Toda a implementação em um arquivo .h de cabeçalho: [fast_mem_pool.h]
Chips, porque este alocador é melhor do que centenas de outros semelhantes - sob o corte.
É assim que minha bicicleta funciona.
1) Na versão Release, não há mutexes e nenhum ciclo de espera para o atômico - mas o alocador é cíclico e regenera recursos continuamente conforme eles são liberados por threads. Como ele faz isso?
Cada alocação de RAM que FastMemPool fornece via fmalloc é, na verdade, mais para um cabeçalho:
struct AllocHeader {
// : tag_this = this + leaf_id
uint64_t tag_this { 2020071700 };
// :
int size;
// :
int leaf_id { -2020071708 };
};
Este cabeçalho pode sempre ser obtido a partir do ponteiro pertencente ao usuário retrocedendo a partir do ponteiro (res_ptr) sizeof (AllocHeader):

Pelo conteúdo do cabeçalho AllocHeader, o método ffree (void * ptr) reconhece suas alocações e descobre em qual das folhas da memória do buffer circular é retornada :
void ffree(void *ptr)
{
char *to_free = static_cast<char *>(ptr)
- sizeof(AllocHeader);
AllocHeader *head = reinterpret_cast<AllocHeader *>(to_free);
Quando o alocador é solicitado a alocar memória, ele examina a folha atual da matriz de folhas para ver se pode cortar o tamanho necessário + o tamanho do cabeçalho sizeof (AllocHeader).
No alocador, as folhas de memória Leaf_Cnt são reservadas com antecedência, cada folha do tamanho Leaf_Size_Bytes (tudo é tradicional aqui). Em busca de uma oportunidade de alocação, o método fmalloc (std :: size_t alocação_size) circulará pelas folhas da matriz leaf_array, e se tudo estiver ocupado em todos os lugares, desde que o sinalizador Do_OS_malloc esteja habilitado, ele tirará memória do sistema operacional maior do que o tamanho exigido por sizeof (AllocHeader) - fora a memória é retirada do buffer circular interno ou do sistema operacional, o alocador sempre cria um cabeçalho com informações de serviço. Se o alocador ficar sem memória e o sinalizador Do_OS_malloc == falso, então fmalloc retornará nullptr - este comportamento é útil para controlar a carga (por exemplo, pular quadros de uma câmera de vídeo quando os módulos de processamento de quadros não acompanharem o FPS da câmera).
Como o ciclismo é implementado
Alocadores cíclicos são projetados para tarefas cíclicas - as tarefas não precisam durar para sempre. Por exemplo, pode ser:
- alocações para sessões de usuário
- processamento de frames de stream de vídeo para análise de vídeo
- a vida das unidades de combate no jogo
Uma vez que pode haver qualquer número de folhas de memória no array leaf_array, no limite é possível fazer uma página para o número teoricamente possível de unidades de combate no jogo, portanto, com a condição de unidades caindo, temos a garantia de obter uma folha de memória livre. Na prática, para análise de vídeo, 16 folhas grandes geralmente são suficientes para mim, das quais as primeiras folhas são doadas para alocações não cíclicas de longo prazo quando o detector é inicializado.
Como a segurança de thread é implementada
Uma série de planilhas de alocação funciona sem mutexes ... A proteção contra erros do tipo "data race" é feita da seguinte forma:
char *buf;
// available == offset
std::atomic<int> available { Leaf_Size_Bytes };
// allocated ==
std::atomic<int> deallocated { 0 };
Cada folha de memória possui 2 contadores:
- disponível inicializado pelo tamanho de Leaf_Size_Bytes. Com cada alocação, este contador diminui, e o mesmo contador serve como um deslocamento em relação ao início da folha de memória == a memória é alocada a partir do final do buffer:
result_ptr = leaf_array[leaf_id].buf + available_after;
- desalocado é inicializado {0} para zero, e com cada desalocação nesta planilha (eu aprendo com AllocHeader em qual planilha ou sistema operacional o negócio está sendo tratado) o contador é aumentado pelo volume liberado:
const int deallocated = leaf_array[head->leaf_id].deallocated.fetch_add(real_size, std::memory_order_acq_rel) + real_size;
Assim que os contadores como este (desalocado == (Leaf_Size_Bytes - disponível)) coincidirem, isso significa que tudo que foi alocado agora é liberado e você pode redefinir a planilha para seu estado original, mas aqui está um ponto sutil: o que acontecerá se após a decisão de redefinir a planilha de volta ao original, alguém aloca outro pequeno pedaço de memória da planilha ... Para excluir isso, use a verificação compare_exchange_strong:
if (deallocated == (Leaf_Size_Bytes - available))
{ // ,
// , , Leaf
if (leaf_array[head->leaf_id].available
.compare_exchange_strong(available, Leaf_Size_Bytes))
{
leaf_array[head->leaf_id].deallocated -= deallocated;
}
}
A folha de memória é reposta ao seu estado original apenas se no momento da reposição permanecer o mesmo estado do contador disponível, que era no momento da decisão. Ta-daa !!!
Um bom bônus é que você pode detectar os seguintes bugs usando o cabeçalho AllocHeader de cada alocação:
- redealocação
- desalocação da memória de outra pessoa
- estouro de buffer
- acesso à área de memória de outra pessoa
O segundo recurso é implementado nessas oportunidades.
2) A compilação de Debug fornece as informações exatas onde a desalocação anterior ocorreu durante a redalocação: nome do arquivo, número da linha de código, nome do método. Isso é implementado na forma de decoradores em torno dos métodos básicos (fmallocd, ffreed, check_accessd - a versão de depuração dos métodos tem um d no final):
/**
* @brief FFREE - free
* @param iFastMemPool - FastMemPool
* @param ptr - fmaloc
*/
#if defined(Debug)
#define FFREE(iFastMemPool, ptr) \
(iFastMemPool)->ffreed (__FILE__, __LINE__, __FUNCTION__, ptr)
#else
#define FFREE(iFastMemPool, ptr) \
(iFastMemPool)->ffree (ptr)
#endif
As macros do pré-processador são usadas:
- __FILE__ - arquivo de origem c ++
- __LINE__ - número da linha no arquivo de origem c ++
- __FUNCTION__ - o nome da função onde isso aconteceu
Essas informações são armazenadas como uma correspondência entre o ponteiro de alocação e as informações de alocação no mediador:
struct AllocInfo {
// : , , :
std::string who;
// true - , false - :
bool allocated { false };
};
std::map<void *, AllocInfo> map_alloc_info;
std::mutex mut_map_alloc_info;
Como a velocidade não é tão importante para depuração, um mutex foi usado para proteger o std :: map padrão. O parâmetro do modelo (bool Raise_Exeptions = DEF_Raise_Exeptions) afeta o lançamento de uma exceção em caso de erro.
Para aqueles que desejam o máximo de conforto na versão Release, você pode definir o sinalizador DEF_Auto_deallocate, então todas as alocações do OS malloc serão gravadas (já sob o mutex em std :: set <>) e liberadas no destruidor FastMemPool (usado como um rastreador de alocação).
3)Para evitar erros como "estouro de buffer", recomendo usar a verificação FastMemPool :: check_access antes de começar a trabalhar com a memória alocada. Enquanto o sistema operacional só reclama quando você entra na RAM de outra pessoa, a função check_access (ou a macro FCHECK_ACCESS) calcula pelo cabeçalho AllocHeader se haverá uma saturação da alocação fornecida:
/**
* @brief check_access -
* @param base_alloc_ptr - FastMemPool
* @param target_ptr -
* @param target_size - ,
* @return - true FastMemPool
*/
bool check_access(void *base_alloc_ptr, void *target_ptr, std::size_t target_size)
// :
if (FCHECK_ACCESS(fastMemPool, elem.array,
&elem.array[elem.array_size - 1], sizeof (int)))
{
elem.array[elem.array_size - 1] = rand();
}
Conhecendo o ponteiro da alocação inicial, você sempre pode obter o cabeçalho, a partir do cabeçalho descobrimos o tamanho da alocação, e então calculamos se o elemento de destino estará dentro da alocação inicial. Basta verificar uma vez antes de iniciar o ciclo de processamento no máximo de acessos teoricamente possíveis. Pode muito bem ser que os valores limite ultrapassem os limites de alocação (por exemplo, nos cálculos, presume-se que alguma variável só pode andar em um determinado intervalo devido à física do processo e, portanto, você não verifica se há quebra de limite de alocação).
É melhor verificar uma vez do que matar uma semana depois à procura de alguém que ocasionalmente grava dados aleatórios em suas estruturas ...
4) Definir o código do modelo padrão em tempo de compilação via CMake.
CmakeLists.txt contém parâmetros configuráveis, por exemplo:
set(DEF_Leaf_Size_Bytes "65536" CACHE PATH "Size of each memory pool leaf")
message("DEF_Leaf_Size_Bytes: ${DEF_Leaf_Size_Bytes}")
set(DEF_Leaf_Cnt "16" CACHE PATH "Memory pool leaf count")
message("DEF_Leaf_Cnt: ${DEF_Leaf_Cnt}")
Isso torna muito conveniente editar os parâmetros no QtCreator:

ou CMake GUI:

Além disso, os parâmetros são passados para o código durante a compilação da seguinte forma:
set(SPEC_DEFINITIONS
${CMAKE_SYSTEM_NAME}
${CMAKE_BUILD_TYPE}
${SPEC_BUILD}
SPEC_VERSION="${Proj_VERSION}"
DEF_Leaf_Size_Bytes=${DEF_Leaf_Size_Bytes}
DEF_Leaf_Cnt=${DEF_Leaf_Cnt}
DEF_Average_Allocation=${DEF_Average_Allocation}
DEF_Need_Registry=${DEF_Need_Registry}
)
#
target_compile_definitions(${TARGET} PUBLIC ${TARGET_DEFINITIONS})
e no código substituem os valores do modelo em Padrão:
#ifndef DEF_Leaf_Size_Bytes
#define DEF_Leaf_Size_Bytes 65535
#endif
template<int Leaf_Size_Bytes = DEF_Leaf_Size_Bytes,
int Leaf_Cnt = DEF_Leaf_Cnt,
int Average_Allocation = DEF_Average_Allocation,
bool Do_OS_malloc = DEF_Do_OS_malloc,
bool Need_Registry = DEF_Need_Registry,
bool Raise_Exeptions = DEF_Raise_Exeptions>
class FastMemPool
{
// ..
};
Assim, o modelo de alocador pode ser ajustado confortavelmente com o mouse ativando / desativando as caixas de seleção dos parâmetros CMake.
5) Para poder usar o alocador em contêineres STL no mesmo arquivo .h, os recursos de std :: allocator são parcialmente implementados no modelo FastMemPoolAllocator:
// compile time :
std::unordered_map<int, int, std::hash<int>,
std::equal_to<int>,
FastMemPoolAllocator<std::pair<const int, int>> > umap1;
// runtime :
std::unordered_map<int, int> umap2(
1024, std::hash<int>(),
std::equal_to<int>(),
FastMemPoolAllocator<std::pair<const int, int>>());
Exemplos de uso podem ser encontrados aqui: test_allocator1.cpp e test_stl_allocator2.cpp .
Por exemplo, o trabalho de construtores e destruidores em alocações:
bool test_Strategy()
{
/*
* Runtime
* ( )
*/
using MyAllocatorType = FastMemPool<333, 33>;
// instance of:
MyAllocatorType fastMemPool;
// inject instance:
FastMemPoolAllocator<std::string,
MyAllocatorType > myAllocator(&fastMemPool);
// 3 :
std::string* str = myAllocator.allocate(3);
// :
myAllocator.construct(str, "Mother ");
myAllocator.construct(str + 1, " washed ");
myAllocator.construct(str + 2, "the frame");
//-
std::cout << str[0] << str[1] << str[2];
// :
myAllocator.destroy(str);
myAllocator.destroy(str + 1);
myAllocator.destroy(str + 2);
// :
myAllocator.deallocate(str, 3);
return true;
}
6) Às vezes, em um grande projeto, você faz algum tipo de módulo, testa tudo exaustivamente - funciona como um relógio suíço. Seu módulo está incluído no Detector, colocado em uma batalha - e às vezes, uma vez por dia, a biblioteca começa a cair no lixo. Depois de executar o dump no depurador, você descobre que em uma das travessias do loop de ponteiros, em vez de nullptr, alguém escreveu o número 8 em seu ponteiro - indo para este ponteiro, você naturalmente irritou o sistema operacional.
Como podemos diminuir a gama de possíveis culpados? É muito simples excluir suas estruturas dos suspeitos - elas precisam ser movidas para a RAM para outro lugar (onde o sabotador não bombardeie):
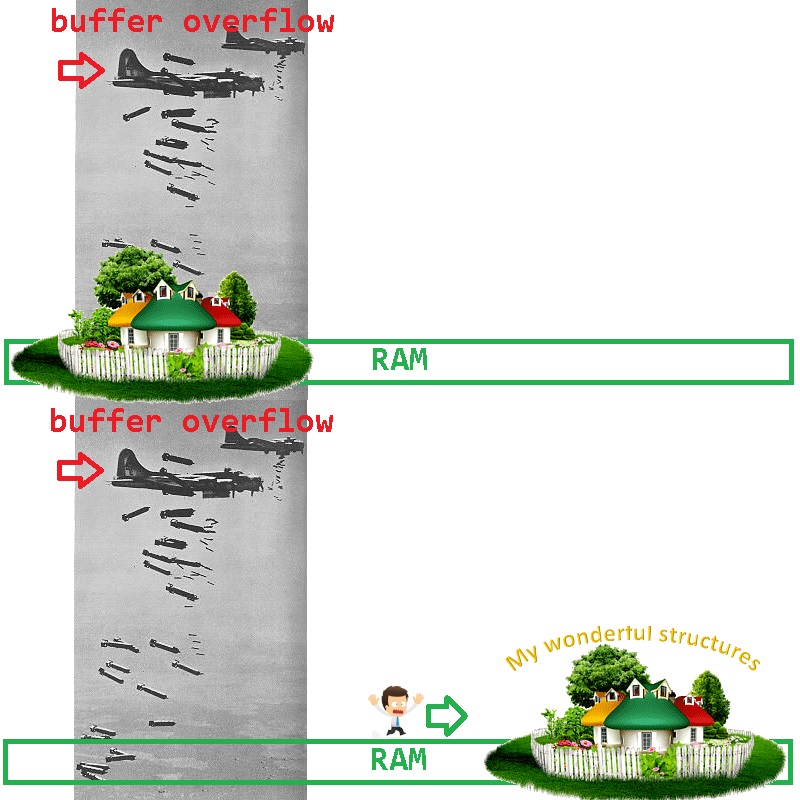
Como isso pode ser feito facilmente com FastMemPool? Muito simples: no FastMemPool, a alocação ocorre cortando o final de uma página de memória - ao solicitar uma página de memória a mais do que você precisa para trabalhar, você garante que o início da página de memória continua sendo um campo de testes para o bombardeio de bugs. Por exemplo:
FastMemPool<100000000, 1, 1024, true, true> bulletproof_mempool;
void *ptr = bulletproof_mempool.fmalloc(1234567);
// ..
// - c ptr
// ..
bulletproof_mempool.ffree(ptr);
Se em um novo lugar alguém está bombardeando suas estruturas, então provavelmente é você mesmo ...
Caso contrário, se a biblioteca se estabilizar, a equipe receberá vários presentes de uma vez:
- seu algoritmo funciona como um relógio suíço novamente
- um codificador com erros pode agora bombardear com segurança uma área de memória vazia (enquanto todos estão procurando por ela), a biblioteca é estável.
- o alcance do bombardeio pode ser monitorado para mudança de memória - para definir armadilhas em um codificador com erros.
No total , quais são as vantagens desta bicicleta em particular:
- ( / )
- , Debug ,
- , /
- , ( nullptr), — , ( FPS , FastMemPool -).
Em nossa empresa, a instalação da análise da geometria 3D de chapas de metal exigia processamento multi-threaded de quadros de vídeo (50FPS). As folhas passam sob a câmera e no reflexo do laser construo um mapa 3D da folha. FastMemPool foi usado para garantir velocidade máxima de trabalho com memória e segurança. Se os fluxos não forem compatíveis com os quadros de entrada, salvar os quadros para processamento futuro da maneira usual leva a um consumo descontrolado de RAM. Com FastMemPool, em caso de estouro, nullptr simplesmente será retornado durante a alocação e o quadro será pulado - na imagem 3D final, tal defeito na forma de salto de etapa indica que é necessário adicionar threads de CPU ao processamento.
A operação de threads sem mutex com um alocador de memória circular e uma pilha de tarefas tornou possível processar os quadros de entrada muito rapidamente, sem perda de quadros e sem sobrecarga de RAM. Agora, este código é executado em 16 threads em uma CPU AMD Ryzen 9 3950X, nenhuma falha na classe FastMemPool foi identificada.
Um diagrama de exemplo simplificado do processo de análise de vídeo com controle de estouro de RAM pode ser visto no código- fonte test_memcontrol1.cpp .
E para sobremesa: no mesmo esquema de exemplo, uma pilha não mutex é usada:
using TWorkStack = SpecSafeStack<VideoFrame>;
//..
// Video frames exchanger:
TWorkStack work_stack;
//..
work_staff->work_stack.push(frame);
//..
VideoFrame * frame = work_staff->work_stack.pop();
Um stand de demonstração funcional com todas as fontes está aqui no gihub .