Para entender como os índices B-tree surgiram, vamos imaginar um mundo sem eles e tentar resolver um problema típico. Ao longo do caminho, discutiremos os problemas que enfrentaremos e as maneiras de resolvê-los.

Introdução
No mundo dos bancos de dados, existem duas maneiras mais comuns de armazenar informações:
- Baseado em estruturas baseadas em Log.
- Com base nas páginas.
A vantagem do primeiro método é que ele permite que você leia e salve dados de maneira fácil e rápida. As novas informações só podem ser gravadas no final do arquivo (gravação sequencial), o que garante alta velocidade de gravação. Este método é usado por bases como Leveldb, Rocksdb, Cassandra.
O segundo método (baseado em página) divide os dados em blocos de tamanho fixo e os salva no disco. Essas peças são chamadas de "páginas" ou "blocos". Eles contêm registros (linhas, tuplas) de tabelas.
Este método de armazenamento de dados é usado por MySQL, PostgreSQL, Oracle e outros. E como estamos falando sobre índices no MySQL, esta é a abordagem que consideraremos.
Armazenamento de dados em MySQL
Portanto, todos os dados no MySQL são salvos no disco como páginas. O tamanho da página é regulado pelas configurações do banco de dados e é 16 KB por padrão.
Cada página contém 38 bytes de cabeçalhos e um final de 8 bytes (conforme mostrado na figura). E o espaço alocado para armazenamento de dados não é totalmente preenchido, porque o MySQL deixa um espaço vazio em cada página para alterações futuras.
Mais adiante nos cálculos, iremos negligenciar as informações do serviço, assumindo que todos os 16 KB da página estão preenchidos com nossos dados. Não vamos nos aprofundar na organização das páginas InnoDB, este é um tópico para um artigo separado. Você pode ler mais sobre isso aqui .

Como concordamos acima que os índices ainda não existem, por exemplo, criaremos uma tabela simples sem nenhum índice (na verdade, o MySQL ainda criará um índice, mas não o levaremos em consideração nos cálculos):
CREATE TABLE `product` (
`id` INT NOT NULL AUTO_INCREMENT,
`name` CHAR(100) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`category_id` INT NOT NULL,
`price` INT NOT NULL,
) ENGINE=InnoDB;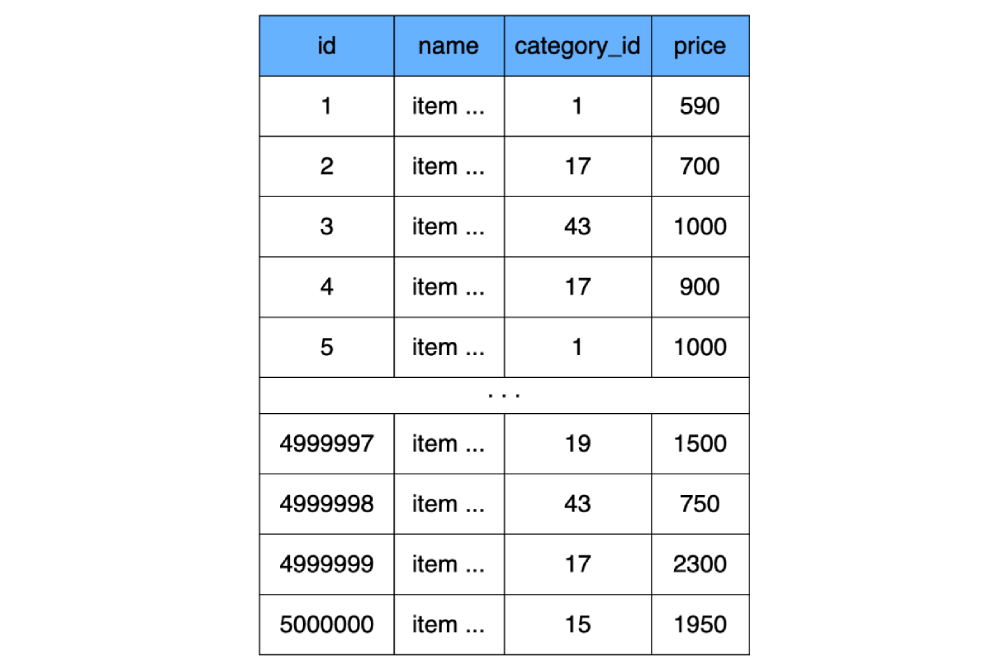
e execute a seguinte solicitação:
SELECT * FROM product WHERE price = 1950;O MySQL abrirá o arquivo onde os dados da tabela estão armazenados
producte começará a iterar sobre todos os registros (linhas) em busca dos requeridos, comparando o campo pricede cada linha encontrada com o valor da consulta. Para maior clareza, considero especificamente a opção com uma varredura completa do arquivo, portanto, os casos em que o MySQL recebe dados do cache não são adequados para nós.
Que problemas podemos enfrentar com isso?
HDD
Como temos tudo armazenado em um disco rígido, vamos dar uma olhada em seu dispositivo. O disco rígido lê e grava dados em setores (blocos). O tamanho desse setor pode ser de 512 bytes a 8 KB (dependendo do disco). Vários setores consecutivos podem ser combinados em clusters.
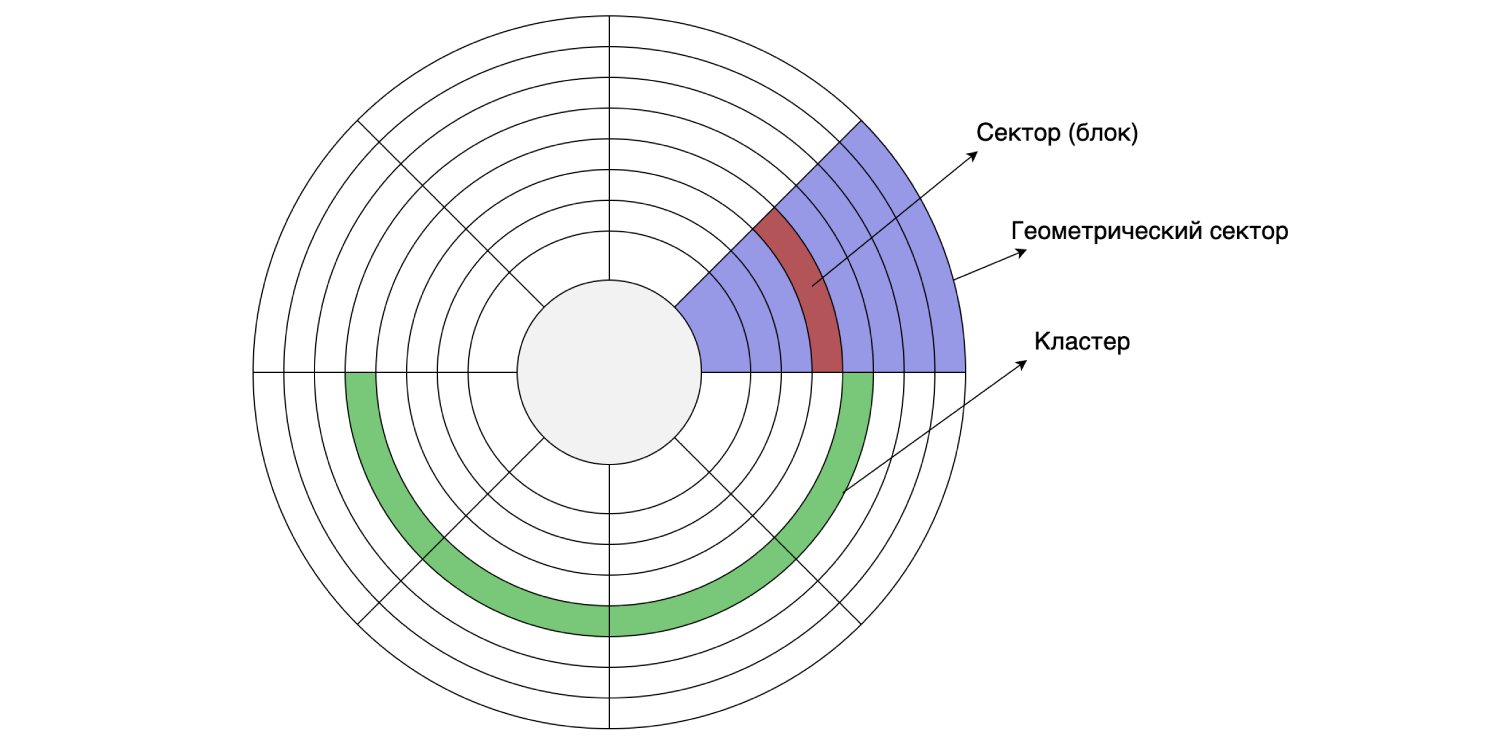
O tamanho do cluster pode ser definido no momento da formatação / particionamento do disco, ou seja, é feito de forma programática. Suponha que o tamanho do setor no disco seja de 4 KB e o sistema de arquivos seja particionado com um tamanho de cluster de 16 KB: um cluster consiste em quatro setores. Como lembramos, o MySQL, por padrão, armazena dados em disco em páginas de 16 KB, portanto, uma página cabe em um cluster de disco.
Vamos calcular quanto espaço nossa placa de produto ocupará, supondo que ela contenha 500.000 itens. Temos três campos de quatro bytes
id, pricee category_id. Vamos concordar que o campo de nome de todos os registros seja preenchido até o fim (todos os 100 caracteres) e cada caractere ocupe 3 bytes. (3 * 4) + (100 * 3) = 312 bytes - isso é quanto pesa uma linha de nossa tabela, e multiplicando isso por 500.000 linhas, obtemos o peso da tabela product156 megabytes.
Assim, para armazenar esta etiqueta, 9750 clusters são necessários no disco rígido (9750 páginas de 16 KB).
Ao salvar no disco, os clusters livres são obtidos, o que leva a uma "mancha" dos clusters de uma placa (arquivo) em todo o disco (isso é chamado de fragmentação). A leitura de tais blocos de memória localizados aleatoriamente no disco é chamada de leitura aleatória. Essa leitura é mais lenta porque você precisa mover a cabeça do disco rígido muitas vezes. Para ler o arquivo inteiro, temos que pular todo o disco para obter os clusters necessários.
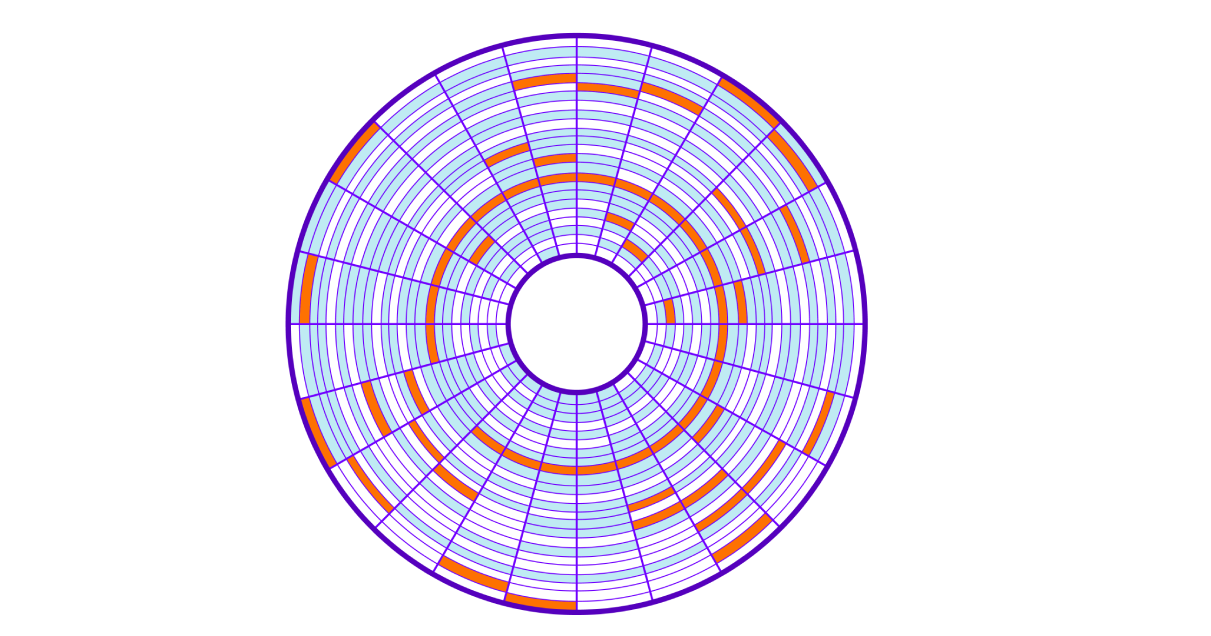
Vamos voltar à nossa consulta SQL. Para localizar todas as linhas, o servidor terá que ler todos os 9750 clusters espalhados pelo disco e levará muito tempo para mover o cabeçote de leitura do disco. Quanto mais clusters usarmos nossos dados, mais lenta será a pesquisa. Além disso, nossa operação obstruirá o sistema de E / S do sistema operacional.
Em última análise, obtemos uma velocidade de leitura baixa; "Suspender" o SO, obstruindo o sistema de E / S; e fazer muitas comparações, verificando as condições da consulta para cada linha.
Minha propria bicicleta
Como podemos resolver esse problema por conta própria?
Precisamos descobrir como melhorar as pesquisas de tabela
product. Vamos criar outra tabela na qual armazenaremos apenas o campo pricee o link para o registro (área em disco) em nossa tabela product. Vamos considerar imediatamente que, ao adicionar dados a uma nova tabela, armazenaremos os preços de forma ordenada.
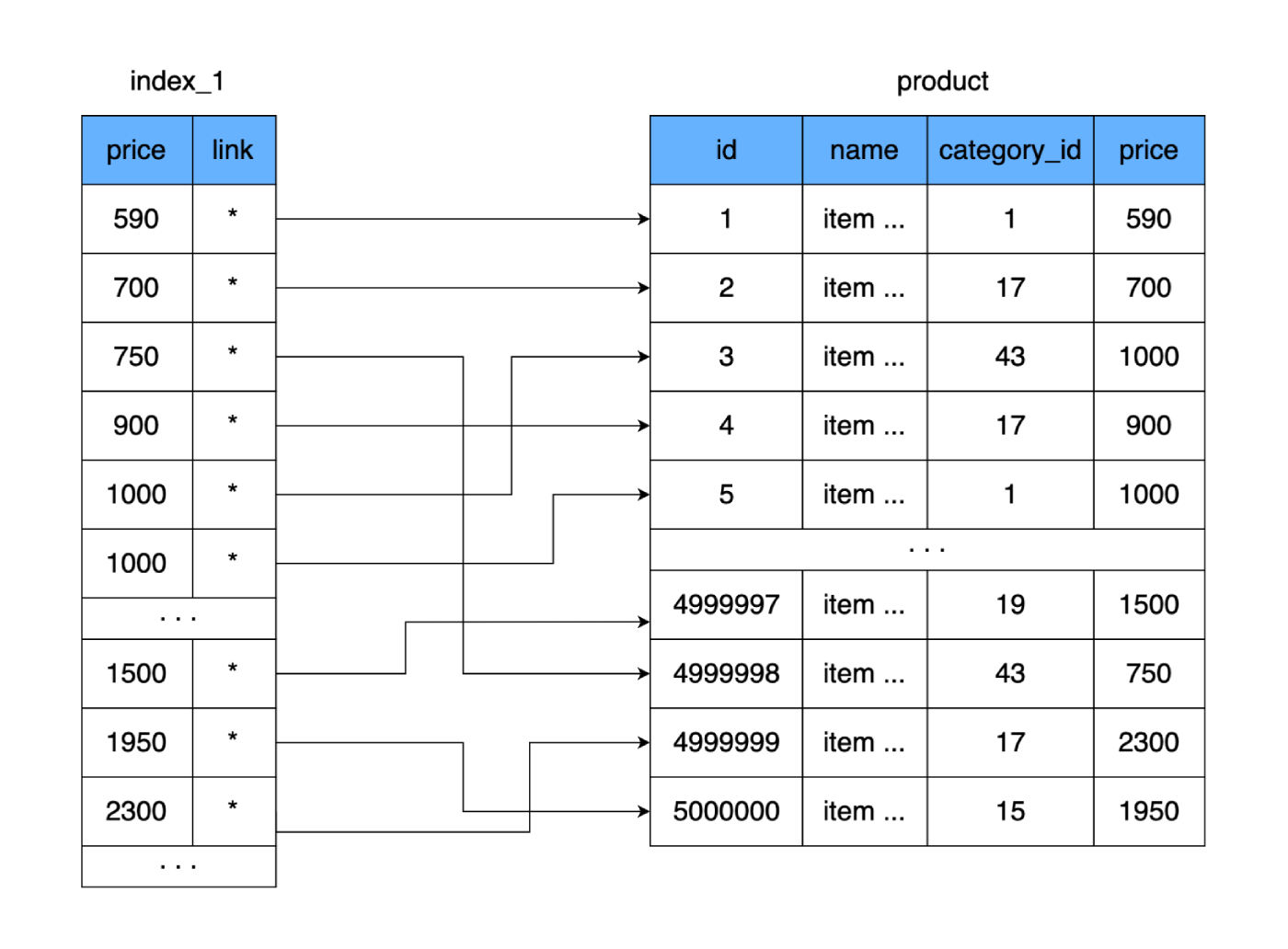
O que isso nos dá? A nova tabela, como a principal, é armazenada no disco página por página (em blocos). Ele contém o preço e um link para a tabela principal. Vamos calcular quanto espaço essa mesa ocupará. O preço ocupa 4 bytes e a referência à tabela principal (endereço) também é de 4 bytes. Para 500.000 linhas, nossa nova tabela pesará apenas 4 MB. Dessa forma, muito mais linhas da nova tabela caberiam em uma página de dados e menos páginas seriam necessárias para armazenar todos os nossos preços.
Se uma tabela completa requer 9.750 clusters de disco rígido (ou o pior cenário, 9.750 saltos de disco rígido), a nova tabela se ajusta a apenas 250 clusters. Isso reduzirá muito o número de clusters usados no disco e, portanto, o tempo gasto em leituras aleatórias. Mesmo se lermos toda a nossa nova tabela e compararmos os valores para encontrar o preço certo, no pior caso, serão necessários 250 saltos nos clusters da nova tabela. E depois de encontrar o endereço necessário, leremos outro cluster onde os dados completos estão localizados. Resultado: 251 leituras em relação ao 9750 original. A diferença é significativa.
Além disso, para pesquisar essa tabela, você pode usar, por exemplo, o algoritmo de pesquisa binária (já que a lista é classificada). Isso economizará ainda mais no número de leituras e operações de comparação.
Vamos chamar nossa segunda tabela de índice.
Hooray! Criamos nosso próprio índice de
Mas pare: conforme a tabela cresce, o índice também fica maior e maior e, eventualmente, voltaremos ao problema original. A pesquisa demorará novamente.
Outro índice
E se você criar outro índice em cima do existente?
Só que desta vez não anotaremos todos os valores do campo
price, mas associaremos um valor a uma página inteira (bloco) do índice. Ou seja, um nível adicional de índice aparecerá, que apontará para o conjunto de dados do índice anterior (a página no disco onde os dados do primeiro índice são armazenados).
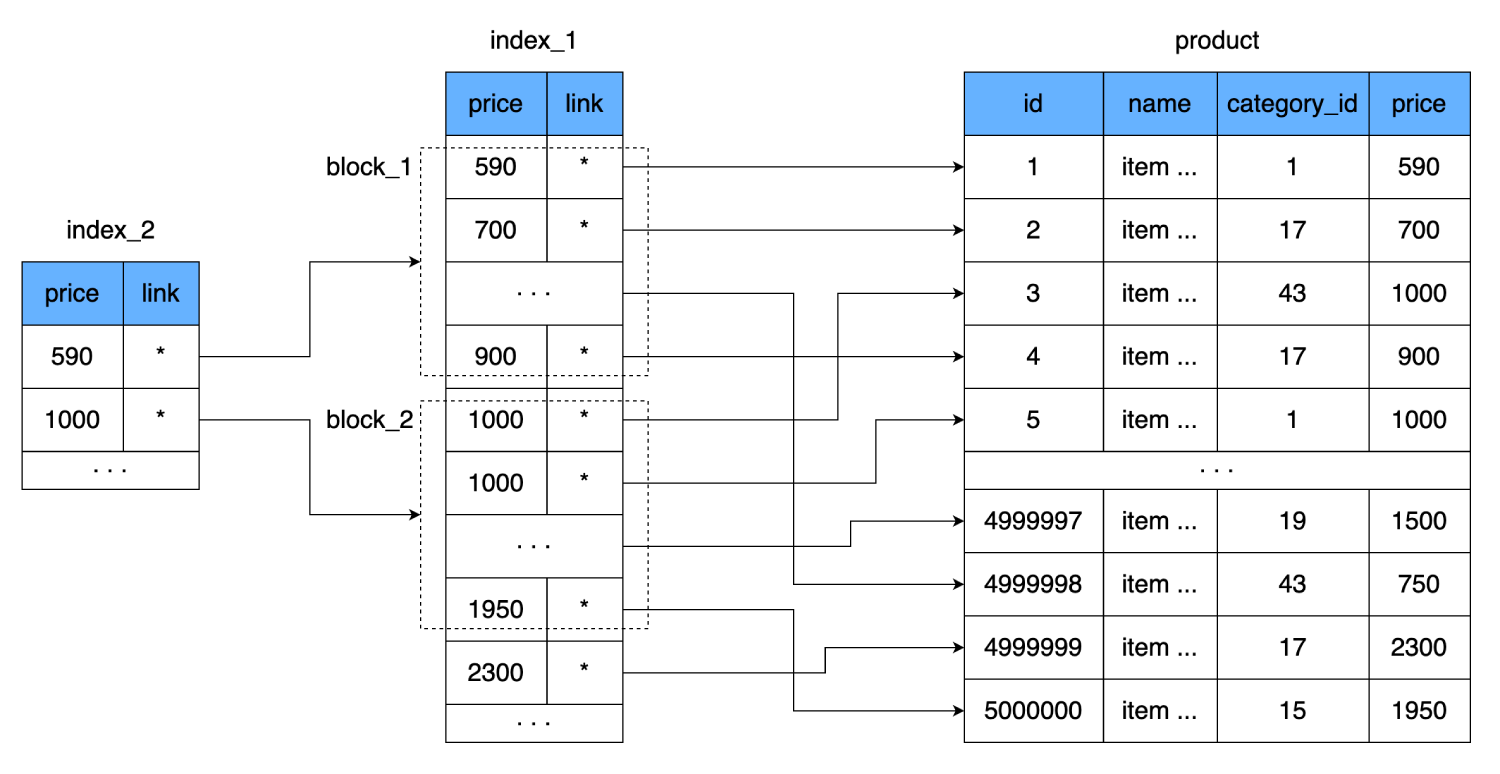
Isso reduzirá ainda mais o número de leituras. Uma linha do nosso índice ocupa 8 bytes, ou seja, podemos encaixar 2.000 linhas em uma página de 16 kilobytes. O novo índice conterá um link para o bloco de 2.000 linhas do primeiro índice e o preço a partir do qual este bloco começa. Uma dessas linhas também ocupa 8 bytes, mas seu número é reduzido drasticamente: em vez de 500.000, apenas 250. Eles até cabem em um cluster de disco rígido. Assim, para encontrar o preço requerido, seremos capazes de determinar exatamente em qual bloco de 2.000 linhas ele se encontra. E no pior caso, para encontrar o mesmo registro, nós:
- Vamos fazer uma leitura do novo índice.
- Depois de percorrer 250 linhas, encontramos um link para o bloco de dados do segundo índice.
- Considere um cluster que contém 2.000 linhas com preços e links para a tabela principal.
- Tendo verificado essas 2.000 linhas, encontraremos o salto necessário e mais uma vez no disco para ler o último bloco de dados.
Teremos um total de 3 saltos de cluster.
Mas, mais cedo ou mais tarde, esse nível também será preenchido com muitos dados. Portanto, teremos que repetir tudo o que fizemos, adicionando um novo nível continuamente. Ou seja, precisamos de uma estrutura de dados para armazenar o índice que adicionará novos níveis à medida que o tamanho do índice aumenta e equilibra independentemente os dados entre eles.
Se virarmos as tabelas de modo que o último índice fique no topo e a tabela principal com os dados embaixo, obteremos uma estrutura muito semelhante a uma árvore.
A estrutura de dados da árvore B funciona em um princípio semelhante, por isso foi escolhida para esses fins.
Árvores B em resumo
Os índices mais comuns usados no MySQL são índices ordenados de árvore B (árvore de pesquisa balanceada) .
A ideia geral de uma árvore B é semelhante às nossas tabelas de índice. Os valores são armazenados em ordem e todas as folhas da árvore estão à mesma distância da raiz.
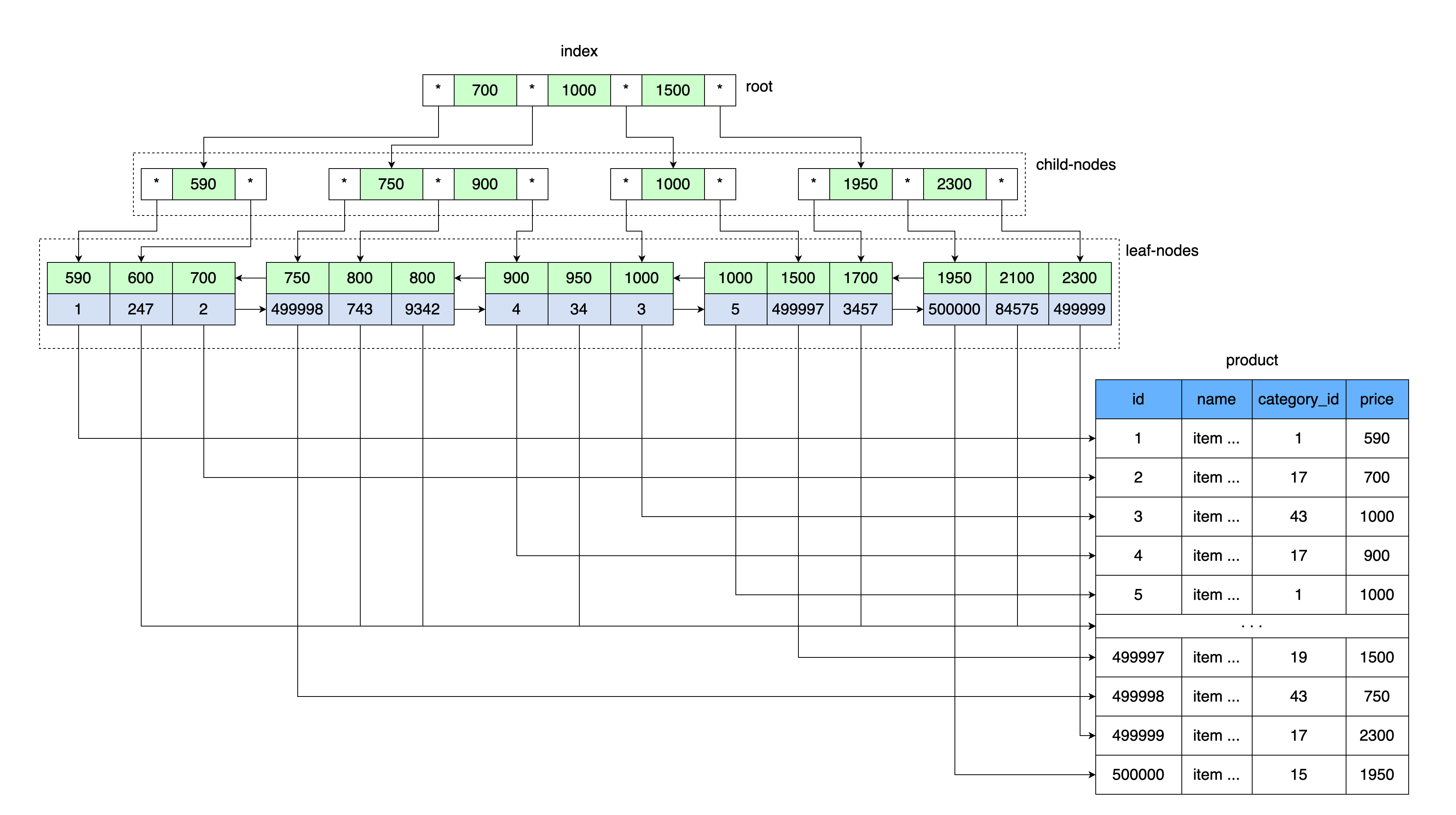
Assim como nossa tabela com um índice armazenou um valor de preço e um link para um bloco de dados, que contém uma faixa de valores com esse preço, também na raiz da árvore B são armazenados o valor do preço e um link para uma área de memória no disco.
Primeiro, a página que contém a raiz da árvore B é lida. Além disso, após inserir o intervalo de chaves, há um ponteiro para o nó filho desejado. A página do nó filho é lida, de onde o link para a planilha de dados é obtido do valor-chave e a página com os dados é lida deste link.
Árvore B no InnoDB
Mais especificamente, o InnoDB usa uma estrutura de dados em árvore B +.
Cada vez que você cria uma tabela, você cria automaticamente uma árvore B +, porque o MySQL armazena esse índice para as chaves primária e secundária.
As chaves secundárias armazenam adicionalmente os valores da chave primária (cluster) como uma referência à linha de dados. Consequentemente, a chave secundária aumenta com o tamanho do valor da chave primária.
Além disso, as árvores B + usam links adicionais entre nós filhos, o que aumenta a velocidade de pesquisa em uma faixa de valores. Leia mais sobre a estrutura dos índices de árvore b + no InnoDB aqui .
Resumindo
O índice b-tree oferece uma grande vantagem ao pesquisar dados em uma faixa de valores, devido a uma grande redução na quantidade de informações lidas do disco. Ele participa não apenas durante a pesquisa por condição, mas também durante as classificações, junções e agrupamentos. Leia como o MySQL usa índices aqui .
A maioria das consultas ao banco de dados são apenas consultas para localizar informações por valor ou por uma faixa de valores. Portanto, no MySQL, o índice mais comumente usado é um índice b-tree.
Além disso, o índice b-tree ajuda na recuperação de dados. Como a chave primária (índice clusterizado) e o valor da coluna na qual o índice não clusterizado é construído (chave secundária) são armazenados nas folhas do índice, você não pode mais acessar a tabela principal para esses dados e retirá-los do índice. Isso é chamado de índice de cobertura. Você pode encontrar mais informações sobre índices clusterizados e não clusterizados neste artigo .
Os índices, assim como as tabelas, também são armazenados no disco e ocupam espaço. Cada vez que você adiciona informações à tabela, o índice deve ser mantido atualizado, para monitorar a exatidão de todos os links entre os nós. Isso cria uma sobrecarga na gravação de informações, que é a principal desvantagem dos índices de árvore b. Sacrificamos a velocidade de gravação para aumentar a velocidade de leitura.
- MySQL . 3-
: ,
: 2018 - blog.jcole.us/innodb
- dev.mysql.com/doc/refman/8.0/en/innodb-storage-engine.html