
Quando comecei minha carreira como desenvolvedor, meu primeiro emprego foi DBA (administrador de banco de dados, DBA). Naqueles anos, antes mesmo do AWS RDS, Azure, Google Cloud e outros serviços em nuvem, havia dois tipos de DBAs:
- , . « », , .
- : , , SQL. ETL- . , .
Os DBAs de aplicativos geralmente fazem parte de equipes de desenvolvimento. Eles tinham um conhecimento profundo de um tópico específico, então geralmente só trabalhavam em um ou dois projetos. Os DBAs de infraestrutura geralmente faziam parte da equipe de TI e podiam trabalhar em vários projetos ao mesmo tempo.
Eu sou o administrador do banco de dados do aplicativo
Nunca tive vontade de mexer em backups ou ajustar o armazenamento (tenho certeza que é divertido!). Até hoje, gosto de dizer que sou um administrador de banco de dados que sabe desenvolver aplicativos, não um desenvolvedor que entende de bancos de dados.
Neste artigo, compartilharei alguns dos truques de desenvolvimento de banco de dados que aprendi ao longo de minha carreira.
Conteúdo:
- Atualize apenas o que precisa ser atualizado
- Desative restrições e índices para cargas pesadas
- Use tabelas UNLOGGED para dados intermediários
- Implementar processos inteiros com WITH e RETURNING
- Evite índices em colunas com baixa seletividade
- Use índices parciais
- Sempre carregue dados classificados
- Índice de colunas altamente correlacionadas com BRIN
- Tornar os índices "invisíveis"
- Não agende processos longos para começar no início de qualquer hora
- Conclusão
Atualize apenas o que precisa ser atualizado
A operação
UPDATEconsome muitos recursos. A melhor maneira de acelerar é atualizar apenas o que precisa ser atualizado.
Aqui está um exemplo de uma solicitação para normalizar uma coluna de e-mail:
db=# UPDATE users SET email = lower(email);
UPDATE 1010000
Time: 1583.935 ms (00:01.584)
Parece inocente, certo? A solicitação atualiza endereços de e-mail para 1.010.000 usuários. Mas todas as linhas precisam ser atualizadas?
db=# UPDATE users SET email = lower(email)
db-# WHERE email != lower(email);
UPDATE 10000
Time: 299.470 ms
Apenas 10.000 linhas precisam ser atualizadas. Ao reduzir a quantidade de dados processados, reduzimos o tempo de execução de 1,5 segundos para menos de 300 ms. Isso também nos poupará mais esforços na manutenção do banco de dados.
Atualize apenas o que precisa ser atualizado.
Este tipo de grande atualização é muito comum em scripts de migração de dados. Na próxima vez que você escrever um script como este, certifique-se de atualizar apenas o que é necessário.
Desative restrições e índices para cargas pesadas
As restrições são uma parte importante dos bancos de dados relacionais: eles mantêm os dados consistentes e confiáveis. Mas tudo tem seu próprio preço e, na maioria das vezes, você tem que pagar ao carregar ou atualizar um grande número de linhas.
Vamos definir um pequeno esquema de armazenamento:
DROP TABLE IF EXISTS product CASCADE;
CREATE TABLE product (
id serial PRIMARY KEY,
name TEXT NOT NULL,
price INT NOT NULL
);
INSERT INTO product (name, price)
SELECT random()::text, (random() * 1000)::int
FROM generate_series(0, 10000);
DROP TABLE IF EXISTS customer CASCADE;
CREATE TABLE customer (
id serial PRIMARY KEY,
name TEXT NOT NULL
);
INSERT INTO customer (name)
SELECT random()::text
FROM generate_series(0, 100000);
DROP TABLE IF EXISTS sale;
CREATE TABLE sale (
id serial PRIMARY KEY,
created timestamptz NOT NULL,
product_id int NOT NULL,
customer_id int NOT NULL
);
Ele define diferentes tipos de restrições como "não nulo", bem como restrições exclusivas ...
Para definir o ponto de partida, vamos começar a adicionar
salechaves estrangeiras à tabela
db=# ALTER TABLE sale ADD CONSTRAINT sale_product_fk
db-# FOREIGN KEY (product_id) REFERENCES product(id);
ALTER TABLE
Time: 18.413 ms
db=# ALTER TABLE sale ADD CONSTRAINT sale_customer_fk
db-# FOREIGN KEY (customer_id) REFERENCES customer(id);
ALTER TABLE
Time: 5.464 ms
db=# CREATE INDEX sale_created_ix ON sale(created);
CREATE INDEX
Time: 12.605 ms
db=# INSERT INTO SALE (created, product_id, customer_id)
db-# SELECT
db-# now() - interval '1 hour' * random() * 1000,
db-# (random() * 10000)::int + 1,
db-# (random() * 100000)::int + 1
db-# FROM generate_series(1, 1000000);
INSERT 0 1000000
Time: 15410.234 ms (00:15.410)
Depois de definir as restrições e os índices, o carregamento de um milhão de linhas na tabela levou cerca de 15,4 segundos.
Agora, primeiro, vamos carregar os dados na tabela e só então adicionar restrições e índices:
db=# INSERT INTO SALE (created, product_id, customer_id)
db-# SELECT
db-# now() - interval '1 hour' * random() * 1000,
db-# (random() * 10000)::int + 1,
db-# (random() * 100000)::int + 1
db-# FROM generate_series(1, 1000000);
INSERT 0 1000000
Time: 2277.824 ms (00:02.278)
db=# ALTER TABLE sale ADD CONSTRAINT sale_product_fk
db-# FOREIGN KEY (product_id) REFERENCES product(id);
ALTER TABLE
Time: 169.193 ms
db=# ALTER TABLE sale ADD CONSTRAINT sale_customer_fk
db-# FOREIGN KEY (customer_id) REFERENCES customer(id);
ALTER TABLE
Time: 185.633 ms
db=# CREATE INDEX sale_created_ix ON sale(created);
CREATE INDEX
Time: 484.244 ms
O carregamento foi muito mais rápido, 2,27 segundos. em vez de 15,4. Índices e limites foram criados muito mais tempo após o carregamento dos dados, mas todo o processo foi muito mais rápido: 3,1 segundos. em vez de 15,4.
Infelizmente, no PostgreSQL você não pode fazer o mesmo com os índices, você só pode descartá-los e recriá-los. Em outros bancos de dados, como Oracle, você pode desabilitar e habilitar índices sem reconstruir.
UNLOGGED-
Quando você altera os dados no PostgreSQL, as alterações são gravadas no registro de gravação antecipada (WAL ). É usado para manter a consistência, reindexar rapidamente durante a recuperação e manter a replicação.
Muitas vezes é necessário escrever para o WAL, mas há algumas circunstâncias em que você pode optar por sair do WAL para acelerar as coisas. Por exemplo, no caso de tabelas intermediárias.
As tabelas intermediárias são chamadas de tabelas únicas, que armazenam dados temporários usados para implementar alguns processos. Por exemplo, em processos ETL, é muito comum carregar dados de arquivos CSV em tabelas de preparação, limpar as informações e carregá-las na tabela de destino. Nesse cenário, a tabela de preparação é de uso único e não é usada em backups ou réplicas.
Tabela UNLOGGED.
As tabelas de teste que não precisam ser recuperadas no caso de uma falha e não são necessárias em réplicas podem ser definidas como UNLOGGED :
CREATE UNLOGGED TABLE staging_table ( /* table definition */ );
Cuidado : antes de usar
UNLOGGED, certifique-se de compreender totalmente todas as implicações.
Implementar processos inteiros com WITH e RETURNING
Digamos que você tenha uma tabela de usuários e descubra que ela contém dados duplicados:
Table setup
db=# SELECT u.id, u.email, o.id as order_id
FROM orders o JOIN users u ON o.user_id = u.id;
id | email | order_id
----+-------------------+----------
1 | foo@bar.baz | 1
1 | foo@bar.baz | 2
2 | me@hakibenita.com | 3
3 | ME@hakibenita.com | 4
3 | ME@hakibenita.com | 5
Usuário haki benita registrado duas vezes, com correio
ME@hakibenita.come me@hakibenita.com. Como não estamos normalizando endereços de e-mail ao inseri-los na tabela, agora temos que lidar com duplicatas.
Nós precisamos:
- Identifique endereços duplicados em letras minúsculas e vincule usuários duplicados uns aos outros.
- Atualize os pedidos para que se refiram apenas a uma das duplicatas.
- Remova duplicatas da tabela.
Você pode vincular usuários duplicados usando uma tabela de preparação:
db=# CREATE UNLOGGED TABLE duplicate_users AS
db-# SELECT
db-# lower(email) AS normalized_email,
db-# min(id) AS convert_to_user,
db-# array_remove(ARRAY_AGG(id), min(id)) as convert_from_users
db-# FROM
db-# users
db-# GROUP BY
db-# normalized_email
db-# HAVING
db-# count(*) > 1;
CREATE TABLE
db=# SELECT * FROM duplicate_users;
normalized_email | convert_to_user | convert_from_users
-------------------+-----------------+--------------------
me@hakibenita.com | 2 | {3}
A tabela intermediária contém links entre as tomadas. Se um usuário com um endereço de e-mail normalizado aparecer mais de uma vez, atribuímos a ele um ID de usuário mínimo, no qual recolheremos todas as duplicatas. O resto dos usuários são armazenados na coluna da matriz e todas as referências a eles serão atualizadas.
Usando a tabela intermediária, atualizaremos os links para duplicatas na tabela
orders:
db=# UPDATE
db-# orders o
db-# SET
db-# user_id = du.convert_to_user
db-# FROM
db-# duplicate_users du
db-# WHERE
db-# o.user_id = ANY(du.convert_from_users);
UPDATE 2
Agora você pode remover duplicatas com segurança de
users:
db=# DELETE FROM
db-# users
db-# WHERE
db-# id IN (
db(# SELECT unnest(convert_from_users)
db(# FROM duplicate_users
db(# );
DELETE 1
Observe que usamos a função unnest para "transformar" a matriz , que transforma cada elemento em uma string.
Resultado:
db=# SELECT u.id, u.email, o.id as order_id
db-# FROM orders o JOIN users u ON o.user_id = u.id;
id | email | order_id
----+-------------------+----------
1 | foo@bar.baz | 1
1 | foo@bar.baz | 2
2 | me@hakibenita.com | 3
2 | me@hakibenita.com | 4
2 | me@hakibenita.com | 5
Ótimo, todas as instâncias de user
3( ME@hakibenita.com) são convertidas em user 2( me@hakibenita.com).
Também podemos verificar se as duplicatas são removidas da tabela
users:
db=# SELECT * FROM users;
id | email
----+-------------------
1 | foo@bar.baz
2 | me@hakibenita.com
Agora podemos nos livrar da mesa de teste:
db=# DROP TABLE duplicate_users;
DROP TABLE
Tudo bem, mas demora muito e precisa de limpeza! Existe uma maneira melhor?
Expressões de tabela generalizadas (CTE)
Com expressões de tabela genéricas , também conhecidas como expressões
WITH, podemos executar todo o procedimento com uma única expressão SQL:
WITH duplicate_users AS (
SELECT
min(id) AS convert_to_user,
array_remove(ARRAY_AGG(id), min(id)) as convert_from_users
FROM
users
GROUP BY
lower(email)
HAVING
count(*) > 1
),
update_orders_of_duplicate_users AS (
UPDATE
orders o
SET
user_id = du.convert_to_user
FROM
duplicate_users du
WHERE
o.user_id = ANY(du.convert_from_users)
)
DELETE FROM
users
WHERE
id IN (
SELECT
unnest(convert_from_users)
FROM
duplicate_users
);
Em vez de uma tabela de teste, criamos uma expressão de tabela genérica e a reutilizamos.
Retornando resultados de CTE
Uma das vantagens de executar DML em uma expressão
WITHé que você pode retornar dados usando a palavra-chave RETURNING . Digamos que precisamos de um relatório sobre o número de linhas atualizadas e excluídas:
WITH duplicate_users AS (
SELECT
min(id) AS convert_to_user,
array_remove(ARRAY_AGG(id), min(id)) as convert_from_users
FROM
users
GROUP BY
lower(email)
HAVING
count(*) > 1
),
update_orders_of_duplicate_users AS (
UPDATE
orders o
SET
user_id = du.convert_to_user
FROM
duplicate_users du
WHERE
o.user_id = ANY(du.convert_from_users)
RETURNING o.id
),
delete_duplicate_user AS (
DELETE FROM
users
WHERE
id IN (
SELECT unnest(convert_from_users)
FROM duplicate_users
)
RETURNING id
)
SELECT
(SELECT count(*) FROM update_orders_of_duplicate_users) AS orders_updated,
(SELECT count(*) FROM delete_duplicate_user) AS users_deleted
;
Resultado:
orders_updated | users_deleted
----------------+---------------
2 | 1
A beleza dessa abordagem é que todo o processo é feito com um único comando, portanto, não há necessidade de gerenciar transações ou se preocupar em liberar a tabela temporária se o processo travar.
Aviso : um leitor do Reddit apontou para mim o possível comportamento imprevisível da execução de DML em expressões de tabela genéricas :
As subexpressões emWITHsão executadas simultaneamente entre si e com a consulta principal. Portanto, quando usado emWITHexpressões de modificação de dados, a ordem real das atualizações será imprevisível.
Isso significa que você não pode confiar na ordem em que as subexpressões independentes são executadas. Acontece que, se houver uma dependência entre eles, como no exemplo acima, você pode contar com a execução da subexpressão dependente antes de usá-los.
Evite índices em colunas com baixa seletividade
Digamos que você tenha um processo de inscrição em que um usuário efetua login em um endereço de e-mail. Para ativar sua conta, você precisa verificar seu e-mail. A tabela pode ser assim:
db=# CREATE TABLE users (
db-# id serial,
db-# username text,
db-# activated boolean
db-#);
CREATE TABLE
A maioria de seus usuários são cidadãos conscientes, eles se cadastram com o endereço de correspondência correto e ativam a conta imediatamente. Vamos preencher a tabela com os dados do usuário e assumir que 90% dos usuários estão ativados:
db=# INSERT INTO users (username, activated)
db-# SELECT
db-# md5(random()::text) AS username,
db-# random() < 0.9 AS activated
db-# FROM
db-# generate_series(1, 1000000);
INSERT 0 1000000
db=# SELECT activated, count(*) FROM users GROUP BY activated;
activated | count
-----------+--------
f | 102567
t | 897433
db=# VACUUM ANALYZE users;
VACUUM
Para consultar o número de usuários ativados e não ativados, você pode criar um índice por coluna
activated:
db=# CREATE INDEX users_activated_ix ON users(activated);
CREATE INDEX
E se você perguntar pelo número de usuários não ativados , a base usará o índice:
db=# EXPLAIN SELECT * FROM users WHERE NOT activated;
QUERY PLAN
--------------------------------------------------------------------------------------
Bitmap Heap Scan on users (cost=1923.32..11282.99 rows=102567 width=38)
Filter: (NOT activated)
-> Bitmap Index Scan on users_activated_ix (cost=0.00..1897.68 rows=102567 width=0)
Index Cond: (activated = false)
A base decidiu que o filtro retornaria 102.567 itens, cerca de 10% da tabela. Isso é consistente com os dados que carregamos, portanto, a tabela fez um bom trabalho.
No entanto, se consultarmos o número de usuários ativados , descobriremos que o banco de dados decidiu não usar o índice :
db=# EXPLAIN SELECT * FROM users WHERE activated;
QUERY PLAN
---------------------------------------------------------------
Seq Scan on users (cost=0.00..18334.00 rows=897433 width=38)
Filter: activated
Muitos desenvolvedores ficam confusos quando o banco de dados não está usando o índice. Para explicar por que isso acontece, o seguinte é: se você precisasse ler a tabela inteira, usaria um índice ?
Provavelmente não, por que isso é necessário? Ler do disco é caro, então você deve ler o mínimo possível. Por exemplo, se a tabela tiver 10 MB e o índice 1 MB, para ler a tabela inteira, você terá que ler 10 MB do disco. E se você adicionar um índice, obterá 11 MB. É um desperdício.
Vamos agora dar uma olhada nas estatísticas que o PostgreSQL coletou em nossa tabela:
db=# SELECT attname, n_distinct, most_common_vals, most_common_freqs
db-# FROM pg_stats
db-# WHERE tablename = 'users' AND attname='activated';
------------------+------------------------
attname | activated
n_distinct | 2
most_common_vals | {t,f}
most_common_freqs | {0.89743334,0.10256667}
Quando o PostgreSQL analisou a tabela, descobriu que
activatedhavia dois valores diferentes na coluna . O valor tna coluna most_common_valscorresponde à frequência 0.89743334na coluna most_common_freqse o valor fcorresponde à frequência 0.10256667. Após análise da tabela, o banco de dados constatou que 89,74% dos registros eram de usuários ativados e os 10,26% restantes não ativados.
Com base nessas estatísticas, o PostgreSQL decidiu que é melhor verificar a tabela inteira do que assumir que 90% das linhas satisfazem a condição. O limite além do qual uma base pode decidir se deve usar um índice depende de muitos fatores e não existe uma regra prática.
Índice para colunas com baixa e alta seletividade.
Use índices parciais
No capítulo anterior, criamos um índice para uma coluna booleana que tinha cerca de 90% dos registros
true(usuários ativados).
Quando perguntamos o número de usuários ativos, o banco de dados não utilizou o índice. E quando questionado sobre o número de não ativados, o banco de dados utilizou o índice.
Surge a pergunta: se o banco de dados não vai usar o índice para filtrar usuários ativos, por que os indexaríamos em primeiro lugar?
Antes de responder a esta pergunta, vejamos o peso do índice completo por coluna
activated:
db=# \di+ users_activated_ix
Schema | Name | Type | Owner | Table | Size
--------+--------------------+-------+-------+-------+------
public | users_activated_ix | index | haki | users | 21 MB
O índice pesa 21 MB. Apenas para referência: a tabela com usuários é de 65 MB. Ou seja, o peso do índice é ~ 32% do peso base. Dito isso, sabemos que é improvável que aproximadamente 90% do conteúdo do índice seja usado.
No PostgreSQL, você pode criar um índice em apenas uma parte de uma tabela - o chamado índice parcial :
db=# CREATE INDEX users_unactivated_partial_ix ON users(id)
db-# WHERE not activated;
CREATE INDEX
Usamos uma expressão
WHEREpara restringir as strings cobertas pelo índice. Vamos verificar se funciona:
db=# EXPLAIN SELECT * FROM users WHERE not activated;
QUERY PLAN
------------------------------------------------------------------------------------------------
Index Scan using users_unactivated_partial_ix on users (cost=0.29..3493.60 rows=102567 width=38)
Ótimo, o banco de dados acabou sendo inteligente o suficiente para perceber que a expressão booleana que usamos em nossa consulta pode funcionar para um índice parcial.
Essa abordagem tem outra vantagem:
db=# \di+ users_unactivated_partial_ix
List of relations
Schema | Name | Type | Owner | Table | Size
--------+------------------------------+-------+-------+-------+---------
public | users_unactivated_partial_ix | index | haki | users | 2216 kB
O índice de coluna completo pesa 21 MB e o índice parcial é de apenas 2,2 MB. Isso é 10%, o que corresponde à proporção de usuários não ativados na tabela.
Sempre carregue dados classificados
Este é um dos meus comentários mais frequentes ao analisar o código. O conselho não é tão intuitivo quanto os outros e pode ter um grande impacto na produtividade.
Digamos que você tenha uma mesa enorme com vendas específicas:
db=# CREATE TABLE sale_fact (id serial, username text, sold_at date);
CREATE TABLE
Todas as noites durante o processo ETL, você carrega dados em uma tabela:
db=# INSERT INTO sale_fact (username, sold_at)
db-# SELECT
db-# md5(random()::text) AS username,
db-# '2020-01-01'::date + (interval '1 day') * round(random() * 365 * 2) AS sold_at
db-# FROM
db-# generate_series(1, 100000);
INSERT 0 100000
db=# VACUUM ANALYZE sale_fact;
VACUUM
Para simular o download, usamos dados aleatórios. Inserimos 100 mil linhas com nomes aleatórios e as datas de venda para o período de 1º de janeiro de 2020 e dois anos de antecedência.
Na maior parte, a tabela é usada para relatórios de vendas de resumo. Na maioria das vezes, eles filtram por data para ver as vendas de um período específico. Para acelerar a varredura de intervalo, vamos criar um índice por
sold_at:
db=# CREATE INDEX sale_fact_sold_at_ix ON sale_fact(sold_at);
CREATE INDEX
Vamos dar uma olhada no plano de execução da solicitação para buscar todas as vendas em junho de 2020:
db=# EXPLAIN (ANALYZE)
db-# SELECT *
db-# FROM sale_fact
db-# WHERE sold_at BETWEEN '2020-07-01' AND '2020-07-31';
QUERY PLAN
-----------------------------------------------------------------------------------------------
Bitmap Heap Scan on sale_fact (cost=108.30..1107.69 rows=4293 width=41)
Recheck Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Heap Blocks: exact=927
-> Bitmap Index Scan on sale_fact_sold_at_ix (cost=0.00..107.22 rows=4293 width=0)
Index Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Planning Time: 0.191 ms
Execution Time: 5.906 ms
Depois de executar a solicitação várias vezes para aquecer o cache, o tempo de execução se estabilizou no nível de 6 ms.
Varredura de bitmap
Em termos de execução, vemos que a base usava digitalização de bitmap. Acontece em duas etapas:
(Bitmap Index Scan): a base percorre todo o índicesale_fact_sold_at_ixe encontra todas as páginas da tabela que contêm as linhas relevantes.(Bitmap Heap Scan): a base lê as páginas que contêm as strings relevantes e encontra aquelas que satisfazem a condição.
As páginas podem conter muitas linhas. Na primeira etapa, o índice é usado para localizar páginas . A segunda etapa busca as linhas nas páginas, daí a operação
Recheck Condno plano de execução segue .
Nesse ponto, muitos DBAs e desenvolvedores terminarão e passarão para a próxima consulta. Mas existe uma maneira de melhorar essa consulta.
Index Scan
Vamos fazer uma pequena mudança no carregamento de dados.
db=# TRUNCATE sale_fact;
TRUNCATE TABLE
db=# INSERT INTO sale_fact (username, sold_at)
db-# SELECT
db-# md5(random()::text) AS username,
db-# '2020-01-01'::date + (interval '1 day') * round(random() * 365 * 2) AS sold_at
db-# FROM
db-# generate_series(1, 100000)
db-# ORDER BY sold_at;
INSERT 0 100000
db=# VACUUM ANALYZE sale_fact;
VACUUM
Desta vez, carregamos os dados classificados por
sold_at.
Agora, o plano de execução para a mesma consulta se parece com este:
db=# EXPLAIN (ANALYZE)
db-# SELECT *
db-# FROM sale_fact
db-# WHERE sold_at BETWEEN '2020-07-01' AND '2020-07-31';
QUERY PLAN
---------------------------------------------------------------------------------------------
Index Scan using sale_fact_sold_at_ix on sale_fact (cost=0.29..184.73 rows=4272 width=41)
Index Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Planning Time: 0.145 ms
Execution Time: 2.294 ms
Após várias execuções, o tempo de execução se estabilizou em 2,3ms. Alcançamos uma economia sustentável de cerca de 60%.
Também vemos que desta vez o banco de dados não usou a varredura de bitmap, mas aplicou uma varredura de índice "normal". Por quê?
Correlação
Quando o banco de dados analisa a tabela, ele coleta todas as estatísticas que pode obter. Um dos parâmetros é a correlação :
Correlação estatística entre a ordem física das linhas e a ordem lógica dos valores nas colunas. Se o valor for em torno de -1 ou +1, uma varredura de índice na coluna é considerada mais vantajosa do que quando o valor de correlação está em torno de 0, uma vez que o número de acessos ao disco aleatórios é reduzido.
Conforme explicado na documentação oficial, a correlação é uma medida de como os valores em uma coluna específica no disco são “classificados”.
Correlação = 1.
Se a correlação for igual a 1, significa que as páginas são armazenadas no disco quase na mesma ordem que as linhas da tabela. Isso é muito comum. Por exemplo, IDs de incremento automático tendem a ter uma correlação próxima a 1. As colunas de data e carimbo de data / hora que mostram quando as linhas foram criadas também têm uma correlação próxima a 1.
Se a correlação for -1, as páginas serão classificadas na ordem inversa das colunas.
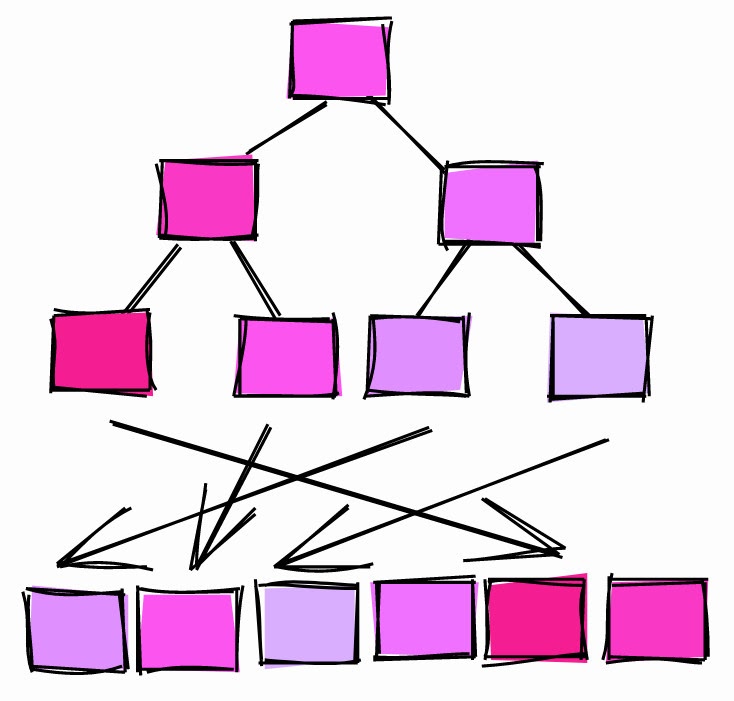
Correlação ~ 0.
Se a correlação for próxima de 0, significa que os valores na coluna não se correlacionam ou dificilmente se correlacionam com a ordem das páginas na tabela.
Vamos voltar para
sale_fact. Quando carregamos os dados na tabela sem pré-classificação, as correlações eram assim:
db=# SELECT tablename, attname, correlation
db-# FROM pg_stats
db=# WHERE tablename = 'sale_fact';
tablename | attname | correlation
-----------+----------+--------------
sale | id | 1
sale | username | -0.005344716
sale | sold_at | -0.011389783
O ID da coluna gerado automaticamente tem uma correlação de 1. A coluna tem uma
sold_atcorrelação muito baixa: valores consecutivos estão espalhados por toda a tabela.
Quando carregamos os dados classificados na tabela, ela calculou as correlações:
tablename | attname | correlation
-----------+----------+----------------
sale_fact | id | 1
sale_fact | username | -0.00041992788
sale_fact | sold_at | 1
A correlação agora
sold_até igual 1.
Então, por que a base usa varreduras de bitmap quando a correlação é baixa, mas varreduras de índice quando a correlação é alta?
- Quando a correlação era 1, a base determinava que as linhas do intervalo solicitado provavelmente estavam em páginas consecutivas. Então, é melhor usar uma varredura de índice para ler várias páginas.
- Quando a correlação estava próxima de 0, a base determinou que as linhas do intervalo solicitado provavelmente estavam espalhadas por toda a tabela. Em seguida, é aconselhável usar uma varredura de bitmap das páginas que contêm as linhas necessárias, e só então extraí-las usando a condição.
Na próxima vez que você carregar dados em uma tabela, pense em quantas informações serão solicitadas e classifique para que os índices possam varrer rapidamente os intervalos.
Comando CLUSTER
Outra maneira de "classificar uma tabela no disco" por um índice específico é usar o comando CLUSTER .
Por exemplo:
db=# TRUNCATE sale_fact;
TRUNCATE TABLE
-- Insert rows without sorting
db=# INSERT INTO sale_fact (username, sold_at)
db-# SELECT
db-# md5(random()::text) AS username,
db-# '2020-01-01'::date + (interval '1 day') * round(random() * 365 * 2) AS sold_at
db-# FROM
db-# generate_series(1, 100000)
INSERT 0 100000
db=# ANALYZE sale_fact;
ANALYZE
db=# SELECT tablename, attname, correlation
db-# FROM pg_stats
db-# WHERE tablename = 'sale_fact';
tablename | attname | correlation
-----------+-----------+----------------
sale_fact | sold_at | -5.9702674e-05
sale_fact | id | 1
sale_fact | username | 0.010033822
Carregamos os dados na tabela em ordem aleatória, de modo que a correlação
sold_até próxima de zero.
Para "recompor" a tabela por
sold_at, usamos o comando CLUSTERpara classificar a tabela no disco de acordo com o índice sale_fact_sold_at_ix:
db=# CLUSTER sale_fact USING sale_fact_sold_at_ix;
CLUSTER
db=# ANALYZE sale_fact;
ANALYZE
db=# SELECT tablename, attname, correlation
db-# FROM pg_stats
db-# WHERE tablename = 'sale_fact';
tablename | attname | correlation
-----------+----------+--------------
sale_fact | sold_at | 1
sale_fact | id | -0.002239401
sale_fact | username | 0.013389298
Depois de agrupar a tabela, a correlação
sold_attornou-se 1.
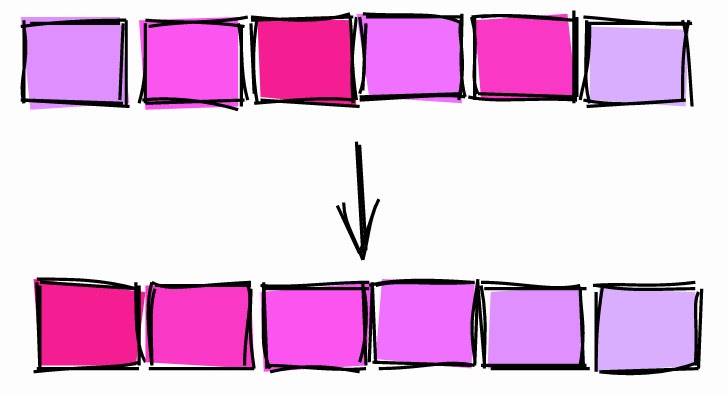
Comando CLUSTER.
Pontos a serem observados:
- O agrupamento de uma tabela em uma coluna específica pode afetar a correlação de outra coluna. Por exemplo, observe a correlação de IDs após o agrupamento por
sold_at. CLUSTERÉ uma operação pesada e bloqueadora, portanto, não a aplique a uma mesa ativa.
Por esses motivos, é melhor inserir dados que já estão classificados e não confiáveis
CLUSTER.
Índice de colunas altamente correlacionadas com BRIN
Quando se trata de índices, muitos desenvolvedores pensam em árvores-B. Mas o PostgreSQL oferece outros tipos de índices, como BRIN :
BRIN é projetado para trabalhar com tabelas muito grandes em que algumas colunas se correlacionam naturalmente com sua localização física dentro da tabela
BRIN significa Block Range Index. De acordo com a documentação, BRIN funciona melhor com colunas altamente correlacionadas. Como vimos nos capítulos anteriores, o incremento automático de IDs e carimbos de data / hora se correlacionam naturalmente com a estrutura física da tabela, portanto, BRIN é mais benéfico para eles.
Sob certas condições, o BRIN pode fornecer melhor "valor pelo dinheiro" em termos de tamanho e desempenho em comparação com um índice B-tree comparável.
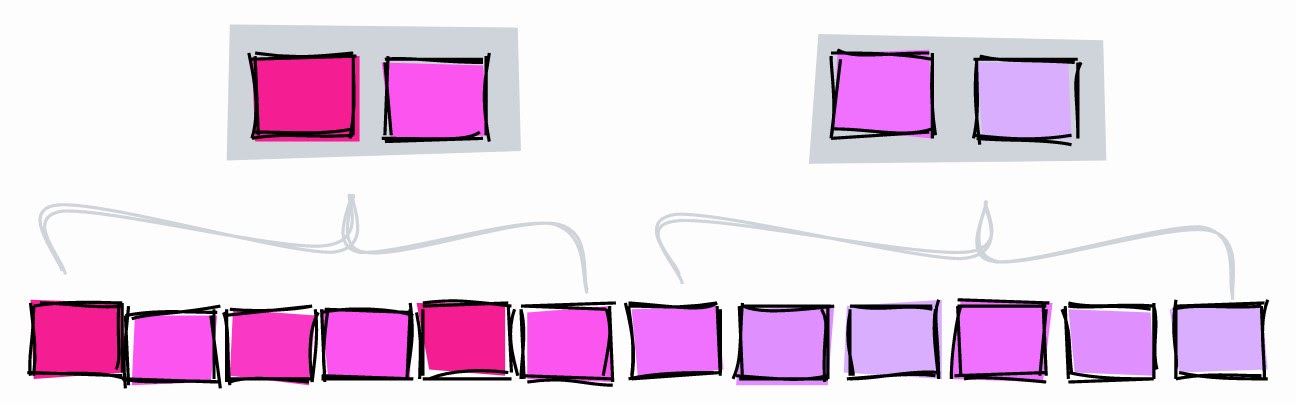
BRIN.
BRIN é um intervalo de valores dentro de várias páginas adjacentes em uma tabela. Digamos que temos os seguintes valores em uma coluna, cada um em uma página separada:
1, 2, 3, 4, 5, 6, 7, 8, 9
BRIN trabalha com intervalos de páginas adjacentes. Se você especificar três páginas adjacentes, o índice divide a tabela em intervalos:
[1,2,3], [4,5,6], [7,8,9]
Para cada intervalo, BRIN armazena os valores mínimo e máximo :
[1–3], [4–6], [7–9]
Vamos usar este índice para procurar o valor 5:
- [1-3] - ele certamente não está aqui.
- [4-6] - talvez aqui.
- [7-9] - ele certamente não está aqui.
Com o BRIN, limitamos a área de pesquisa ao bloco 4-6.
Vamos dar outro exemplo. Faça com que os valores da coluna tenham uma correlação próxima de zero, ou seja, eles não são classificados:
[2,9,5], [1,4,7], [3,8,6]
A indexação de três blocos adjacentes nos dará os seguintes intervalos:
[2–9], [1–7], [3–8]
Vamos procurar o valor 5:
- [2-9] - pode estar aqui.
- [1-7] - pode estar aqui.
- [3-8] - pode estar aqui.
Nesse caso, o índice não restringe a pesquisa de forma alguma, portanto, é inútil.
Compreendendo as pages_per_range
O número de páginas adjacentes é determinado pelo parâmetro
pages_per_range. O número de páginas em um intervalo afeta o tamanho e a precisão do BRIN:
- Um
pages_per_rangeíndice menor e menos preciso dará um grande valor . - Um valor pequeno
pages_per_rangefornecerá um índice maior e mais preciso.
O padrão
pages_per_rangeé 128.
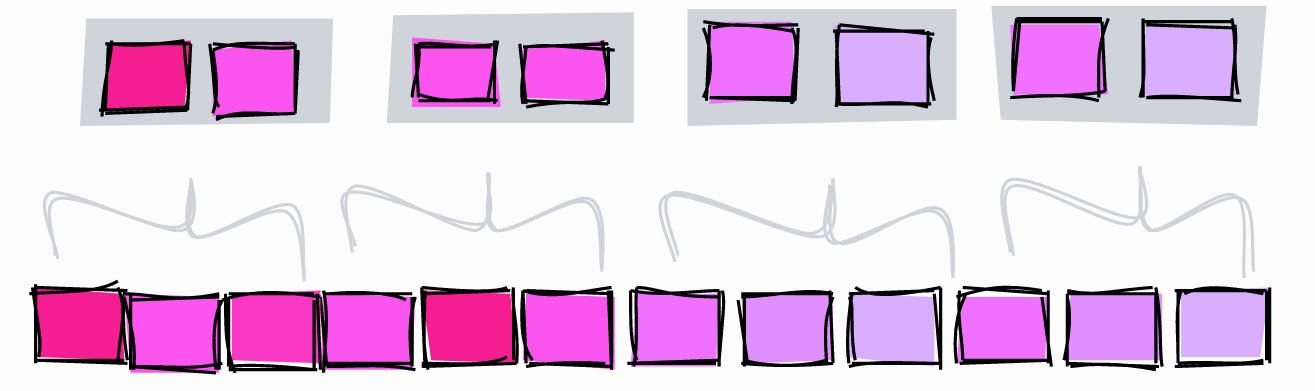
BRIN com pages_per_range inferiores.
Para ilustrar, vamos criar um BRIN com intervalos de duas páginas e procurar um valor de 5:
- [1-2] - ele certamente não está aqui.
- [3-4] - ele certamente não está aqui.
- [5-6] - pode estar aqui.
- [7-8] - ele certamente não está aqui.
- [9] - aqui definitivamente não.
Com um intervalo de duas páginas, podemos restringir a pesquisa aos blocos 5 e 6. Se o intervalo for de três páginas, o índice limitará a pesquisa aos blocos 4, 5 e 6.
Outra diferença entre os dois índices é que quando o intervalo era de três páginas, precisávamos armazenar três intervalos , e com duas páginas em um intervalo, já obtemos cinco intervalos e o índice aumenta.
Criar BRIN
Vamos pegar uma tabela
sales_facte criar um BRIN por coluna sold_at:
db=# CREATE INDEX sale_fact_sold_at_bix ON sale_fact
db-# USING BRIN(sold_at) WITH (pages_per_range = 128);
CREATE INDEX
O padrão é
pages_per_range = 128.
Agora vamos consultar o período da data de vendas:
db=# EXPLAIN (ANALYZE)
db-# SELECT *
db-# FROM sale_fact
db-# WHERE sold_at BETWEEN '2020-07-01' AND '2020-07-31';
QUERY PLAN
--------------------------------------------------------------------------------------------
Bitmap Heap Scan on sale_fact (cost=13.11..1135.61 rows=4319 width=41)
Recheck Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Rows Removed by Index Recheck: 23130
Heap Blocks: lossy=256
-> Bitmap Index Scan on sale_fact_sold_at_bix (cost=0.00..12.03 rows=12500 width=0)
Index Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Execution Time: 8.877 ms
A base pegou o período de datas usando BRIN, mas isso não é nada interessante ...
Otimizando pages_per_range
De acordo com o plano de execução, o banco de dados removeu 23.130 linhas das páginas, que encontrou por meio do índice. Isso pode indicar que o intervalo especificado para o índice é muito grande para esta consulta. Vamos criar um índice com metade do número de páginas do intervalo:
db=# CREATE INDEX sale_fact_sold_at_bix64 ON sale_fact
db-# USING BRIN(sold_at) WITH (pages_per_range = 64);
CREATE INDEX
db=# EXPLAIN (ANALYZE)
db- SELECT *
db- FROM sale_fact
db- WHERE sold_at BETWEEN '2020-07-01' AND '2020-07-31';
QUERY PLAN
---------------------------------------------------------------------------------------------
Bitmap Heap Scan on sale_fact (cost=13.10..1048.10 rows=4319 width=41)
Recheck Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Rows Removed by Index Recheck: 9434
Heap Blocks: lossy=128
-> Bitmap Index Scan on sale_fact_sold_at_bix64 (cost=0.00..12.02 rows=6667 width=0)
Index Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Execution Time: 5.491 ms
Com 64 páginas no intervalo, a base excluiu menos linhas encontradas usando o índice - 9 434. Isso significa que teve que fazer menos operações de I / O e a consulta foi executada um pouco mais rápido, em ~ 5,5 ms em vez de ~ 8,9.
Vamos testar o índice com valores diferentes
pages_per_range:
| pages_per_range | Linhas removidas ao verificar novamente o índice |
| 128 | 23130 |
| 64 | 9 434 |
| 8 | 874 |
| 4 | 446 |
| 2 | 446 |
Diminuir o
pages_per_rangeíndice se torna mais preciso e remove menos linhas das páginas que encontra.
Observe que otimizamos uma consulta muito específica. Isso é bom para ilustração, mas na vida real é melhor usar valores que atendam às necessidades da maioria das consultas.
Estimando o tamanho do índice
Outra grande vantagem do BRIN é seu tamanho. Nos capítulos anteriores,
sold_atcriamos um índice de árvore B para o campo . Seu tamanho era de 2.224 KB. E o tamanho BRIN com o parâmetro é pages_per_range=128apenas 48 KB: 46 vezes menor.
Schema | Name | Type | Owner | Table | Size
--------+-----------------------+-------+-------+-----------+-------
public | sale_fact_sold_at_bix | index | haki | sale_fact | 48 kB
public | sale_fact_sold_at_ix | index | haki | sale_fact | 2224 kB
O tamanho BRIN também é afetado
pages_per_range. Por exemplo, BRIN s pages_per_range=2pesa 56 Kb, pouco mais de 48 Kb.
Tornar os índices "invisíveis"
PostgreSQL tem um ótimo recurso DDL transacional . Ao longo dos anos com a Oracle, eu se acostumaram a usar os comandos DDL, tais como
CREATE, DROPe no final das transações ALTER. Mas no PostgreSQL, você pode executar comandos DDL dentro de uma transação, e as alterações serão aplicadas somente depois que a transação for confirmada.
Recentemente, descobri que o uso de DDL transacional pode tornar os índices invisíveis! Isso é útil quando você deseja ver um plano de execução sem índices.
Por exemplo, em uma tabela
sale_fact, criamos um índice em uma coluna sold_at. O plano de execução para a solicitação de busca de vendas de julho é assim:
db=# EXPLAIN
db-# SELECT *
db-# FROM sale_fact
db-# WHERE sold_at BETWEEN '2020-07-01' AND '2020-07-31';
QUERY PLAN
--------------------------------------------------------------------------------------------
Index Scan using sale_fact_sold_at_ix on sale_fact (cost=0.42..182.80 rows=4319 width=41)
Index Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))P
Para ver como o plano ficaria se não houvesse índice
sale_fact_sold_at_ix, você pode colocar o índice dentro de uma transação e reverter imediatamente:
db=# BEGIN;
BEGIN
db=# DROP INDEX sale_fact_sold_at_ix;
DROP INDEX
db=# EXPLAIN
db-# SELECT *
db-# FROM sale_fact
db-# WHERE sold_at BETWEEN '2020-07-01' AND '2020-07-31';
QUERY PLAN
---------------------------------------------------------------------------------
Seq Scan on sale_fact (cost=0.00..2435.00 rows=4319 width=41)
Filter: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
db=# ROLLBACK;
ROLLBACK
Primeiro, vamos iniciar uma transação com
BEGIN. Em seguida, eliminamos o índice e geramos o plano de execução. Observe que o plano agora usa uma varredura completa da tabela como se o índice não existisse. Neste ponto, a transação ainda está em andamento, então o índice ainda não foi descartado. Para concluir a transação sem eliminar o índice, reverta-o usando o comando ROLLBACK.
Vamos verificar se o índice ainda existe:
db=# \di+ sale_fact_sold_at_ix
List of relations
Schema | Name | Type | Owner | Table | Size
--------+----------------------+-------+-------+-----------+---------
public | sale_fact_sold_at_ix | index | haki | sale_fact | 2224 kB
Outros bancos de dados que não suportam DDL transacional podem atingir o objetivo de forma diferente. Por exemplo, o Oracle permite que você marque um índice como invisível e o otimizador o ignorará.
Aviso : se você deixar cair o índice dentro de uma transação, ele vai levar ao bloqueio das operações competitivas
SELECT, INSERT, UPDATEe DELETEna tabela até que a transação está ativa. Use com cuidado em ambientes de teste e evite o uso em instalações de produção.
Não agende processos longos para começar no início de qualquer hora
Os investidores sabem que coisas estranhas podem acontecer quando o preço das ações atinge belos valores redondos, por exemplo, $ 10, $ 100, $ 1000. Aqui está o que eles escrevem sobre isso :
[...] o preço do ativo pode mudar de maneira imprevisível, cruzando valores redondos como $ 50 ou $ 100 por ação. Muitos comerciantes inexperientes gostam de comprar ou vender ativos quando o preço atinge números redondos , porque pensam que são preços justos.
Deste ponto de vista, os desenvolvedores não são muito diferentes dos investidores. Quando precisam agendar um processo longo, costumam escolher um horário.
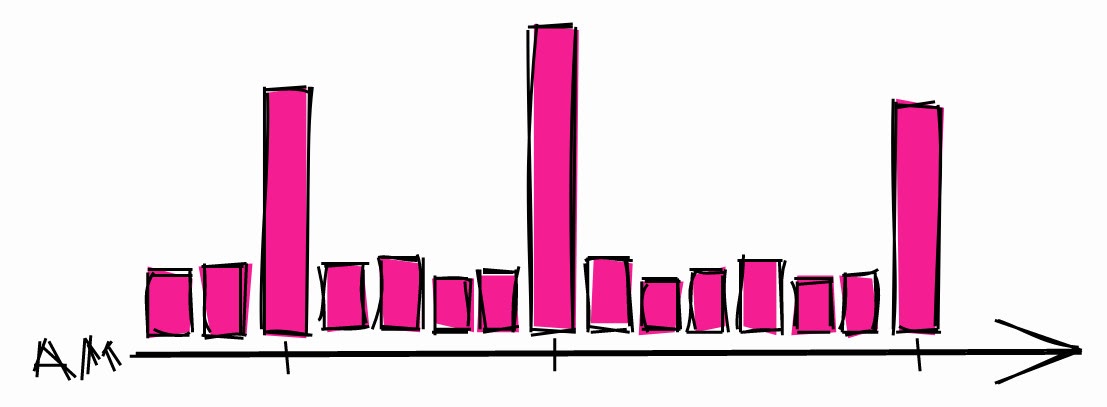
Carga típica do sistema durante a noite.
Isso pode levar a picos de carga durante essas horas. Portanto, se você precisar agendar um processo longo, há uma chance maior de que o sistema fique ocioso em outros momentos.
Recomenda-se também o uso de atrasos aleatórios nas programações para não iniciar no mesmo horário todas as vezes. Então, mesmo que outra tarefa seja agendada para esta hora, não será um grande problema. Se você estiver usando um cronômetro systemd, poderá usar a opção RandomizedDelaySec .
Conclusão
Este artigo fornece dicas de vários graus de evidência com base em minha experiência. Alguns são fáceis de implementar, alguns requerem um conhecimento profundo de como funcionam os bancos de dados. Bancos de dados são a espinha dorsal da maioria dos sistemas modernos, portanto, o tempo gasto aprendendo como trabalhar é um bom investimento para qualquer desenvolvedor!