Introdução
Este artigo descreve uma classificação de mesclagem adaptativa não recursiva estável chamada quadsort.
Troca quádrupla
Quadsort é baseado em uma troca quádrupla. Tradicionalmente, a maioria dos algoritmos de classificação é baseada na troca binária, onde duas variáveis são classificadas usando uma terceira variável temporária. Geralmente é assim:
if (val[0] > val[1])
{
tmp[0] = val[0];
val[0] = val[1];
val[1] = tmp[0];
}Em uma troca quádrupla, a classificação ocorre usando quatro variáveis de substituição (troca). Na primeira etapa, as quatro variáveis são parcialmente classificadas em quatro variáveis de troca; na segunda etapa, elas são completamente classificadas de volta nas quatro variáveis originais.
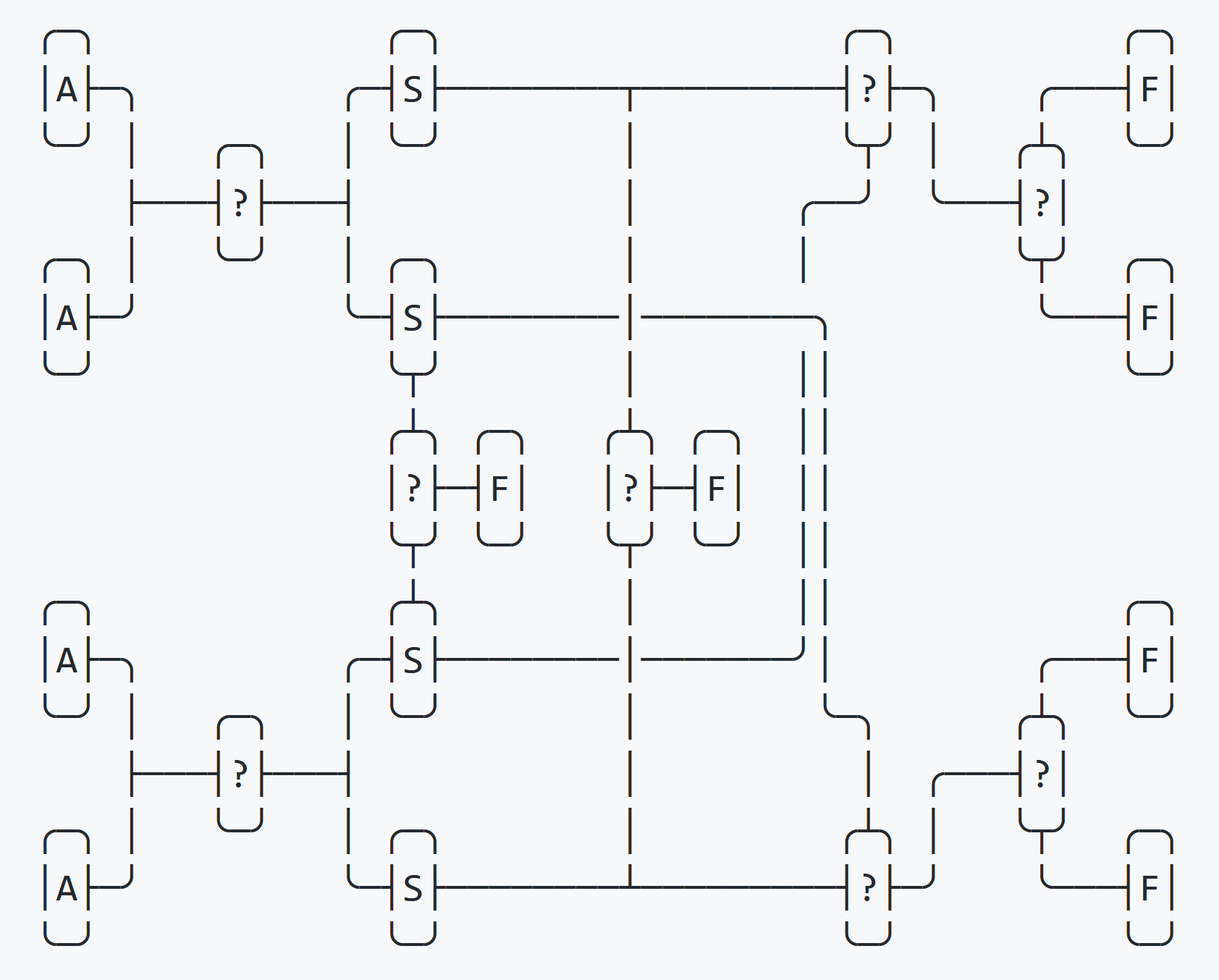
Este processo é mostrado no diagrama acima.
Após a primeira rodada de classificação, um if check determina se as quatro variáveis de troca estão classificadas em ordem. Nesse caso, a troca termina imediatamente. Em seguida, ele verifica se as variáveis de troca estão classificadas na ordem inversa. Nesse caso, a classificação termina imediatamente. Se ambos os testes falharem, então a localização final é conhecida e dois testes permanecem para determinar o pedido final.
Isso elimina uma comparação redundante para sequências que estão em ordem. Ao mesmo tempo, uma comparação adicional é criada para sequências aleatórias. No entanto, no mundo real, raramente comparamos dados verdadeiramente aleatórios. Portanto, quando os dados são ordenados em vez de confusos, essa mudança na probabilidade é benéfica.
Há também uma melhoria geral de desempenho ao eliminar a troca desnecessária. Em C, uma troca quádrupla básica se parece com isto:
if (val[0] > val[1])
{
tmp[0] = val[1];
tmp[1] = val[0];
}
else
{
tmp[0] = val[0];
tmp[1] = val[1];
}
if (val[2] > val[3])
{
tmp[2] = val[3];
tmp[3] = val[2];
}
else
{
tmp[2] = val[2];
tmp[3] = val[3];
}
if (tmp[1] <= tmp[2])
{
val[0] = tmp[0];
val[1] = tmp[1];
val[2] = tmp[2];
val[3] = tmp[3];
}
else if (tmp[0] > tmp[3])
{
val[0] = tmp[2];
val[1] = tmp[3];
val[2] = tmp[0];
val[3] = tmp[1];
}
else
{
if (tmp[0] <= tmp[2])
{
val[0] = tmp[0];
val[1] = tmp[2];
}
else
{
val[0] = tmp[2];
val[1] = tmp[0];
}
if (tmp[1] <= tmp[3])
{
val[2] = tmp[1];
val[3] = tmp[3];
}
else
{
val[2] = tmp[3];
val[3] = tmp[1];
}
}Caso o array não possa ser perfeitamente dividido em quatro partes, a cauda de 1-3 elementos é classificada usando a troca binária tradicional.
A troca quádrupla descrita acima é implementada em quadsort.
Mesclagem quádrupla
No primeiro estágio, a troca quádrupla pré-classifica a matriz em blocos de quatro elementos, conforme descrito acima.
O segundo estágio usa uma abordagem semelhante para detectar ordens ordenadas e invertidas, mas em blocos de 4, 16, 64 ou mais elementos, este estágio é tratado como uma classificação de mesclagem tradicional.
Isso pode ser representado da seguinte forma:
main memory: AAAA BBBB CCCC DDDD
swap memory: ABABABAB CDCDCDCD
main memory: ABCDABCDABCDABCDA primeira linha usa uma troca quádrupla para criar quatro blocos de quatro elementos classificados cada. A segunda linha usa uma fusão quad para combinar em dois blocos de oito itens classificados cada um na memória swap. Na última linha, os blocos são mesclados de volta na memória principal e ficamos com um bloco de 16 elementos classificados. Abaixo está a visualização.

Na verdade, essas operações exigem o dobro da memória de troca. Mais sobre isso mais tarde.
Pular
Outra diferença é que, devido ao aumento do custo das operações de mesclagem, é benéfico verificar se quatro blocos estão em ordem direta ou reversa.
Caso os quatro blocos estejam em ordem, a operação de mesclagem é ignorada, pois não tem sentido. No entanto, isso requer uma verificação if adicional e, para dados classificados aleatoriamente, essa verificação se torna cada vez mais improvável à medida que o tamanho do bloco aumenta. Felizmente, a frequência dessa verificação é quadruplicada a cada ciclo, enquanto o benefício potencial quadruplica a cada ciclo.
Caso os quatro blocos estejam na ordem inversa, uma troca estável no local é realizada.
No caso de apenas dois dos quatro blocos serem ordenados ou estarem na ordem inversa, as comparações na fusão em si são desnecessárias e subsequentemente omitidas. Os dados ainda precisam ser copiados para trocar a memória, mas este é um procedimento menos computacional.
Isso permite que o algoritmo quadsort classifique as sequências em ordem progressiva e regressiva usando
ncomparações em vez de n * log ncomparações.
Verificações de limite
Outro problema com a classificação de mesclagem tradicional é que ela desperdiça recursos em verificações de limite desnecessárias. Se parece com isso:
while (a <= a_max && b <= b_max)
if (a <= b)
[insert a++]
else
[insert b++]Para otimização, nosso algoritmo compara o último elemento da sequência A com o último elemento da sequência B. Se o último elemento da sequência A for menor que o último elemento da sequência B, então sabemos que o teste
b < b_maxsempre será falso, porque a sequência A é a primeira a se fundir completamente.
Da mesma forma, se o último elemento da seqüência A for maior que o último elemento da seqüência B, sabemos que o teste
a < a_maxsempre será falso. Se parece com isso:
if (val[a_max] <= val[b_max])
while (a <= a_max)
{
while (a > b)
[insert b++]
[insert a++]
}
else
while (b <= b_max)
{
while (a <= b)
[insert a++]
[insert b++]
}Cauda de fusão
Quando você classifica uma matriz de 65 elementos, termina com uma matriz classificada de 64 elementos e uma matriz classificada de um elemento no final. Isso não resultará em uma operação de troca (troca) adicional se toda a sequência estiver em ordem. Em qualquer caso, para isso, o programa deve escolher o tamanho ideal do array (64, 256 ou 1024).
Outro problema é que o tamanho da matriz abaixo do ideal leva a operações de troca desnecessárias. Para contornar esses dois problemas, o procedimento de mesclagem quádrupla é cancelado quando o tamanho do bloco atinge 1/8 do tamanho da matriz e o restante da matriz é classificado usando mesclagem final. A principal vantagem da fusão de cauda é que ela permite que o swap quadsort seja reduzido para n / 2 sem afetar significativamente o desempenho.
Big O
| Nome | Melhor | Meio | Pior | Estábulo | Memória |
|---|---|---|---|---|---|
| quadsort | n | n log n | n log n | sim | n |
Quando os dados já estão classificados ou classificados em ordem reversa, quadsort faz n comparações.
Cache
Como o quadsort usa n / 2 swaps, o uso do cache não é tão ideal quanto a classificação local. No entanto, classificar os dados aleatórios no local resulta em trocas abaixo do ideal. Com base em meus benchmarks, quadsort é sempre mais rápido do que a classificação local, desde que o array não transborde o cache L1, que pode chegar a 64 KB em processadores modernos.
Wolfsort
Wolfsort é um algoritmo de classificação híbrido radixsort / quadsort que melhora o desempenho ao trabalhar com dados aleatórios. Esta é basicamente uma prova de conceito que só funciona com inteiros de 32 e 64 bits sem sinal.
Visualização
A visualização abaixo executa quatro testes. O primeiro teste é baseado em uma distribuição aleatória, o segundo em uma distribuição ascendente, o terceiro em uma distribuição descendente e o quarto em uma distribuição ascendente com cauda aleatória.
A metade superior mostra a troca e a metade inferior mostra a memória principal. As cores variam para operações de pular, trocar, mesclar e copiar.
Referência: quadsort, std :: stable_sort, timsort, pdqsort e wolfsort
O seguinte benchmark foi executado na configuração WSL gcc versão 7.4.0 (Ubuntu 7.4.0-1ubuntu1 ~ 18.04.1). O código-fonte é compilado pela equipe
g++ -O3 quadsort.cpp. Cada teste é executado cem vezes e apenas a melhor execução é relatada.
A abscissa é o tempo de execução.
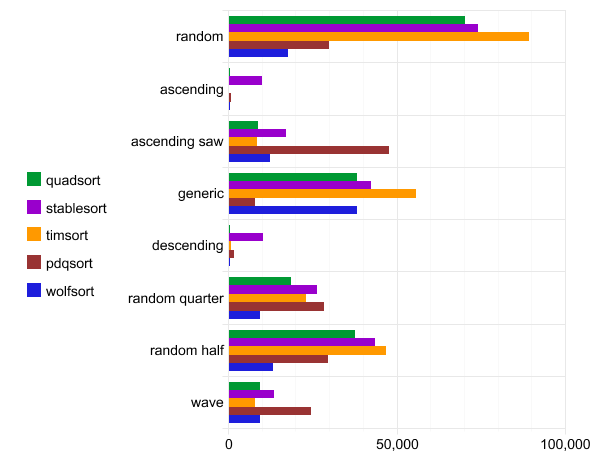
Folha de dados do Quadsort, std :: stable_sort, timsort, pdqsort e wolfsort
| quadsort | 1000000 | i32 | 0.070469 | 0.070635 | ||
| stablesort | 1000000 | i32 | 0.073865 | 0.074078 | ||
| timsort | 1000000 | i32 | 0.089192 | 0.089301 | ||
| pdqsort | 1000000 | i32 | 0.029911 | 0.029948 | ||
| wolfsort | 1000000 | i32 | 0.017359 | 0.017744 | ||
| quadsort | 1000000 | i32 | 0.000485 | 0.000511 | ||
| stablesort | 1000000 | i32 | 0.010188 | 0.010261 | ||
| timsort | 1000000 | i32 | 0.000331 | 0.000342 | ||
| pdqsort | 1000000 | i32 | 0.000863 | 0.000875 | ||
| wolfsort | 1000000 | i32 | 0.000539 | 0.000579 | ||
| quadsort | 1000000 | i32 | 0.008901 | 0.008934 | () | |
| stablesort | 1000000 | i32 | 0.017093 | 0.017275 | () | |
| timsort | 1000000 | i32 | 0.008615 | 0.008674 | () | |
| pdqsort | 1000000 | i32 | 0.047785 | 0.047921 | () | |
| wolfsort | 1000000 | i32 | 0.012490 | 0.012554 | () | |
| quadsort | 1000000 | i32 | 0.038260 | 0.038343 | ||
| stablesort | 1000000 | i32 | 0.042292 | 0.042388 | ||
| timsort | 1000000 | i32 | 0.055855 | 0.055967 | ||
| pdqsort | 1000000 | i32 | 0.008093 | 0.008168 | ||
| wolfsort | 1000000 | i32 | 0.038320 | 0.038417 | ||
| quadsort | 1000000 | i32 | 0.000559 | 0.000576 | ||
| stablesort | 1000000 | i32 | 0.010343 | 0.010438 | ||
| timsort | 1000000 | i32 | 0.000891 | 0.000900 | ||
| pdqsort | 1000000 | i32 | 0.001882 | 0.001897 | ||
| wolfsort | 1000000 | i32 | 0.000604 | 0.000625 | ||
| quadsort | 1000000 | i32 | 0.006174 | 0.006245 | ||
| stablesort | 1000000 | i32 | 0.014679 | 0.014767 | ||
| timsort | 1000000 | i32 | 0.006419 | 0.006468 | ||
| pdqsort | 1000000 | i32 | 0.016603 | 0.016629 | ||
| wolfsort | 1000000 | i32 | 0.006264 | 0.006329 | ||
| quadsort | 1000000 | i32 | 0.018675 | 0.018729 | ||
| stablesort | 1000000 | i32 | 0.026384 | 0.026508 | ||
| timsort | 1000000 | i32 | 0.023226 | 0.023395 | ||
| pdqsort | 1000000 | i32 | 0.028599 | 0.028674 | ||
| wolfsort | 1000000 | i32 | 0.009517 | 0.009631 | ||
| quadsort | 1000000 | i32 | 0.037593 | 0.037679 | ||
| stablesort | 1000000 | i32 | 0.043755 | 0.043899 | ||
| timsort | 1000000 | i32 | 0.047008 | 0.047112 | ||
| pdqsort | 1000000 | i32 | 0.029800 | 0.029847 | ||
| wolfsort | 1000000 | i32 | 0.013238 | 0.013355 | ||
| quadsort | 1000000 | i32 | 0.009605 | 0.009673 | ||
| stablesort | 1000000 | i32 | 0.013667 | 0.013785 | ||
| timsort | 1000000 | i32 | 0.007994 | 0.008138 | ||
| pdqsort | 1000000 | i32 | 0.024683 | 0.024727 | ||
| wolfsort | 1000000 | i32 | 0.009642 | 0.009709 |
Deve-se observar que pdqsort não é uma classificação estável, portanto, funciona mais rápido com dados na ordem normal (ordem geral).
O próximo benchmark foi executado no WSL gcc versão 7.4.0 (Ubuntu 7.4.0-1ubuntu1 ~ 18.04.1). O código-fonte é compilado pela equipe
g++ -O3 quadsort.cpp. Cada teste é executado cem vezes e apenas a melhor execução é relatada. Ele mede o desempenho em matrizes que variam de 675 a 100.000 elementos.
O eixo X do gráfico abaixo é a cardinalidade, o eixo Y é o tempo de execução.

Folha de dados do Quadsort, std :: stable_sort, timsort, pdqsort e wolfsort
| quadsort | 100000 | i32 | 0.005800 | 0.005835 | ||
| stablesort | 100000 | i32 | 0.006092 | 0.006122 | ||
| timsort | 100000 | i32 | 0.007605 | 0.007656 | ||
| pdqsort | 100000 | i32 | 0.002648 | 0.002670 | ||
| wolfsort | 100000 | i32 | 0.001148 | 0.001168 | ||
| quadsort | 10000 | i32 | 0.004568 | 0.004593 | ||
| stablesort | 10000 | i32 | 0.004813 | 0.004923 | ||
| timsort | 10000 | i32 | 0.006326 | 0.006376 | ||
| pdqsort | 10000 | i32 | 0.002345 | 0.002373 | ||
| wolfsort | 10000 | i32 | 0.001256 | 0.001274 | ||
| quadsort | 5000 | i32 | 0.004076 | 0.004086 | ||
| stablesort | 5000 | i32 | 0.004394 | 0.004420 | ||
| timsort | 5000 | i32 | 0.005901 | 0.005938 | ||
| pdqsort | 5000 | i32 | 0.002093 | 0.002107 | ||
| wolfsort | 5000 | i32 | 0.000968 | 0.001086 | ||
| quadsort | 2500 | i32 | 0.003196 | 0.003303 | ||
| stablesort | 2500 | i32 | 0.003801 | 0.003942 | ||
| timsort | 2500 | i32 | 0.005296 | 0.005322 | ||
| pdqsort | 2500 | i32 | 0.001606 | 0.001661 | ||
| wolfsort | 2500 | i32 | 0.000509 | 0.000520 | ||
| quadsort | 1250 | i32 | 0.001767 | 0.001823 | ||
| stablesort | 1250 | i32 | 0.002812 | 0.002887 | ||
| timsort | 1250 | i32 | 0.003789 | 0.003865 | ||
| pdqsort | 1250 | i32 | 0.001036 | 0.001325 | ||
| wolfsort | 1250 | i32 | 0.000534 | 0.000655 | ||
| quadsort | 675 | i32 | 0.000368 | 0.000592 | ||
| stablesort | 675 | i32 | 0.000974 | 0.001160 | ||
| timsort | 675 | i32 | 0.000896 | 0.000948 | ||
| pdqsort | 675 | i32 | 0.000489 | 0.000531 | ||
| wolfsort | 675 | i32 | 0.000283 | 0.000308 |
Referência: quadsort e qsort (mergesort)
O próximo benchmark foi executado no WSL gcc versão 7.4.0 (Ubuntu 7.4.0-1ubuntu1 ~ 18.04.1). O código-fonte é compilado pela equipe
g++ -O3 quadsort.cpp. Cada teste é executado cem vezes e apenas a melhor execução é relatada.
quadsort: sorted 1000000 i32s in 0.119437 seconds. MO: 19308657 ( )
qsort: sorted 1000000 i32s in 0.133077 seconds. MO: 21083741 ( )
quadsort: sorted 1000000 i32s in 0.002071 seconds. MO: 999999 ()
qsort: sorted 1000000 i32s in 0.007265 seconds. MO: 3000004 ()
quadsort: sorted 1000000 i32s in 0.019239 seconds. MO: 4007580 ( )
qsort: sorted 1000000 i32s in 0.071322 seconds. MO: 20665677 ( )
quadsort: sorted 1000000 i32s in 0.076605 seconds. MO: 19242642 ( )
qsort: sorted 1000000 i32s in 0.038389 seconds. MO: 6221917 ( )
quadsort: sorted 1000000 i32s in 0.002305 seconds. MO: 999999 ()
qsort: sorted 1000000 i32s in 0.009659 seconds. MO: 4000015 ()
quadsort: sorted 1000000 i32s in 0.022940 seconds. MO: 9519209 ( )
qsort: sorted 1000000 i32s in 0.042135 seconds. MO: 13152042 ( )
quadsort: sorted 1000000 i32s in 0.034456 seconds. MO: 6787656 ( )
qsort: sorted 1000000 i32s in 0.098691 seconds. MO: 20584424 ( )
quadsort: sorted 1000000 i32s in 0.066240 seconds. MO: 11383441 ( )
qsort: sorted 1000000 i32s in 0.118086 seconds. MO: 20572142 ( )
quadsort: sorted 1000000 i32s in 0.038116 seconds. MO: 15328606 ( )
qsort: sorted 1000000 i32s in 4.471858 seconds. MO: 1974047339 ( )
quadsort: sorted 1000000 i32s in 0.060989 seconds. MO: 15328606 ()
qsort: sorted 1000000 i32s in 0.043175 seconds. MO: 10333679 ()
quadsort: sorted 1023 i32s in 0.016126 seconds. (random 1-1023)
qsort: sorted 1023 i32s in 0.033132 seconds. (random 1-1023)MO indica o número de comparações realizadas em 1 milhão de itens.
O benchmark acima compara quadsort com glibc qsort () através da mesma interface de propósito geral e sem quaisquer vantagens injustas conhecidas como inlining.
random order: 635, 202, 47, 229, etc
ascending order: 1, 2, 3, 4, etc
uniform order: 1, 1, 1, 1, etc
descending order: 999, 998, 997, 996, etc
wave order: 100, 1, 102, 2, 103, 3, etc
stable/unstable: 100, 1, 102, 1, 103, 1, etc
random range: time to sort 1000 arrays ranging from size 0 to 999 containing random dataReferência: quadsort e qsort (quicksort)
Este teste particular é feito usando a implementação qsort () do Cygwin, que usa quicksort por baixo do capô. O código-fonte é compilado pela equipe
gcc -O3 quadsort.c. Cada teste é executado cem vezes, apenas a melhor execução é relatada.
quadsort: sorted 1000000 i32s in 0.119437 seconds. MO: 19308657 ( )
qsort: sorted 1000000 i32s in 0.133077 seconds. MO: 21083741 ( )
quadsort: sorted 1000000 i32s in 0.002071 seconds. MO: 999999 ()
qsort: sorted 1000000 i32s in 0.007265 seconds. MO: 3000004 ()
quadsort: sorted 1000000 i32s in 0.019239 seconds. MO: 4007580 ( )
qsort: sorted 1000000 i32s in 0.071322 seconds. MO: 20665677 ( )
quadsort: sorted 1000000 i32s in 0.076605 seconds. MO: 19242642 ( )
qsort: sorted 1000000 i32s in 0.038389 seconds. MO: 6221917 ( )
quadsort: sorted 1000000 i32s in 0.002305 seconds. MO: 999999 ()
qsort: sorted 1000000 i32s in 0.009659 seconds. MO: 4000015 ()
quadsort: sorted 1000000 i32s in 0.022940 seconds. MO: 9519209 ( )
qsort: sorted 1000000 i32s in 0.042135 seconds. MO: 13152042 ( )
quadsort: sorted 1000000 i32s in 0.034456 seconds. MO: 6787656 ( )
qsort: sorted 1000000 i32s in 0.098691 seconds. MO: 20584424 ( )
quadsort: sorted 1000000 i32s in 0.066240 seconds. MO: 11383441 ( )
qsort: sorted 1000000 i32s in 0.118086 seconds. MO: 20572142 ( )
quadsort: sorted 1000000 i32s in 0.038116 seconds. MO: 15328606 ( )
qsort: sorted 1000000 i32s in 4.471858 seconds. MO: 1974047339 ( )
quadsort: sorted 1000000 i32s in 0.060989 seconds. MO: 15328606 ()
qsort: sorted 1000000 i32s in 0.043175 seconds. MO: 10333679 ()
quadsort: sorted 1023 i32s in 0.016126 seconds. (random 1-1023)
qsort: sorted 1023 i32s in 0.033132 seconds. (random 1-1023)Nesse benchmark, fica claro por que o quicksort geralmente é preferível ao merge tradicional, ele faz menos comparações para dados em ordem crescente, uniformemente distribuído e para dados em ordem decrescente. No entanto, na maioria dos testes, teve um desempenho pior do que o quadsort. Quicksort também exibe uma velocidade de classificação extremamente lenta para dados ordenados por onda. O teste de dados aleatórios mostra que quadsort é duas vezes mais rápido ao classificar pequenos arrays.
Quicksort é mais rápido em testes de uso geral e estáveis, mas apenas porque é um algoritmo instável.
Veja também: