Abordagem de motivação
A abordagem geralmente aceita para tarefas de visão computacional é usar imagens como uma matriz 3D (altura, largura, número de canais) e aplicar convoluções a elas. Essa abordagem tem várias desvantagens:
- nem todos os pixels são criados iguais. Por exemplo, se temos uma tarefa de classificação, o objeto em si é mais importante para nós do que o fundo. É interessante que os autores não digam que a Atenção já está sendo usada em tarefas de visão computacional;
- As convoluções não funcionam bem o suficiente com pixels distantes. Existem abordagens com convoluções dilatadas e agrupamento médio global, mas elas não resolvem o problema em si;
- As convoluções não são eficientes o suficiente em redes neurais muito profundas.
Como resultado, os autores propõem o seguinte: converter as imagens em algum tipo de tokens visuais e submetê-las ao transformador.

- Primeiro, um backbone regular é usado para obter mapas de recursos
- Em seguida, o mapa de recursos é convertido em tokens visuais
- Tokens são alimentados para transformadores
- A saída do transformador pode ser usada para problemas de classificação
- E se você combinar a saída do transformador com um mapa de recursos, você pode obter previsões para tarefas de segmentação
Dentre os trabalhos em direções semelhantes, os autores ainda mencionam Atenção, mas notam que geralmente Atenção é aplicada aos pixels, portanto, aumenta muito a complexidade computacional. Eles também falam sobre trabalhos para melhorar a eficiência das redes neurais, mas acreditam que nos últimos anos têm proporcionado cada vez menos melhorias, portanto, outras abordagens devem ser buscadas.
Transformador visual
Agora vamos dar uma olhada mais de perto em como o modelo funciona.
Conforme mencionado acima, o backbone busca mapas de recursos e eles são passados para as camadas do transformador visual.
Cada transformador visual consiste em três partes: um tokenizer, um transformador e um projetor.
Tokenizer

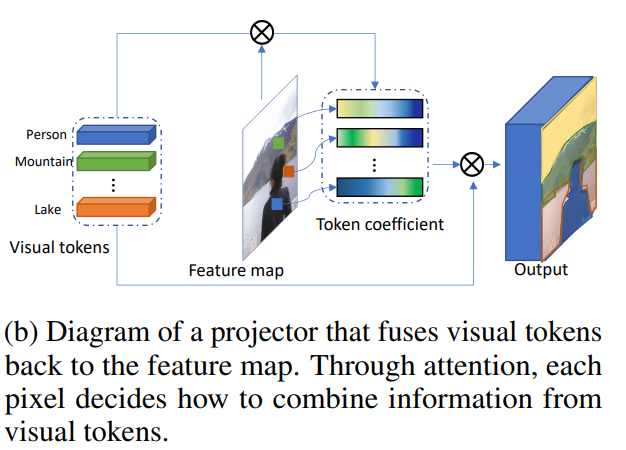
O tokenizer recupera tokens visuais. Na verdade, pegamos um mapa de características, fazemos uma reformulação em (H * W, C) e a partir disso obtemos os tokens. A

visualização dos coeficientes para os tokens se parece com isto:

Codificação de posição
Como de costume, os transformadores precisam não apenas de tokens, mas também de informações sobre sua posição.

Primeiro, fazemos uma redução da amostra, depois multiplicamos pelos pesos de treinamento e concatenamos com tokens. Para ajustar o número de canais, você pode adicionar convolução 1D.
Transformador
Finalmente, o próprio transformador.

Combinando tokens visuais e mapa de recursos
Isso torna o projetor.

Tokenização dinâmica
Após a primeira camada de transformadores, podemos não apenas extrair novos tokens visuais, mas também usar aqueles extraídos das etapas anteriores. Pesos treinados são usados para combiná-los:

Usando transformadores visuais para construir modelos de visão computacional
Além disso, os autores descrevem como o modelo é aplicado a problemas de visão computacional. Os blocos do transformador têm três hiperparâmetros: o número de canais no mapa de recursos C, o número de canais no token visual Ct e o número de tokens visuais L.
Se o número de canais se revelar inadequado durante a transição entre os blocos do modelo, então as convoluções 1D e 2D são usadas para obter o número necessário de canais.
Para acelerar os cálculos e reduzir o tamanho do modelo, use as convoluções de grupo.
Os autores anexam blocos de ** pseudocódigo ** no artigo. O código completo está prometido para ser postado no futuro.
Classificação de imagem
Pegamos o ResNet e criamos ResNets de transformador visual (VT-ResNet) com base nele.
Saímos do estágio 1-4, mas em vez do último colocamos transformadores visuais.
Saída de backbone - mapa de recursos 14 x 14, número de canais 512 ou 1024 dependendo da profundidade do VT-ResNet. 8 tokens visuais para 1024 canais são criados a partir do mapa de recursos. A saída do transformador vai para o cabeçote para classificação.

Segmentação semântica
Para esta tarefa, as redes em pirâmide de características panóticas (FPN) são tomadas como modelo básico.
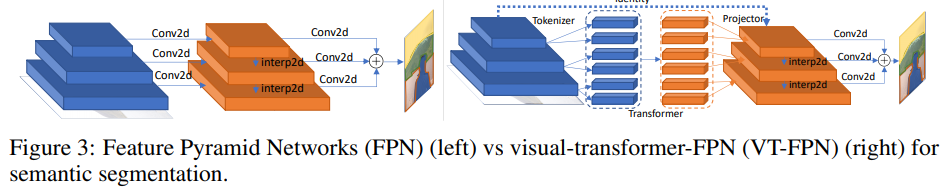
No FPN, as convoluções funcionam em imagens de alta resolução, então o modelo é pesado. Os autores substituem essas operações por transformador visual. Novamente, 8 tokens e 1024 canais.
Experimentos
Classificação ImageNet
Treine 400 épocas com RMSProp. Eles começam com uma taxa de aprendizado de 0,01, aumentam para 0,16 durante 5 épocas de aquecimento e, em seguida, multiplicam cada época por 0,9875. São usados a normalização de lote e o tamanho de lote 2048. Suavização de rótulo, AutoAugment, probabilidade de sobrevivência de profundidade estocástica 0,9, abandono 0,2, EMA 0,99985.
Este é o número de experimentos que eu tive que fazer para encontrar tudo isso ...
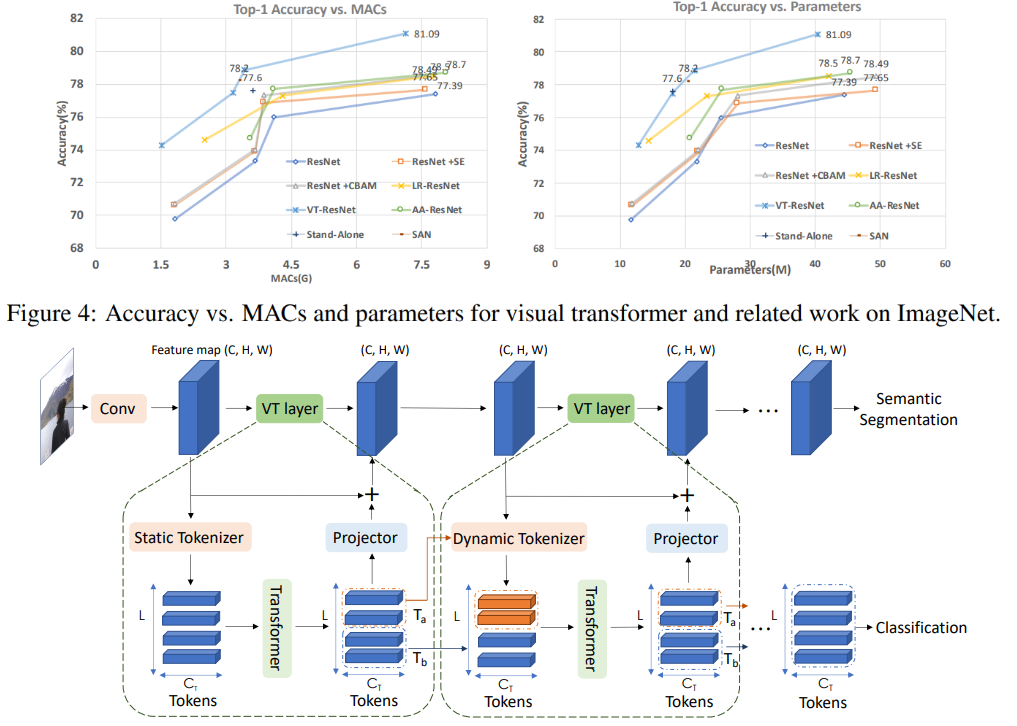
Neste gráfico você pode ver que a abordagem dá uma qualidade maior com um número reduzido de cálculos e tamanho do modelo.
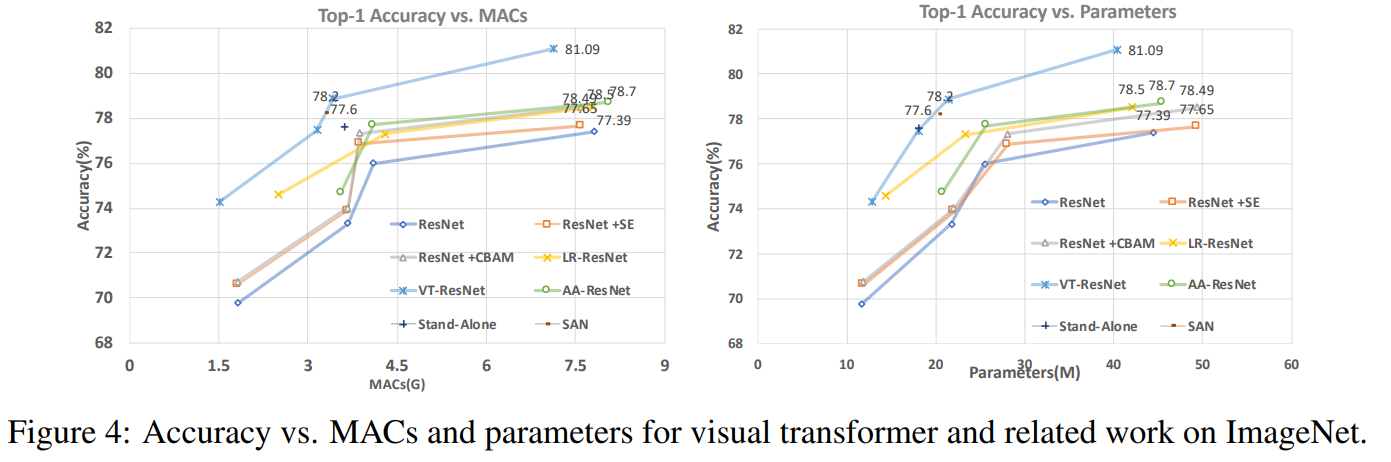
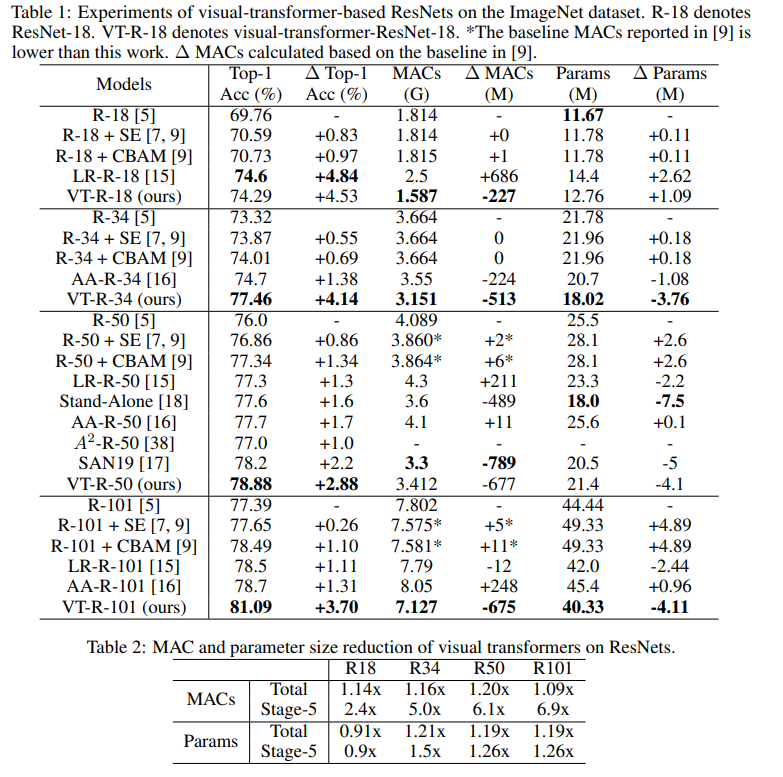
Títulos de artigos para modelos comparados:
ResNet + CBAM - Módulo de atenção de bloqueio convolucional
ResNet + SE - Redes
de compressão e excitação LR-ResNet - Redes de relação local para reconhecimento de imagem
Autônomo - Autocuidado autônomo em modelos de visão
AA-ResNet - Redes convolucionais aumentadas de atenção
SAN - Explorando autocuidado para reconhecimento de imagem
Estudo de ablação
Para acelerar os experimentos, pegamos VT-ResNet- {18, 34} e treinamos 90 épocas.
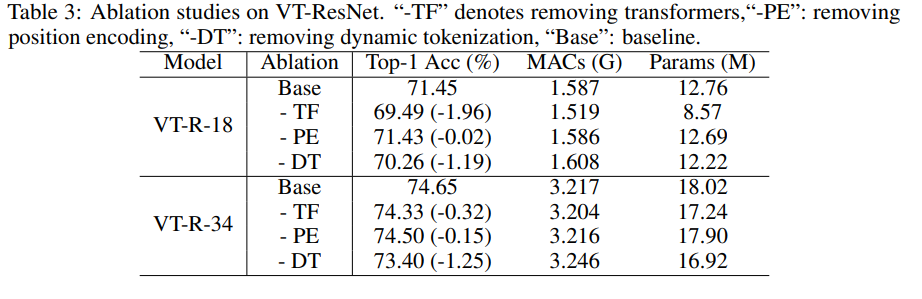
Usar transformadores em vez de convoluções dá o maior ganho. A tokenização dinâmica em vez da tokenização estática também oferece um grande impulso. A codificação de posição oferece apenas uma ligeira melhoria.
Resultados de segmentação

Como você pode ver, a métrica cresceu apenas ligeiramente, mas o modelo consome 6,5 vezes menos MAC.
Futuro potencial da abordagem
Experimentos têm mostrado que a abordagem proposta permite criar modelos mais eficientes (em termos de custos computacionais), que ao mesmo tempo alcançam melhor qualidade. A arquitetura proposta funciona com sucesso para várias tarefas de visão computacional, e espera-se que sua aplicação ajude a melhorar os sistemas que usam visão de comutador - AR / VR, carros autônomos e outros.
A revisão foi preparada por Andrey Lukyanenko, o desenvolvedor líder do MTS.