
Este artigo descreverá a experiência de criar uma rede neural para reconhecimento de rosto, para classificar todas as fotos de uma conversa VK para encontrar uma pessoa específica. Sem qualquer experiência em escrever redes neurais e conhecimento mínimo de Python.
Introdução
Temos um amigo, que se chama Sergei, que adora se fotografar de uma forma incomum e colocá-lo em uma conversa, além de temperar essas fotos com frases corporativas. Então, em uma das noites da discórdia, tivemos uma ideia - criar um público em VK, onde pudéssemos postar Sergey com suas citações. As primeiras 10 postagens no adiamento foram fáceis, mas depois ficou claro que não fazia sentido revisar todos os anexos em uma conversa com as mãos. Então, decidiu-se escrever uma rede neural para automatizar esse processo.
Plano
- Obtenha links para fotos de uma conversa
- Baixar fotos
- Escrevendo uma rede neural
Antes de iniciar o desenvolvimento
, Python pip. , 0, ,
1. Obtendo links para fotos
Portanto, queremos obter todas as fotos da conversa, o método messages.getHistoryAttachments é adequado para nós , que retorna os materiais do diálogo ou conversa.
Desde 15 de fevereiro de 2019, Vkontakte negou o acesso a mensagens para aplicativos que não passaram pela moderação. Das opções de solução alternativa, posso sugerir vkhost , que ajudará você a obter um token de mensageiros de terceiros
Com o token recebido no vkhost, podemos coletar a solicitação de API de que precisamos usando o Postman . Claro, você pode preencher tudo com canetas sem ele, mas para maior clareza, vamos usá-lo.
Preencha os parâmetros:
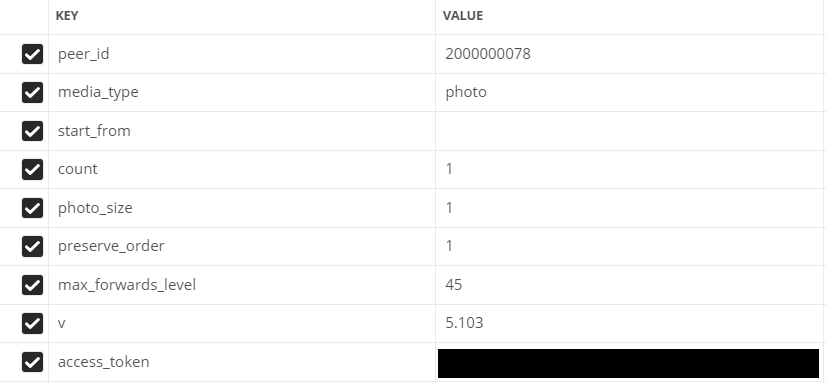
- peer_id - identificador de destino
Para uma conversa: 2.000.000.000 + id de conversa (pode ser visto na barra de endereço).
Para usuário: id do usuário. - media_type - tipo de mídia
No nosso caso, foto
- start_from - deslocamento para selecionar vários itens.
Vamos deixar vazio por enquanto.
- contagem - o número de objetos recebidos
No máximo 200, é quanto vamos usar
- photo_sizes - sinaliza para retornar todos os tamanhos na matriz
1 ou 0. Usamos 1
- preserve_order - sinalizador que indica se os anexos devem ser devolvidos em sua ordem original
1 ou 0. Usamos 1
- v - versão vk api
1 ou 0. Usamos 1
Campos preenchidos no Postman
Vá para escrever o código
Por conveniência, todo o código será dividido em vários scripts separados.
Usará o módulo json (para decodificar os dados) e a biblioteca de solicitações (para fazer solicitações de http)
Lista de códigos se houver menos de 200 fotos em uma conversa / diálogo
import json
import requests
val = 1 #
Fin = open("input.txt","a") #
# GET API response
response = requests.get("https://api.vk.com/method/messages.getHistoryAttachments?peer_id=2000000078&media_type=photo&start_from=&count=10&photo_size=1&preserve_order=1&max_forwards_level=45&v=5.103&access_token=_")
items = json.loads(response.text) # JSON
# GET ,
for item in items['response']['items']: # items
link = item['attachment']['photo']['sizes'][-1]['url'] # ,
print(val,':',link) #
Fin.write(str(link)+"\n") #
val += 1 #
Se houver mais de 200 fotos
import json
import requests
next = None #
def newfunc():
val = 1 #
global next
Fin = open("input.txt","a") #
# GET API response
response = requests.get(f"https://api.vk.com/method/messages.getHistoryAttachments?peer_id=2000000078&media_type=photo&start_from={next}&count=200&photo_size=1&preserve_order=1&max_forwards_level=44&v=5.103&access_token=_")
items = json.loads(response.text) # JSON
if items['response']['items'] != []: #
for item in items['response']['items']: # items
link = item['attachment']['photo']['sizes'][-1]['url'] # ,
print(val,':',link) #
val += 1 #
Fin.write(str(link)+"\n") #
next = items['response']['next_from'] #
print('dd',items['response']['next_from'])
newfunc() #
else: #
print(" ")
newfunc()É hora de baixar links
2. Baixando imagens
Para baixar as fotos usamos a biblioteca urllib
import urllib.request
f = open('input.txt') #
val = 1 #
for line in f: #
line = line.rstrip('\n')
# "img"
urllib.request.urlretrieve(line, f"img/{val}.jpg")
print(val,':','') #
val += 1 #
print("")
O processo de carregamento de todas as imagens não é dos mais rápidos, principalmente se as fotos forem 8330. Espaço para este caso também é necessário, se o número de fotos for igual ao meu ou mais, recomendo liberar 1,5 - 2 GB para isso . O

trabalho bruto está concluído, agora você pode começar interessante - escrever uma rede neural
3. Escrevendo uma rede neural
Depois de examinar muitas bibliotecas e opções diferentes, decidiu-se usar a biblioteca
Face Recognition
O que é que isso pode fazer?
A partir da documentação, considere os recursos mais básicos de
rostos de busca em fotos
podem encontrar qualquer número de pessoas na foto, até mesmo lida com

identificação difusa em fotos individuais
pode reconhecer quem pertence à pessoa na imagem

para nós o método mais adequado será a identificação de pessoas
Treinamento
Dos requisitos para a biblioteca é necessário o Python 3.3+ ou Python 2.7.No caso das bibliotecas, o reconhecimento facial e o PIL mencionados acima serão usados para trabalhar com imagens.
A biblioteca Face Recognition não é oficialmente suportada no Windows , mas funcionou para mim. Tudo funciona de forma estável com macOS e Linux.
Explicação do que está acontecendo
Para começar, precisamos definir um classificador para procurar uma pessoa por quem já ocorrerá uma verificação posterior das fotos.
Recomendo escolher a foto mais nítida possível de uma pessoa em vista frontal.Ao enviar uma foto, a biblioteca divide as imagens nas coordenadas das características faciais de uma pessoa (nariz, olhos, boca e queixo).

Bem, então a questão é pequena, resta apenas aplicar um método semelhante à foto que queremos comparar com nosso classificador. Em seguida, deixamos a rede neural comparar as características faciais por coordenadas.
Bem, o próprio código em si:
import face_recognition
from PIL import Image #
find_face = face_recognition.load_image_file("face/sergey.jpg") #
face_encoding = face_recognition.face_encodings(find_face)[0] # ,
i = 0 #
done = 0 #
numFiles = 8330 # -
while i != numFiles:
i += 1 #
unknown_picture = face_recognition.load_image_file(f"img/{i}.jpg") #
unknown_face_encoding = face_recognition.face_encodings(unknown_picture) #
pil_image = Image.fromarray(unknown_picture) #
#
if len(unknown_face_encoding) > 0: #
encoding = unknown_face_encoding[0] # 0 ,
results = face_recognition.compare_faces([face_encoding], encoding) #
if results[0] == True: #
done += 1 #
print(i,"-"," !")
pil_image.save(f"done/{int(done)}.jpg") #
else: #
print(i,"-"," !")
else: #
print(i,"-"," !")
Também é possível executar tudo de acordo com uma análise aprofundada em uma placa de vídeo, para isso você precisa adicionar o parâmetro model = "cnn" e alterar o fragmento de código da imagem com a qual queremos procurar a pessoa certa:
unknown_picture = face_recognition.load_image_file(f"img/{i}.jpg") #
face_locations = face_recognition.face_locations(unknown_picture, model= "cnn") # GPU
unknown_face_encoding = face_recognition.face_encodings(unknown_picture) # Resultado
Sem GPU. Ao mesmo tempo, a rede neural passou e classificou 8.330 fotos em 1 hora e 40 minutos e ao mesmo tempo encontrou 142 fotos, 62 delas com a imagem da pessoa desejada. Claro, houve falsos positivos em memes e outras pessoas.
C GPU. O tempo de processamento demorou muito mais, 17 horas e 22 minutos, e encontrei 230 fotos das quais 99 são as pessoas de que precisamos.
Em conclusão, podemos dizer que o trabalho não foi feito em vão. Automatizamos o processo de classificação de 8330 fotos, o que é muito melhor do que classificá-las você mesmo.
Você também pode baixar o código-fonte completo do github