Primeiro, vamos nos familiarizar brevemente com os métodos de percorrer gráficos, escrever o pathfinding real e, em seguida, passar para o mais delicioso: otimizar o desempenho e os custos de memória. Idealmente, você deve desenvolver uma implementação que não gere lixo quando usada.
Fiquei surpreso quando uma pesquisa superficial não me deu uma única boa implementação do algoritmo A * em C # sem usar bibliotecas de terceiros (isso não significa que não haja nenhuma). Então é hora de esticar os dedos!
Estou aguardando um leitor que queira entender o trabalho dos algoritmos de pathfinding, bem como especialistas em algoritmos para se familiarizar com a implementação e métodos de sua otimização.
Vamos começar!
Uma excursão pela história
Uma grade bidimensional pode ser representada como um gráfico, onde cada um dos vértices possui 8 arestas:
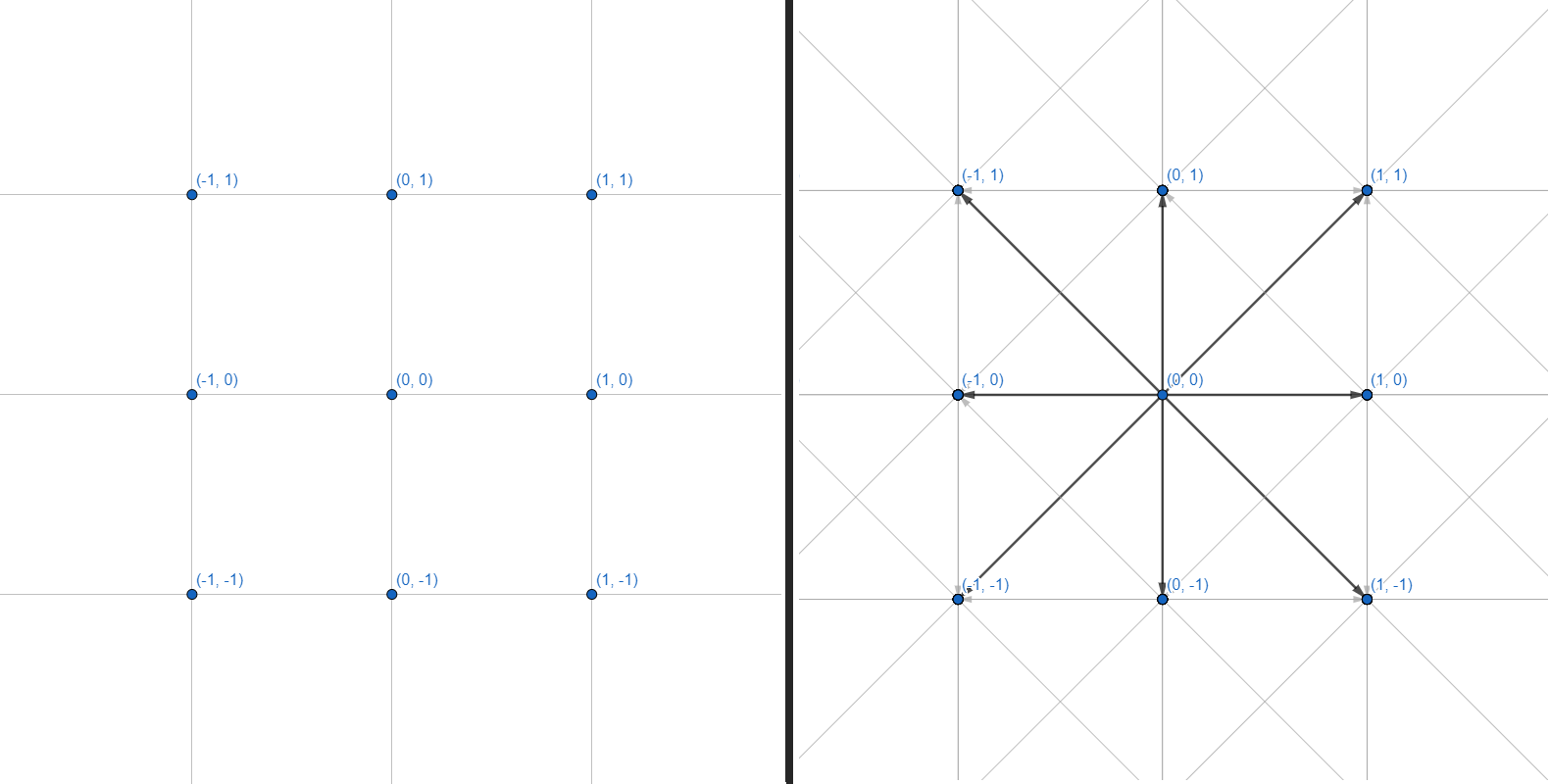
Trabalharemos com gráficos. Cada vértice é uma coordenada inteira. Cada aresta é uma transição reta ou diagonal entre coordenadas adjacentes. Não faremos a grade de coordenadas e o cálculo da geometria dos obstáculos - nos restringiremos a uma interface que aceita várias coordenadas como entrada e retorna um conjunto de pontos para a construção de um caminho:
public interface IPath
{
IReadOnlyCollection<Vector2Int> Calculate(Vector2Int start, Vector2Int target,
IReadOnlyCollection<Vector2Int> obstacles);
}Para começar, considere os métodos existentes para percorrer o gráfico.
Pesquisa de profundidade
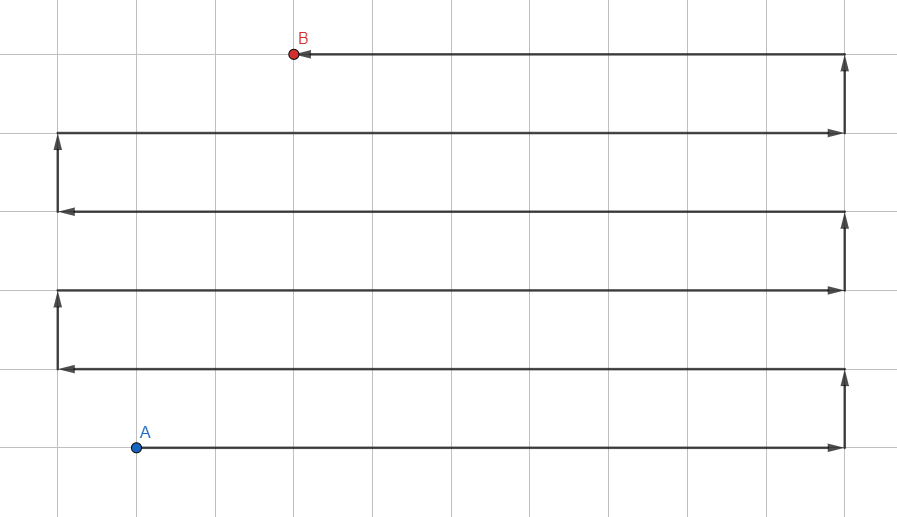
O mais simples dos algoritmos:
- Adicione todos os vértices não visitados próximos ao atual à pilha.
- Mova para o primeiro vértice da pilha.
- Se o vértice for o desejado, saia do ciclo. Se você chegar a um beco sem saída, volte.
- GOTO 1.
Se parece com isso:
, Node , .
private Node DFS(Node first, Node target)
{
List<Node> visited = new List<Node>();
Stack<Node> frontier = new Stack<Node>();
frontier.Push(first);
while (frontier.Count > 0)
{
var current = frontier.Pop();
visited.Add(current);
if (current == target)
return Node;
var neighbours = current.GenerateNeighbours();
foreach(var neighbour in neighbours)
if (!visited.Contains(neighbour))
frontier.Push(neighbour);
}
return default;
}, Node , .
É organizado no formato LIFO ( Último a entrar - Primeiro a sair ), onde os vértices recém-adicionados são analisados primeiro. Cada transição entre os vértices deve ser monitorada para construir o caminho real ao longo das transições.
Essa abordagem nunca (bem, quase) retornará o caminho mais curto, pois processa o gráfico em uma direção aleatória. É mais adequado para pequenos gráficos, a fim de determinar sem dor de cabeça se existe pelo menos algum caminho para o vértice desejado (por exemplo, se o link desejado está presente na árvore de tecnologia).
No caso de uma grade de navegação e gráficos infinitos, essa busca irá incessantemente em uma direção e desperdiçará recursos de computação sem chegar ao ponto desejado. Isso é resolvido limitando a área em que o algoritmo opera. Fazemos com que ele analise apenas pontos localizados a não mais que N passos do inicial. Assim, quando o algoritmo atinge a borda da região, ele se desdobra e continua a analisar os vértices dentro do raio especificado.
Às vezes é impossível determinar a área com precisão, mas você não deseja definir a borda aleatoriamente. Uma pesquisa aprofundada iterativa vem para o resgate :
- Defina a área mínima para DFS.
- Começe a pesquisar.
- Se o caminho não for encontrado, aumente a área de pesquisa em 1.
- GOTO 2.
O algoritmo será executado continuamente, cada vez cobrindo uma área maior até que finalmente encontre o ponto desejado.
Pode parecer um desperdício de energia executar novamente o algoritmo em um raio um pouco maior (de qualquer maneira, a maior parte da área já foi analisada na última iteração!), Mas não: o número de transições entre vértices cresce geometricamente a cada aumento no raio. Será muito mais caro pegar um raio maior do que o necessário, do que caminhar várias vezes ao longo de raios pequenos.
É fácil para tal pesquisa apertar um limite de tempo: ela irá pesquisar um caminho com um raio de expansão exatamente até o tempo especificado terminar.
Largura da primeira pesquisa
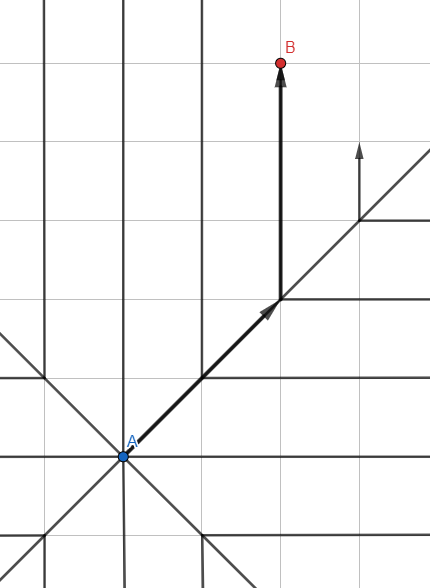
A ilustração pode se parecer com Jump Search - mas este é o algoritmo de onda usual , e as linhas representam os caminhos de propagação de pesquisa com os pontos intermediários removidos.
Em contraste com a pesquisa em profundidade usando uma pilha (LIFO), vamos pegar uma fila (FIFO) para processar os vértices:
- Adicione todos os vizinhos não visitados à fila.
- Vá para o primeiro vértice da fila.
- Se o vértice for o desejado, saia do ciclo, caso contrário, GOTO 1.
Se parece com isso:
, Node , .
private Node BFS(Node first, Node target)
{
List<Node> visited = new List<Node>();
Queue<Node> frontier = new Queue<Node>();
frontier.Enqueue(first);
while (frontier.Count > 0)
{
var current = frontier.Dequeue();
visited.Add(current);
if (current == target)
return Node;
var neighbours = current.GenerateNeighbours();
foreach(var neighbour in neighbours)
if (!visited.Contains(neighbour))
frontier.Enqueue(neighbour);
}
return default;
}, Node , .
Essa abordagem fornece o caminho ideal , mas há um problema: como o algoritmo processa vértices em todas as direções, ele funciona muito lentamente em longas distâncias e em gráficos com fortes ramificações. Este é apenas o nosso caso.
Aqui, a área de atuação do algoritmo não pode ser limitada, pois em qualquer caso não ultrapassará o raio até o ponto desejado. Outros métodos de otimização são necessários.
UMA *
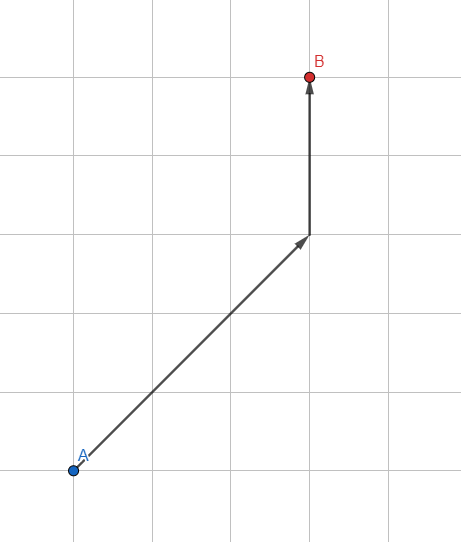
Vamos modificar o Breadth First Search padrão: não usamos uma fila regular para armazenar vértices, mas uma fila classificada com base em heurísticas - uma estimativa aproximada do caminho esperado.
Como estimar o caminho esperado? O mais simples é o comprimento do vetor do vértice processado até o ponto desejado. Quanto menor o vetor, mais promissor é o ponto e mais próximo do início da fila ele se torna. O algoritmo dará prioridade aos vértices que estão na direção da meta.
Assim, cada iteração dentro do algoritmo levará um pouco mais de tempo devido a cálculos adicionais, mas ao reduzir o número de vértices para análise (apenas os mais promissores serão processados), alcançamos um aumento tremendo na velocidade do algoritmo.
Mas ainda existem muitos vértices processados. Encontrar o comprimento de um vetor é uma operação cara que envolve o cálculo da raiz quadrada. Portanto, usaremos um cálculo simplificado para a heurística.
Vamos criar um vetor inteiro:
public readonly struct Vector2Int : IEquatable<Vector2Int>
{
private static readonly double Sqr = Math.Sqrt(2);
public Vector2Int(int x, int y)
{
X = x;
Y = y;
}
public int X { get; }
public int Y { get; }
/// <summary>
/// Estimated path distance without obstacles.
/// </summary>
public double DistanceEstimate()
{
int linearSteps = Math.Abs(Math.Abs(Y) - Math.Abs(X));
int diagonalSteps = Math.Max(Math.Abs(Y), Math.Abs(X)) - linearSteps;
return linearSteps + Sqr * diagonalSteps;
}
public static Vector2Int operator +(Vector2Int a, Vector2Int b)
=> new Vector2Int(a.X + b.X, a.Y + b.Y);
public static Vector2Int operator -(Vector2Int a, Vector2Int b)
=> new Vector2Int(a.X - b.X, a.Y - b.Y);
public static bool operator ==(Vector2Int a, Vector2Int b)
=> a.X == b.X && a.Y == b.Y;
public static bool operator !=(Vector2Int a, Vector2Int b)
=> !(a == b);
public bool Equals(Vector2Int other)
=> X == other.X && Y == other.Y;
public override bool Equals(object obj)
{
if (!(obj is Vector2Int))
return false;
var other = (Vector2Int) obj;
return X == other.X && Y == other.Y;
}
public override int GetHashCode()
=> HashCode.Combine(X, Y);
public override string ToString()
=> $"({X}, {Y})";
}Uma estrutura padrão para armazenar um par de coordenadas. Aqui, vemos o cache de raiz quadrada para que possa ser calculado apenas uma vez. A interface IEquatable nos permite comparar os vetores entre si sem ter que traduzir Vector2Int para o objeto e vice-versa. Isso irá acelerar muito nosso algoritmo e eliminar alocações desnecessárias.
DistanceEstimate () é usado para estimar a distância aproximada ao alvo calculando o número de transições retas e diagonais. Uma forma alternativa é comum:
return Math.Max(Math.Abs(X), Math.Abs(Y))Esta opção funcionará ainda mais rápido, mas isso é compensado pela baixa precisão da estimativa da distância diagonal.
Agora que temos uma ferramenta para trabalhar com coordenadas, vamos criar um objeto que representa o topo do gráfico:
internal class PathNode
{
public PathNode(Vector2Int position, double traverseDist, double heuristicDist, PathNode parent)
{
Position = position;
TraverseDistance = traverseDist;
Parent = parent;
EstimatedTotalCost = TraverseDistance + heuristicDist;
}
public Vector2Int Position { get; }
public double TraverseDistance { get; }
public double EstimatedTotalCost { get; }
public PathNode Parent { get; }
}No Parent registraremos o vértice anterior para cada novo: isso ajudará na construção do caminho final por pontos. Além das coordenadas, também salvamos a distância percorrida e o custo estimado do caminho para que possamos selecionar os vértices mais promissores para processamento.
Esta aula implora por melhorias, mas vamos voltar a ela mais tarde. Por enquanto, vamos desenvolver um método que gere os vizinhos do vértice:
internal static class NodeExtensions
{
private static readonly (Vector2Int position, double cost)[] NeighboursTemplate = {
(new Vector2Int(1, 0), 1),
(new Vector2Int(0, 1), 1),
(new Vector2Int(-1, 0), 1),
(new Vector2Int(0, -1), 1),
(new Vector2Int(1, 1), Math.Sqrt(2)),
(new Vector2Int(1, -1), Math.Sqrt(2)),
(new Vector2Int(-1, 1), Math.Sqrt(2)),
(new Vector2Int(-1, -1), Math.Sqrt(2))
};
public static IEnumerable<PathNode> GenerateNeighbours(this PathNode parent, Vector2Int target)
{
foreach ((Vector2Int position, double cost) in NeighboursTemplate)
{
Vector2Int nodePosition = position + parent.Position;
double traverseDistance = parent.TraverseDistance + cost;
double heuristicDistance = (position - target).DistanceEstimate();
yield return new PathNode(nodePosition, traverseDistance, heuristicDistance, parent);
}
}
}NeighboursTemplate - um modelo predefinido para criar vizinhos lineares e diagonais do ponto desejado. Também leva em consideração o aumento do custo das transições diagonais.
GenerateNeighbors - Um gerador que atravessa o NeighboursTemplate e retorna um novo vértice para todos os oito lados adjacentes.
Seria possível empurrar a funcionalidade dentro do PathNode, mas parece uma pequena violação do SRP. E também não quero adicionar funcionalidade de terceiros dentro do próprio algoritmo: manteremos as classes o mais compactas possível.
É hora de enfrentar a principal aula de descoberta de caminhos!
public class Path
{
private readonly List<PathNode> frontier = new List<PathNode>();
private readonly List<Vector2Int> ignoredPositions = new List<Vector2Int>();
public IReadOnlyCollection<Vector2Int> Calculate(Vector2Int start, Vector2Int target,
IReadOnlyCollection<Vector2Int> obstacles) {...}
private bool GenerateNodes(Vector2Int start, Vector2Int target,
IEnumerable<Vector2Int> obstacles, out PathNode node)
{
frontier.Clear();
ignoredPositions.Clear();
ignoredPositions.AddRange(obstacles);
// Add starting point.
frontier.Add(new PathNode(start, 0, 0, null));
while (frontier.Any())
{
// Find node with lowest estimated cost.
var lowest = frontier.Min(a => a.EstimatedTotalCost);
PathNode current = frontier.First(a => a.EstimatedTotalCost == lowest);
ignoredPositions.Add(current.Position);
if (current.Position.Equals(target))
{
node = current;
return true;
}
GenerateFrontierNodes(current, target);
}
// All nodes analyzed - no path detected.
node = null;
return false;
}
private void GenerateFrontierNodes(PathNode parent, Vector2Int target)
{
foreach (PathNode newNode in parent.GenerateNeighbours(target))
{
// Position is already checked or occupied by an obstacle.
if (ignoredPositions.Contains(newNode.Position)) continue;
// Node is not present in queue.
var node = frontier.FirstOrDefault(a => a.Position == newNode.Position);
if (node == null)
frontier.Add(newNode);
// Node is present in queue and new optimal path is detected.
else if (newNode.TraverseDistance < node.TraverseDistance)
{
frontier.Remove(node);
frontier.Add(newNode);
}
}
}
}GenerateNodes trabalha com duas coleções: frontier, que contém uma fila de vértices para análise, e ignorePositions, à qual são adicionados vértices já processados.
Cada iteração do loop encontra o vértice mais promissor, verifica se chegamos ao ponto final e gera novos vizinhos para este vértice.
E toda essa beleza cabe em 50 linhas.
Resta implementar a interface:
public IReadOnlyCollection<Vector2Int> Calculate(Vector2Int start, Vector2Int target,
IReadOnlyCollection<Vector2Int> obstacles)
{
if (!GenerateNodes(start, target, obstacles, out PathNode node))
return Array.Empty<Vector2Int>();
var output = new List<Vector2Int>();
while (node.Parent != null)
{
output.Add(node.Position);
node = node.Parent;
}
output.Add(start);
return output.AsReadOnly();
}GenerateNodes nos retorna o vértice final e, como escrevemos um vizinho pai para cada um deles, é suficiente percorrer todos os pais até o vértice inicial e obter o caminho mais curto. Tudo está bem!
Ou não?
Otimização de algoritmo
1. PathNode
Vamos começar de forma simples. Vamos simplificar o PathNode:
internal readonly struct PathNode
{
public PathNode(Vector2Int position, Vector2Int target, double traverseDistance)
{
Position = position;
TraverseDistance = traverseDistance;
double heuristicDistance = (position - target).DistanceEstimate();
EstimatedTotalCost = traverseDistance + heuristicDistance;
}
public Vector2Int Position { get; }
public double TraverseDistance { get; }
public double EstimatedTotalCost { get; }
}Este é um wrapper de dados comum que também é criado com frequência. Não há razão para torná-lo uma classe e carregar memória toda vez que escrevemos um novo . Portanto, usaremos struct.
Mas há um problema: as estruturas não podem conter referências circulares para seu próprio tipo. Portanto, em vez de armazenar o Parent dentro do PathNode, precisamos de outra maneira de rastrear a construção de caminhos entre vértices. É fácil - vamos adicionar uma nova coleção à classe Path:
private readonly Dictionary<Vector2Int, Vector2Int> links;E modificamos ligeiramente a geração de vizinhos:
private void GenerateFrontierNodes(PathNode parent, Vector2Int target)
{
foreach (PathNode newNode in parent.GenerateNeighbours(target))
{
// Position is already checked or occupied by an obstacle.
if (ignoredPositions.Contains(newNode.Position)) continue;
// Node is not present in queue.
if (!frontier.TryGet(newNode.Position, out PathNode existingNode))
{
frontier.Enqueue(newNode);
links[newNode.Position] = parent.Position; // Add link to dictionary.
}
// Node is present in queue and new optimal path is detected.
else if (newNode.TraverseDistance < existingNode.TraverseDistance)
{
frontier.Modify(newNode);
links[newNode.Position] = parent.Position; // Add link to dictionary.
}
}
}Em vez de escrever o pai no próprio vértice, escrevemos a transição para o dicionário. Como bônus, o dicionário pode trabalhar diretamente com Vector2Int, e não com PathNode, já que precisamos apenas de coordenadas e nada mais.
Gerar o resultado dentro de Calculate também é simplificado:
public IReadOnlyCollection<Vector2Int> Calculate(Vector2Int start, Vector2Int target,
IReadOnlyCollection<Vector2Int> obstacles)
{
if (!GenerateNodes(start, target, obstacles))
return Array.Empty<Vector2Int>();
var output = new List<Vector2Int> {target};
while (links.TryGetValue(target, out target))
output.Add(target);
return output.AsReadOnly();
}2. NodeExtensions
A seguir, vamos lidar com a geração de vizinhos. IEnumerable, apesar de todos os seus benefícios, gera uma triste quantidade de lixo em muitas situações. Vamos nos livrar disso:
internal static class NodeExtensions
{
private static readonly (Vector2Int position, double cost)[] NeighboursTemplate = {
(new Vector2Int(1, 0), 1),
(new Vector2Int(0, 1), 1),
(new Vector2Int(-1, 0), 1),
(new Vector2Int(0, -1), 1),
(new Vector2Int(1, 1), Math.Sqrt(2)),
(new Vector2Int(1, -1), Math.Sqrt(2)),
(new Vector2Int(-1, 1), Math.Sqrt(2)),
(new Vector2Int(-1, -1), Math.Sqrt(2))
};
public static void Fill(this PathNode[] buffer, PathNode parent, Vector2Int target)
{
int i = 0;
foreach ((Vector2Int position, double cost) in NeighboursTemplate)
{
Vector2Int nodePosition = position + parent.Position;
double traverseDistance = parent.TraverseDistance + cost;
buffer[i++] = new PathNode(nodePosition, target, traverseDistance);
}
}
}Agora, nosso método de extensão não é um gerador: ele apenas preenche o buffer que é passado para ele como um argumento. O buffer é armazenado como outra coleção dentro do Path:
private const int MaxNeighbours = 8;
private readonly PathNode[] neighbours = new PathNode[MaxNeighbours];E é usado assim:
neighbours.Fill(parent, target);
foreach(var neighbour in neighbours)
{
// ...3. HashSet
Em vez de usar List, vamos usar HashSet:
private readonly HashSet<Vector2Int> ignoredPositions;É muito mais eficiente ao trabalhar com grandes coleções, o método ignorePositions.Contains () consome muitos recursos devido à frequência das chamadas. Uma simples mudança no tipo de coleção dará um aumento perceptível no desempenho.
4. BinaryHeap
Há um lugar em nossa implementação que desacelera o algoritmo dez vezes:
// Find node with lowest estimated cost.
var lowest = frontier.Min(a => a.EstimatedTotalCost);
PathNode current = frontier.First(a => a.EstimatedTotalCost == lowest);Listar em si é uma escolha ruim e usar o Linq torna as coisas piores.
Idealmente, queremos uma coleção com:
- Classificação automática.
- Baixo crescimento de complexidade assintótica.
- Operação de inserção rápida.
- Operação de remoção rápida.
- Fácil navegação pelos elementos.
SortedSet pode parecer uma boa opção, mas não sabe como conter duplicatas. Se escrevermos a classificação por EstimatedTotalCost, todos os vértices com o mesmo preço (mas com coordenadas diferentes!) Serão eliminados. Em áreas abertas com um pequeno número de obstáculos, isso não é assustador, além de acelerar o algoritmo, mas em labirintos estreitos, o resultado será rotas imprecisas e resultados falso-negativos.
Portanto, implementaremos nossa coleção - o heap binário ! A implementação clássica satisfaz 4 de 5 requisitos, e uma pequena modificação tornará esta coleção ideal para nosso caso.
A coleção é uma árvore parcialmente classificada com a complexidade das operações de inserção e exclusão igual a log (n) .
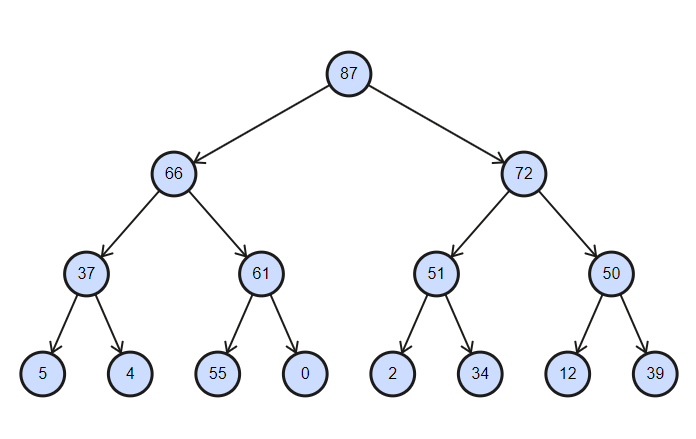
Pilha binária classificada em ordem decrescente
internal interface IBinaryHeap<in TKey, T>
{
void Enqueue(T item);
T Dequeue();
void Clear();
bool TryGet(TKey key, out T value);
void Modify(T value);
int Count { get; }
}Vamos escrever a parte fácil:
internal class BinaryHeap : IBinaryHeap<Vector2Int, PathNode>
{
private readonly IDictionary<Vector2Int, int> map;
private readonly IList<PathNode> collection;
private readonly IComparer<PathNode> comparer;
public BinaryHeap(IComparer<PathNode> comparer)
{
this.comparer = comparer;
collection = new List<PathNode>();
map = new Dictionary<Vector2Int, int>();
}
public int Count => collection.Count;
public void Clear()
{
collection.Clear();
map.Clear();
}
// ...
}Usaremos IComparer para classificação personalizada de vértices. IList é, na verdade, o repositório de vértices com o qual trabalharemos. Precisamos do IDictionary para acompanhar os índices dos vértices para sua rápida remoção (a implementação padrão do heap binário nos permite trabalhar convenientemente apenas com o elemento superior).
Vamos adicionar um elemento:
public void Enqueue(PathNode item)
{
collection.Add(item);
int i = collection.Count - 1;
map[item.Position] = i;
// Sort nodes from bottom to top.
while(i > 0)
{
int j = (i - 1) / 2;
if (comparer.Compare(collection[i], collection[j]) <= 0)
break;
Swap(i, j);
i = j;
}
}
private void Swap(int i, int j)
{
PathNode temp = collection[i];
collection[i] = collection[j];
collection[j] = temp;
map[collection[i].Position] = i;
map[collection[j].Position] = j;
}Cada novo elemento é adicionado à última célula da árvore, após o que é parcialmente classificado de baixo para cima: por nós do novo elemento à raiz, até que o menor elemento seja o mais alto possível. Como nem toda a coleção é classificada, mas apenas os nós intermediários entre o topo e o último, a operação tem o log de complexidade (n) .
Obtendo um item:
public PathNode Dequeue()
{
if (collection.Count == 0) return default;
PathNode result = collection.First();
RemoveRoot();
map.Remove(result.Position);
return result;
}
private void RemoveRoot()
{
collection[0] = collection.Last();
map[collection[0].Position] = 0;
collection.RemoveAt(collection.Count - 1);
// Sort nodes from top to bottom.
var i = 0;
while(true)
{
int largest = LargestIndex(i);
if (largest == i)
return;
Swap(i, largest);
i = largest;
}
}
private int LargestIndex(int i)
{
int leftInd = 2 * i + 1;
int rightInd = 2 * i + 2;
int largest = i;
if (leftInd < collection.Count
&& comparer.Compare(collection[leftInd], collection[largest]) > 0)
largest = leftInd;
if (rightInd < collection.Count
&& comparer.Compare(collection[rightInd], collection[largest]) > 0)
largest = rightInd;
return largest;
}Por analogia com a adição: o elemento raiz é removido e o último é colocado em seu lugar. Em seguida, uma classificação parcial de cima para baixo troca os itens de forma que o menor fique no topo.
Depois disso, implementamos a busca por um elemento e o alteramos:
public bool TryGet(Vector2Int key, out PathNode value)
{
if (!map.TryGetValue(key, out int index))
{
value = default;
return false;
}
value = collection[index];
return true;
}
public void Modify(PathNode value)
{
if (!map.TryGetValue(value.Position, out int index))
throw new KeyNotFoundException(nameof(value));
collection[index] = value;
}Não há nada complicado aqui: procuramos o índice do elemento através do dicionário, após o que o acessamos diretamente.
Versão genérica do heap:
internal class BinaryHeap<TKey, T> : IBinaryHeap<TKey, T> where TKey : IEquatable<TKey>
{
private readonly IDictionary<TKey, int> map;
private readonly IList<T> collection;
private readonly IComparer<T> comparer;
private readonly Func<T, TKey> lookupFunc;
public BinaryHeap(IComparer<T> comparer, Func<T, TKey> lookupFunc, int capacity)
{
this.comparer = comparer;
this.lookupFunc = lookupFunc;
collection = new List<T>(capacity);
map = new Dictionary<TKey, int>(capacity);
}
public int Count => collection.Count;
public void Enqueue(T item)
{
collection.Add(item);
int i = collection.Count - 1;
map[lookupFunc(item)] = i;
while(i > 0)
{
int j = (i - 1) / 2;
if (comparer.Compare(collection[i], collection[j]) <= 0)
break;
Swap(i, j);
i = j;
}
}
public T Dequeue()
{
if (collection.Count == 0) return default;
T result = collection.First();
RemoveRoot();
map.Remove(lookupFunc(result));
return result;
}
public void Clear()
{
collection.Clear();
map.Clear();
}
public bool TryGet(TKey key, out T value)
{
if (!map.TryGetValue(key, out int index))
{
value = default;
return false;
}
value = collection[index];
return true;
}
public void Modify(T value)
{
if (!map.TryGetValue(lookupFunc(value), out int index))
throw new KeyNotFoundException(nameof(value));
collection[index] = value;
}
private void RemoveRoot()
{
collection[0] = collection.Last();
map[lookupFunc(collection[0])] = 0;
collection.RemoveAt(collection.Count - 1);
var i = 0;
while(true)
{
int largest = LargestIndex(i);
if (largest == i)
return;
Swap(i, largest);
i = largest;
}
}
private void Swap(int i, int j)
{
T temp = collection[i];
collection[i] = collection[j];
collection[j] = temp;
map[lookupFunc(collection[i])] = i;
map[lookupFunc(collection[j])] = j;
}
private int LargestIndex(int i)
{
int leftInd = 2 * i + 1;
int rightInd = 2 * i + 2;
int largest = i;
if (leftInd < collection.Count && comparer.Compare(collection[leftInd], collection[largest]) > 0) largest = leftInd;
if (rightInd < collection.Count && comparer.Compare(collection[rightInd], collection[largest]) > 0) largest = rightInd;
return largest;
}
}Agora, nosso pathfinding tem uma velocidade decente e quase não há geração de lixo sobrando. O fim está próximo!
5. Coleções reutilizáveis
O algoritmo está sendo desenvolvido visando a capacidade de chamá-lo dezenas de vezes por segundo. A geração de qualquer lixo é categoricamente inaceitável: um coletor de lixo carregado pode (e irá!) Causar reduções periódicas no desempenho.
Todas as coleções, exceto a saída, já são declaradas uma vez quando a classe é criada, e colocaremos a última lá também:
private const int MaxNeighbours = 8;
private readonly PathNode[] neighbours = new PathNode[MaxNeighbours];
private readonly IBinaryHeap<Vector2Int, PathNode> frontier;
private readonly HashSet<Vector2Int> ignoredPositions;
private readonly IList<Vector2Int> output;
private readonly IDictionary<Vector2Int, Vector2Int> links;
public Path()
{
var comparer = Comparer<PathNode>.Create((a, b) => b.EstimatedTotalCost.CompareTo(a.EstimatedTotalCost));
frontier = new BinaryHeap(comparer);
ignoredPositions = new HashSet<Vector2Int>();
output = new List<Vector2Int>();
links = new Dictionary<Vector2Int, Vector2Int>();
}O método público assume o seguinte formato:
public IReadOnlyCollection<Vector2Int> Calculate(Vector2Int start, Vector2Int target,
IReadOnlyCollection<Vector2Int> obstacles)
{
if (!GenerateNodes(start, target, obstacles))
return Array.Empty<Vector2Int>();
output.Clear();
output.Add(target);
while (links.TryGetValue(target, out target))
output.Add(target);
return output.AsReadOnly();
}E não se trata apenas de criar coleções! As coleções mudam dinamicamente sua capacidade quando preenchidas; se o caminho for longo, o redimensionamento ocorrerá dezenas de vezes. Isso consome muita memória. Quando limpamos as coleções e as reutilizamos sem declarar novas, elas mantêm sua capacidade. A construção do primeiro caminho criará muito lixo ao inicializar coleções e alterar suas capacidades, mas as chamadas subsequentes funcionarão bem sem quaisquer alocações (desde que o comprimento de cada caminho calculado seja mais ou menos o mesmo, sem distorções acentuadas). Daí o próximo ponto:
6. (Bônus) Anúncio do tamanho das coleções
Uma série de perguntas surgem imediatamente:
- É melhor descarregar a carga para o construtor da classe Path ou deixá-la na primeira chamada para o pathfinder?
- Qual a capacidade de alimentar as coleções?
- É mais barato anunciar uma capacidade maior imediatamente ou deixar a coleção expandir por conta própria?
A terceira pode ser respondida de imediato: se tivermos centenas e milhares de células para encontrar um caminho, será definitivamente mais barato atribuir imediatamente um determinado tamanho às nossas coleções.
As outras duas perguntas são mais difíceis de responder. A resposta a essas perguntas precisa ser determinada empiricamente para cada caso de uso. Se ainda decidirmos mover a carga para o construtor, então é hora de adicionar um limite no número de etapas ao nosso algoritmo:
public Path(int maxSteps)
{
this.maxSteps = maxSteps;
var comparer = Comparer<PathNode>.Create((a, b) => b.EstimatedTotalCost.CompareTo(a.EstimatedTotalCost));
frontier = new BinaryHeap(comparer, maxSteps);
ignoredPositions = new HashSet<Vector2Int>(maxSteps);
output = new List<Vector2Int>(maxSteps);
links = new Dictionary<Vector2Int, Vector2Int>(maxSteps);
}Dentro de GenerateNodes, corrija o loop:
var step = 0;
while (frontier.Count > 0 && step++ <= maxSteps)
{
// ...
}Assim, as coleções são imediatamente atribuídas a uma capacidade igual ao caminho máximo. Algumas coleções contêm não apenas os nós percorridos, mas também seus vizinhos: para tais coleções, você pode usar uma capacidade 4-5 vezes maior do que a especificada.
Pode parecer um pouco demais, mas para caminhos próximos ao máximo declarado, a atribuição do tamanho das coleções gasta metade a três vezes menos memória do que a expansão dinâmica. Por outro lado, se você atribuir valores muito grandes ao valor maxSteps e gerar caminhos curtos, essa inovação só causará danos. Ah, e você não deve tentar usar int.MaxValue!
A solução ideal seria criar dois construtores, um dos quais define a capacidade inicial das coleções. Então, nossa classe pode ser usada em ambos os casos sem modificá-la.
O que mais você pode fazer?
- .
- XML-.
- GetHashCode Vector2Int. , , , .
- , . .
- IComparable PathNode EqualityComparer. .
- : , . , , .
- Altere a assinatura do método em nossa interface para refletir melhor sua essência:
bool Calculate(Vector2Int start, Vector2Int target, IReadOnlyCollection<Vector2Int> obstacles, out IReadOnlyCollection<Vector2Int> path);
Assim, o método mostra claramente a lógica de seu funcionamento, enquanto o método original deveria ter sido chamado assim: CalculateOrReturnEmpty .
A versão final da classe Path:
/// <summary>
/// Reusable A* path finder.
/// </summary>
public class Path : IPath
{
private const int MaxNeighbours = 8;
private readonly PathNode[] neighbours = new PathNode[MaxNeighbours];
private readonly int maxSteps;
private readonly IBinaryHeap<Vector2Int, PathNode> frontier;
private readonly HashSet<Vector2Int> ignoredPositions;
private readonly List<Vector2Int> output;
private readonly IDictionary<Vector2Int, Vector2Int> links;
/// <summary>
/// Creation of new path finder.
/// </summary>
/// <exception cref="ArgumentOutOfRangeException"></exception>
public Path(int maxSteps = int.MaxValue, int initialCapacity = 0)
{
if (maxSteps <= 0)
throw new ArgumentOutOfRangeException(nameof(maxSteps));
if (initialCapacity < 0)
throw new ArgumentOutOfRangeException(nameof(initialCapacity));
this.maxSteps = maxSteps;
var comparer = Comparer<PathNode>.Create((a, b) => b.EstimatedTotalCost.CompareTo(a.EstimatedTotalCost));
frontier = new BinaryHeap<Vector2Int, PathNode>(comparer, a => a.Position, initialCapacity);
ignoredPositions = new HashSet<Vector2Int>(initialCapacity);
output = new List<Vector2Int>(initialCapacity);
links = new Dictionary<Vector2Int, Vector2Int>(initialCapacity);
}
/// <summary>
/// Calculate a new path between two points.
/// </summary>
/// <exception cref="ArgumentNullException"></exception>
public bool Calculate(Vector2Int start, Vector2Int target,
IReadOnlyCollection<Vector2Int> obstacles,
out IReadOnlyCollection<Vector2Int> path)
{
if (obstacles == null)
throw new ArgumentNullException(nameof(obstacles));
if (!GenerateNodes(start, target, obstacles))
{
path = Array.Empty<Vector2Int>();
return false;
}
output.Clear();
output.Add(target);
while (links.TryGetValue(target, out target)) output.Add(target);
path = output;
return true;
}
private bool GenerateNodes(Vector2Int start, Vector2Int target, IReadOnlyCollection<Vector2Int> obstacles)
{
frontier.Clear();
ignoredPositions.Clear();
links.Clear();
frontier.Enqueue(new PathNode(start, target, 0));
ignoredPositions.UnionWith(obstacles);
var step = 0;
while (frontier.Count > 0 && step++ <= maxSteps)
{
PathNode current = frontier.Dequeue();
ignoredPositions.Add(current.Position);
if (current.Position.Equals(target)) return true;
GenerateFrontierNodes(current, target);
}
// All nodes analyzed - no path detected.
return false;
}
private void GenerateFrontierNodes(PathNode parent, Vector2Int target)
{
neighbours.Fill(parent, target);
foreach (PathNode newNode in neighbours)
{
// Position is already checked or occupied by an obstacle.
if (ignoredPositions.Contains(newNode.Position)) continue;
// Node is not present in queue.
if (!frontier.TryGet(newNode.Position, out PathNode existingNode))
{
frontier.Enqueue(newNode);
links[newNode.Position] = parent.Position;
}
// Node is present in queue and new optimal path is detected.
else if (newNode.TraverseDistance < existingNode.TraverseDistance)
{
frontier.Modify(newNode);
links[newNode.Position] = parent.Position;
}
}
}
}Link para o código fonte