Inventando uma bicicleta ou escrevendo um perceptron em C ++. Parte 1
Vamos escrever uma biblioteca simples para implementar um perceptron em C ++

Introdução
Olá a todos, neste post quero compartilhar com vocês minha primeira experiência em escrever redes neurais. Existem muitos artigos sobre a implementação de redes neurais (redes neurais no futuro) na Internet, mas não quero usar algoritmos de outras pessoas sem entender a essência de seu trabalho, então decidi criar meu próprio código do zero.
Nesta parte, descreverei os principais pontos do mate. partes que serão úteis para nós. Toda a teoria foi retirada de vários sites, principalmente da Wikipedia.
Link para a 3ª parte com o algoritmo de aprendizado: habr.com/ru/post/514626
Então, vamos lá.
Um pouco de teoria
Vamos concordar que não estou reivindicando o título de "o melhor algoritmo de aprendizado de máquina", estou apenas mostrando minha implementação e minhas ideias. Além disso, estou sempre aberto a críticas construtivas e conselhos sobre o código, isso é importante, é para isso que a comunidade existe.
, .

. .
. :
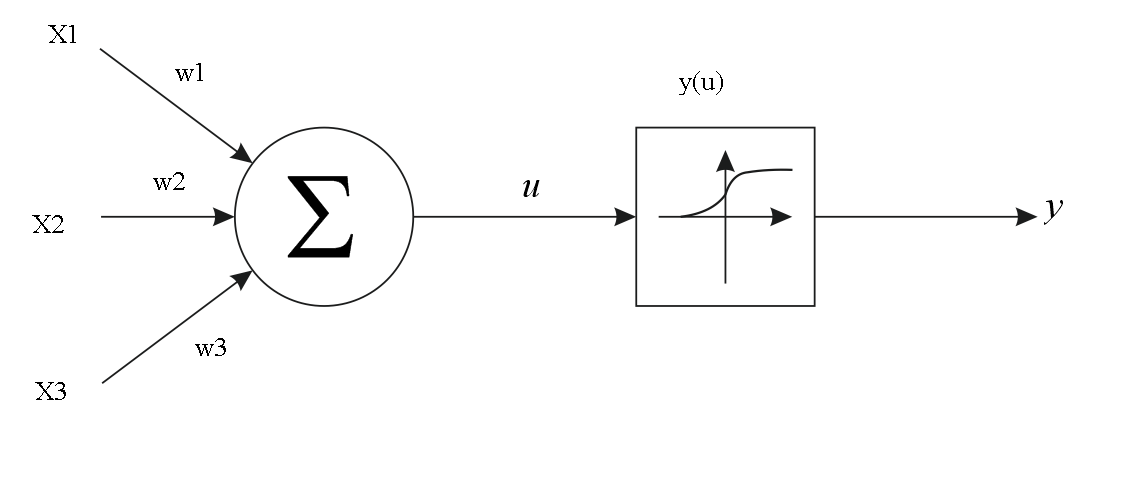
, (1, 2, 3), u (w1, w2, w3), :
u = x1*w1 + x2*w2 + x3*w3
:

. y(u), u – . , .
, , . , , . , – (, ). :

(0; 1), . y(u) .
, . , .
, , .
, . , , ( ).
, 2 : , .
:
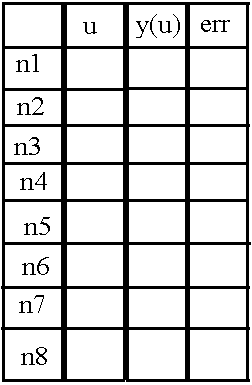
8 ( n1 n8), u, «y(u)» «err», (). «err» .
, , .
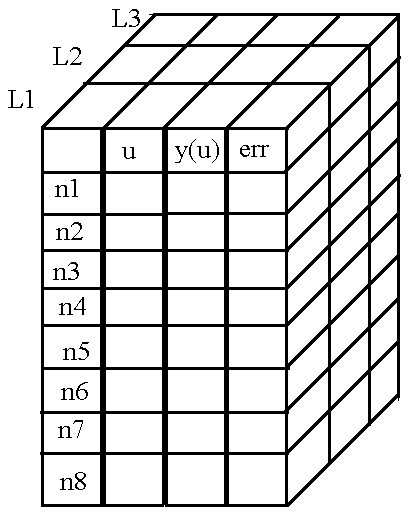
, .
. , , , . , .
Bem, consegui explicar os princípios de armazenamento dos valores necessários nos neurônios. Agora vamos descobrir como armazenar os pesos das conexões entre os neurônios.
Considere a seguinte rede, por exemplo:
...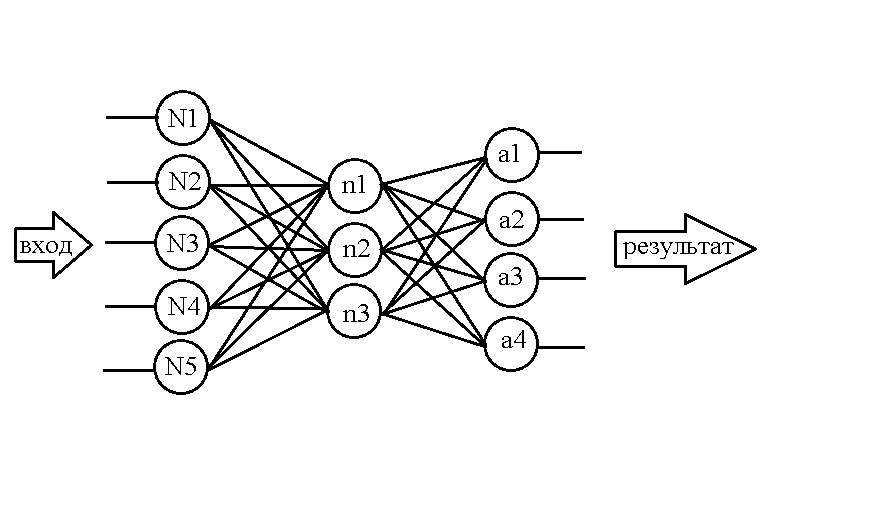
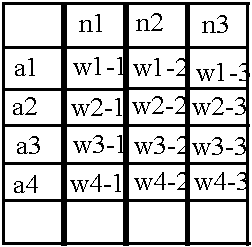
Já sabendo estruturar neurônios na memória, vamos fazer uma tabela semelhante para pesos:

Sua estrutura não é nada complicada: por exemplo, o valor do peso entre o neurônio N1 e o neurônio n1 está contido na célula w1-1, da mesma forma com outros pesos. Mas, novamente, essa matriz é adequada para armazenar pesos apenas entre as duas primeiras camadas, mas ainda há pesos na rede entre a segunda e a terceira camadas. Vamos usar o truque já conhecido - adicionar uma nova dimensão ao array, mas com uma advertência: deixe os nomes das linhas exibirem a camada de neurônios à esquerda em relação ao "feixe" de pesos, e a camada de neurônios à direita se encaixa nos nomes das colunas.
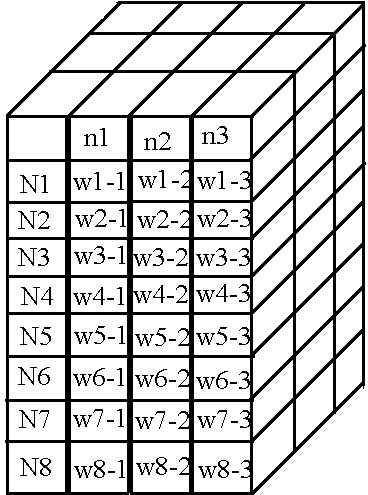
Em seguida, obtemos a seguinte tabela para o segundo "pacote" de pesos:
:
«», .. , , « » , - , . )).
, .
C++. 2
, .
, . .
, !
header —
, . header — ( «neuro.h»). :
class NeuralNet {
public:
NeuralNet(uint8_t L, uint16_t *n);
void Do_it(uint16_t size, double *data);
void getResult(uint16_t size, double* data);
void learnBackpropagation(double* data, double* ans, double acs, double k);
private:
vector<vector<vector<double>>> neurons;
vector<vector<vector<double>>> weights;
uint8_t numLayers;
vector<double> neuronsInLayers;
double Func(double in);
double Func_p(double in);
uint32_t MaxEl(uint16_t size, uint16_t *arr);
void CreateNeurons(uint8_t L, uint16_t *n);
void CreateWeights(uint8_t L, uint16_t *n);
};, , header' ). :
// , ,
#ifndef NEURO_H
#define NEURO_H
#include <vector> //
#include <math.h> // ,
#include <stdint.h> // , .
:
NeuralNet(uint8_t L, uint16_t *n);, , - .
void Do_it(uint16_t size, double *data);)), .
void getResult(uint16_t size, double* data);.
void learnBackpropagation(double* data, double* ans, double acs, double k);, .
, :
vector<vector<vector<double>>> neurons; // ,
vector<vector<vector<double>>> weights; // ,
uint8_t numLayers; //
vector<double> neuronsInLayers; //,
/*
, , , ,
*/
double Func(double in); //
double Func_p(double in); //
uint32_t MaxEl(uint16_t size, uint16_t *arr);//
void CreateNeurons(uint8_t L, uint16_t *n);//
void CreateWeights(uint8_t L, uint16_t *n);
header — :
#endifheader . — source — ).
source —
, .
:
NeuralNet::NeuralNet(uint8_t L, uint16_t *n) {
CreateNeurons(L, n); //
CreateWeights(L, n); //
this->numLayers = L;
this->neuronsInLayers.resize(L);
for (uint8_t l = 0; l < L; l++)this->neuronsInLayers[l] = n[l]; //
}
, :
void NeuralNet::Do_it(uint16_t size, double *data) {
for (int n = 0; n < size; n++) { //
neurons[n][0][0] = data[n]; //
neurons[n][1][0] = Func(neurons[n][0][0]); //
}
for (int L = 1; L < numLayers; L++) { //
for (int N = 0; N < neuronsInLayers[L]; N++) {
double input = 0;
for (int lastN = 0; lastN < neuronsInLayers[L - 1]; lastN++) {//
input += neurons[lastN][1][L - 1] * weights[lastN][N][L - 1];
}
neurons[N][0][L] = input;
neurons[N][1][L] = Func(input);
}
}
}
E, finalmente, a última coisa que eu gostaria de falar é a função de exibição do resultado. Bem, aqui nós apenas copiamos os valores dos neurônios da última camada para o array passado para nós como um parâmetro:
void NeuralNet::getResult(uint16_t size, double* data) {
for (uint16_t r = 0; r < size; r++) {
data[r] = neurons[r][1][numLayers - 1];
}
}
Indo para o pôr do sol
Vamos parar por aqui, a próxima parte será dedicada a uma única função que permite treinar a rede. Devido à complexidade e abundância da matemática, decidi retirá-la em uma parte separada, onde também testaremos o trabalho de toda a biblioteca como um todo.
Mais uma vez, agradeço seus conselhos e comentários nos comentários.
Obrigado pela atenção ao artigo, até breve!
PS: Como prometido - link para fontes: GitHub