Agora precisamos aprender a descrever a lógica que operará nos dados recebidos e emitir um veredicto sobre se nossa regra funcionará em uma determinada situação. É a esta seção da regra e seus recursos que este artigo é dedicado. A descrição da seção de lógica de detecção é a parte mais importante da sintaxe, cujo conhecimento é necessário para entender as regras existentes e escrever as suas próprias.
Na próxima publicação, nos deteremos em detalhes na descrição de meta-informação (atributos que são informativos ou de natureza infraestrutural, como uma descrição ou identificador) e coleções de regras. Siga nossas publicações!
Descrição da lógica de detecção (atributo de detecção)
As condições de ativação das regras são definidas no atributo de detecção . Seus subcampos descrevem a parte técnica principal da regra. É importante observar que uma regra pode ter apenas uma parte descritiva e várias origens de registro e detecção. Como a seção de detecção descreve o critério de acionamento com base nos dados da seção de fontes, essas duas seções têm um 1 a 1.
Em geral, o conteúdo do campo de detecção consiste em duas partes lógicas:
- uma descrição das suposições sobre os campos do evento (IDs de pesquisa),
- a relação lógica entre essas descrições ( período de tempo e expressão no campo de condição ).

A descrição das suposições sobre o conteúdo dos campos do evento é feita especificando identificadores de pesquisa. Esse identificador pode ser um (como aqui ) ou pode haver vários deles (como aqui ).
A segunda parte pode ser de três tipos:
- a condição usual,
- uma condição com uma expressão agregada (como no exemplo acima),
- condição com a palavra-chave próximo .
A sintaxe dos elementos de cada parte é descrita na seção correspondente deste artigo.
IDs de pesquisa
Um identificador de pesquisa é um par de valores-chave, em que a chave é o nome do identificador de pesquisa e o valor é uma lista ou dicionário (também conhecido como array associativo). Por analogia com as linguagens de programação - lista ou mapa. O formato de especificação de listas e dicionários é definido pelo padrão YAML, que pode ser encontrado aqui . É importante notar que o formato de regra Sigma não fixa os nomes dos identificadores de pesquisa, mas na maioria das vezes você pode encontrar variações com a seleção de palavras.
Existem requisitos gerais que se aplicam a itens de lista e itens de dicionário:
- Todos os valores são tratados como strings que não diferenciam maiúsculas de minúsculas, ou seja, não há diferença entre letras maiúsculas e minúsculas.
- (wildcards) ‘*’ ‘?’. ‘*’ — ( ), ‘?’ — ( ).
- ‘\’, ‘\*’. , : ‘\\*’. .
- , .
- ‘ .
Identificador de pesquisa de lista de valores As
listas de valores contêm cadeias de caracteres que são pesquisadas em toda a mensagem do evento. Os elementos da lista são combinados com um OU lógico.
detection:
keywords:
- EVILSERVICE
- svchost.exe -n evil
condition: keywords

Exemplos de regras contendo identificadores de pesquisa como uma lista de valores:
- regras / web / web_apache_segfault.yml (a lista pode conter um elemento)
- regras / windows / powershell / powershell_clear_powershell_history.yml
- rules / linux / lnx_shell_susp_log_entries.yml
Identificador de pesquisa de dicionário
Os dicionários consistem em um conjunto de pares de valores-chave, onde a chave é o nome do campo do evento e o valor pode ser uma string, um número inteiro ou uma lista de um desses tipos (listas de strings ou números são combinadas com um OU lógico). Os conjuntos de dicionários são combinados por um E.
Esquema geral:
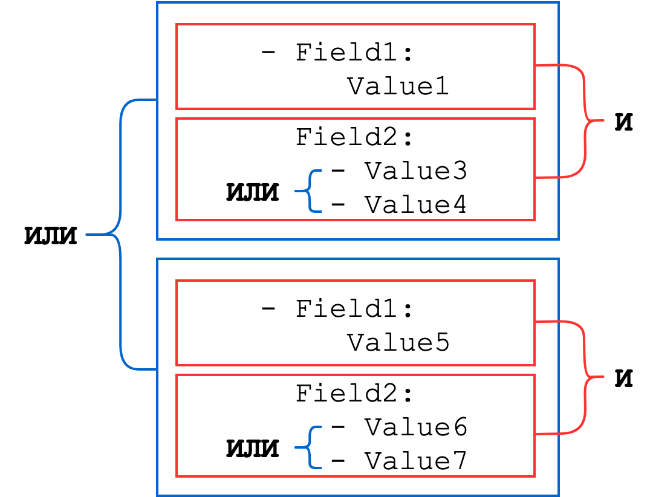
Vamos considerar vários exemplos.
Exemplo 1. Regras de regra de limpeza de log de eventos
/ windows / builtin / win_susp_security_eventlog_cleared.yml
Esta regra será acionada se o evento atender à condição:
EventID = 517 OR EventID = 1102
Na regra, tem a seguinte aparência:
detection:
selection:
EventID:
- 517
- 1102
condition: selection Aqui, a seleção é o nome do único identificador de pesquisa e o restante dos subcampos são seu valor, e esse valor é do tipo "dicionário". Neste dicionário, EventID é a chave e os números 517 e 1102 formam uma lista, que é o valor desta chave de dicionário.
Exemplo 2. Uma solicitação de tíquete suspeita, provavelmente regras Kerberoasting
/ windows / builtin / win_susp_rc4_kerberos.yml
Esta regra será acionada se o evento atender à condição:
EventID = 4679 AND TicketOptions = 0x40810000 AND TicketEncryption = 0x17 AND ServiceName não termina com um sinal '$'
Na regra, tem a seguinte aparência:
detection:
selection:
EventID: 4769
TicketOptions: '0x40810000'
TicketEncryption: '0x17'
reduction:
- ServiceName: '*$'
condition: selection and not reduction Valores de campo especiais
Existem dois valores de campo especiais que podem ser usados:
- Um valor vazio especificado por duas aspas simples ''
- O valor nulo especificado pela palavra-chave nula
Observação: um valor não vazio não pode ser especificado por meio da construção não nula
A aplicação desses valores depende do sistema SIEM de destino. Para descrever a condição não nula, você precisa criar um identificador de pesquisa separado com um valor vazio e tirar dele a negação da condição (o campo da condição é descrito no final do artigo). Considere outros exemplos de regras que usam a descrição de um campo vazio.
Exemplo 3. Lançamento suspeito de um fluxo remoto
rules / windows / sysmon / sysmon_password_dumper_lsass.yml
A regra especificada será acionada se o evento atender à condição:
EventID = 8 AND TargetImage = 'C: \ Windows \ System32 \ lsass.exe' E StartModule é um campo vazio
Na regra, tem a seguinte aparência:
detection:
selection:
EventID: 8
TargetImage: 'C:\Windows\System32\lsass.exe'
StartModule: null
condition: selection Exemplo 4. Gravando um arquivo executável em um fluxo de arquivo alternativo regras NTFS
/ windows / sysmon / sysmon_ads_executable.yml
A regra considerada é um exemplo da designação correta de um valor não vazio. Esta regra será acionada se o evento atender à condição:
EventID = 15 AND I
mphash != '00000000000000000000000000000000' Imphash
Na regra, tem a seguinte aparência:
detection:
selection:
EventID: 15
filter:
Imphash:
- '00000000000000000000000000000000'
- null
condition: selection and not filter Como mencionado acima, a negação agora deve ser colocada na condição (o campo da condição), e não nos identificadores de pesquisa.
Modificadores de valor
A interpretação dos valores de campo em uma regra pode ser alterada usando modificadores. Os modificadores são adicionados após o nome do campo, cada modificador é precedido por uma barra vertical (barra vertical) - “|”. Eles podem ser encadeados para construir cadeias (pipelines) de modificadores:

O valor do campo é modificado de acordo com a ordem dos modificadores na cadeia. Os modificadores podem ser de dois tipos: modificadores de transformação e de tipo.
Os modificadores de transformação são aqueles que convertem o valor do campo original em algum outro valor ou transformam a lógica para processar listas de valores em identificadores de pesquisa. Um exemplo do primeiro tipo são os modificadores Base64 e o segundo é o modificador all . Todos os modificadores serão discutidos com mais detalhes posteriormente.
Vamos dar uma olhada em cada um dos modificadores de transformação. Para maior clareza, mostraremos esquematicamente como exatamente este ou aquele modificador altera o valor inicial.
começa com
O modificador startswith é usado para combinar o início de uma string com o valor desejado.

Exemplos de uso:
- regras / windows / builtin / win_ad_replication_non_machine_account.yml
- regras / windows / process_creation / win_apt_winnti_mal_hk_jan20.yml
- regras / windows / powershell / powershell_downgrade_attack.yml
termina com
O modificador endswith é usado para combinar o final da string com o valor de pesquisa.

Exemplos de uso:
- regras / windows / process_creation / win_local_system_owner_account_discovery.yml
- regras / windows / sysmon / sysmon_minidumwritedump_lsass.yml
- regras / windows / process_creation / win_susp_odbcconf.yml
contém
O modificador contém verifica a ocorrência de uma substring no valor do campo. Na verdade, esse modificador converte o valor do campo da seguinte maneira:

Ou seja, se considerarmos os resultados da aplicação dos modificadores considerados, você pode escrever a seguinte fórmula:
startswith + endswith = contains
Exemplos:
- regras / windows / process_creation / win_hack_bloodhound.yml
- regras / windows / process_creation / win_mimikatz_command_line.yml
- regras / windows / sysmon / sysmon_webshell_creation_detect.yml
tudo
Normalmente, os elementos da folha são combinados com um OU lógico. O modificador all muda o OR lógico para o lógico E. Ou seja, todos os elementos da lista devem estar presentes. Vamos ver como as condições mudariam no esquema geral, que estava no início da seção:
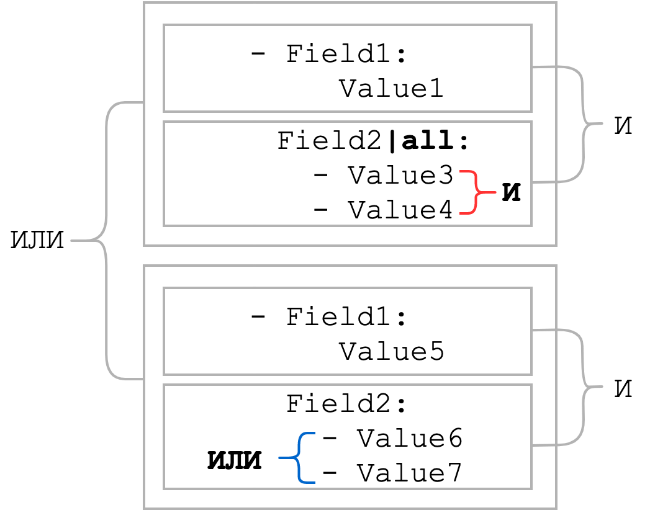
Como você pode ver, quando o modificador all foi aplicado, a conexão lógica entre os itens da lista tornou-se AND. Normalmente, o modificador all é usado em conjunto com o modificador contains. Esse grupo pode servir como um substituto para o padrão com metacaracteres curinga se a ordem das partes estáticas for desconhecida.
Exemplos de uso do modificador all :
- regras / windows / builtin / win_meterpreter_or_cobaltstrike_getsystem_service_installation.yml
- regras / windows / powershell / powershell_suspicious_profile_create.yml
- regras / windows / powershell / powershell_suspicious_download.yml
base64
Esse modificador é aplicado quando o valor do campo é codificado em Base64 e, para maior clareza, escrevemos o texto codificado na regra, e não a string Base64 resultante.

Este modificador assume uma correspondência exata do campo com a string codificada. Geralmente é mais útil identificar sinais de atividade suspeita nos dados originais do que procurar uma correspondência exata para o resultado codificado. Portanto, ainda não há exemplos de uso do modificador base64 .
base64offset
Devido à natureza da codificação Base64, você não pode usar um pipeline de base64 e contém para localizar uma substring codificada . O modificador base64offset é criado para esse propósito . É usado quando uma string é codificada em Base64 e queremos encontrar uma substring da string codificada. Além disso, os caracteres que circundam a substring desejada são desconhecidos de antemão, e o deslocamento da substring em relação ao início da string é desconhecido. Você pode ver claramente o que está em jogo aqui.
Quase sempre esse modificador é usado junto com o modificador contém :

Exemplos de uso:
- regras / windows / process_creation / win_encoded_frombase64string.yml
- regras / windows / process_creation / win_encoded_iex.yml
Importante! Os três modificadores de transformação de codificação a seguir são usados apenas em conjunto com os modificadores Base64.
utf16le ou largo
Os modificadores utf16le e wide são sinônimos. Eles transformam um campo de string na codificação UTF-16LE, ou seja
“123” -> 0x31 0x00 0x32 0x00 0x33 0x00.

utf16be
O modificador utf16be converte o valor da string do campo em UTF-16BE, ou seja
“123” -> 0x00 0x31 0x00 0x32 0x00 0x33.

utf16
O modificador utf16 adiciona uma marca de ordem de byte (BOM) e codifica uma string em UTF-16
“123” -> 0xFF 0xFE 0x31 0x00 0x32 0x00 0x33 0x00.

Atualmente, há apenas um modificador de tipo - re .
ré
Este modificador de tipo interpreta o valor do campo como um padrão de expressão regular. Até agora, ele só é compatível com o conversor para uma consulta Elasticsearch, portanto, praticamente não aparece nas regras públicas.
Exemplos de uso:
- regras / windows / process_creation / win_invoke_obfuscation_obfuscated_iex_commandline.yml
- regras / windows / builtin / win_invoke_obfuscation_obfuscated_iex_services.yml
- regras / windows / builtin / win_mal_creddumper.yml
Intervalo de tempo (atributo de intervalo de tempo)
Além disso, a lógica de detecção pode ser refinada especificando o intervalo de tempo durante o qual os identificadores de pesquisa devem aparecer. Abreviações padrão são usadas para denotar unidades de tempo:
15s (15 )
30m (30 )
12h (12 )
7d (7 )
3M (3 ) Exemplos de uso:
- regras / linux / modsecurity / modsec_mulitple_blocks.yml
- rules-unsupported / net_possible_dns_rebinding.yml
- regras / windows / builtin / win_rare_service_installs.yml
Descrição das condições de acionamento da regra (atributo de condição)
De acordo com a documentação oficial da Sigma, a parte da regra que contém a condição de disparo é a mais complexa e mudará com o tempo. As seguintes expressões estão disponíveis atualmente.
Operações lógicas E, OU
Eles são indicados pelas palavras - chave e e ou, respectivamente. Essas expressões são os principais elementos da construção de um relacionamento lógico entre os identificadores de pesquisa.
detection:
keywords1:
- EVILSERVICE
- svchost.exe -n evil
keywords2:
- SERVICEEVIL
- svchost.exe -n live
condition: keywords1 or keywords2 Exemplos de uso:
Um dos valores de ID de pesquisa / todos os valores de ID de pesquisa (1 / todos do identificador de pesquisa) O
mesmo que no caso anterior, se o ID de pesquisa
- 1 - OR lógico entre alternativas,
- all - lógico AND entre alternativas.
Por padrão,
condition: keywordssignifica que os valores listados no identificador de palavras-chave são lógicos OU, ou seja, é o mesmo que escrever condition: 1 of keywords. Se quisermos que os valores sejam combinados com um AND lógico, precisamos escrever condition: all of keywords.
Exemplos de uso:
Um dos IDs de pesquisa / todos os IDs de pesquisa (1 / todos eles)
OU lógico (1 deles) ou E lógico (todos eles) entre todos os IDs de pesquisa fornecidos. Por padrão, os IDs de pesquisa são vinculados por um E lógico, se forem elementos de um dicionário, ou um OU lógico, se forem elementos de uma lista. Para alterar essas relações, esta estrutura foi criada. Assim, a condição, condição: 1 deles, significa que pelo menos um dos identificadores de pesquisa deve aparecer no evento.
Exemplos de uso:
- regras / windows / process_creation / win_hack_bloodhound.yml
- regras / windows / powershell / powershell_psattack.yml
- regras / cloud / aws_ec2_download_userdata.yml
Um dos IDs de pesquisa que correspondem ao padrão de nome / todos os IDs de pesquisa que correspondem ao padrão de nome (1 / todos os padrões de identificador de pesquisa)
Igual ao parágrafo anterior, mas a seleção é limitada a identificadores de pesquisa cujos nomes correspondem ao padrão. Esses padrões são construídos usando o curinga * (qualquer número de caracteres) em uma posição específica no padrão de nome.
A sintaxe é a seguinte:
condition: 1 of selection*
condition: all of selection* Exemplos de uso:
- regras / windows / builtin / win_user_added_to_local_administrators.yml
- regras / windows / process_creation / win_susp_eventlog_clear.yml
- regras / cloud / aws_iam_backdoor_users_keys.yml
Negação lógica
Negativos lógicos são construídos usando a palavra-chave not . Conforme observado acima, a expressão “não vazio” deve ser especificada no campo de condição , e não na descrição do ID de pesquisa. O exemplo a seguir mostra claramente a versão correta da descrição da expressão "o valor do campo não está vazio".

Exemplos de uso:
- regras / windows / sysmon / sysmon_malware_backconnect_ports.yml
- regras / windows / process_creation / win_apt_gallium.yml
Tubo
A barra vertical (ou barra vertical) indica que o resultado da expressão será passado para uma função agregada, cujo resultado provavelmente será comparado a algum valor.
Esquema geral:
_ | _
condition: selection | count(category) by dst_ip > 30 Exemplos de uso:
- regras / windows / builtin / win_susp_failed_logons_single_source.yml
- regras / windows / other / win_rare_schtask_creation.yml
- regras / rede / net_high_dns_requests_rate.yml
Parênteses
Os parênteses são usados para especificar uma subexpressão. Isso pode ser útil para especificar a ordem em que uma expressão lógica é avaliada ou para negar um predicado que contém várias expressões. Eles têm a maior prioridade para a operação.
condition: selection and (keywords1 or keywords2)
condition: selection and not (filter1 or filter2) Exemplo de uso:
Expressões de função agregada
Expressões agregadas (ou expressões de função agregada) são usadas para quantificar os eventos que ocorreram.
Esquema de expressão agregada:

Todas as funções agregadas, exceto contagem, requerem um nome de campo como parâmetro. A função de contagem conta todos os eventos correspondentes se nenhum nome de campo for especificado. Se um nome de campo for especificado, a função contará valores diferentes neste campo. Por exemplo, a expressão a seguir conta o número de portas diferentes às quais as conexões foram feitas a partir de um endereço IP e, se esse número exceder 10, a regra será acionada:
condition: selection | count(dst_port) by src_ip > 10 Exemplos de uso:
- rules / linux / lnx_susp_failed_logons_single_source.yml
- regras / windows / other / win_rare_schtask_creation.yml
- regras / rede / net_susp_network_scan.yml
Expressão agregada perto
A palavra-chave near é usada para gerar uma consulta (se esta funcionalidade for suportada pelo sistema de destino e backend) que reconhece a ocorrência de todos os IDs de pesquisa especificados dentro de um intervalo de tempo especificado após encontrar o primeiro ID.
Esquema geral:
near search-id-1 [ [ and search-id-2 | and not search-id-3 ] ... ]
exemplo de sintaxe:
timeframe: 30s
condition: selector | near dllload1 and dllload2 and not exclusion As mesmas regras se aplicam à expressão de pesquisa após a palavra próxima e à expressão de pesquisa antes da barra vertical, que detalhamos acima.
Exemplos de uso:
- regras / windows / sysmon / sysmon_mimikatz_inmemory_detection.yml
- regras / windows / builtin / win_susp_samr_pwset.yml
A prioridade padrão das operações é:
- (expressão)
- X do padrão de pesquisa
- Não
- E
- Ou
- |
Assim, os parênteses têm a prioridade mais alta, e o tubo tem a mais baixa.
Observação: se vários campos de condição forem especificados, o valor final será obtido aplicando OR lógico a todos os valores de expressão.
Neste artigo, descrevemos a lógica de detecção. Acompanhe nossas postagens, no próximo artigo veremos os demais campos da regra. A maioria deles são de natureza informacional ou infraestrutural. Além dos campos com metainformações, vamos nos deter em tal característica da composição de regras, que é chamada de coleções de regras. Para as pessoas que não estão familiarizadas com as complexidades da linguagem YAML, considerar este aspecto da sintaxe será útil ao ler estranhos e escrever suas próprias regras.
Autor : Anton Kutepov, especialista do departamento de serviços especializados e desenvolvimento de Tecnologias Positivas (PT Expert Security Center)