Se você já projeta aplicativos de back-end ou bancos de dados há algum tempo, provavelmente já escreveu código para executar consultas paginadas. Por exemplo - assim:
SELECT * FROM table_name LIMIT 10 OFFSET 40
Do jeito que está?
Mas se é assim que você fez a paginação, lamento dizer que você não fez da forma mais eficiente.
Você quer discutir comigo? Você não precisa perder tempo . Slack , Shopify e Mixmax já estão usando os truques que quero falar hoje.
Nomeie pelo menos um back-end de desenvolvedor, que nunca usou
OFFSETe LIMITpara realizar consultas com paginação. Em MVP (Produto Mínimo Viável, Produto Mínimo Viável) e em projetos que usam pequenas quantidades de dados, esta abordagem é bastante aplicável. Simplesmente funciona, por assim dizer.
Mas se você precisa criar sistemas confiáveis e eficientes do zero, deve cuidar com antecedência da eficiência das consultas aos bancos de dados usados em tais sistemas.
Hoje falaremos sobre os problemas associados às implementações amplamente usadas (desculpe) de mecanismos de execução de consultas paginadas e como obter alto desempenho ao executar tais consultas.
O que há de errado com OFFSET e LIMIT?
Como já foi dito,
OFFSETe LIMITse mostra perfeitamente em projetos que não precisam trabalhar com grandes quantidades de dados.
O problema surge quando o banco de dados cresce a um tamanho que deixa de caber na memória do servidor. No entanto, ao trabalhar com este banco de dados, você deve usar consultas paginadas.
Para que este problema se manifeste, é necessário que ocorra uma situação em que o SGBD recorra a uma ineficiente operação Full Table Scan ao executar cada consulta com paginação (ao mesmo tempo, podem ocorrer operações de inserção e exclusão de dados , e não precisamos de dados desatualizados!).
O que é uma "varredura completa da tabela" (ou "varredura sequencial da tabela", Varredura sequencial)? Esta é uma operação durante a qual o SGBD lê sequencialmente cada linha da tabela, ou seja, os dados nela contidos, e os verifica em relação a uma determinada condição. Esse tipo de varredura de tabela é conhecido por ser o mais lento. O fato é que quando ele é executado, muitas operações de I / O são realizadas que usam o subsistema de disco do servidor. A situação é agravada pelos atrasos associados ao trabalho com dados armazenados em discos e pelo fato de que a transferência de dados do disco para a memória é uma operação que consome muitos recursos.
Por exemplo, você tem registros de 100 milhões de usuários e está executando uma consulta com a construção
OFFSET 50000000... Isso significa que o SGBD terá que carregar todos esses registros (e nem precisamos deles!), Colocá-los na memória, e depois pegar, digamos, 20 resultados reportados no LIMIT.
Digamos que possa ser parecido com "selecione as linhas 50.000 a 50020 de 100.000". Ou seja, primeiro o sistema precisará carregar 50.000 linhas para executar a consulta. Vê quanto trabalho desnecessário ela tem que fazer?
Se você não acredita em mim, dê uma olhada no exemplo que criei usando db-fiddle.com .

Exemplo em db-fiddle.com
Lá, à esquerda, no campo
Schema SQL, está o código para inserir 100.000 linhas no banco de dados, e à direita, no campoQuery SQL, duas consultas são mostradas. O primeiro, lento, tem a seguinte aparência:
SELECT *
FROM `docs`
LIMIT 10 OFFSET 85000;
E a segunda, que é uma solução eficaz para o mesmo problema, assim:
SELECT *
FROM `docs`
WHERE id > 85000
LIMIT 10;
Para atender a essas solicitações, basta clicar no botão
Runno topo da página. Feito isso, vamos comparar as informações sobre o tempo de execução da consulta. Acontece que a execução de uma consulta ineficiente leva pelo menos 30 vezes mais tempo do que a execução da segunda (este tempo difere do início ao início, por exemplo, o sistema pode relatar que levou 37 ms para completar a primeira solicitação, e execução do segundo - 1 ms).
E se houver mais dados, tudo parecerá ainda pior (para verificar isso, dê uma olhada no meu exemplo com 10 milhões de linhas).
O que acabamos de discutir deve lhe dar algumas dicas sobre como as consultas de banco de dados são realmente tratadas.
Lembre-se de que quanto maior o valor
OFFSET - quanto mais tempo a solicitação demorará.
O que deve ser usado em vez de uma combinação de OFFSET e LIMIT?
Em vez de uma combinação
OFFSET, LIMITvale a pena usar uma estrutura construída de acordo com o seguinte esquema:
SELECT * FROM table_name WHERE id > 10 LIMIT 20
Esta é a execução de uma consulta de paginação baseada em cursor.
Em vez de localmente armazenado atual
OFFSETe LIMITe enviá-los a cada pedido, é necessário para armazenar a última chave primária recebida (normalmente - um ID) e LIMIT, como resultado e será solicitado que se assemelha ao supracitado.
Por quê? O fato é que, ao especificar explicitamente o identificador da última linha lida, você informa ao DBMS onde ele precisa começar a procurar os dados de que precisa. Além disso, a busca, graças ao uso da chave, será realizada de forma eficiente, o sistema não terá que ser distraído por linhas que estão fora da faixa especificada.
Vamos dar uma olhada na seguinte comparação de desempenho de diferentes consultas. Aqui está uma consulta ineficaz.
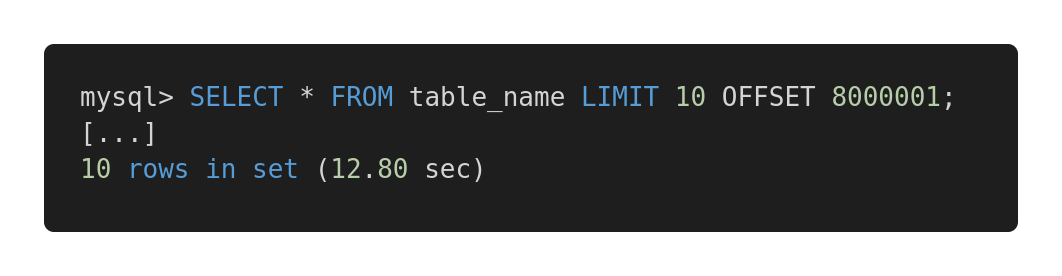
Consulta lenta
E aqui está uma versão otimizada desta consulta.

Consulta rápida
Ambas as consultas retornam exatamente a mesma quantidade de dados. Mas o primeiro leva 12,80 segundos e o segundo 0,01 segundos. Você sente a diferença?
Possíveis problemas
Para que o método de execução da consulta proposto funcione de forma eficiente, a tabela deve ter uma coluna (ou colunas) contendo índices sequenciais únicos, como um identificador inteiro. Em alguns casos específicos, isso pode determinar o sucesso do uso de tais consultas para aumentar a velocidade de trabalho com o banco de dados.
Naturalmente, ao projetar consultas, é necessário levar em consideração as peculiaridades da arquitetura das tabelas e escolher os mecanismos que melhor se manifestarão nas tabelas existentes. Por exemplo, se você precisa trabalhar em consultas com grandes quantidades de dados relacionados, pode achar este artigo interessante .
Se nos deparamos com o problema da ausência de uma chave primária, por exemplo, se houver uma tabela com um relacionamento muitos-para-muitos, então a abordagem tradicional de usar
OFFSETe LIMITcertamente funcionará para nós. Mas sua aplicação pode levar à execução de consultas potencialmente lentas. Nesses casos, eu recomendaria usar uma chave primária de incremento automático, mesmo se você só precisar dela para organizar consultas paginadas.
Se você está interessado neste tópico - aqui , aqui e aqui - alguns materiais úteis.
Resultado
A principal conclusão que podemos tirar é que sempre, não importa o tamanho dos bancos de dados de que estamos falando, precisamos analisar a velocidade de execução da consulta. Em nossa época, escalabilidade de soluções é extremamente importante, e se você projetar tudo corretamente desde o início do trabalho em um determinado sistema, isso, no futuro, pode salvar o desenvolvedor de muitos problemas.
Como você analisa e otimiza as consultas ao banco de dados?
