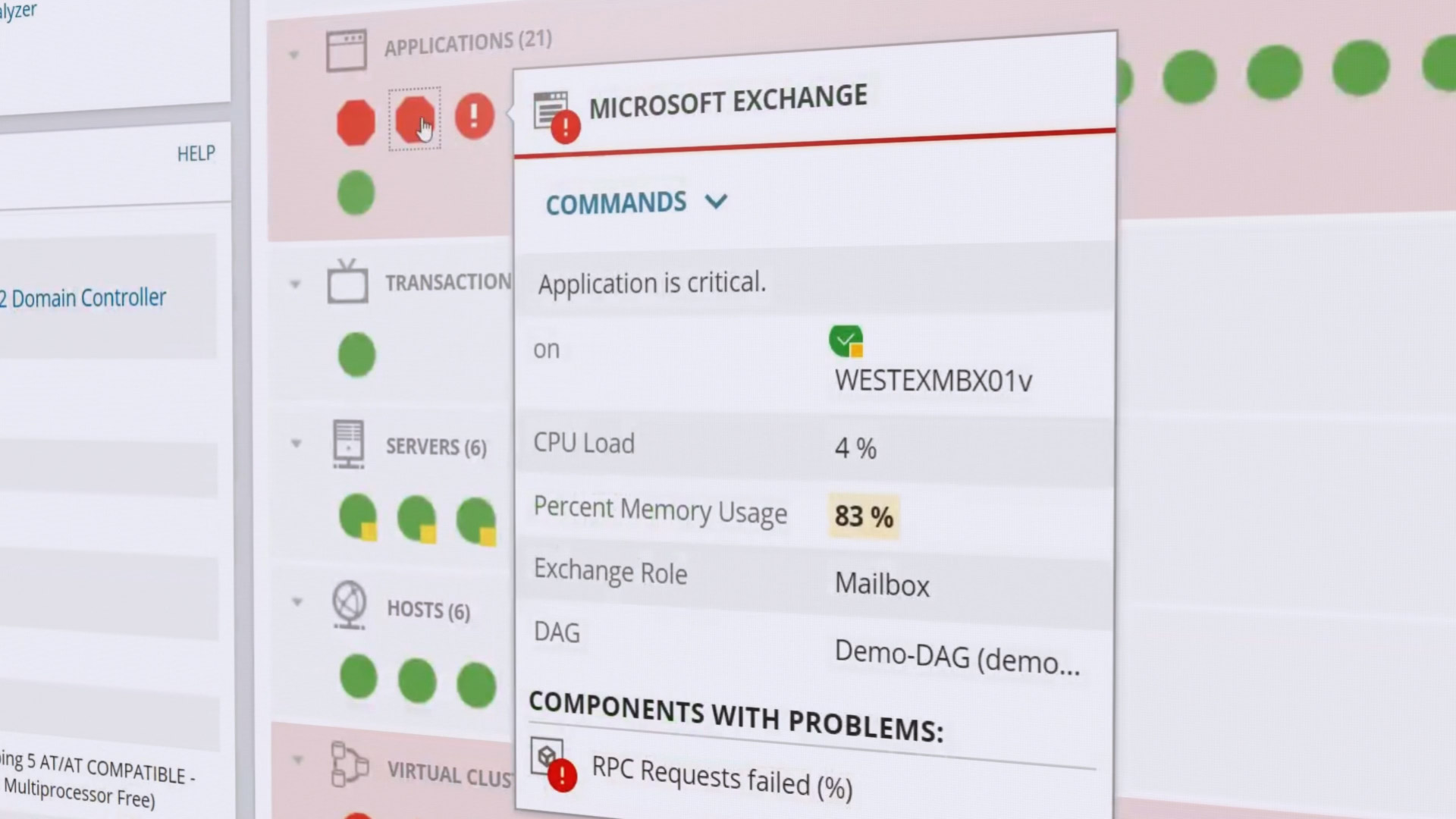
Ele mostra estatísticas sobre o tempo de resposta, carga da CPU, memória, etc. O desempenho de aplicativos individuais é monitorado: o suporte para mais de 1200 aplicativos diferentes está integrado. O status do hardware também é verificado: uso da CPU, carga do disco, fonte de alimentação, status do ventilador, etc. Os status são codificados por cores de verde a vermelho para facilitar a avaliação rápida da integridade do sistema.
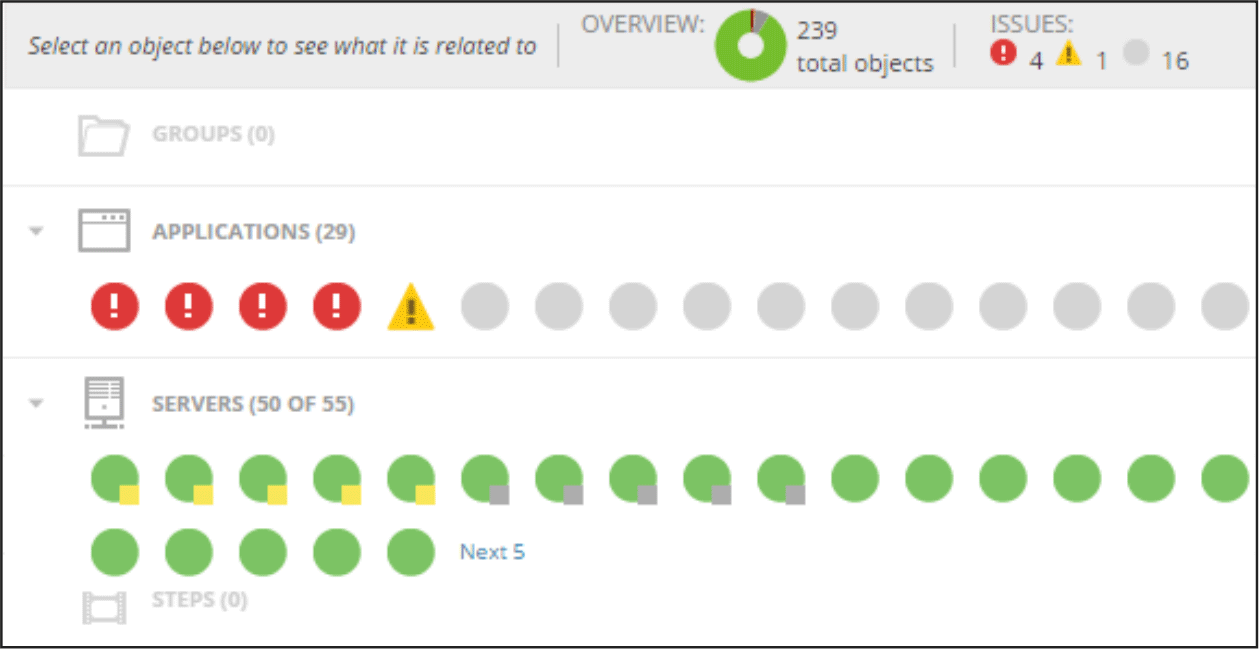
O monitor detecta automaticamente novo hardware e software em seu cluster, adicionando-o imediatamente ao painel. Este é um dos principais recursos do SAM, bem como a automação máxima - modelos preparados para automatizar tarefas regulares de monitoramento e manutenção, modelos para relatórios e notificações.
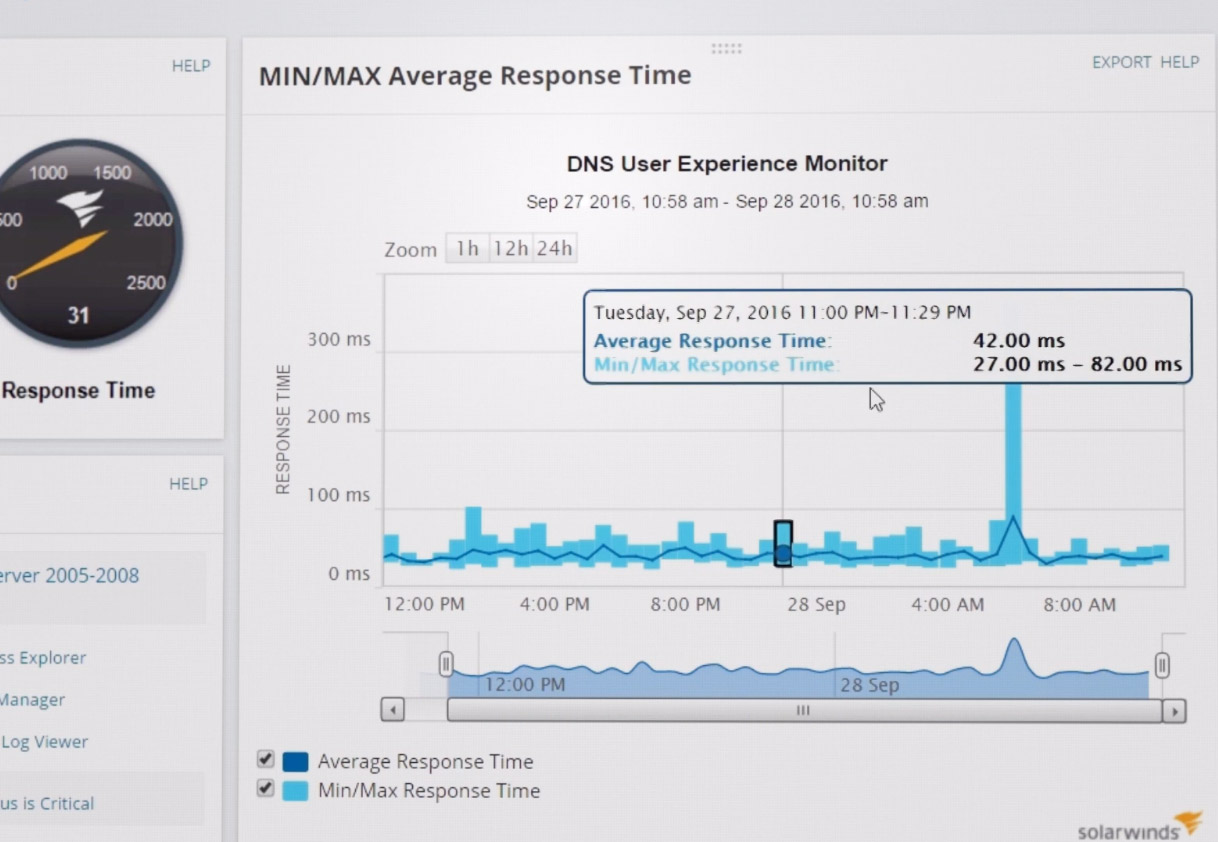
Normalmente, esses serviços têm um período de teste gratuito e o custo pode depender do conjunto de funcionalidades utilizadas. Há também um período de teste aqui, e o custo do SolarWinds Server e Application Monitor começa em 1275 euros em funcionalidade mínima.
Monitor Navicat
Outro exemplo é o Navicat Monitor , especializado em monitoramento de banco de dados. Suporta MySQL, MariaDB, SQL Server, bem como DBMSs em nuvem, como Amazon RDS, Amazon Aurora, Oracle Cloud, Google Cloud e Microsoft Azure.

Visualização padrão Visualização
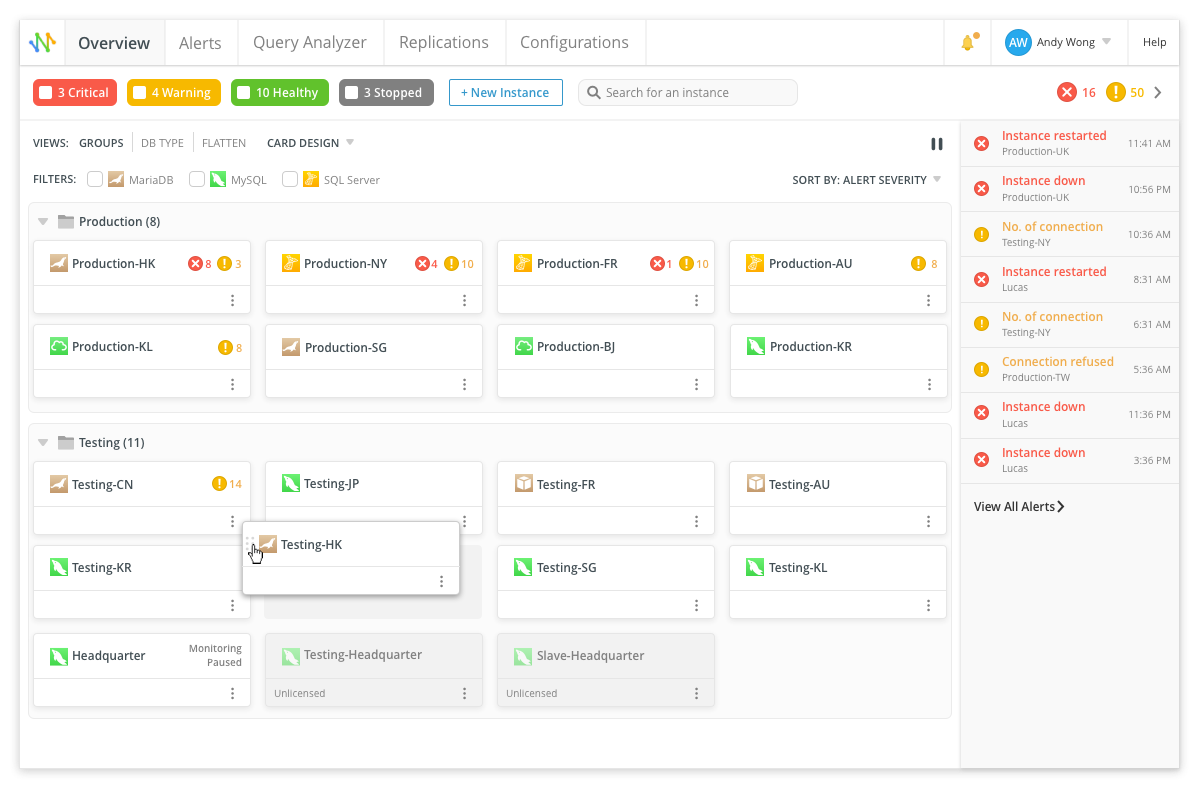
compacta O
monitor rastreia o tempo de execução de consultas específicas, executando-as em um intervalo especificado.

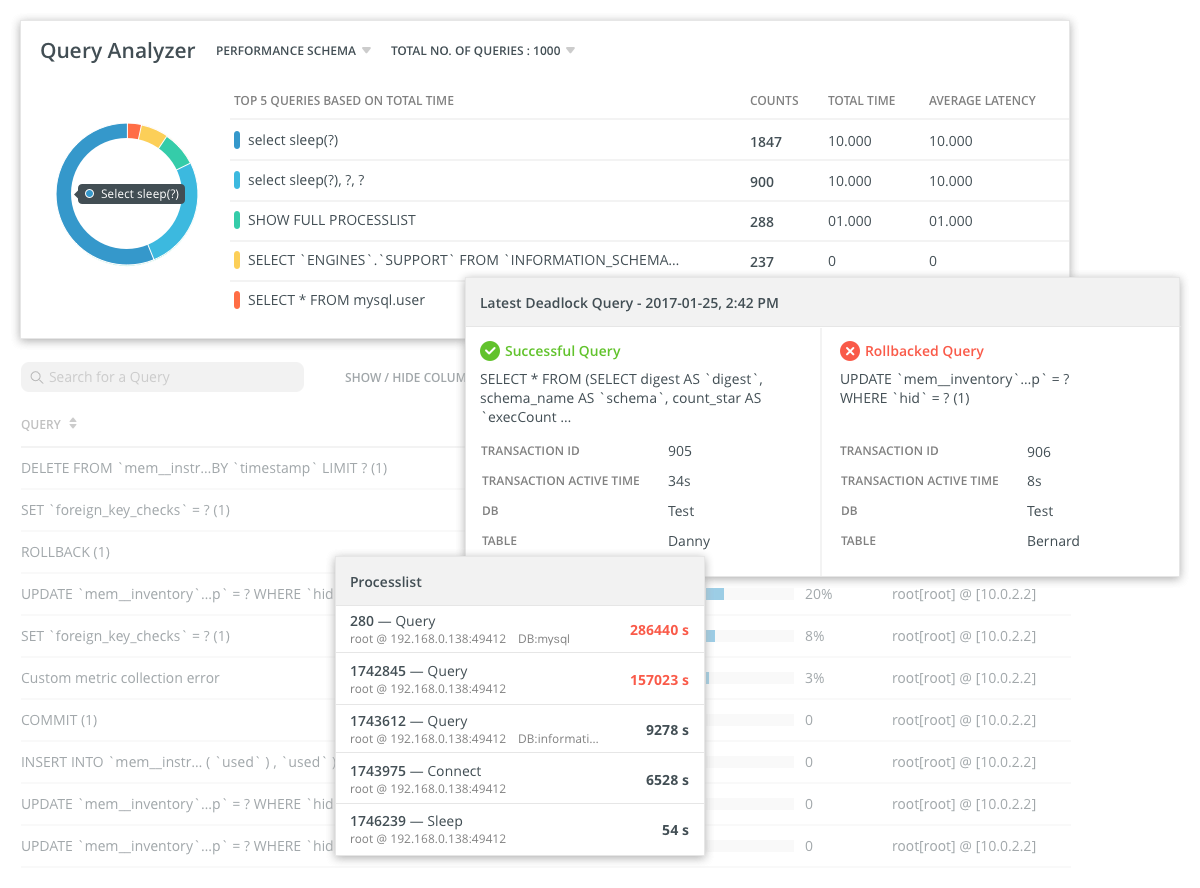
Além de consultas ao banco de dados, outras consultas são enviadas periodicamente aos servidores para monitorar os indicadores de desempenho do sistema de E / S, rede, etc. As estatísticas são coletadas sobre a utilização da CPU, utilização da memória e outras métricas padrão.
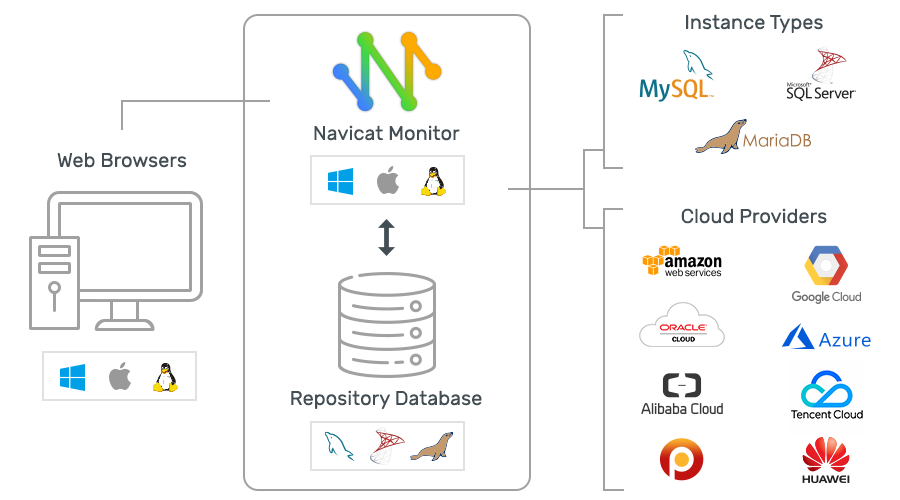
A arquitetura do Navicat Monitor não fornece instalação de software em objetos de monitoramento
O preço mínimo do Navicat Monitor é de US $ 32,99 por token por mês (um token corresponde ao monitoramento de um servidor ou quatro bases do Azure). Há um teste de 14 dias totalmente funcional.
Zabbix
Zabbix é uma ferramenta gratuita de código aberto que monitora a saúde da rede, dos aplicativos e do próprio servidor. Vem com modelos prontos para monitorar servidores e sistemas operacionais populares, incluindo HP, IBM, Lenovo, Dell, servidores Linux, Ubuntu e Solaris. Ao longo dos anos, a comunidade Zabbix preparou modelos para vários cenários.
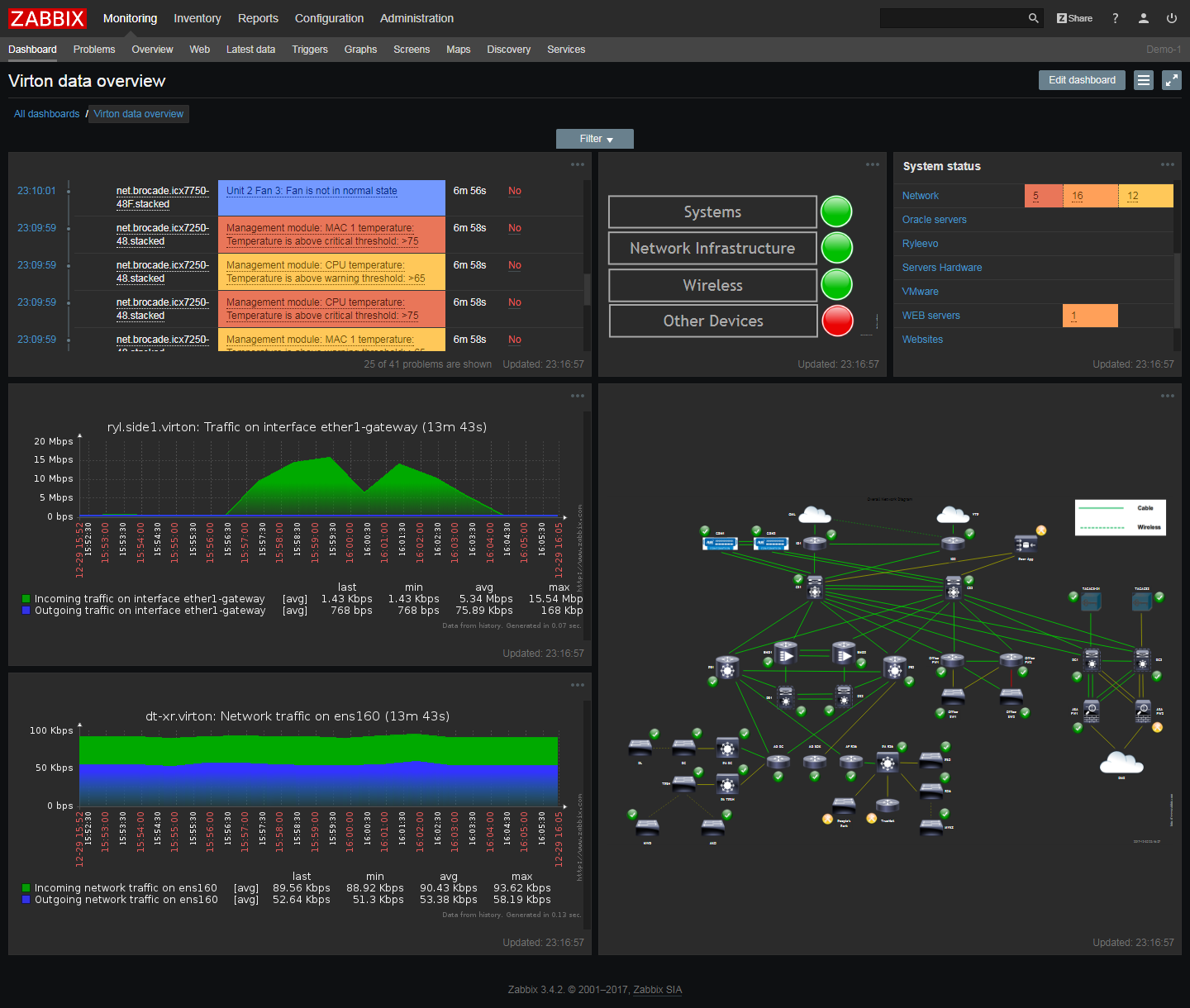
Os principais módulos do Zabbix monitoram a carga da CPU, uso de memória, taxa de erro de E / S, espaço livre em disco, status do ventilador, temperatura e características do sistema de energia. O módulo de rede verifica o tráfego, a disponibilidade da rede, a taxa de perda de pacotes, a qualidade das conexões TCP e a taxa de transferência dos roteadores.
O Zabbix mantém uma lista de versões de software e firmware instaladas para sinalizar instalações de software não autorizadas.

O administrador do sistema pode programar notificações no Zabbix de acordo com condições arbitrárias, bem como alterar a importância das notificações ativas. No painel de controle, você pode adicionar usuários - e enviar a cada um deles certos tipos de notificações, e os scripts de automação permitem que você inicie tarefas automaticamente e as atribua aos funcionários.
Graças ao acesso remoto e função de gerenciamento, Zabbix pode ser considerado uma boa ferramenta de administração de servidor.
A única desvantagem deste sistema é que se você adicionou cerca de 1000 servidores ou mais para monitoramento, devido ao grande número de mensagens e procedimentos de criptografia, o Zabbix começa a responder lentamente aos comandos, portanto, esta ferramenta não é muito adequada para empresas muito grandes. Os
sistemas de monitoramento de servidor diferem em funcionalidade ... Nem todos podem monitorar a integridade de aplicativos individuais, o desempenho do servidor e os tempos de resposta. Mas essas deficiências podem ser corrigidas com ferramentas adicionais: por exemplo, sistemas analíticos e de monitoramento de log.
Um servidor confiável para aluguel e a escolha certa de um plano de tarifas permitirão que você se distraia menos com notificações de monitoramento desagradáveis - tudo funcionará perfeitamente e com um tempo de atividade muito alto!
