Vamos lembrar o plano pelo qual estamos nos movendo:
1 parte . Decidimos a tarefa técnica e a arquitetura da solução, escrevemos um aplicativo em golang.
Parte 2 (você está aqui agora). Lançamos nosso aplicativo para produção, o tornamos escalonável e testamos a carga.
Parte 3. Vamos tentar descobrir por que precisamos armazenar mensagens em um buffer, e não em arquivos, e também comparar os serviços de fila kafka, rabbitmq e yandex entre si.
Parte 4. Vamos implantar o cluster Clickhouse, escrever streaming para transferir dados do buffer de lá, configurar a visualização em datalens.
Parte 5.Vamos colocar toda a infraestrutura na forma adequada - configurar ci / cd usando gitlab ci, conectar o monitoramento e a descoberta de serviço usando consul e prometheus.

Bem, vamos prosseguir com nossas tarefas.
Colocamos em produção
Na parte 1, montamos o aplicativo, testamos e também carregamos a imagem no registro de contêiner privado, pronto para implantação.
Em geral, as próximas etapas devem ser quase óbvias - criamos máquinas virtuais, configuramos um balanceador de carga e registramos um nome DNS com proxy para cloudflare. Mas temo que essa opção não corresponda exatamente aos nossos termos de referência. Queremos ser capazes de dimensionar nosso serviço no caso de um aumento na carga e eliminar os nós quebrados que não podem atender às solicitações.
Para escalonamento, usaremos os grupos de instâncias disponíveis na nuvem de computação. Eles permitem que você crie máquinas virtuais a partir de um modelo, monitore sua disponibilidade por meio de verificações de integridade e também aumentem automaticamente o número de nós em caso de aumento da carga.Mais detalhes aqui .
Há apenas uma pergunta - qual modelo usar para a máquina virtual? Claro, você pode instalar o linux, configurá-lo, fazer uma imagem e enviá-la para o armazenamento de imagens em Yandex.Cloud. Mas para nós é uma jornada longa e difícil. Ao revisar as várias imagens disponíveis ao criar uma máquina virtual, encontramos uma instância interessante - imagem otimizada para contêiner ( https://cloud.yandex.ru/docs/cos/concepts/ ). Ele permite que você execute um único contêiner do docker no host em modo de rede. Ou seja, ao criar uma máquina virtual, aproximadamente a seguinte especificação é indicada para uma imagem otimizada de contêiner:
spec:
containers:
- name: api
image: vozerov/events-api:v1
command:
- /app/app
args:
- -kafka=kafka.ru-central1.internal:9092
securityContext:
privileged: false
tty: false
stdin: false
restartPolicy: AlwaysE depois de iniciar a máquina virtual, esse contêiner será baixado e iniciado localmente.
O esquema é bastante interessante:
- Criamos um grupo de instâncias com escalonamento automático quando excedemos 60% do uso da CPU.
- Como modelo, especificamos uma máquina virtual com uma imagem otimizada para contêiner e parâmetros para executar nosso contêiner Docker.
- Criamos um balanceador de carga, que examinará nosso grupo de instâncias e será atualizado automaticamente ao adicionar ou remover máquinas virtuais.
- O aplicativo será monitorado como um grupo de instâncias e pelo próprio balanceador, o que desequilibrará as máquinas virtuais inacessíveis.
Soa como um plano!
Vamos tentar criar um grupo de instâncias usando terraform. Toda a descrição encontra-se em instance-group.tf, comentarei os pontos principais:
- O ID da conta de serviço será usado para criar e excluir máquinas virtuais. A propósito, teremos que criá-lo.
service_account_id = yandex_iam_service_account.instances.id - spec.yml, , . registry , - — docker hub. , —
metadata = { docker-container-declaration = file("spec.yml") ssh-keys = "ubuntu:${file("~/.ssh/id_rsa.pub")}" } - service account id, container optimized image, container registry . registry , :
service_account_id = yandex_iam_service_account.docker.id - Scale policy. :
autoscale { initialsize = 3 measurementduration = 60 cpuutilizationtarget = 60 minzonesize = 1 maxsize = 6 warmupduration = 60 stabilizationduration = 180 }
. — fixed_scale , auth_scale.
:
initial size — ;
measurement_duration — ;
cpu_utilization_target — , ;
min_zone_size — — , ;
max_size — ;
warmup_duration — , , ;
stabilization_duration — — , .
. 3 (initial_size), (min_zone_size). cpu (measurement_duration). 60% (cpu_utilization_target), , (max_size). 60 (warmup_duration), cpu. 120 (stabilization_duration), 60% (cpu_utilization_target).
— https://cloud.yandex.ru/docs/compute/concepts/instance-groups/policies#auto-scale-policy - Allocation policy. , , — .
allocationpolicy { zones = ["ru-central1-a", "ru-central1-b", "ru-central1-c"] } - :
deploy_policy { maxunavailable = 1 maxcreating = 1 maxexpansion = 1 maxdeleting = 1 }
max_creating — ;
max_deleting — ;
max_expansion — ;
max_unavailable — RUNNING, ;
— https://cloud.yandex.ru/docs/compute/concepts/instance-groups/policies#deploy-policy - :
load_balancer { target_group_name = "events-api-tg" }
Ao criar um grupo de instâncias, você também pode criar um grupo de destino para o balanceador de carga. Ele terá como alvo as máquinas virtuais associadas. Se excluídos, os nós serão removidos do balanceamento e, após a criação, serão adicionados ao balanceamento após passar nas verificações de estado.
Parece que tudo é básico - vamos criar uma conta de serviço para o grupo de instâncias e, na verdade, o próprio grupo.
vozerov@mba:~/events/terraform (master *) $ terraform apply -target yandex_iam_service_account.instances -target yandex_resourcemanager_folder_iam_binding.editor
... skipped ...
Apply complete! Resources: 2 added, 0 changed, 0 destroyed.
vozerov@mba:~/events/terraform (master *) $ terraform apply -target yandex_compute_instance_group.events_api_ig
... skipped ...
Apply complete! Resources: 1 added, 0 changed, 0 destroyed.O grupo foi criado - você pode visualizar e verificar:
vozerov@mba:~/events/terraform (master *) $ yc compute instance-group list
+----------------------+---------------+------+
| ID | NAME | SIZE |
+----------------------+---------------+------+
| cl1s2tu8siei464pv1pn | events-api-ig | 3 |
+----------------------+---------------+------+
vozerov@mba:~/events/terraform (master *) $ yc compute instance list
+----------------------+---------------------------+---------------+---------+----------------+-------------+
| ID | NAME | ZONE ID | STATUS | EXTERNAL IP | INTERNAL IP |
+----------------------+---------------------------+---------------+---------+----------------+-------------+
| ef3huodj8g4gc6afl0jg | cl1s2tu8siei464pv1pn-ocih | ru-central1-c | RUNNING | 130.193.44.106 | 172.16.3.3 |
| epdli4s24on2ceel46sr | cl1s2tu8siei464pv1pn-ipym | ru-central1-b | RUNNING | 84.201.164.196 | 172.16.2.31 |
| fhmf37k03oobgu9jmd7p | kafka | ru-central1-a | RUNNING | 84.201.173.41 | 172.16.1.31 |
| fhmh4la5dj0m82ihoskd | cl1s2tu8siei464pv1pn-ahuj | ru-central1-a | RUNNING | 130.193.37.94 | 172.16.1.37 |
| fhmr401mknb8omfnlrc0 | monitoring | ru-central1-a | RUNNING | 84.201.159.71 | 172.16.1.14 |
| fhmt9pl1i8sf7ga6flgp | build | ru-central1-a | RUNNING | 84.201.132.3 | 172.16.1.26 |
+----------------------+---------------------------+---------------+---------+----------------+-------------+
vozerov@mba:~/events/terraform (master *) $Três nós com nomes tortos são nosso grupo. Verificamos se os aplicativos estão disponíveis para eles:
vozerov@mba:~/events/terraform (master *) $ curl -D - -s http://130.193.44.106:8080/status
HTTP/1.1 200 OK
Date: Mon, 13 Apr 2020 16:32:04 GMT
Content-Length: 3
Content-Type: text/plain; charset=utf-8
ok
vozerov@mba:~/events/terraform (master *) $ curl -D - -s http://84.201.164.196:8080/status
HTTP/1.1 200 OK
Date: Mon, 13 Apr 2020 16:32:09 GMT
Content-Length: 3
Content-Type: text/plain; charset=utf-8
ok
vozerov@mba:~/events/terraform (master *) $ curl -D - -s http://130.193.37.94:8080/status
HTTP/1.1 200 OK
Date: Mon, 13 Apr 2020 16:32:15 GMT
Content-Length: 3
Content-Type: text/plain; charset=utf-8
ok
vozerov@mba:~/events/terraform (master *) $A propósito, você pode acessar as máquinas virtuais com o login do ubuntu e ver os logs do contêiner e como ele é iniciado.
Um grupo-alvo também foi criado para o balanceador para o qual as solicitações podem ser enviadas:
vozerov@mba:~/events/terraform (master *) $ yc load-balancer target-group list
+----------------------+---------------+---------------------+-------------+--------------+
| ID | NAME | CREATED | REGION ID | TARGET COUNT |
+----------------------+---------------+---------------------+-------------+--------------+
| b7rhh6d4assoqrvqfr9g | events-api-tg | 2020-04-13 16:23:53 | ru-central1 | 3 |
+----------------------+---------------+---------------------+-------------+--------------+
vozerov@mba:~/events/terraform (master *) $Vamos já criar um balanceador e tentar enviar tráfego para ele! Este processo é descrito em load-balancer.tf, pontos-chave:
- Indicamos em qual porta externa o balanceador atenderá e em qual porta enviaremos uma solicitação às máquinas virtuais. Indicamos o tipo de endereço externo - ip v4. No momento, o balanceador de carga opera no nível de transporte, portanto, ele só pode balancear conexões tcp / udp. Portanto, você terá que parafusar SSL em suas máquinas virtuais ou em um serviço externo que pode lidar com https, por exemplo, cloudflare.
listener { name = "events-api-listener" port = 80 target_port = 8080 external_address_spec { ipversion = "ipv4" } } healthcheck { name = "http" http_options { port = 8080 path = "/status" } }
Verificações de saúde. Aqui, especificamos os parâmetros para verificação de nossos nós - verificamos por http url / status na porta 8080. Se a verificação falhar, a máquina perderá o equilíbrio.
Mais informações sobre o balanceador de carga - cloud.yandex.ru/docs/load-balancer/concepts . Curiosamente, você pode conectar o serviço de proteção DDOS no balanceador. Então, o tráfego já limpo chegará aos seus servidores.
Nós criamos:
vozerov@mba:~/events/terraform (master *) $ terraform apply -target yandex_lb_network_load_balancer.events_api_lb
... skipped ...
Apply complete! Resources: 1 added, 0 changed, 0 destroyed.Tiramos o ip do balanceador criado e testamos o trabalho:
vozerov@mba:~/events/terraform (master *) $ yc load-balancer network-load-balancer get events-api-lb
id:
folder_id:
created_at: "2020-04-13T16:34:28Z"
name: events-api-lb
region_id: ru-central1
status: ACTIVE
type: EXTERNAL
listeners:
- name: events-api-listener
address: 130.193.37.103
port: "80"
protocol: TCP
target_port: "8080"
attached_target_groups:
- target_group_id:
health_checks:
- name: http
interval: 2s
timeout: 1s
unhealthy_threshold: "2"
healthy_threshold: "2"
http_options:
port: "8080"
path: /statusAgora podemos deixar mensagens nele:
vozerov@mba:~/events/terraform (master *) $ curl -D - -s -X POST -d '{"key1":"data1"}' http://130.193.37.103/post
HTTP/1.1 200 OK
Content-Type: application/json
Date: Mon, 13 Apr 2020 16:42:57 GMT
Content-Length: 41
{"status":"ok","partition":0,"Offset":1}
vozerov@mba:~/events/terraform (master *) $ curl -D - -s -X POST -d '{"key1":"data1"}' http://130.193.37.103/post
HTTP/1.1 200 OK
Content-Type: application/json
Date: Mon, 13 Apr 2020 16:42:58 GMT
Content-Length: 41
{"status":"ok","partition":0,"Offset":2}
vozerov@mba:~/events/terraform (master *) $ curl -D - -s -X POST -d '{"key1":"data1"}' http://130.193.37.103/post
HTTP/1.1 200 OK
Content-Type: application/json
Date: Mon, 13 Apr 2020 16:43:00 GMT
Content-Length: 41
{"status":"ok","partition":0,"Offset":3}
vozerov@mba:~/events/terraform (master *) $Ótimo, tudo funciona. O toque final permanece para que estejamos disponíveis via https - vamos conectar o cloudflare com proxy. Se decidir fazer sem o cloudflare, você pode pular esta etapa.
vozerov@mba:~/events/terraform (master *) $ terraform apply -target cloudflare_record.events
... skipped ...
Apply complete! Resources: 1 added, 0 changed, 0 destroyed.Teste em HTTPS:
vozerov@mba:~/events/terraform (master *) $ curl -D - -s -X POST -d '{"key1":"data1"}' https://events.kis.im/post
HTTP/2 200
date: Mon, 13 Apr 2020 16:45:01 GMT
content-type: application/json
content-length: 41
set-cookie: __cfduid=d7583eb5f791cd3c1bdd7ce2940c8a7981586796301; expires=Wed, 13-May-20 16:45:01 GMT; path=/; domain=.kis.im; HttpOnly; SameSite=Lax
cf-cache-status: DYNAMIC
expect-ct: max-age=604800, report-uri="https://report-uri.cloudflare.com/cdn-cgi/beacon/expect-ct"
server: cloudflare
cf-ray: 5836a7b1bb037b2b-DME
{"status":"ok","partition":0,"Offset":5}
vozerov@mba:~/events/terraform (master *) $Tudo está finalmente funcionando.
Testando a carga
Resta-nos talvez a etapa mais interessante - realizar o teste de carga do nosso serviço e obter alguns números - por exemplo, o 95º percentil do tempo de processamento de uma solicitação. Também seria bom testar o escalonamento automático de nosso grupo de nós.
Antes de iniciar o teste, vale a pena fazer uma coisa simples - adicionar nossos nós de aplicativo ao prometheus para controlar o número de solicitações e o tempo de processamento de uma solicitação. Como ainda não adicionamos nenhuma descoberta de serviço (faremos isso no artigo 5 desta série), simplesmente escreveremos static_configs em nosso servidor de monitoramento. Você pode descobrir seu ip da maneira padrão por meio da lista de instâncias de computação yc e, em seguida, adicionar as seguintes configurações a /etc/prometheus/prometheus.yml:
- job_name: api
metrics_path: /metrics
static_configs:
- targets:
- 172.16.3.3:8080
- 172.16.2.31:8080
- 172.16.1.37:8080Os endereços IP de nossas máquinas também podem ser obtidos da lista de instâncias do yc compute. Reinicie o prometheus via systemctl restart prometheus e verifique se os nós estão sendo pesquisados com êxito, acessando a interface da web disponível na porta 9090 (84.201.159.71:9090).
Vamos adicionar um painel à grafana da pasta grafana. Vamos ao Grafana na porta 3000 (84.201.159.71:3000) e com um login / senha - admin / Senha. Em seguida, adicione um prometheus local e importe o painel. Na verdade, neste ponto, a preparação está concluída - você pode lançar solicitações em nossa instalação.
Para o teste, usaremos o tanque yandex ( https://yandex.ru/dev/tank/ ) com um plugin para sobrecarga.yandex.neto que nos permitirá visualizar os dados recebidos pelo tanque. Tudo que você precisa para trabalhar está na pasta de carregamento do repositório git original.
Um pouco sobre o que existe:
- token.txt - um arquivo com uma chave API de sobrecarga.yandex.net - você pode obtê-lo registrando-se no serviço.
- load.yml - um arquivo de configuração para o tanque, há um domínio para teste - events.kis.im, tipo de carga rps e o número de solicitações 15.000 por segundo durante 3 minutos.
- data - um arquivo especial para gerar uma configuração no formato ammo.txt. Nele escrevemos o tipo de solicitação, url, grupo para exibir estatísticas e os dados reais que precisam ser enviados.
- makeammo.py - script para gerar o arquivo ammo.txt a partir do arquivo de dados. Mais sobre o script - yandextank.readthedocs.io/en/latest/ammo_generators.html
- ammo.txt - o arquivo de munição resultante que será usado para enviar solicitações.
Para testar, peguei uma máquina virtual fora de Yandex.Cloud (para manter tudo honesto) e criei um registro DNS para ele load.kis.im. Rolei docker lá, já que vamos iniciar o tanque usando a imagem https://hub.docker.com/r/direvius/yandex-tank/ .
Bem, vamos começar. Copie nossa pasta para o servidor, adicione um token e inicie o tanque:
vozerov@mba:~/events (master *) $ rsync -av load/ cloud-user@load.kis.im:load/
... skipped ...
sent 2195 bytes received 136 bytes 1554.00 bytes/sec
total size is 1810 speedup is 0.78
vozerov@mba:~/events (master *) $ ssh load.kis.im -l cloud-user
cloud-user@load:~$ cd load/
cloud-user@load:~/load$ echo "TOKEN" > token.txt
cloud-user@load:~/load$ sudo docker run -v $(pwd):/var/loadtest --net host --rm -it direvius/yandex-tank -c load.yaml ammo.txt
No handlers could be found for logger "netort.resource"
17:25:25 [INFO] New test id 2020-04-13_17-25-25.355490
17:25:25 [INFO] Logging handler <logging.StreamHandler object at 0x7f209a266850> added
17:25:25 [INFO] Logging handler <logging.StreamHandler object at 0x7f209a20aa50> added
17:25:25 [INFO] Created a folder for the test. /var/loadtest/logs/2020-04-13_17-25-25.355490
17:25:25 [INFO] Configuring plugins...
17:25:25 [INFO] Loading plugins...
17:25:25 [INFO] Testing connection to resolved address 104.27.164.45 and port 80
17:25:25 [INFO] Resolved events.kis.im into 104.27.164.45:80
17:25:25 [INFO] Configuring StepperWrapper...
17:25:25 [INFO] Making stpd-file: /var/loadtest/ammo.stpd
17:25:25 [INFO] Default ammo type ('phantom') used, use 'phantom.ammo_type' option to override it
... skipped ...É isso, o processo está em execução. No console, fica mais ou menos assim:

E estamos aguardando a conclusão do processo e observando o tempo de resposta, a quantidade de solicitações e, claro, o escalonamento automático do nosso grupo de máquinas virtuais. Você pode monitorar um grupo de máquinas virtuais através da interface web; nas configurações de um grupo de máquinas virtuais existe uma guia "Monitoramento".
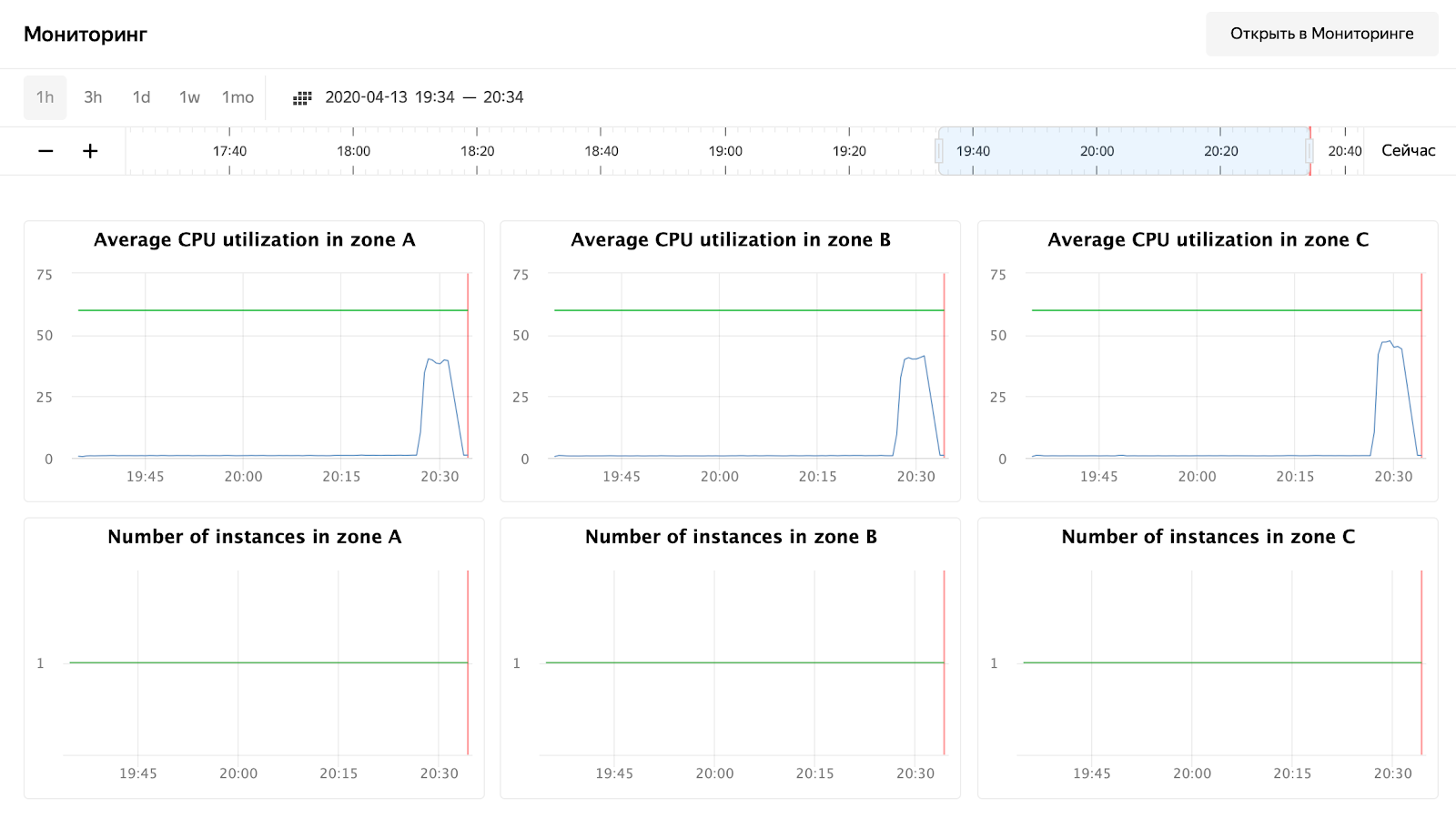
Como você pode ver, nossos nós não carregaram até 50% da CPU, então o teste de escalonamento automático terá que ser repetido. Por enquanto, vamos dar uma olhada no tempo de processamento da solicitação no Grafana:
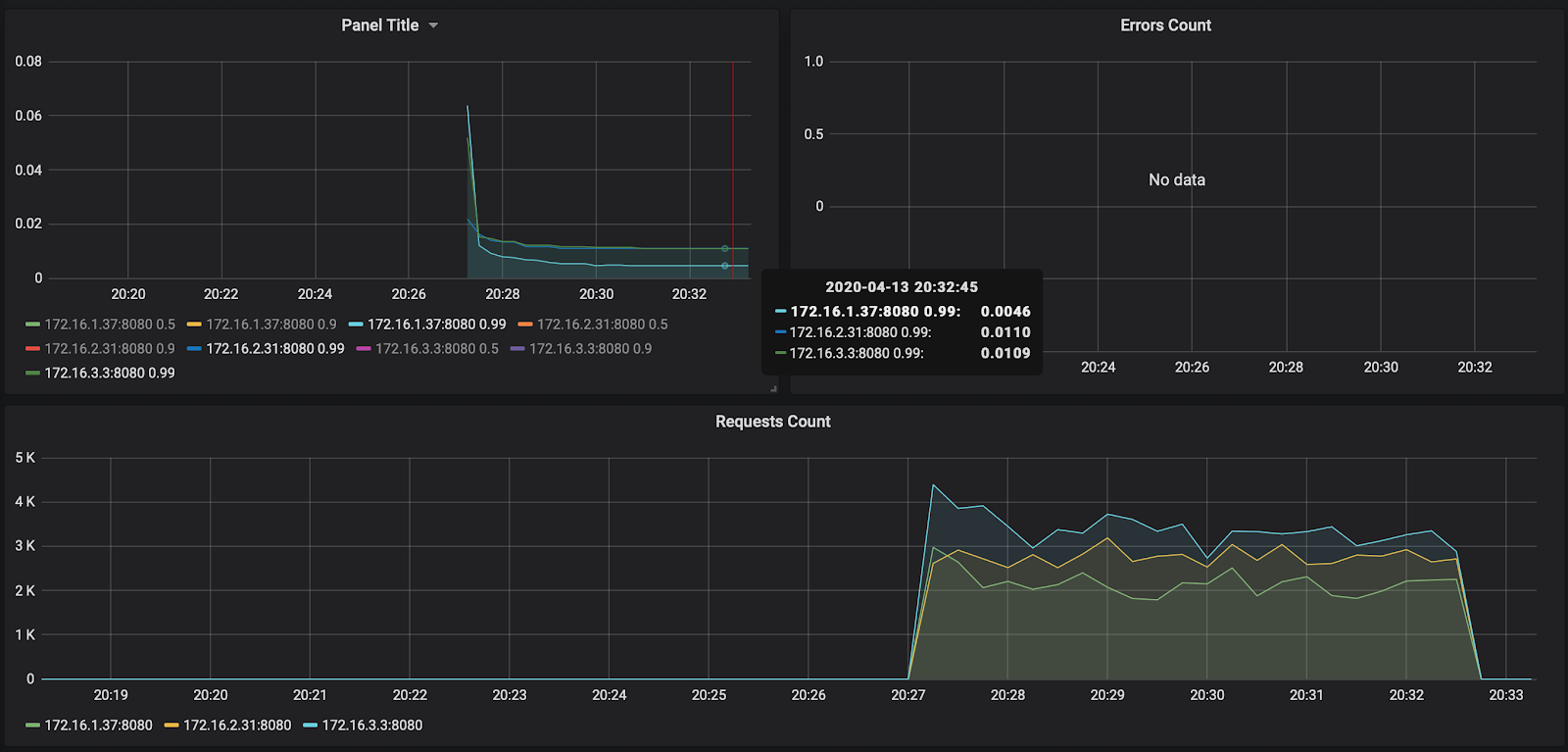
O número de solicitações - cerca de 3.000 por nó - não foi carregado um pouco para 10.000. O tempo de resposta agrada - cerca de 11 ms por solicitação. O único que se destaca - 172.16.1.37 - tem metade do tempo para processar uma solicitação. Mas isso também é lógico - está na mesma zona de disponibilidade ru-central1-a que kafka, que armazena mensagens.
A propósito, o relatório do primeiro lançamento está disponível no link: https://overload.yandex.net/265967 .
Então, vamos executar um teste mais divertido - adicione instâncias: 2.000 para obter 15.000 solicitações por segundo e aumentar o tempo de teste para 10 minutos. O arquivo resultante terá a seguinte aparência:
overload:
enabled: true
package: yandextank.plugins.DataUploader
token_file: "token.txt"
phantom:
address: 130.193.37.103
load_profile:
load_type: rps
schedule: const(15000, 10m)
instances: 2000
console:
enabled: true
telegraf:
enabled: falseO leitor atento notará que mudei o endereço para o IP do balanceador - isso se deve ao fato de que o cloudflare começou a me bloquear para uma grande quantidade de requisições de um ip. Tive que definir o tanque diretamente no balanceador Yandex.Cloud. Após o lançamento, você pode observar a seguinte imagem: O
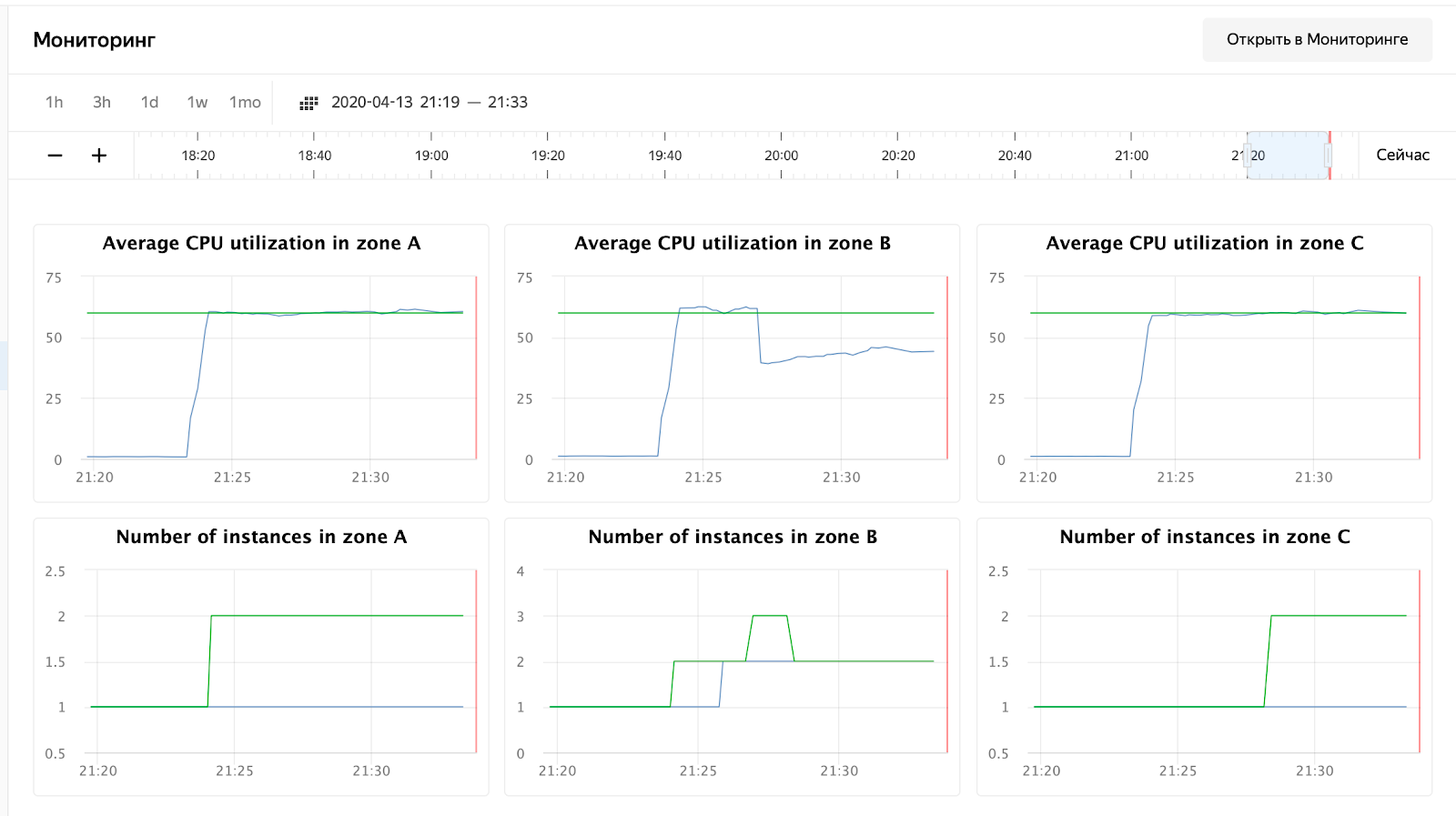
uso da CPU aumentou e o planejador decidiu aumentar o número de nós na zona B, o que ele fez. Isso pode ser visto nos registros do grupo de instâncias:
vozerov@mba:~/events/load (master *) $ yc compute instance-group list-logs events-api-ig
2020-04-13 18:26:47 cl1s2tu8siei464pv1pn-ejok.ru-central1.internal 1m AWAITING_WARMUP_DURATION -> RUNNING_ACTUAL
2020-04-13 18:25:47 cl1s2tu8siei464pv1pn-ejok.ru-central1.internal 37s OPENING_TRAFFIC -> AWAITING_WARMUP_DURATION
2020-04-13 18:25:09 cl1s2tu8siei464pv1pn-ejok.ru-central1.internal 43s CREATING_INSTANCE -> OPENING_TRAFFIC
2020-04-13 18:24:26 cl1s2tu8siei464pv1pn-ejok.ru-central1.internal 6s DELETED -> CREATING_INSTANCE
2020-04-13 18:24:19 cl1s2tu8siei464pv1pn-ozix.ru-central1.internal 0s PREPARING_RESOURCES -> DELETED
2020-04-13 18:24:19 cl1s2tu8siei464pv1pn-ejok.ru-central1.internal 0s PREPARING_RESOURCES -> DELETED
2020-04-13 18:24:15 Target allocation changed in accordance with auto scale policy in zone ru-central1-a: 1 -> 2
2020-04-13 18:24:15 Target allocation changed in accordance with auto scale policy in zone ru-central1-b: 1 -> 2
... skipped ...
2020-04-13 16:23:57 Balancer target group b7rhh6d4assoqrvqfr9g created
2020-04-13 16:23:43 Going to create balancer target group
O escalonador também decidiu aumentar o número de servidores em outras zonas, mas fiquei sem limite de endereços ip externos :) Aliás, eles podem ser aumentados através de uma solicitação ao suporte técnico, especificando cotas e valores desejados.
Conclusão
O artigo não foi fácil - tanto em volume quanto em quantidade de informações. Mas passamos pela fase mais difícil e fizemos o seguinte:
- Monitoramento elevado e kafka.
- , .
- load balancer’ cloudflare ssl .
Da próxima vez, vamos comparar e testar o serviço de fila rabbitmq / kafka / yandex.
Fique ligado!
* Este material está na gravação de vídeo do workshop aberto REBRAIN & Yandex.Cloud: Aceitamos 10.000 solicitações por segundo no Yandex Cloud - https://youtu.be/cZLezUm0ekE
Se você estiver interessado em participar de tais eventos online e fazer perguntas em tempo real, conecte-se a canal DevOps por REBRAIN .
Gostaríamos de agradecer especialmente a Yandex.Cloud pela oportunidade de realizar tal evento. Link para eles
Se você precisar mudar para a nuvem ou tiver dúvidas sobre sua infraestrutura, fique à vontade para deixar uma solicitação .
PS Temos 2 auditorias gratuitas por mês, talvez o seu projeto esteja entre elas.