Portanto, dentro de cada processo separado não há problemas tradicionais "estranhos" com execução paralela de código, bloqueios, condições de corrida , ... E o desenvolvimento do próprio DBMS é agradável e simples.
Mas a mesma simplicidade impõe uma limitação significativa. Como há apenas um thread de trabalho dentro do processo, ele não pode usar mais de um núcleo da CPU para executar uma solicitação , o que significa que a velocidade do servidor depende diretamente da frequência e da arquitetura de um núcleo separado.
Em nossa época de fim da "corrida de megahertz" e dos sistemas multicore e multiprocessador vitoriosos, tal comportamento é um luxo e um desperdício inaceitáveis. Portanto, a partir do PostgreSQL 9.6, ao processar uma consulta, algumas operações podem ser realizadas por vários processos simultaneamente.
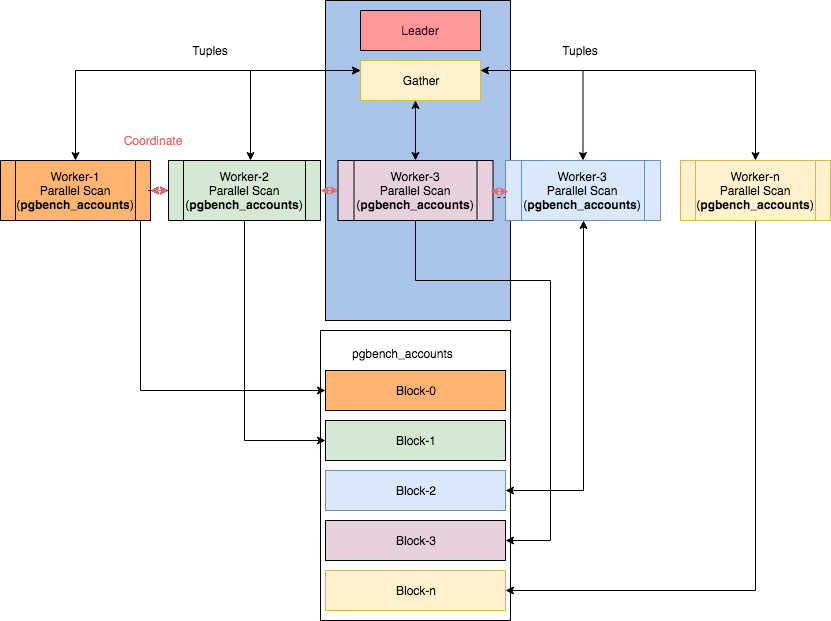
Você pode se familiarizar com os esquemas de operação de alguns nós paralelos no artigo "Paralelismo em PostgreSQL" de Ibrar Ahmed, de onde esta imagem foi retirada.No entanto, neste caso torna-se ... não trivial ler os planos.
Resumidamente, a cronologia da implementação da execução paralela das operações do plano se parece com esta:
- 9.6 - funcionalidade básica: Seq Scan , Join, Aggregate
- 10 - Varredura de índice (para btree), Varredura de heap de bitmap, união de hash, união de mesclagem, verificação de subconsulta
- 11 - operações de grupo : Hash Join com tabela de hash compartilhada, Append (UNION)
- 12 - estatísticas básicas por trabalhador nos nós do plano
- 13 - estatísticas detalhadas por trabalhador
Portanto, se você estiver usando uma das versões mais recentes do PostgreSQL, as chances de vê-lo no plano são
Parallel ...muito altas. E com ele eles vêm e ...
Estranhezas ao longo do tempo
Vamos pegar um plano do PostgreSQL 9.6 :
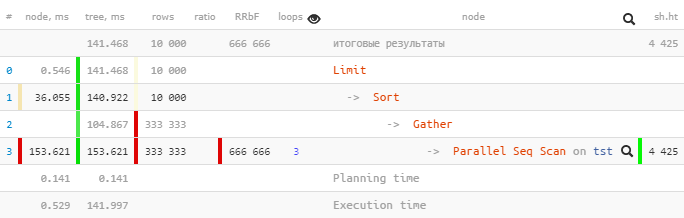
[veja explain.tensor.ru]
Apenas um foi
Parallel Seq Scanexecutado 153,621 ms em uma subárvore e Gatherjunto com todos os subnós - apenas 104,867 ms.
Como assim? O tempo total "lá em cima" diminuiu ?
Vamos dar uma olhada no
Gathernó- em mais detalhes:
Gather (actual time=0.969..104.867 rows=333333 loops=1)
Workers Planned: 2
Workers Launched: 2
Buffers: shared hit=4425Workers Launched: 2nos diz que além do processo principal abaixo da árvore, mais 2 processos adicionais estavam envolvidos - um total de 3. Portanto, tudo o que aconteceu dentro da Gathersubárvore é a criatividade total de todos os 3 processos de uma vez.
Agora vamos ver o que está lá
Parallel Seq Scan:
Parallel Seq Scan on tst (actual time=0.024..51.207 rows=111111 loops=3)
Filter: ((i % 3) = 0)
Rows Removed by Filter: 222222
Buffers: shared hit=4425Aha!
loops=3É um resumo de todos os 3 processos. E, em média, cada um desses ciclos demorou 51,207ms. Ou seja, o servidor demorou 51.207 x 3 = 153.621milissegundos de tempo do processador para concluir esse nó . Ou seja, se quisermos entender "o que o servidor estava fazendo" - este número nos ajudará a entender.
Observe que para entender o tempo de execução "real" , você precisa dividir o tempo total pelo número de trabalhadores - ou seja [actual time] x [loops] / [Workers Launched].
Em nosso exemplo, cada trabalhador realizou apenas um ciclo através do nó, portanto
153.621 / 3 = 51.207. E sim, agora não há nada de estranho que o único Gatherno processo de cabeça foi concluído "por assim dizer, em menos tempo."
Total: veja em explain.tensor.ru o tempo de nó total (para todos os processos) para entender com que tipo de carga seu servidor estava ocupado e para otimizar em qual parte da consulta vale a pena gastar tempo.
Nesse sentido, o comportamento do mesmo explain.depesz.com , mostrando o tempo "médio real" de uma vez, parece menos útil para fins de depuração:
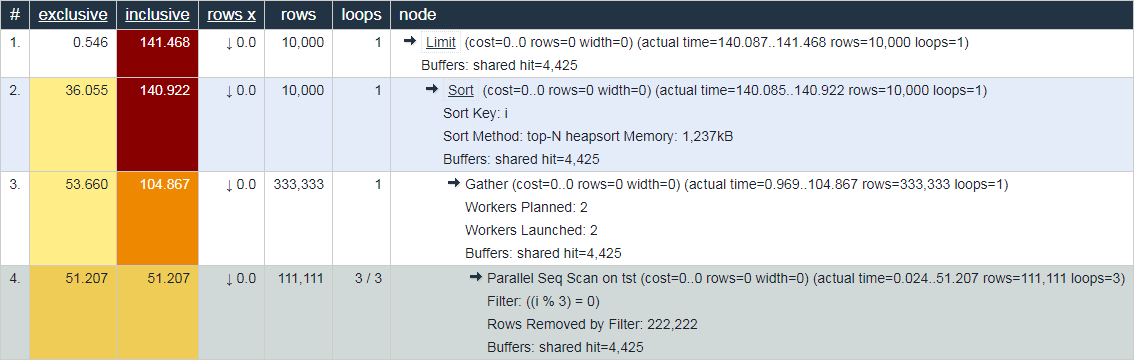
Não concorda? Bem-vindo aos comentários!
Gather Merge perde tudo
Agora vamos executar a mesma consulta para as versões 10 do PostgreSQL :
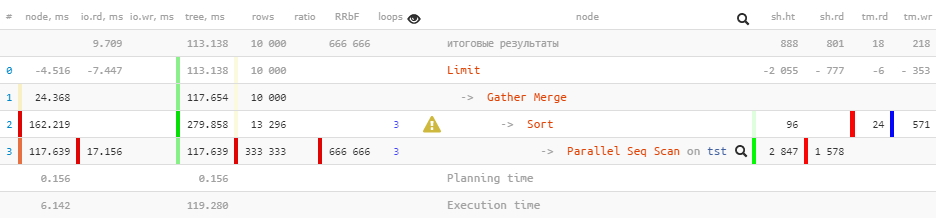
[veja explain.tensor.ru]
Observe que
Gatheragora temos um nó em vez de um nó no plano Gather Merge. Aqui está o que o manual diz sobre isso :
Quando um nó está acima da parte paralela do planoGather Merge, em vez deGather, significa que todos os processos que executam as partes do plano paralelo estão gerando tuplas em ordem classificada e que o processo principal está executando uma mesclagem para preservar a ordem. O nóGather, por outro lado, recebe tuplas de processos subordinados em uma ordem arbitrária que seja conveniente para ele, violando a ordem de classificação que poderia existir.
Mas nem tudo está bem no reino dinamarquês:
Limit (actual time=110.740..113.138 rows=10000 loops=1)
Buffers: shared hit=888 read=801, temp read=18 written=218
I/O Timings: read=9.709
-> Gather Merge (actual time=110.739..117.654 rows=10000 loops=1)
Workers Planned: 2
Workers Launched: 2
Buffers: shared hit=2943 read=1578, temp read=24 written=571
I/O Timings: read=17.156Ao passar atributos
Bufferse I/O Timingssubir na árvore, alguns dos dados foram perdidos prematuramente . Podemos estimar o tamanho dessa perda em cerca de 2/3 , que são formados por processos auxiliares.
Infelizmente, no próprio plano, não há onde obter essas informações - daí as "desvantagens" no nó subjacente. E se você observar a evolução posterior deste plano no PostgreSQL 12 , então não muda fundamentalmente, exceto que algumas estatísticas são adicionadas para cada trabalhador no
Sortnó:
Limit (actual time=77.063..80.480 rows=10000 loops=1)
Buffers: shared hit=1764, temp read=223 written=355
-> Gather Merge (actual time=77.060..81.892 rows=10000 loops=1)
Workers Planned: 2
Workers Launched: 2
Buffers: shared hit=4519, temp read=575 written=856
-> Sort (actual time=72.630..73.252 rows=4278 loops=3)
Sort Key: i
Sort Method: external merge Disk: 1832kB
Worker 0: Sort Method: external merge Disk: 1512kB
Worker 1: Sort Method: external merge Disk: 1248kB
Buffers: shared hit=4519, temp read=575 written=856
-> Parallel Seq Scan on tst (actual time=0.014..44.970 rows=111111 loops=3)
Filter: ((i % 3) = 0)
Rows Removed by Filter: 222222
Buffers: shared hit=4425
Planning Time: 0.142 ms
Execution Time: 83.884 msTotal: não confie nos dados do nó acima
Gather Merge.