Mas como funciona exatamente o Rastreamento de objetos? Existem muitas soluções de Aprendizado Profundo para esse problema, e hoje eu quero falar sobre uma solução comum e a matemática por trás dela.
Portanto, neste artigo, tentarei falar com palavras e fórmulas simples sobre:
- YOLO é um ótimo detector de objetos
- Filtros Kalman
- Distância de Mahalanobis
- SORT profundo
YOLO é um ótimo detector de objetos
Imediatamente você precisa fazer uma observação muito importante que você precisa lembrar - Detecção de Objetos não é Rastreamento de Objetos. Para muitos, isso não será novidade, mas muitas vezes as pessoas confundem esses conceitos. Em palavras simples:
Detecção de objeto é simplesmente a definição de objetos na imagem / moldura. Ou seja, um algoritmo ou rede neural define um objeto e registra sua posição e caixas delimitadoras (parâmetros de retângulos em torno dos objetos). Até agora, não se falou de outros quadros, e o algoritmo funciona com apenas um.
Exemplo: o
rastreamento de objetos é outra questão. Aqui, a tarefa não é apenas identificar objetos no quadro, mas também vincular informações de quadros anteriores de forma a não perder o objeto ou torná-lo único.
Exemplo:

Ou seja, o Rastreador de objetos inclui a detecção de objetos para determinar os objetos e outros algoritmos para entender qual objeto em um novo quadro pertence a qual do quadro anterior.
Portanto, a Detecção de objetos desempenha um papel muito importante na tarefa de rastreamento.
Por que YOLO? Sim, porque YOLO é considerado mais eficiente do que muitos outros algoritmos de identificação de objetos. Aqui está um pequeno gráfico para comparação dos criadores do YOLO:
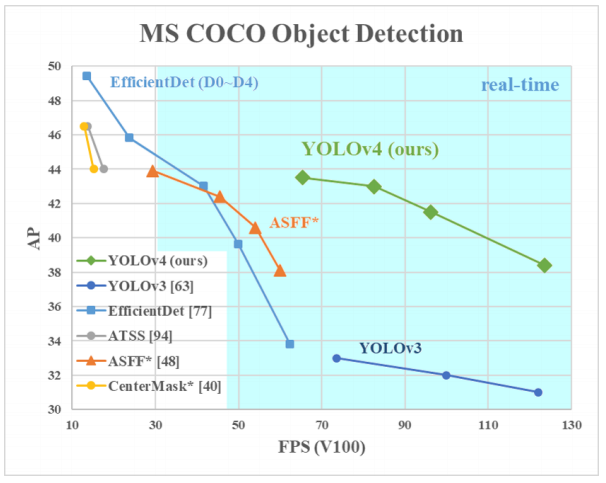
Aqui estamos olhando para o YOLOv3-4, pois são as versões mais recentes e são mais eficientes do que as anteriores.
Arquiteturas de diferentes detectores de objetos
Portanto, existem várias arquiteturas de rede neural projetadas para definir objetos. Eles são geralmente classificados em "duas camadas", como RCNN, RCNN rápido e RCNN mais rápido, e "camada única", como YOLO.
As redes neurais de "duas camadas" listadas acima usam as chamadas regiões na imagem para determinar se um objeto específico está nessa região.
Geralmente é assim (para um RCNN mais rápido, que é o mais rápido dos sistemas de duas camadas listados):
- A imagem / moldura é alimentada para a entrada
- O quadro é executado pela CNN para formar mapas de recursos
- Uma rede neural separada define regiões com alta probabilidade de encontrar objetos nelas
- Em seguida, usando o pool de RoI, essas regiões são compactadas e alimentadas na rede neural, que determina a classe do objeto nas regiões

Mas essas redes neurais têm dois problemas principais: elas não olham para o quadro completo, mas apenas para regiões individuais, e são relativamente lentas.
O que há de tão legal no YOLO? O fato de que esta arquitetura não tem dois problemas de cima, e ela provou repetidamente sua eficácia.
Em geral, a arquitetura YOLO nos primeiros blocos não difere muito em termos da "lógica de blocos" de outros detectores, ou seja, uma imagem é enviada para a entrada, em seguida, mapas de recursos são criados usando CNN (embora YOLO use seu próprio CNN chamado Darknet-53), então esses mapas de recursos são analisados de uma determinada maneira (mais sobre isso depois), dando as posições e tamanhos das caixas delimitadoras e as classes a que pertencem.

Mas o que são Pescoço, Predição Densa e Predição Esparsa?
Lidamos com a previsão esparsa um pouco antes - é apenas uma reiteração de como os algoritmos de duas camadas funcionam: eles definem regiões individualmente e, em seguida, classificam essas regiões.
O pescoço (ou "pescoço") é um bloco separado, criado para agregar informações de camadas separadas dos blocos anteriores (conforme mostrado na figura acima) para aumentar a precisão da previsão. Se estiver interessado nisso, você pode pesquisar no Google os termos "Rede de agregação de caminhos", "Módulo de atenção espacial" e "Pooling da pirâmide espacial".
E, finalmente, o que distingue o YOLO de todas as outras arquiteturas é um bloco chamado (em nossa imagem acima) Predição Densa. Vamos nos concentrar um pouco mais nisso, pois se trata de uma solução muito interessante, que só permitiu ao YOLO entrar na liderança em eficiência de detecção de objetos.
YOLO (You Only Look Once) segue a filosofia de olhar para a imagem uma vez e, para essa visão (isto é, uma passagem da imagem por uma rede neural), fazer todas as definições de objeto necessárias. Como isso acontece?
Então, ao sair do trabalho do YOLO, geralmente queremos isso:
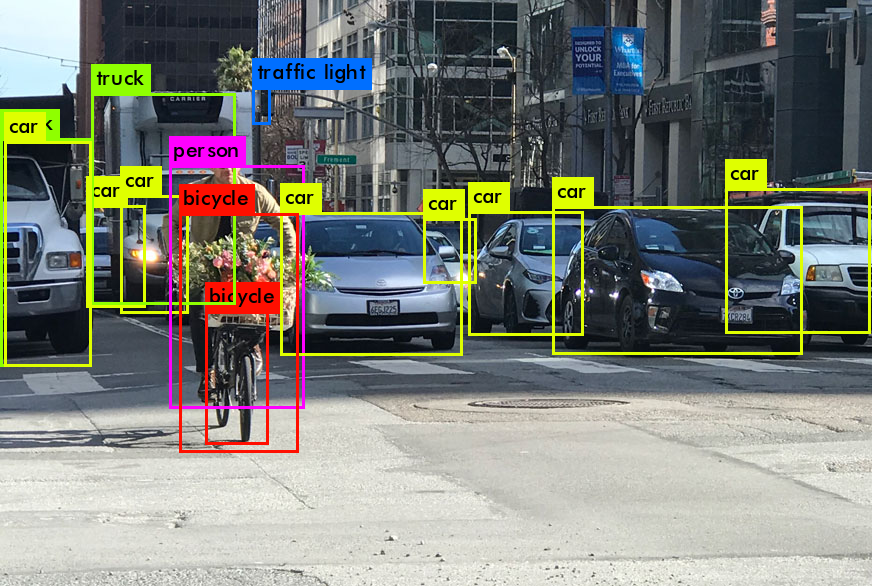
O que o YOLO faz quando aprende com os dados (em palavras simples):
Etapa 1: Normalmente, as imagens serão remodeladas para um tamanho de 416x416 antes de treinar a rede neural para que possam ser alimentadas em lotes (para acelerar o aprendizado )
Passo 2: Divida a imagem (por enquanto mentalmente) em células de tamanho a x a . No YOLOv3-4, costuma-se dividir em células de tamanho 13x13 (falaremos sobre diferentes escalas um pouco mais tarde para tornar isso mais claro).

Agora vamos nos concentrar nessas células nas quais dividimos a imagem / quadro. Essas células, chamadas células de grade, estão no cerne da ideia YOLO. Cada célula é uma "âncora" à qual as caixas delimitadoras são anexadas. Ou seja, vários retângulos são desenhados ao redor da célula para definir o objeto (uma vez que não está claro qual forma o retângulo será mais adequado, eles são desenhados ao mesmo tempo em várias e diferentes formas), e suas posições, largura e altura são calculadas em relação ao centro desta célula.
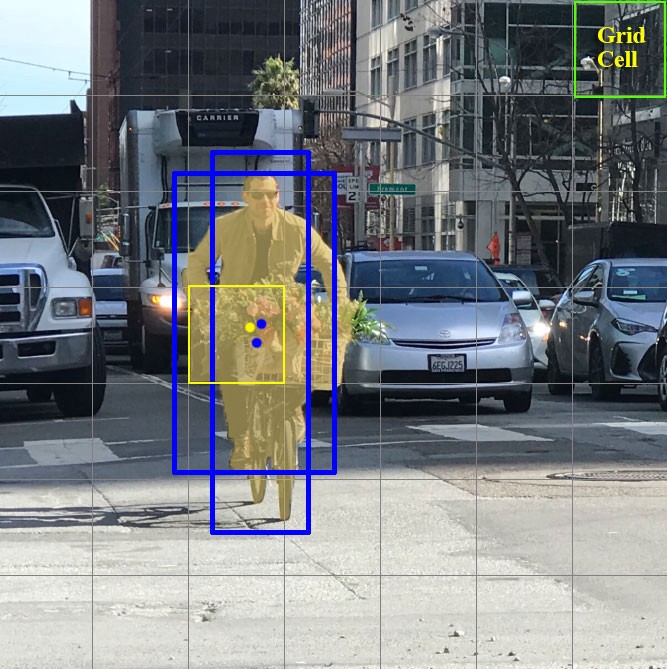
Como essas caixas delimitadoras são desenhadas ao redor da gaiola? Como seu tamanho e posição são determinados? É aqui que a técnica das caixas de âncora (na tradução - caixas de âncora ou "retângulos de âncora") entra em ação. Eles são definidos no início pelo próprio usuário ou seus tamanhos são determinados com base nos tamanhos das caixas delimitadoras que estão no conjunto de dados no qual o YOLO será treinado (agrupamento K-means e IoU são usados para determinar os tamanhos mais apropriados). Normalmente, existem 3 caixas de âncora diferentes a serem desenhadas ao redor (ou dentro) de uma célula:

Por que isso é feito? Ficará claro agora ao discutirmos como o YOLO aprende.
Etapa 3. A imagem do conjunto de dados é executada em nossa rede neural (observe que, além da imagem no conjunto de dados de treinamento, devemos ter as posições e tamanhos das caixas delimitadoras reais para os objetos nele. Isso é chamado de "anotação" e é feito principalmente manualmente )
Agora vamos pensar sobre o que precisamos para obter a saída.
Para cada célula, precisamos entender duas coisas fundamentais:
- Qual das 3 caixas de âncora desenhadas ao redor da gaiola se adapta melhor a nós, e como podemos ajustá-la um pouco para que se encaixe bem no objeto
- Que objeto está dentro desta caixa de âncora e está lá
Qual deve ser o resultado do YOLO?
1. Na saída de cada célula, queremos obter:

2. A saída deve incluir os seguintes parâmetros:
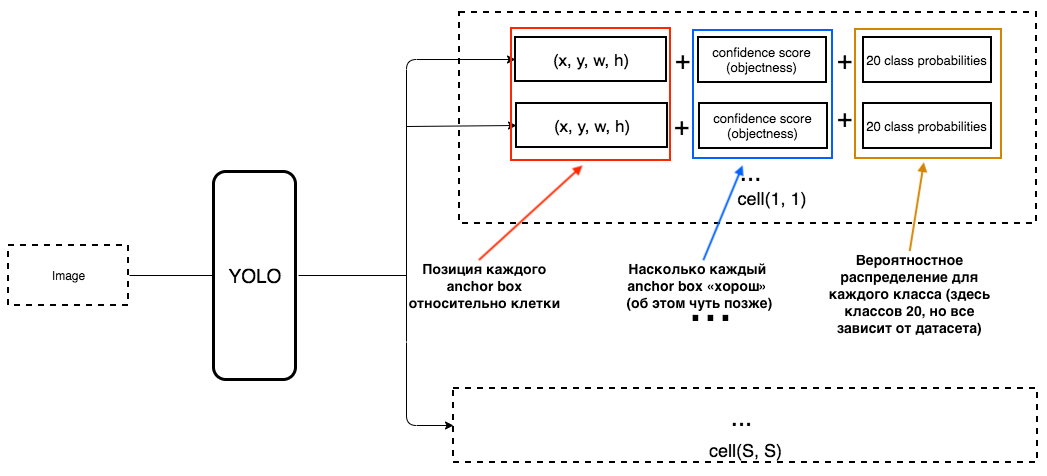
Como a objetividade é determinada? Na verdade, esse parâmetro é determinado usando a métrica IoU durante o treinamento. A métrica IoU funciona assim:
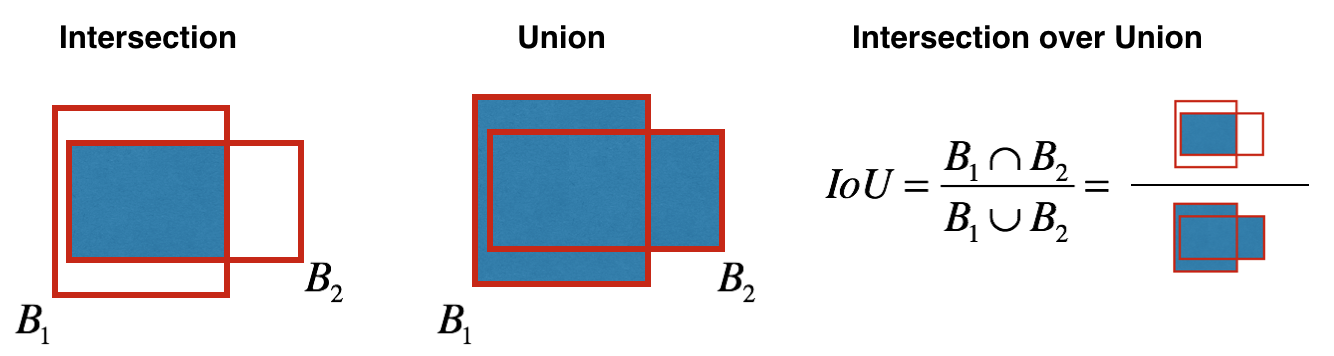
no início, você pode definir um limite para essa métrica e, se sua caixa delimitadora prevista estiver acima desse limite, ela terá objetividade igual a um, e todas as outras caixas delimitadoras com objetividade inferior serão excluídas. Precisaremos desse valor de objetividade quando calcularmos a pontuação de confiança geral (até que ponto temos certeza de que este é o objeto de que precisamos está localizado dentro do retângulo previsto) para cada objeto específico.
E agora a diversão começa. Vamos imaginar que somos os criadores do YOLO e precisamos treiná-la para reconhecer as pessoas no quadro / imagem. Alimentamos a imagem do conjunto de dados para o YOLO, onde a extração de recursos ocorre no início e, no final, obtemos uma camada CNN que nos informa sobre todas as células nas quais "dividimos" nossa imagem. E se essa camada nos diz uma "mentira" sobre as células da imagem, então devemos ter uma grande perda, para que mais tarde ela possa ser reduzida quando as imagens a seguir forem alimentadas na rede neural.
Para ser claro, há um diagrama muito simples de como o YOLO cria essa última camada:
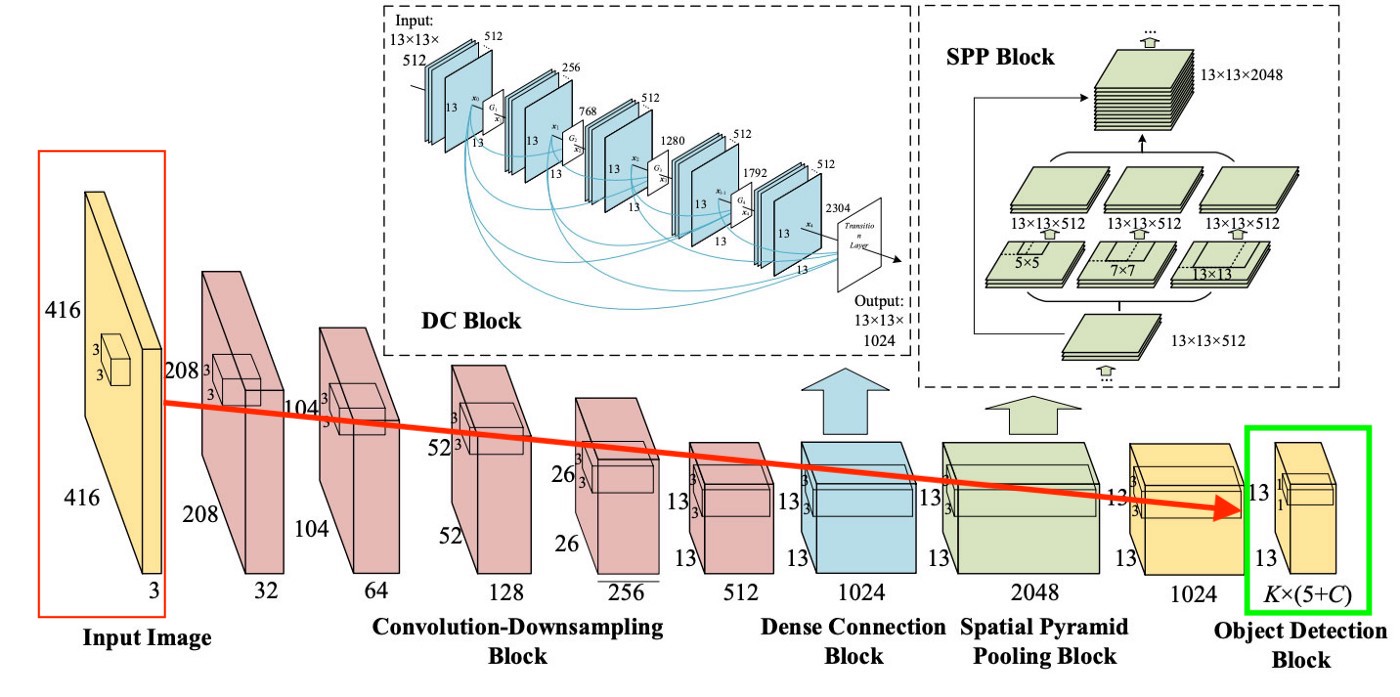
Como podemos ver na foto, essa camada é 13x13 (para fotos, o tamanho original é 416x416) para falar sobre "cada célula" na foto. Desta última camada, são obtidas as informações que desejamos.
YOLO prevê 5 parâmetros (para cada caixa de âncora para uma célula específica):

Para facilitar o entendimento, há uma boa visualização neste tópico:

Como você pode entendê-los a partir desta imagem, a tarefa do YOLO é prever esses parâmetros com a maior precisão possível, a fim de determinar o objeto na imagem com a maior precisão possível. E a pontuação de confiança, que é determinada para cada caixa delimitadora prevista, é uma espécie de filtro para filtrar previsões totalmente imprecisas. Para cada caixa delimitadora prevista, multiplicamos sua IoU pela probabilidade de que este seja um certo objeto (a distribuição de probabilidade é calculada durante o treinamento da rede neural), pegamos a melhor probabilidade de todas as possíveis e se o número após a multiplicação exceder um certo limite, então podemos deixar isso previsto caixa delimitadora na imagem.
Além disso, quando temos apenas caixas delimitadoras previstas com uma pontuação de alta confiança, nossas previsões (se visualizadas) podem ser mais ou menos assim:

Agora podemos usar a técnica NMS (supressão não máxima) para filtrar as caixas delimitadoras de tal forma que por de um objeto, havia apenas uma caixa delimitadora prevista.

Você também deve saber que YOLOv3-4 é previsto em 3 escalas diferentes. Ou seja, a imagem é dividida em 64 células de grade, 256 células e 1024 células para ver também pequenos objetos. Para cada grupo de células, o algoritmo repete as ações necessárias durante a predição / aprendizagem, que foram descritas acima.
Muitas técnicas foram usadas no YOLOv4 para aumentar a precisão do modelo sem perder muita velocidade. Mas, para a previsão em si, a Predição Densa foi mantida igual ao YOLOv3. Se você está interessado no que os autores fizeram de forma mágica para aumentar a precisão sem perder velocidade, há um excelente artigo escrito sobre o YOLOv4 .
Espero ter conseguido transmitir um pouco sobre como funciona o YOLO em geral (mais precisamente, as duas últimas versões, ou seja, YOLOv3 e YOLOv4), e isso despertará em você o desejo de usar este modelo no futuro, ou aprender um pouco mais sobre seu trabalho.
Agora que descobrimos qual é talvez a melhor rede neural para Detecção de Objetos (em termos de velocidade / qualidade), vamos finalmente passar a como podemos associar informações sobre nossos objetos YOLO específicos entre quadros de vídeo. Como o programa pode entender que a pessoa no quadro anterior é a mesma pessoa do novo?
SORT profundo
Para entender essa tecnologia, você deve primeiro entender alguns aspectos matemáticos - distância de Mahalonobis e filtro de Kalman.
Distância de Mahalonobis Vamos
considerar um exemplo muito simples para compreender intuitivamente o que é a distância de Maholonobis e por que ela é necessária. Muitas pessoas provavelmente sabem o que é a distância euclidiana. Normalmente, essa é a distância de um ponto a outro no espaço euclidiano:
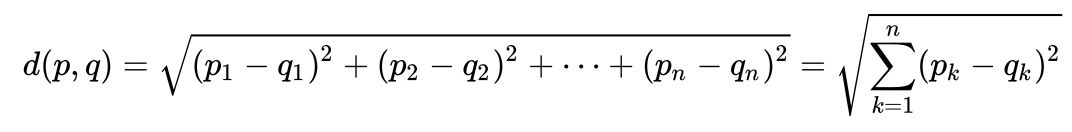

Digamos que temos duas variáveis - X1 e X2. Para cada um deles, temos muitas dimensões.
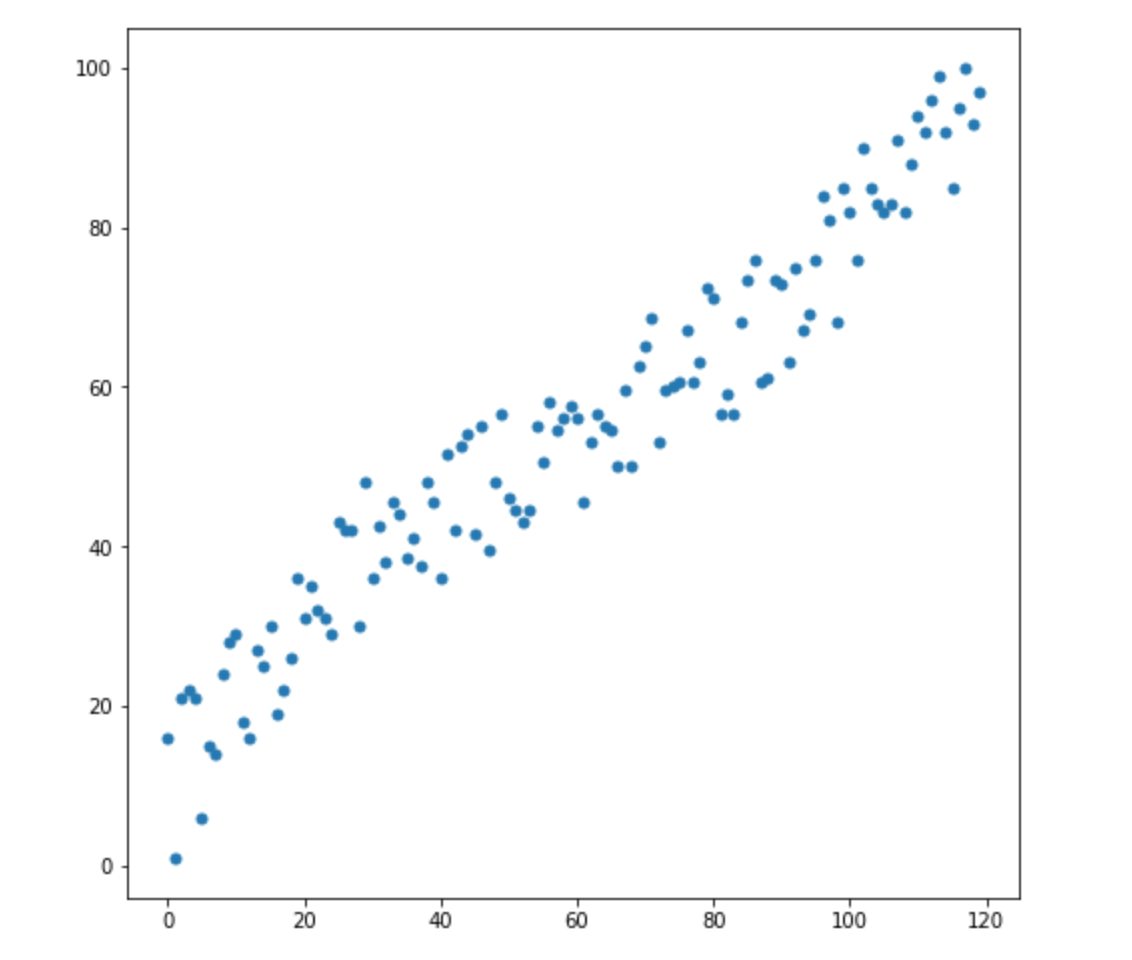
Agora, digamos que temos 2 novas dimensões:
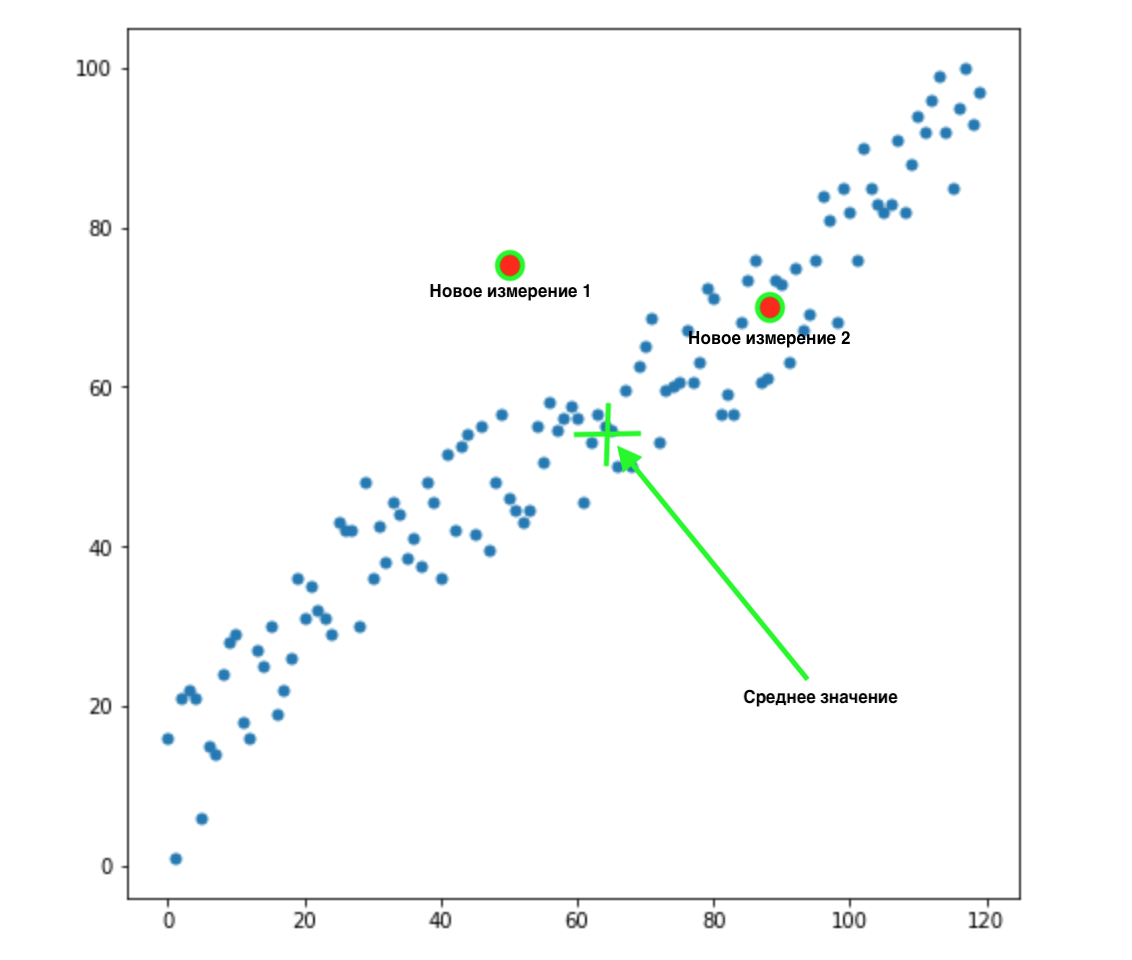
Como sabemos qual desses dois valores é o mais apropriado para nossa distribuição? Tudo é óbvio à vista - o ponto 2 é adequado para nós. Mas a distância euclidiana à média é a mesma para ambos os pontos. Conseqüentemente, uma simples distância euclidiana da média não funcionará para nós.
Como podemos ver na imagem acima, as variáveis estão correlacionadas entre si e de forma bastante forte. Se eles não se correlacionassem entre si, ou se correlacionassem muito menos, poderíamos fechar os olhos e aplicar a distância euclidiana para certas tarefas, mas aqui precisamos corrigir a correlação e levá-la em consideração.
Isso é exatamente o que a distância de Mahalonobis pode suportar. Uma vez que geralmente existem mais de duas variáveis em conjuntos de dados, usaremos uma matriz de covariância em vez de correlação:
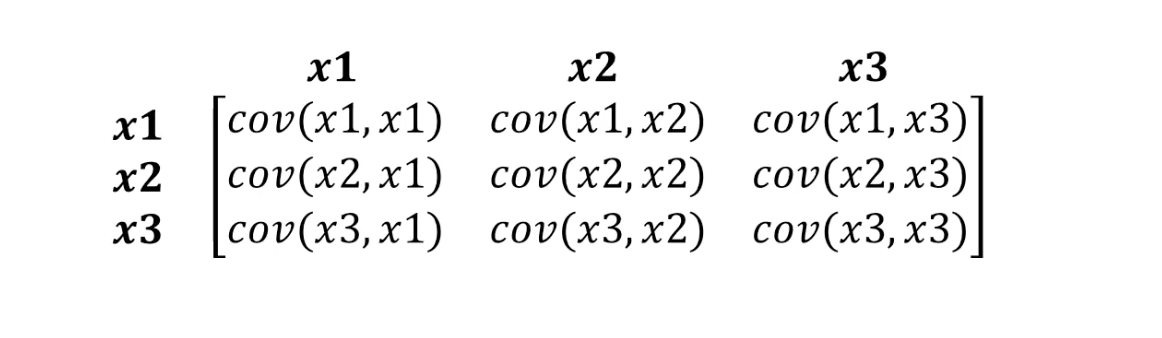
O que a distância de Mahalonobis realmente faz:
- Livre-se da covariância variável
- Torna a variância das variáveis igual a 1
- Em seguida, ele usa a distância euclidiana usual para os dados transformados.
Vejamos a fórmula de como a distância de Mahalonobis é calculada:

Vamos ver o que significam os componentes de nossa fórmula:
- Essa diferença é a diferença entre nosso novo ponto e as médias de cada variável.
- S é a matriz de covariância de que falamos um pouco antes.
Uma coisa muito importante pode ser compreendida a partir da fórmula. Na verdade, estamos multiplicando pela matriz de covariância invertida. Nesse caso, quanto maior a correlação entre as variáveis, maior a probabilidade de encurtarmos a distância, pois multiplicaremos pelo inverso do maior - ou seja, o número menor (se em palavras simples).
Provavelmente não entraremos nos detalhes da álgebra linear, tudo o que precisamos entender é que medimos a distância entre os pontos de forma a levar em consideração a variância de nossas variáveis e a covariância entre elas.
Filtro de Kalman
Para perceber que se trata de uma coisa legal, comprovada, que pode ser aplicada em tantas áreas, basta saber que o filtro de Kalman foi usado na década de 1960. Sim, sim, estou sugerindo isso - o vôo para a lua. Tem sido aplicado lá em vários lugares, inclusive trabalhando com trajetórias de voos de ida e volta. O filtro de Kalman também é frequentemente usado em análises de séries temporais em mercados financeiros, na análise de indicadores de vários sensores em fábricas, empresas e muitos outros lugares. Espero ter intrigado você um pouco e iremos descrever brevemente o filtro de Kalman e como ele funciona. Também aconselho a leitura deste artigo sobre Habré se quiser saber mais sobre ele.
Filtro de Kalman
, . , , .
, . 4 . , 72 .
3 :
1) (Kalman Gain):

, - ( ).
2) , ( , ), , .

3) (), :
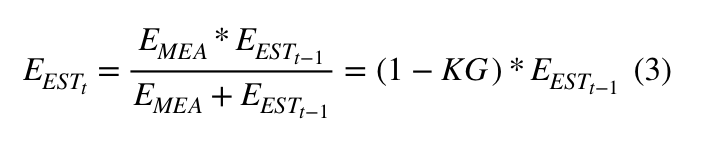
, :
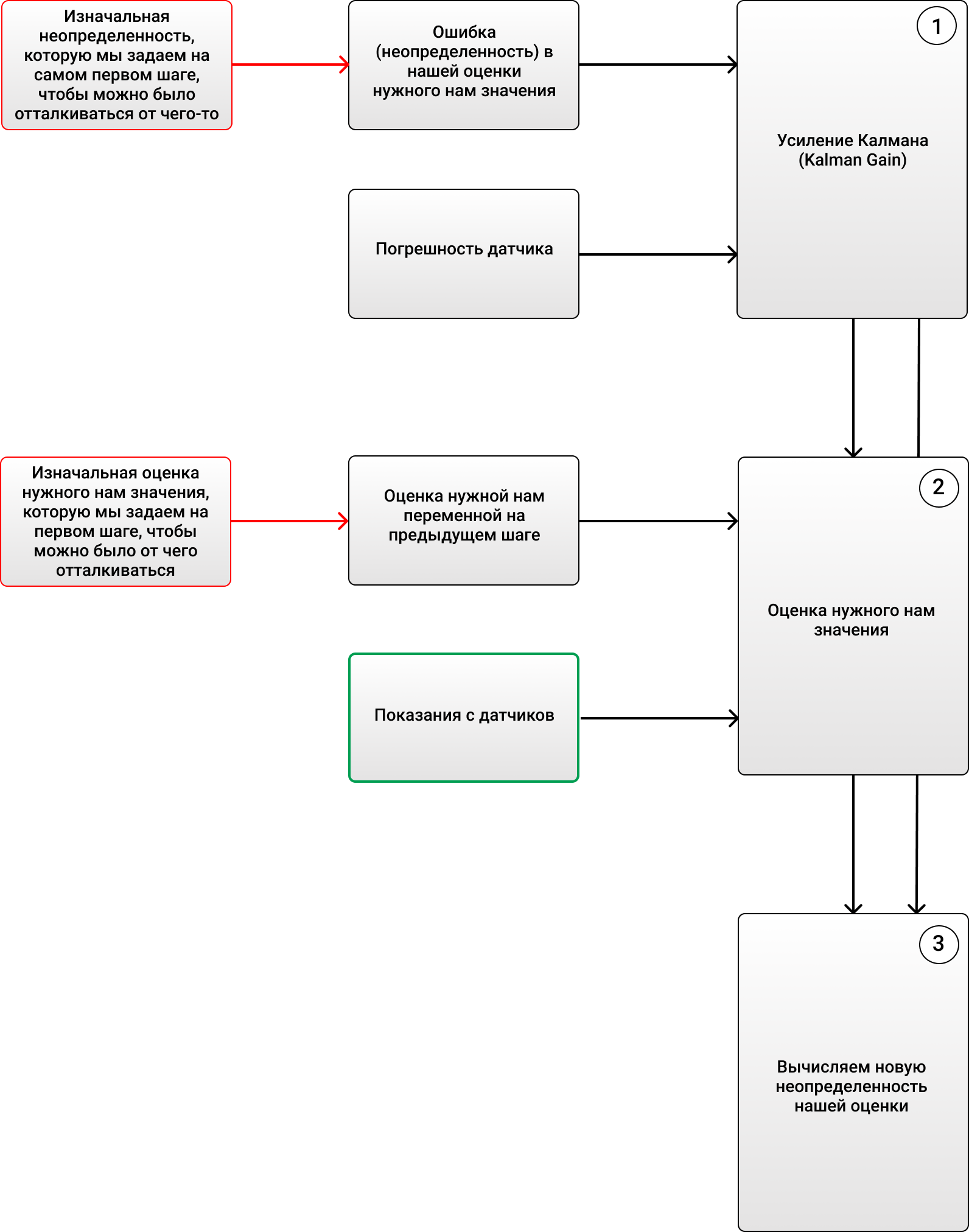
, 69 ( ), 2 . , , 4 (, , ), KG (1) 2/(2+4) = 0.33. ( ), . 70 (), . (2), , 68+0.33(70-68)=68.66. (3) (1-0.33)2 = 1.32. , , , . :
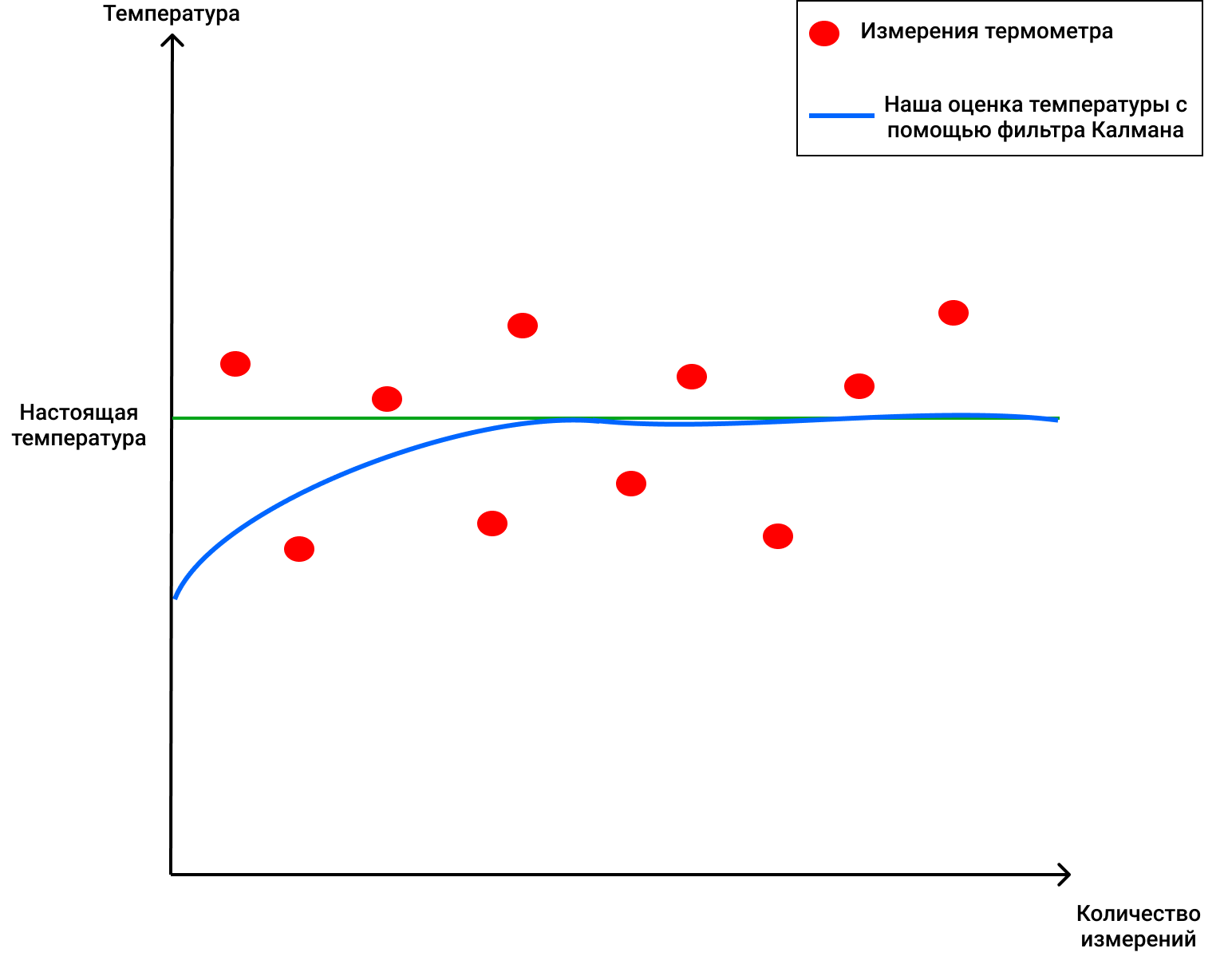
, !
, , , , , ( , ).
, . 4 . , 72 .
3 :
1) (Kalman Gain):
, - ( ).
2) , ( , ), , .
3) (), :
, :
, 69 ( ), 2 . , , 4 (, , ), KG (1) 2/(2+4) = 0.33. ( ), . 70 (), . (2), , 68+0.33(70-68)=68.66. (3) (1-0.33)2 = 1.32. , , , . :
, !
, , , , , ( , ).
DeepSORT - finalmente!
Portanto, agora sabemos quais são o filtro de Kalman e a distância de Mahalonobis. A tecnologia DeepSORT simplesmente vincula esses dois conceitos para transferir informações de um quadro para outro e adiciona uma nova métrica chamada aparência. Primeiro, usando a detecção de objetos, a posição, o tamanho e a classe de uma caixa delimitadora são determinados. Então você pode, em princípio, aplicar o algoritmo húngaro para associar certos objetos a IDs de objeto que estavam anteriormente no quadro e rastreados usando filtros de Kalman - e tudo ficará super, como no SORT original... Mas a tecnologia DeepSORT permite melhorar a precisão da detecção e reduzir o número de trocas entre objetos, quando, por exemplo, uma pessoa no quadro obstrui brevemente outra, e agora a pessoa que foi obstruída é considerada um novo objeto. Como ela faz isso?
Ela adiciona um elemento legal ao seu trabalho - a chamada "aparência" das pessoas que aparecem no quadro (aparência). Essa aparência foi treinada por uma rede neural separada que foi criada pelos autores do DeepSORT. Eles usaram cerca de 1.100.000 fotos de mais de 1.000 pessoas diferentes para fazer a rede neural prever corretamenteO SORT original tem um problema - uma vez que a aparência do objeto não é usada lá, então, de fato, quando o objeto cobre algo por vários frames (por exemplo, outra pessoa ou uma coluna dentro de um edifício), o algoritmo então atribui outro ID a essa pessoa - como resultado em que a chamada "memória" de objetos no SORT original tem vida curta.
Portanto, agora os objetos têm duas propriedades - sua dinâmica de movimento e sua aparência. Para dinâmica, temos indicadores que são filtrados e previstos usando o filtro de Kalman - (u, v, a, h, u ', v', a ', h'), onde u, v é a posição X do retângulo previsto e Y, a é a proporção do retângulo previsto, h é a altura do retângulo e as derivadas em relação a cada valor. Para aparência, foi treinada uma rede neural, que tinha a estrutura:
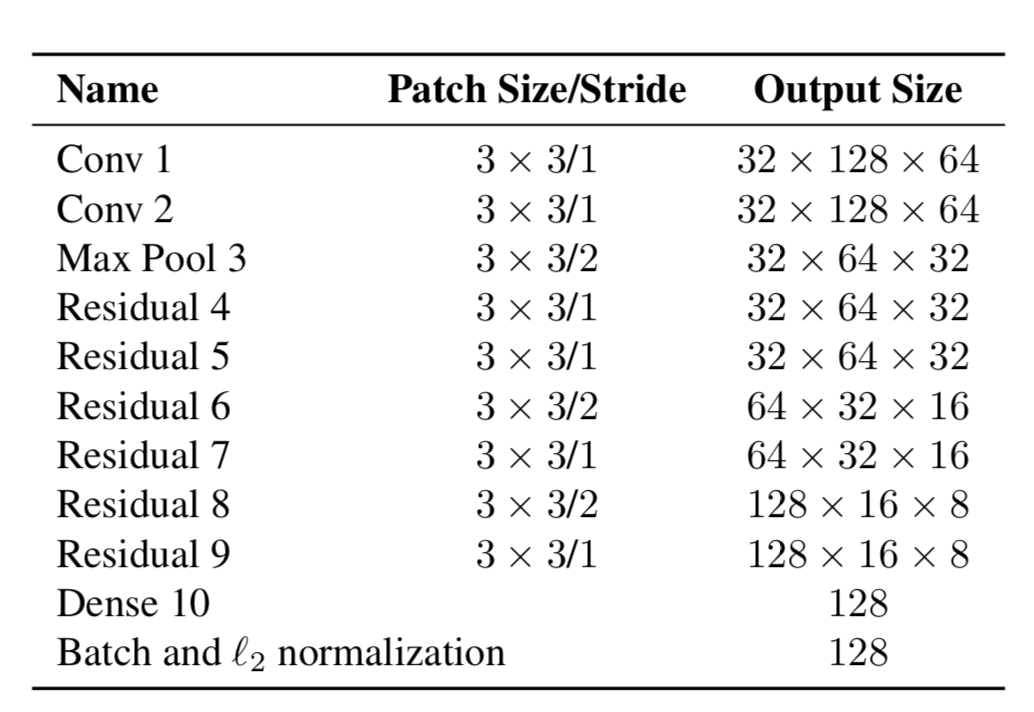
E no final produziu um vetor de recursos, 128x1 de tamanho. E então, ao invés de calcular a distância entre certos objetos usando YOLO, e objetos que já seguíamos no quadro, e então atribuir um certo ID simplesmente usando a distância de Mahalonobis, os autores criaram uma nova métrica para calcular a distância, que inclui ambas as previsões usando filtros de Kalman, e "distância cosseno", como é chamado, o coeficiente de Otiai.
Como resultado, a distância de um determinado objeto YOLO ao objeto predito pelo filtro de Kalman (ou um objeto que já está entre aqueles que foram observados nos quadros anteriores) é:

Onde Da é a distância de similaridade externa e Dk é a distância de Mahalonobis. Além disso, essa distância híbrida é usada no algoritmo húngaro para classificar corretamente certos objetos com IDs existentes.
Assim, uma métrica adicional simples Da ajudou a criar um algoritmo DeepSORT novo e elegante que é usado em muitos problemas e é bastante popular no problema de Rastreamento de Objeto.
O artigo acabou tendo bastante peso, graças a quem leu até o fim! Espero ter sido capaz de dizer algo novo e ajudá-lo a entender como o Rastreamento de Objetos funciona no YOLO e DeepSORT.