Olá! É difícil encontrar um programador de microcontrolador que nunca tenha encontrado uma falha grave. Muitas vezes, ele não é processado de forma alguma, mas simplesmente permanece suspenso em um loop infinito do manipulador fornecido no arquivo de inicialização do fabricante. Ao mesmo tempo, o programador tenta encontrar intuitivamente o motivo da falha. Na minha opinião, esta não é a melhor forma de resolver o problema.
Neste artigo, quero descrever uma metodologia para analisar falhas graves de microcontroladores populares com um núcleo Cortex M3 / M4. Embora, talvez, "técnica" seja uma palavra muito alta. Em vez disso, vou apenas dar um exemplo de como analiso a ocorrência de falhas graves e mostrar o que pode ser feito em uma situação semelhante. Usarei o software IAR e a placa de depuração STM32F4DISCOVERY, já que muitos programadores aspirantes têm essas ferramentas. No entanto, isso é totalmente irrelevante, este exemplo pode ser adaptado para qualquer processador da família e qualquer ambiente de desenvolvimento.

Fall into HardFault
Antes de tentar analisar o HatdFault, você precisa investigá-lo. Existem diversas formas de fazer isto. Imediatamente me ocorreu tentar mudar o processador do estado Thumb para o estado ARM, definindo o endereço da instrução de salto incondicional para um número par.
Uma pequena digressão. Como você sabe, os microcontroladores da família Cortex M3 / M4 usam o conjunto de instruções de montagem Thumb-2 e sempre funcionam no modo Thumb. O modo ARM não é compatível. Se você tentar definir o valor do endereço de salto incondicional (BX reg) com o bit menos significativo apagado, a exceção UsageFault ocorrerá, pois o processador tentará mudar seu estado para ARM. Você pode ler mais sobre isso em [1] (cláusulas 2.8 THE INSTRUCTION SET; 4.3.4 Linguagem Assembler: Chamada e Ramificação Incondicional).
Para começar, proponho simular um salto incondicional para um endereço par em C / C ++. Para fazer isso, vou criar uma função func_hard_fault, então vou tentar chamá-la por ponteiro, após diminuir o endereço do ponteiro em um. Isso pode ser feito da seguinte forma:
void func_hard_fault(void);
void main(void)
{
void (*ptr_hard_fault_func) (void); //
ptr_hard_fault_func = reinterpret_cast<void(*)()>(reinterpret_cast<uint8_t *>(func_hard_fault) - 1); //
ptr_hard_fault_func(); //
while(1) continue;
}
void func_hard_fault(void) //,
{
while(1) continue;
}
Vamos ver com o depurador o que fiz.

Em vermelho, destaquei a instrução de salto atual no endereço em RON R1, que contém um endereço de salto par. Como resultado:

esta operação pode ser realizada de forma ainda mais simples usando inserções de assembler:
void main(void)
{
//
asm("LDR R1, =0x0800029A"); //- f
asm("BX r1"); // R1
while(1) continue;
}
Hooray, entramos no HardFault, missão concluída!
Análise HardFault
Onde chegamos ao HardFault?
Na minha opinião, o mais importante é saber de onde viemos o HardFault. Isso não é difícil de fazer. Primeiro, vamos escrever nosso próprio manipulador para a situação HardFault.
extern "C"
{
void HardFault_Handler(void)
{
}
}Agora vamos falar sobre como descobrir como chegamos aqui. O núcleo do processador Cortex M3 / M4 tem algo maravilhoso como a preservação do contexto [1] (cláusula 9.1.1 Empilhamento). Em termos simples, quando ocorre alguma exceção, o conteúdo dos registros R0-R3, R12, LR, PC, PSR são armazenados na pilha.

Aqui, o registro mais importante para nós será o registro do PC, que contém informações sobre a instrução em execução no momento. Como o valor do registrador foi colocado na pilha no momento da exceção, ele conterá o endereço da última instrução executada. O resto dos registros são menos importantes para análise, mas algo útil pode ser retirado deles. LR é o endereço de retorno da última transição, R0-R3, R12 são valores que podem dizer em qual direção se mover, PSR é apenas um registro geral do status do programa.
Proponho descobrir os valores dos registros no manipulador. Para fazer isso, escrevi o seguinte código (vi um código semelhante em um dos arquivos do fabricante):
extern "C"
{
void HardFault_Handler(void)
{
struct
{
uint32_t r0;
uint32_t r1;
uint32_t r2;
uint32_t r3;
uint32_t r12;
uint32_t lr;
uint32_t pc;
uint32_t psr;
}*stack_ptr; // (SP)
asm(
"TST lr, #4 \n" // 3 ( )
"ITE EQ \n" // 3?
"MRSEQ %[ptr], MSP \n" //,
"MRSNE %[ptr], PSP \n" //,
: [ptr] "=r" (stack_ptr)
);
while(1) continue;
}
}
Como resultado, temos os valores de todos os registros salvos:
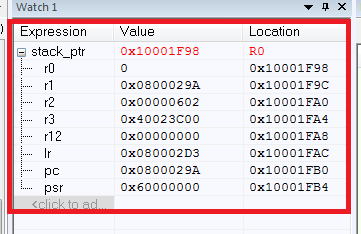
O que aconteceu aqui? Primeiro, temos o ponteiro da pilha stack_ptr, tudo está claro aqui. Surgem dificuldades com a inserção do montador (se houver necessidade de entender as instruções de montagem do Cortex então recomendo [2]).
Por que simplesmente não salvamos a pilha via MRS stack_ptr, MSP? O fato é que os núcleos Cortex M3 / M4 possuem dois ponteiros de pilha [1] (item 3.1.3 Ponteiro de pilha R13) - o ponteiro de pilha MSP principal e o ponteiro de pilha de processo PSP. Eles são usados para diferentes modos de processador. Não vou aprofundar no que isso é feito e como funciona, mas darei uma pequena explicação.
Para descobrir o modo de operação do processador (usado neste MSP ou PSP), você precisa verificar o terceiro bit do registro de comunicação. Este bit determina qual ponteiro de pilha é usado para retornar de uma exceção. Se este bit estiver definido, então é MSP, se não, então PSP. Em geral, a maioria dos aplicativos escritos em C / C ++ usa apenas MSPs e essa verificação pode ser omitida.
Então, qual é o resultado final? Tendo uma lista de registros salvos, podemos facilmente determinar de onde o programa caiu no HardFault do registro do PC. O PC aponta para o endereço 0x0800029A, que é o endereço de nossa instrução de "interrupção". Além disso, não se esqueça da importância dos valores dos outros registros.
Causa de HardFault
Na verdade, também podemos descobrir a causa do HardFault. Dois registros nos ajudarão nisso. Registro de status de falha de hardware (HFSR) e registro de status de falha configurável (CFSR; UFSR + BFSR + MMFSR). O registro CFSR consiste em três registros: Registro de status de falha de uso (UFSR), Registro de status de falha de barramento (BFSR), Registro de endereço de falha de gerenciamento de memória (MMFSR). Você pode ler sobre eles, por exemplo, em [1] e [3].
Proponho ver o que esses registros produzem no meu caso:

primeiro, o bit HFSR FORCED é definido. Isso significa que ocorreu uma falha que não pode ser processada. Para obter mais diagnósticos, examine o restante dos registros de status de falha.
Em segundo lugar, o bit CFSR INVSTATE é definido. Isso significa que ocorreu um UsageFault porque o processador tentou executar uma instrução que usa EPSR ilegalmente.
O que é EPSR? EPSR - Registro de status do programa de execução. Este é um registro PSR interno - um registro de status de programa especial (que, como lembramos, é armazenado na pilha). O vigésimo quarto bit deste registro indica o estado atual do processador (Thumb ou ARM). Isso pode determinar o motivo da falha. Vamos tentar contá-lo:
volatile uint32_t EPSR = 0xFFFFFFFF;
asm(
"MRS %[epsr], PSP \n"
: [epsr] "=r" (EPSR)
);
Como resultado da execução, obtemos o valor EPSR = 0.

Acontece que o registro mostra o status do ARM e encontramos a causa da falha? Na verdade não. De fato, de acordo com [3] (p. 23), a leitura desse registro usando um comando especial MSR sempre retorna zero. Não está muito claro para mim porque funciona assim, porque este registro já é somente leitura, mas aqui ele não pode ser lido completamente (apenas alguns bits podem ser usados via xPSR). Talvez essas sejam algumas limitações arquitetônicas.
Como resultado, infelizmente, todas essas informações não fornecem praticamente nada para um programador MK comum. É por isso que considero todos esses registros apenas como um acréscimo à análise do contexto armazenado.
No entanto, por exemplo, se a falha foi causada pela divisão por zero (esta falha é permitida definindo o bit DIV_0_TRP do registro CCR), então o bit DIVBYZERO será definido no registro CFSR, o que nos indicará a razão para esta falha.
Qual é o próximo?
O que pode ser feito depois de analisarmos a causa da falha? O procedimento a seguir parece ser uma boa opção:
- Imprima os valores de todos os registros analisados no console de depuração (printf). Isso só pode ser feito se você tiver um depurador JTAG.
- Salve as informações de falha no flash interno ou externo (se disponível). Também é possível exibir o valor do registro do PC na tela do dispositivo (se disponível).
- Recarregue o processador NVIC_SystemReset ().

Fontes
- Joseph Yiu. O guia definitivo para o ARM Cortex-M3.
- Guia do usuário genérico dos dispositivos Cortex-M3.
- Manual de programação STM32 Cortex-M4 MCUs e MPUs.