Recentemente, colegas na "loja" começaram a me perguntar de forma independente: como obter todos os canais Bluetooth de um receptor SDR simultaneamente? A largura de banda permite, há SDR com uma largura de banda de saída de 80 MHz ou mais. Você pode, é claro, fazer isso em FPGA, mas o tempo de desenvolvimento será bem longo. Eu sei há muito tempo que é muito fácil fazer isso em uma GPU, mas é isso!
O padrão Bluetooth define a camada física em duas versões: Classic e Low Energy. A especificação está aqui . O documento é terrivelmente grande; lê-lo por inteiro é perigoso para o cérebro. Felizmente, grandes empresas de instrumentação têm os meios para criar documentos visuais sobre um tópico. Tektronix e National Instruments , por exemplo. Não tenho absolutamente nenhuma chance de competir com eles em termos de qualidade de apresentação do material. Se você estiver interessado, siga os links.
Tudo que eu preciso saber sobre a camada física para criar um filtro multicanal é o passo da grade de frequência e a taxa de modulação. Eles são tabulados em um dos seguintes documentos:
, 80 79 1 , , 40 2 . 1 2 , .
, .
Bluetooth Classic Bluetooth Low Energy. , . , "" . . , .
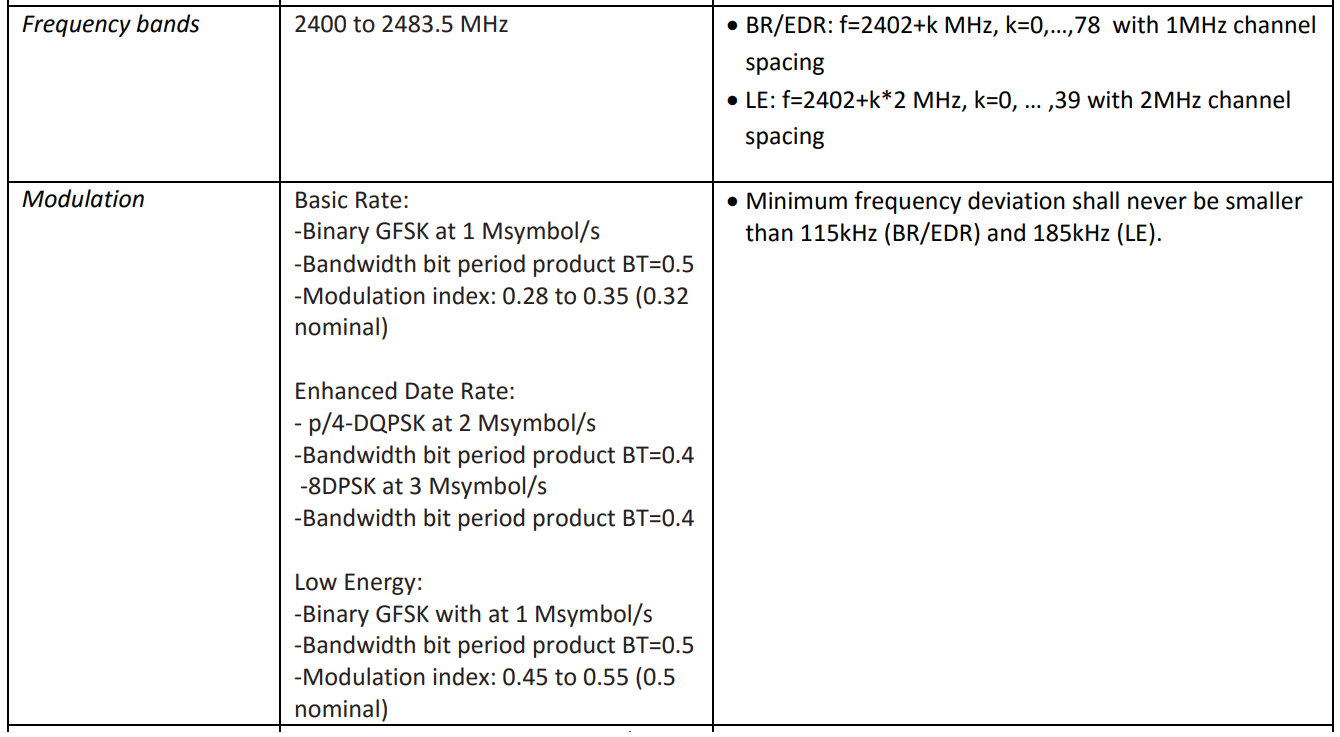
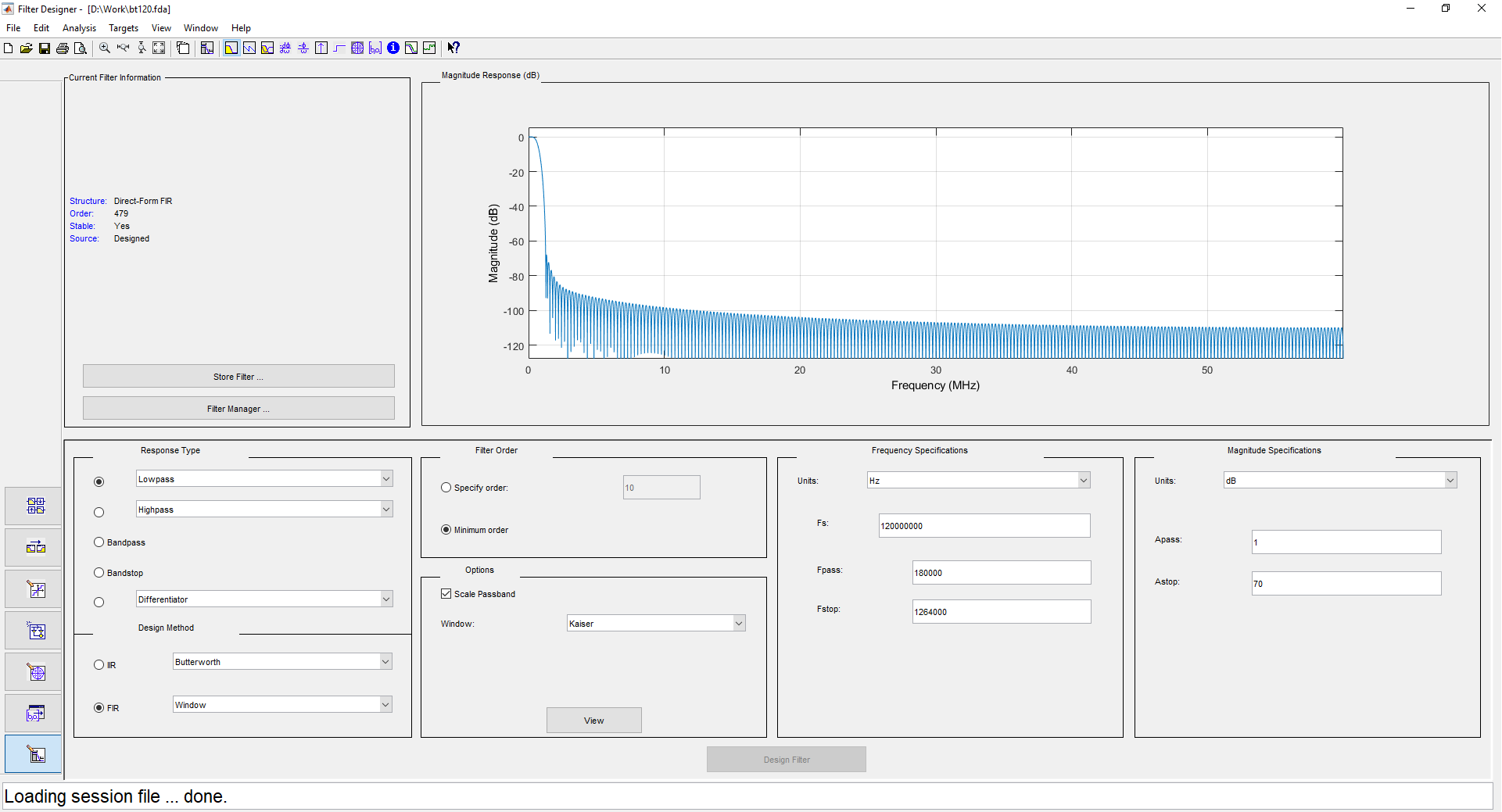
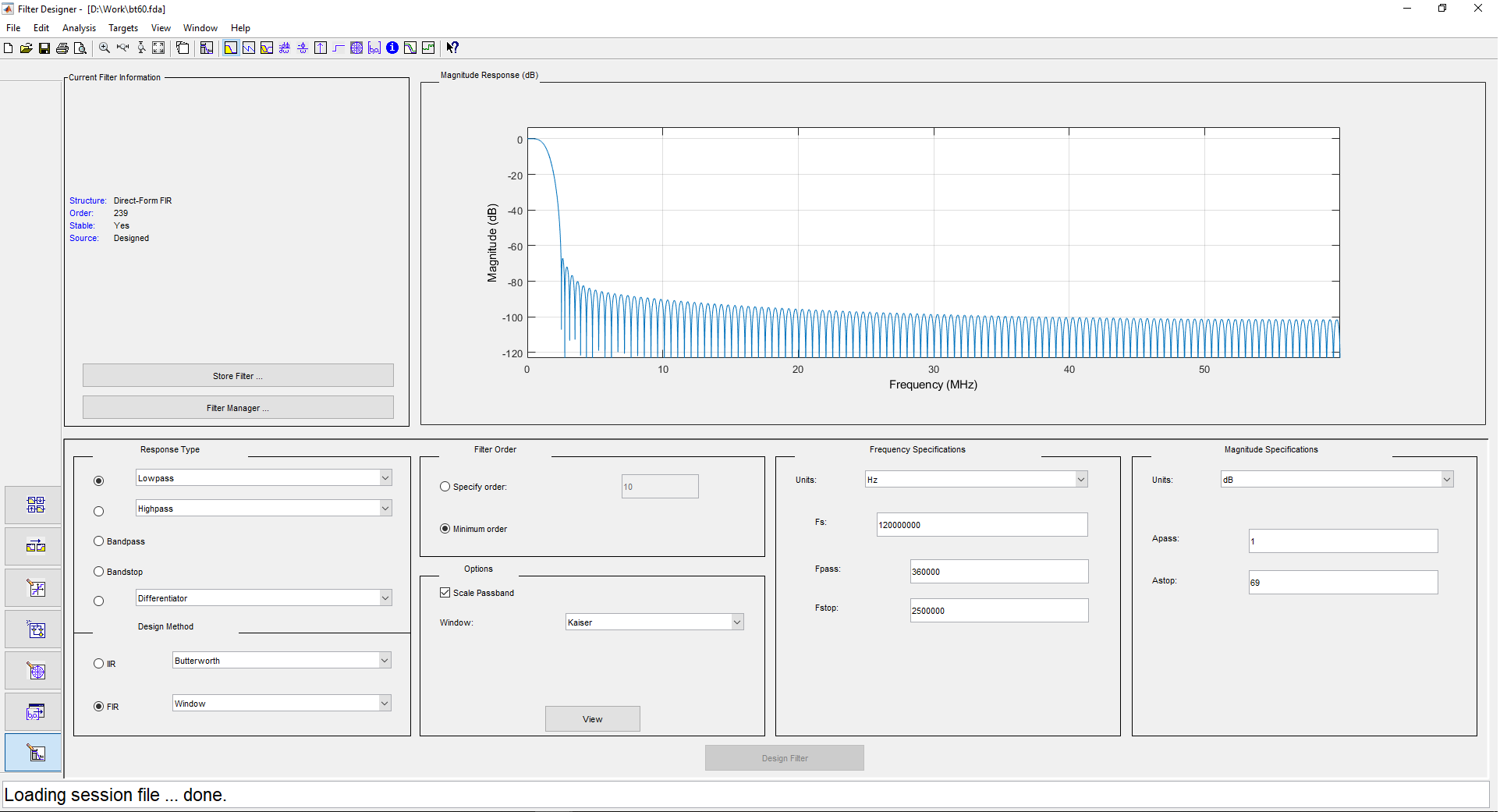
1 ( ) 500 , 480 . 2 1 240 , . . filterDesigner -header:
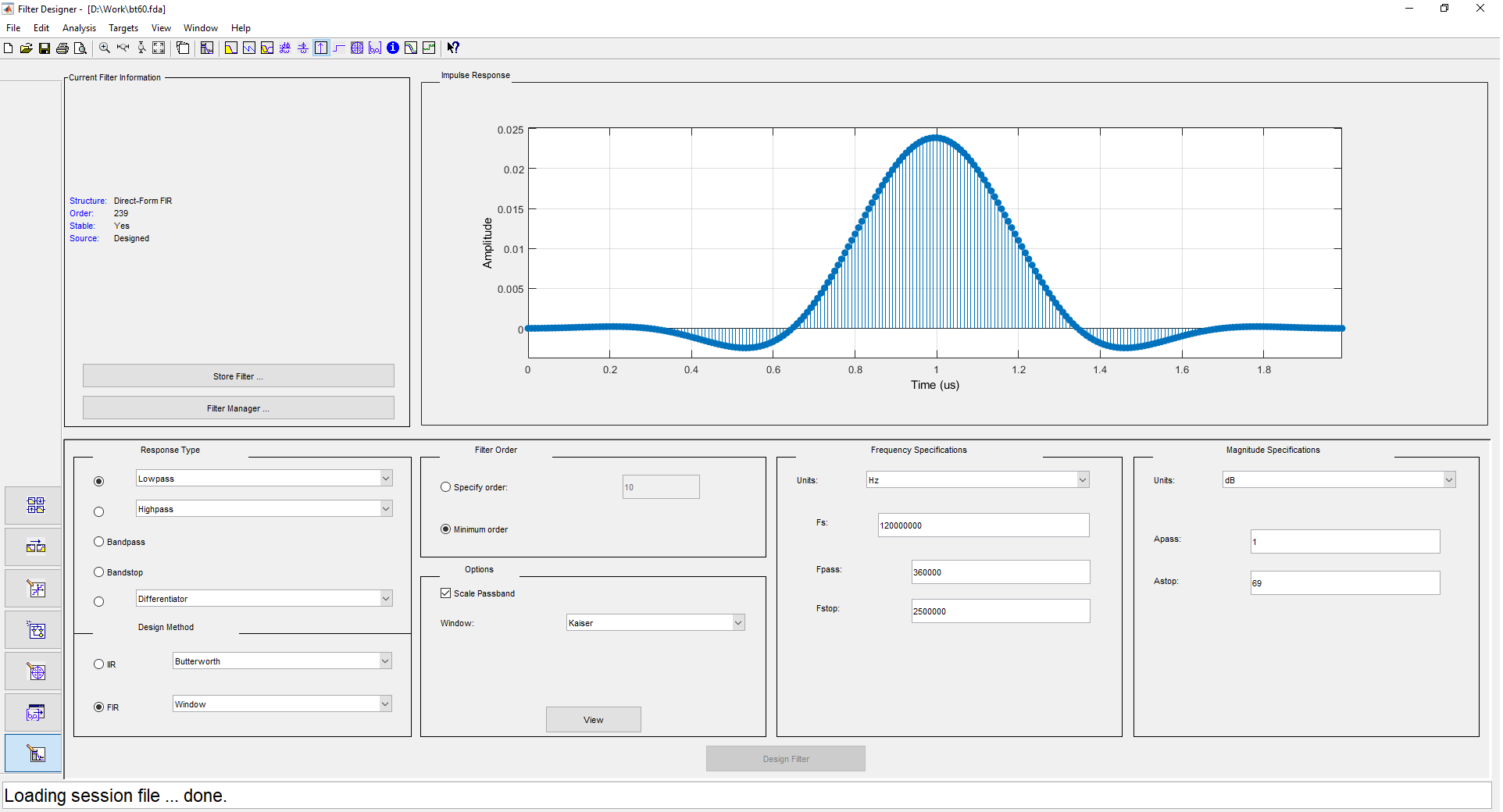
: DDC (Digital Down Converter). , . — - . .
GPU : , CUDA . Polyphase or WOLA (Weight, Overlap and Add) FFT Filterbank. . , 11 ( ), :
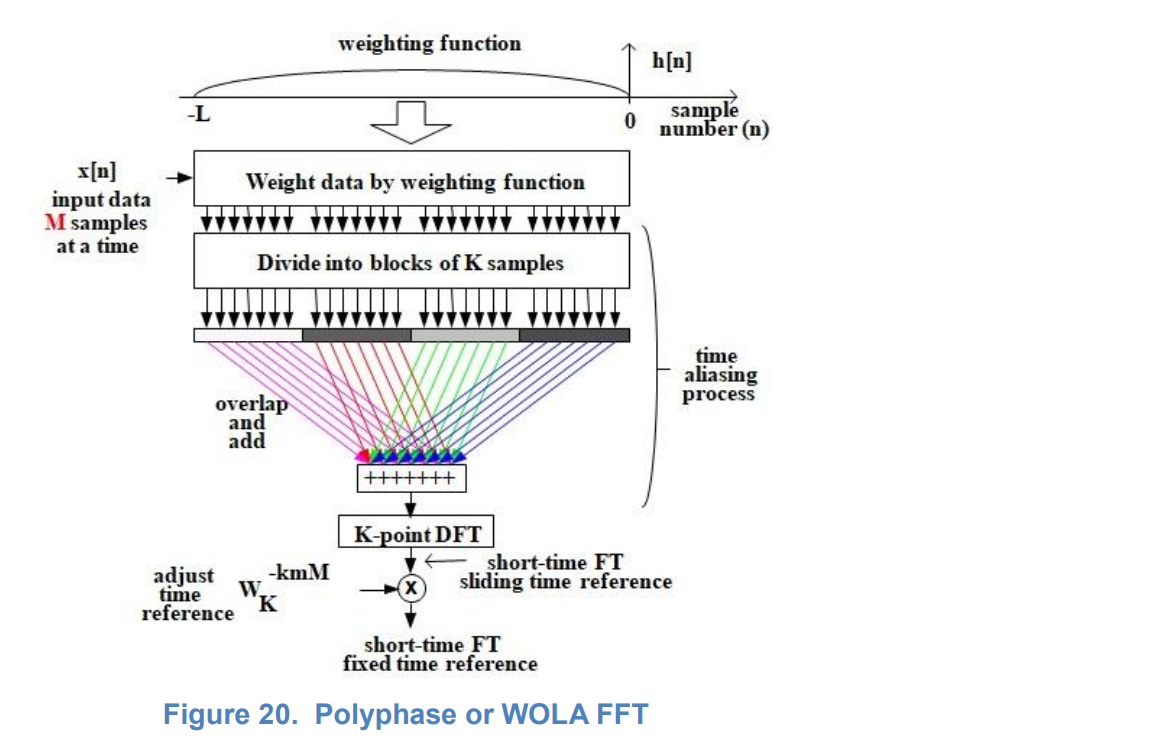
. , . , , . , . , , . . , ( ), . , . , , ,
, , .
, . " " FMC126P. . FMC AD9371 100 . .
- GPU GTX 1050. (, : , , ). .
, - . GPU. , .
, , :
__global__ void cuComplexMultiplyWindowKernel(const cuComplex *data, const float *window, size_t windowSize, cuComplex *result) {
__shared__ cuComplex multiplicationResult[480];
multiplicationResult[threadIdx.x] = cuComplexMultiplyFloat(data[threadIdx.x + windowSize / 4 * blockIdx.x], window[threadIdx.x]);
__syncthreads();
cuComplex sum;
sum.x = sum.y = 0;
if (threadIdx.x < windowSize / 4) {
for(int i = 0; i < 4; i++) {
sum = cuComplexAdd(sum, multiplicationResult[threadIdx.x + i * windowSize / 4]);
}
result[threadIdx.x + windowSize / 4 * blockIdx.x] = sum;
}
}
cudaError_t cuComplexMultiplyWindow(const cuComplex *data, const float *window, size_t windowSize, cuComplex *result, size_t dataSize, cudaStream_t stream) {
size_t windowStep = windowSize / 4;
cuComplexMultiplyWindowKernel<<<dataSize / windowStep - 3, windowSize, 1024, stream>>>(data, window, windowSize, result);
return cudaGetLastError();
}
, , , , .
. AD9371 2450 , .
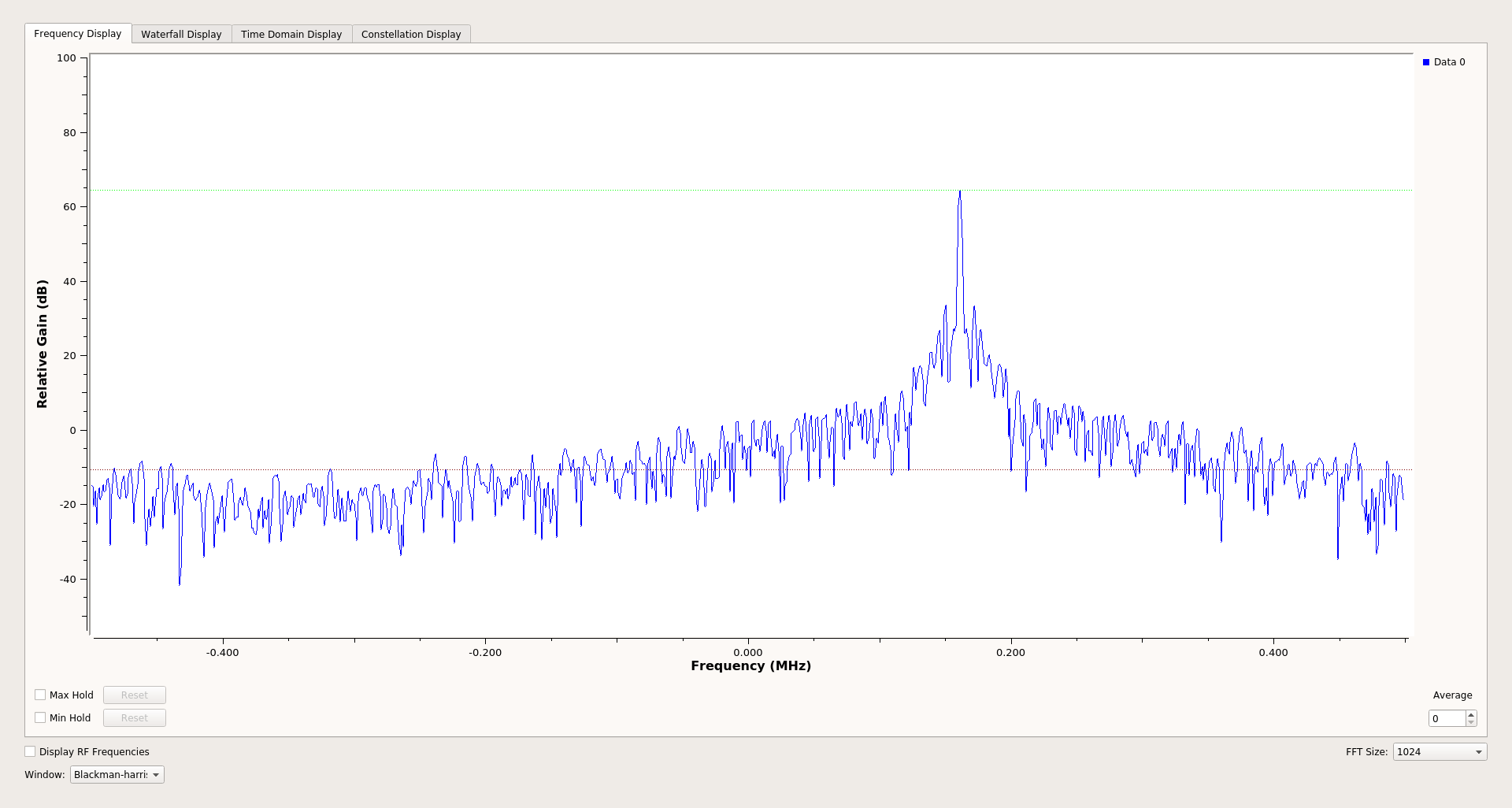
: XRTX , - .
gaudima, !