
Sempre me interessei pelas falhas do sistema e pelas estranhezas de seu comportamento, especialmente quando trabalham em suas condições normais. Recentemente, vi um dos slides da apresentação de Ian Goodfellow, que achei muito engraçado. Um ruído visual aleatório foi enviado a uma rede neural treinada, e ela o reconheceu como um dos objetos que conhecia. Muitas questões surgem imediatamente aqui. As diferentes redes neurais treinadas verão o mesmo objeto? Qual é o nível máximo de confiança na rede neural de que esse ruído aleatório é de fato um objeto reconhecido? E o que a rede neural realmente "vê" lá?
Por curiosidade sobre isso, nasceu esta entrada. Felizmente, experimentos como esse são muito fáceis de fazer com o PyTorch.... Para visualizar por que a rede neural classifica objetos de uma certa maneira, uso a estrutura de interpretabilidade do modelo Captum . O código pode ser baixado do Github .
Importância das perguntas
Você pode perguntar por que essas perguntas são importantes. Em muitos casos, os desenvolvedores não criam modelos do zero. Eles escolhem plataformas e redes pré-treinadas do zoológico modelo como pontos de partida. Isso economiza tempo - você não precisa coletar dados e conduzir o treinamento inicial da rede neural. No entanto, também significa que problemas inesperados podem surgir em locais inesperados. Dependendo de como esse modelo é usado, podem surgir problemas de segurança no processo.
Modelos pré-treinados
Modelos pré-treinados são fáceis de começar e podem enviar dados rapidamente para classificação. Nesse caso, você não precisa definir os modelos e treiná-los - tudo isso já foi feito antes de você e eles estão prontos para uso imediatamente após a implantação. Modelos pré-treinados da biblioteca Torchvision são treinados em um conjunto de imagens do banco de dados Imagenet , dividido em 1000 categorias... É importante lembrar que esse treinamento envolveu a identificação de um único objeto em uma imagem, não a análise de imagens complexas contendo vários objetos. No segundo caso, você também pode obter resultados interessantes, mas este é um tópico completamente diferente. Baixar modelos pré-treinados da biblioteca Torchvision é muito fácil. Você só precisa importar o modelo selecionado, definindo o parâmetro pré-treinado para True. Também incluí uma modalidade de avaliação nos modelos, pois não há curva de aprendizado durante os testes.
Primeiro, tenho uma linha de código que opta por usar cuda ou cpu, dependendo se uma GPU está disponível. Para esses testes simples, uma GPU não é necessária, mas como eu tenho uma, eu a uso.
device = "cuda" if torch.cuda.is_available() else "cpu"
import torchvision.models as models
vgg16 = models.vgg16(pretrained=True)
vgg16.eval()
vgg16.to(device)
Uma lista de modelos pré-treinados da Torchvision pode ser encontrada aqui . Eu não queria usar todas as redes neurais pré-treinadas, isso já é demais. Eu escolhi os cinco seguintes:
- vgg16
- resnet18
- alexnet
- densenet
- começo
Não usei nenhuma metodologia especial para escolher redes neurais. Por exemplo, Vgg16 e Inception são frequentemente usados em exemplos diferentes e são todos diferentes.
Como criar imagens com ruído
Precisaremos de uma maneira de gerar automaticamente imagens contendo ruído que possam ser alimentadas por redes neurais. Para fazer isso, usei uma combinação das bibliotecas Numpy e PIL e escrevi uma pequena função que retorna uma imagem cheia de ruído aleatório.
import numpy as np
from PIL import Image
def gen_image():
image = (np.random.standard_normal([256, 256, 3]) * 255).astype(np.uint8)
im = Image.fromarray(image)
return im
Você acaba com algo como o seguinte:

Convertendo imagens
Depois disso, precisamos converter nossas imagens em tensor e normalizá-las. O código a seguir pode ser usado não apenas em ruído aleatório, mas também em qualquer imagem que desejamos alimentar em redes neurais pré-treinadas (é por isso que o código usa os valores Resize e CenterCrop).
def xform_image(image):
transform = transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])])
new_image = transform(image).to(device)
new_image = new_image.unsqueeze_(0)
return new_imageTemos previsões
Depois de preparadas as imagens transformadas, é fácil obter previsões a partir do modelo desdobrado. Neste caso, a função xform_image é assumida para retornar image_xform. No código que usei para teste, divido o trabalho entre essas duas funções, mas aqui as coloquei juntas para facilitar a referência. Basicamente, precisamos alimentar a imagem transformada para a rede, executar a função softmax, usar a função topk para obter a pontuação e o ID do rótulo previsto para o melhor resultado.
with torch.no_grad():
vgg16_res = vgg16(image_xform)
vgg16_output = F.softmax(vgg16_res, dim=1)
vgg16score, pred_label_idx = torch.topk(vgg16_output, 1)
resultados
Bem, agora vemos como gerar imagens com ruído e alimentá-las em uma rede pré-treinada. Então, quais são os resultados? Para este teste, decidi gerar 1000 imagens com ruído, executá-las em 5 redes pré-treinadas selecionadas e colocá-las em um dataframe do Pandas para análise rápida. Os resultados foram interessantes e um tanto inesperados.
| vgg16 | resnet18 | alexnet | densenet | começo | |
|---|---|---|---|---|---|
| contagem | 1000,000000 | 1000,000000 | 1000,000000 | 1000,000000 | 1000,000000 |
| significar | 0,226978 | 0,328249 | 0,147289 | 0,409413 | 0,020204 |
| std | 0,067972 | 0,071808 | 0,038628 | 0,148315 | 0,016490 |
| min | 0,074922 | 0,127953 | 0,061019 | 0,139161 | 0,005963 |
| 25% | 0,178240 | 0,278830 | 0,120568 | 0,291042 | 0,011641 |
| 50% | 0,223623 | 0,324111 | 0,143090 | 0,387705 | 0,015880 |
| 75% | 0,270547 | 0,373325 | 0,171139 | 0,511357 | 0,022519 |
| max | 0,438011 | 0,580559 | 0,328568 | 0,868025 | 0,198698 |
Como você pode ver, algumas das redes neurais decidiram que esse ruído está, na verdade, representando algo específico com um nível bastante alto de confiança. Resnet18 e densenet atingiram o pico de 50%. Tudo isso é muito bom, mas o que exatamente essas redes “veem” no meio do ruído? Curiosamente, diferentes redes "encontraram" diferentes objetos ali. Cada uma das redes viu algo diferente. Resnet18 tinha 100% de certeza de que era uma água-viva, enquanto a Inception, ao contrário, tinha muito pouca confiança nas previsões, embora ao mesmo tempo visse muito mais objetos do que qualquer outra rede.
Vgg16:
978
14
7
1
Resnet18:
1000
Alexnet:
942
58
Densenet:
893
37
33
20
16
1
Inception:
155
123
102
85
83
81
69
32
26
25
24
18
16
16
12
12
11
9
9
8
7
5
5
5
- 5
4
4
4
4
3
3
3
3
3
2
2
2
2
2
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
Só por diversão, decidi ver que tipo de assinatura a Microsoft vai colocar sob a imagem de ruído, que aproximei do início desta entrada. Para o teste, decidi seguir o caminho mais simples e usei o PowerPoint do Office 365. O resultado é interessante porque, ao contrário dos modelos imagenet que tentam reconhecer um único objeto, o PowerPoint tenta reconhecer vários objetos para criar uma descrição precisa da imagem.
A imagem mostra um elefante, gente, grande, bola.
O resultado não me decepcionou. Do meu ponto de vista, a imagem do ruído foi reconhecida como um circo.
Perspectivas
Isso nos leva a outra questão - o que uma rede neural vê que a faz pensar que o ruído é um objeto? Em nossa busca por uma resposta, podemos usar uma ferramenta de interpretação de modelos que nos permitirá entender aproximadamente o que a rede "vê". Captum é uma estrutura de interpretação de modelo para PyTorch. Não fiz nada de especial aqui, apenas usei o código dos tutoriais do site deles. Acabei de adicionar o parâmetro internal_batch_size com um valor de 50, porque sem ele minha GPU ficou sem memória muito rapidamente.
Para as visualizações, usei duas atribuições baseadas em gradiente e uma atribuição baseada em oclusão. Com essas visualizações, tentamos entender o que era importante para o classificador e, portanto, “ver” o que a rede vê. Também usei meu modelo resnet pré-treinado, porém você pode alterar o código e usar qualquer outro modelo pré-treinado.
Antes de passar ao ruído, tomei a imagem da camomila como uma demonstração do processo de renderização, já que seus sinais são fáceis de reconhecer.
result = resnet18(image_xform)
result = F.softmax(result, dim=1)
score, pred_label_idx = torch.topk(result, 1)
integrated_gradients = IntegratedGradients(resnet18)
attributions_ig = integrated_gradients.attribute(image_xform, target=pred_label_idx,
internal_batch_size=50, n_steps=200)
default_cmap = LinearSegmentedColormap.from_list('custom blue',
[(0, '#ffffff'),
(0.25, '#000000'),
(1, '#000000')], N=256)
_ = viz.visualize_image_attr(np.transpose(attributions_ig.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(image_xform.squeeze().cpu().detach().numpy(), (1,2,0)),
method='heat_map',
cmap=default_cmap,
show_colorbar=True,
sign='positive',
outlier_perc=1)
noise_tunnel = NoiseTunnel(integrated_gradients)
attributions_ig_nt = noise_tunnel.attribute(image_xform, n_samples=10, nt_type='smoothgrad_sq', target=pred_label_idx, internal_batch_size=50)
_ = viz.visualize_image_attr_multiple(np.transpose(attributions_ig_nt.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(image_xform.squeeze().cpu().detach().numpy(), (1,2,0)),
["original_image", "heat_map"],
["all", "positive"],
cmap=default_cmap,
show_colorbar=True)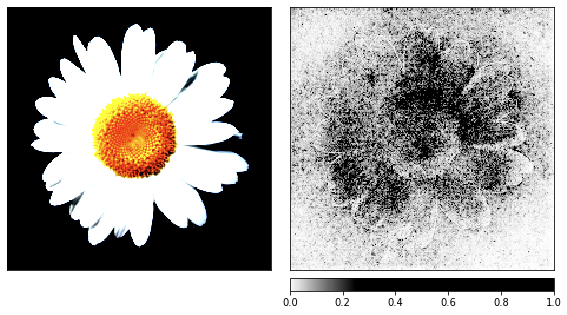
occlusion = Occlusion(resnet18)
attributions_occ = occlusion.attribute(image_xform,
strides = (3, 8, 8),
target=pred_label_idx,
sliding_window_shapes=(3,15, 15),
baselines=0)
_ = viz.visualize_image_attr_multiple(np.transpose(attributions_occ.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(image_xform.squeeze().cpu().detach().numpy(), (1,2,0)),
["original_image", "heat_map"],
["all", "positive"],
show_colorbar=True,
outlier_perc=2,
)

Visualização de ruído
Geramos as imagens anteriores com base na camomila, e agora é hora de ver como as coisas funcionam com ruído aleatório.
Estou usando a rede resnet18 pré-treinada e com essa imagem ela tem 40% de certeza de que vê uma água-viva. Não vou repetir o código, o código para renderização é o mesmo que o dado acima.


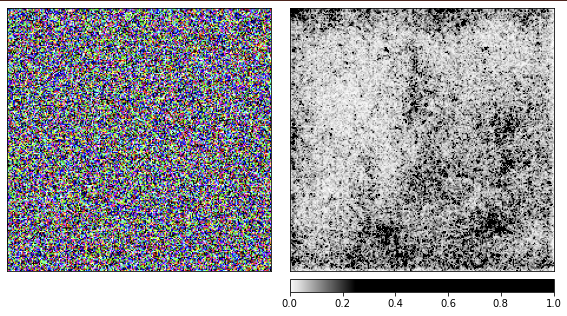

Pelas visualizações, fica claro que nós, humanos, nunca seremos capazes de entender por que a rede vê uma água-viva aqui. Algumas áreas da imagem são marcadas como mais importantes, mas não são tão definidas como vimos no exemplo da camomila. Ao contrário da camomila, as águas-vivas são amorfas e diferem no nível de transparência.
Você pode estar se perguntando como seria a renderização do processamento de uma imagem real de uma água-viva? Meu código está postado no Github, e será fácil obter uma resposta a essa pergunta com sua ajuda.
Conclusão
Com base nessa gravação, é fácil ver como é fácil enganar redes neurais alimentando-as com entradas inesperadas. Para seu crédito, diremos que fizeram seu trabalho e deram o melhor resultado que puderam. Também pode ser verificado nos resultados do trabalho que, em tais casos, não basta apenas filtrar opções com baixa confiança, já que algumas opções tinham bastante confiança. Precisamos ficar de olho nas situações em que os sistemas do mundo real falham com tanta facilidade. Não devemos ficar surpresos com a entrada de dados inesperados no sistema - e isso é o que os especialistas em segurança vêm fazendo há algum tempo.