
No mundo moderno do Big Data, o Apache Spark é o padrão de fato para o desenvolvimento de tarefas de processamento de dados em lote. Além disso, também é utilizado para criar aplicativos de streaming operando no conceito de microlote, processando e enviando dados em pequenas porções (Spark Structured Streaming). E, tradicionalmente, faz parte da pilha geral do Hadoop, usando YARN (ou, em alguns casos, Apache Mesos) como o gerenciador de recursos. Em 2020, seu uso tradicional para a maioria das empresas está em questão devido à falta de distribuições Hadoop decentes - o desenvolvimento de HDP e CDH foi interrompido, o CDH está subdesenvolvido e tem um custo alto e o resto dos provedores de Hadoop deixaram de existir ou têm um futuro vago.Portanto, o crescente interesse entre a comunidade e as grandes empresas é o lançamento do Apache Spark usando Kubernetes - tendo se tornado o padrão na orquestração de contêineres e gerenciamento de recursos em nuvens privadas e públicas, resolve o problema de programação de recursos inconveniente de tarefas do Spark no YARN e fornece uma plataforma de desenvolvimento constante com muitos comerciais e distribuições de código aberto para empresas de todos os tamanhos e faixas. Além disso, na onda de popularidade, a maioria já conseguiu adquirir algumas de suas instalações e aumentar sua expertise no uso, o que simplifica a mudança.ele resolve o agendamento complicado de tarefas do Spark no YARN e fornece uma plataforma em constante evolução com muitas distribuições comerciais e de código aberto para empresas de todos os tamanhos e faixas. Além disso, na onda de popularidade, a maioria já conseguiu adquirir algumas de suas instalações e aumentar sua expertise no uso, o que simplifica a mudança.ele resolve o complicado planejamento de recursos das tarefas do Spark no YARN e fornece uma plataforma robusta com muitas distribuições comerciais e de código aberto para empresas de todos os tamanhos e faixas. Além disso, na onda de popularidade, a maioria já conseguiu adquirir algumas de suas instalações e aumentar sua expertise no uso, o que simplifica a mudança.
A partir da versão 2.3.0, o Apache Spark adquiriu suporte oficial para executar tarefas no cluster Kubernetes e, hoje, falaremos sobre a maturidade atual desta abordagem, vários casos de uso e armadilhas que serão encontradas durante a implementação.
Em primeiro lugar, consideraremos o processo de desenvolvimento de tarefas e aplicativos com base no Apache Spark e destacaremos os casos típicos em que você precisa executar uma tarefa em um cluster Kubernetes. Ao preparar este post, o OpenShift é usado como um kit de distribuição e os comandos que são relevantes para seu utilitário de linha de comando (oc) serão fornecidos. Para outras distribuições do Kubernetes, os comandos correspondentes do utilitário de linha de comando padrão do Kubernetes (kubectl) ou seus análogos (por exemplo, para a política oc adm) podem ser usados.
O primeiro caso de uso é envio de faísca
No processo de desenvolvimento de tarefas e aplicativos, o desenvolvedor precisa executar tarefas para depurar a transformação de dados. Teoricamente, os stubs podem ser usados para esses fins, mas o desenvolvimento com a participação de instâncias reais (embora de teste) de sistemas finitos tem se mostrado nesta classe de problemas de maneira mais rápida e melhor. No caso em que estamos depurando em cópias reais de sistemas finais, dois cenários são possíveis:
- o desenvolvedor executa a tarefa Spark localmente no modo autônomo;
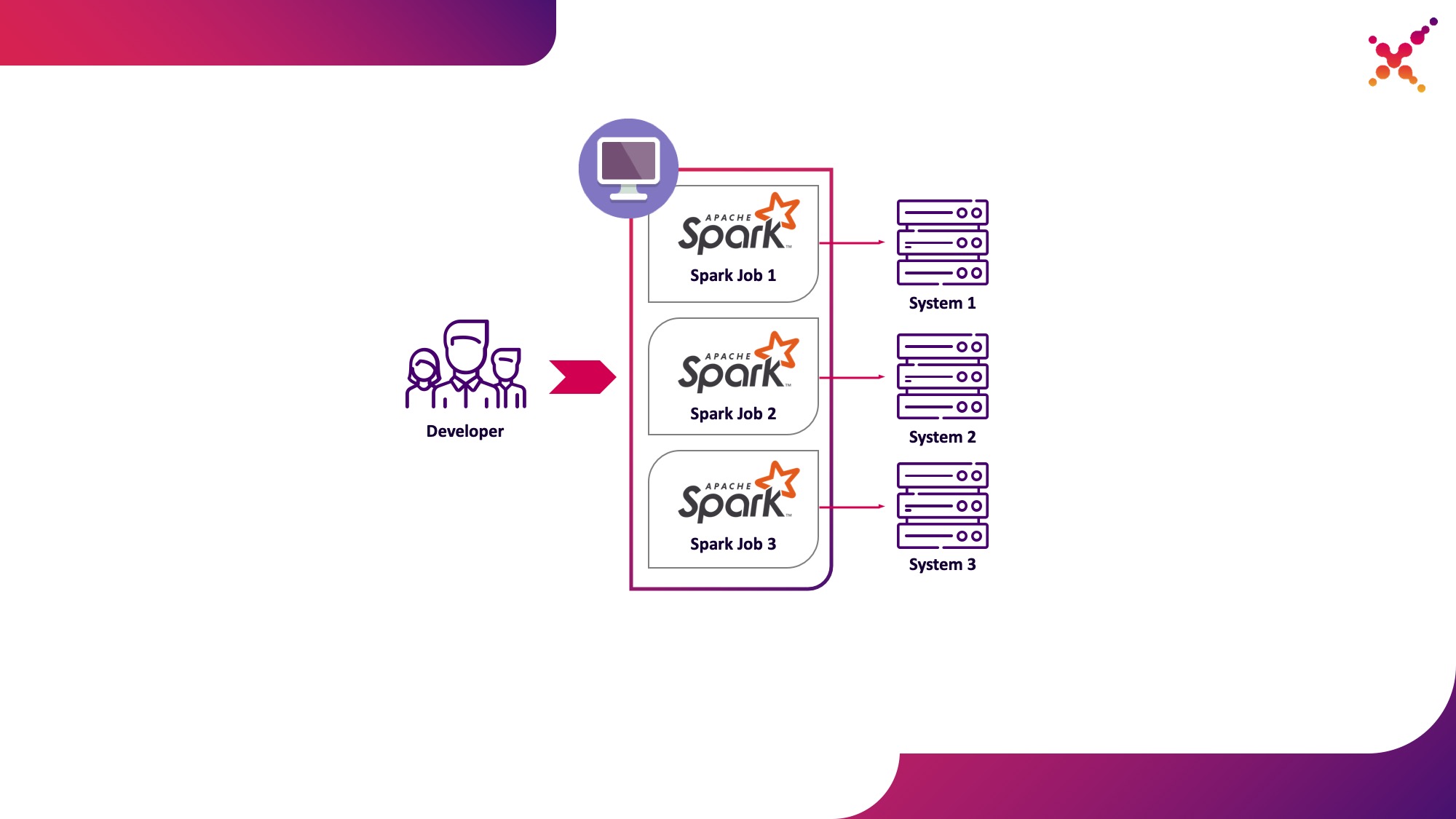
- um desenvolvedor executa uma tarefa Spark em um cluster Kubernetes em um loop de teste.

A primeira opção tem o direito de existir, mas acarreta uma série de desvantagens:
- para cada desenvolvedor, é necessário fornecer acesso do local de trabalho a todas as cópias dos sistemas finais de que ele precisa;
- a máquina de trabalho requer recursos suficientes para executar a tarefa desenvolvida.
A segunda opção é desprovida dessas desvantagens, já que o uso de um cluster Kubernetes permite alocar o pool de recursos necessário para executar tarefas e fornecer a ele o acesso necessário a instâncias de sistemas finais, fornecendo acesso flexível a ele usando o modelo de função Kubernetes para todos os membros da equipe de desenvolvimento. Vamos destacá-lo como o primeiro caso de uso - executando tarefas do Spark a partir de uma máquina de desenvolvimento local em um cluster Kubernetes em um loop de teste.
Vamos dar uma olhada mais de perto no processo de configuração do Spark para execução local. Para começar a usar o Spark, você precisa instalá-lo:
mkdir /opt/spark
cd /opt/spark
wget http://mirror.linux-ia64.org/apache/spark/spark-2.4.5/spark-2.4.5.tgz
tar zxvf spark-2.4.5.tgz
rm -f spark-2.4.5.tgz
Coletamos os pacotes necessários para trabalhar com o Kubernetes:
cd spark-2.4.5/
./build/mvn -Pkubernetes -DskipTests clean package
A compilação completa leva muito tempo e, para compilar imagens Docker e executá-las no cluster Kubernetes, na realidade, você só precisa de arquivos jar do diretório "assembly /", portanto, só pode criar este subprojeto:
./build/mvn -f ./assembly/pom.xml -Pkubernetes -DskipTests clean package
Para executar tarefas do Spark no Kubernetes, você precisa criar uma imagem Docker para usar como imagem base. 2 abordagens são possíveis aqui:
- A imagem do Docker gerada inclui o código executável para a tarefa Spark;
- A imagem criada inclui apenas Spark e as dependências necessárias, o código executável é hospedado remotamente (por exemplo, em HDFS).
Primeiro, vamos construir uma imagem Docker contendo um exemplo de teste de uma tarefa Spark. Para construir imagens Docker, o Spark possui um utilitário chamado "docker-image-tool". Vamos estudar a ajuda nisso:
./bin/docker-image-tool.sh --help
Ele pode ser usado para criar imagens Docker e enviá-las para registros remotos, mas por padrão tem várias desvantagens:
- sem falhas cria 3 imagens Docker de uma vez - para Spark, PySpark e R;
- não permite que você especifique o nome da imagem.
Portanto, usaremos uma versão modificada deste utilitário, mostrado abaixo:
vi bin/docker-image-tool-upd.sh
#!/usr/bin/env bash
function error {
echo "$@" 1>&2
exit 1
}
if [ -z "${SPARK_HOME}" ]; then
SPARK_HOME="$(cd "`dirname "$0"`"/..; pwd)"
fi
. "${SPARK_HOME}/bin/load-spark-env.sh"
function image_ref {
local image="$1"
local add_repo="${2:-1}"
if [ $add_repo = 1 ] && [ -n "$REPO" ]; then
image="$REPO/$image"
fi
if [ -n "$TAG" ]; then
image="$image:$TAG"
fi
echo "$image"
}
function build {
local BUILD_ARGS
local IMG_PATH
if [ ! -f "$SPARK_HOME/RELEASE" ]; then
IMG_PATH=$BASEDOCKERFILE
BUILD_ARGS=(
${BUILD_PARAMS}
--build-arg
img_path=$IMG_PATH
--build-arg
datagram_jars=datagram/runtimelibs
--build-arg
spark_jars=assembly/target/scala-$SPARK_SCALA_VERSION/jars
)
else
IMG_PATH="kubernetes/dockerfiles"
BUILD_ARGS=(${BUILD_PARAMS})
fi
if [ -z "$IMG_PATH" ]; then
error "Cannot find docker image. This script must be run from a runnable distribution of Apache Spark."
fi
if [ -z "$IMAGE_REF" ]; then
error "Cannot find docker image reference. Please add -i arg."
fi
local BINDING_BUILD_ARGS=(
${BUILD_PARAMS}
--build-arg
base_img=$(image_ref $IMAGE_REF)
)
local BASEDOCKERFILE=${BASEDOCKERFILE:-"$IMG_PATH/spark/docker/Dockerfile"}
docker build $NOCACHEARG "${BUILD_ARGS[@]}" \
-t $(image_ref $IMAGE_REF) \
-f "$BASEDOCKERFILE" .
}
function push {
docker push "$(image_ref $IMAGE_REF)"
}
function usage {
cat <<EOF
Usage: $0 [options] [command]
Builds or pushes the built-in Spark Docker image.
Commands:
build Build image. Requires a repository address to be provided if the image will be
pushed to a different registry.
push Push a pre-built image to a registry. Requires a repository address to be provided.
Options:
-f file Dockerfile to build for JVM based Jobs. By default builds the Dockerfile shipped with Spark.
-p file Dockerfile to build for PySpark Jobs. Builds Python dependencies and ships with Spark.
-R file Dockerfile to build for SparkR Jobs. Builds R dependencies and ships with Spark.
-r repo Repository address.
-i name Image name to apply to the built image, or to identify the image to be pushed.
-t tag Tag to apply to the built image, or to identify the image to be pushed.
-m Use minikube's Docker daemon.
-n Build docker image with --no-cache
-b arg Build arg to build or push the image. For multiple build args, this option needs to
be used separately for each build arg.
Using minikube when building images will do so directly into minikube's Docker daemon.
There is no need to push the images into minikube in that case, they'll be automatically
available when running applications inside the minikube cluster.
Check the following documentation for more information on using the minikube Docker daemon:
https://kubernetes.io/docs/getting-started-guides/minikube/#reusing-the-docker-daemon
Examples:
- Build image in minikube with tag "testing"
$0 -m -t testing build
- Build and push image with tag "v2.3.0" to docker.io/myrepo
$0 -r docker.io/myrepo -t v2.3.0 build
$0 -r docker.io/myrepo -t v2.3.0 push
EOF
}
if [[ "$@" = *--help ]] || [[ "$@" = *-h ]]; then
usage
exit 0
fi
REPO=
TAG=
BASEDOCKERFILE=
NOCACHEARG=
BUILD_PARAMS=
IMAGE_REF=
while getopts f:mr:t:nb:i: option
do
case "${option}"
in
f) BASEDOCKERFILE=${OPTARG};;
r) REPO=${OPTARG};;
t) TAG=${OPTARG};;
n) NOCACHEARG="--no-cache";;
i) IMAGE_REF=${OPTARG};;
b) BUILD_PARAMS=${BUILD_PARAMS}" --build-arg "${OPTARG};;
esac
done
case "${@: -1}" in
build)
build
;;
push)
if [ -z "$REPO" ]; then
usage
exit 1
fi
push
;;
*)
usage
exit 1
;;
esac
Usando-o, construímos uma imagem Spark de base contendo uma tarefa de teste para calcular o número Pi usando Spark (aqui {docker-registry-url} é a URL do registro de imagem Docker, {repo} é o nome do repositório dentro do registro, que coincide com o projeto no OpenShift , {image-name} é o nome da imagem (se a separação de imagem em três níveis for usada, por exemplo, como no registro de imagem integrado do Red Hat OpenShift), {tag} é a tag desta versão da imagem):
./bin/docker-image-tool-upd.sh -f resource-managers/kubernetes/docker/src/main/dockerfiles/spark/Dockerfile -r {docker-registry-url}/{repo} -i {image-name} -t {tag} build
Faça login no cluster OKD usando o utilitário do console (aqui {OKD-API-URL} é o URL da API do cluster OKD):
oc login {OKD-API-URL}
Vamos obter o token do usuário atual para autorização no Docker Registry:
oc whoami -t
Faça login no Docker Registry interno do cluster OKD (use o token obtido com o comando anterior como a senha):
docker login {docker-registry-url}
Faça upload da imagem do Docker construída para o Docker Registry OKD:
./bin/docker-image-tool-upd.sh -r {docker-registry-url}/{repo} -i {image-name} -t {tag} push
Vamos verificar se a imagem montada está disponível em OKD. Para fazer isso, abra um URL com uma lista de imagens do projeto correspondente no navegador (aqui {project} é o nome do projeto dentro do cluster OpenShift, {OKD-WEBUI-URL} é o URL do console da Web OpenShift) - https: // {OKD-WEBUI-URL} / console / project / {project} / browse / images / {nome da imagem}.
Para executar tarefas, uma conta de serviço deve ser criada com os privilégios de executar pods como root (discutiremos esse ponto mais tarde):
oc create sa spark -n {project}
oc adm policy add-scc-to-user anyuid -z spark -n {project}
Execute o comando spark-submit para publicar a tarefa Spark no cluster OKD, especificando a conta de serviço criada e a imagem Docker:
/opt/spark/bin/spark-submit --name spark-test --class org.apache.spark.examples.SparkPi --conf spark.executor.instances=3 --conf spark.kubernetes.authenticate.driver.serviceAccountName=spark --conf spark.kubernetes.namespace={project} --conf spark.submit.deployMode=cluster --conf spark.kubernetes.container.image={docker-registry-url}/{repo}/{image-name}:{tag} --conf spark.master=k8s://https://{OKD-API-URL} local:///opt/spark/examples/target/scala-2.11/jars/spark-examples_2.11-2.4.5.jar
Aqui:
--name é o nome da tarefa que participará da formação do nome dos pods do Kubernetes;
--class - a classe do arquivo executável chamado quando a tarefa é iniciada;
--conf - parâmetros de configuração do Spark;
spark.executor.instances O número de executores Spark a serem executados.
spark.kubernetes.authenticate.driver.serviceAccountName O nome da conta de serviço Kubernetes usada ao iniciar pods (para definir o contexto de segurança e os recursos ao interagir com a API Kubernetes);
spark.kubernetes.namespace - namespace do Kubernetes no qual os pods do driver e do executor serão executados;
spark.submit.deployMode - método de inicialização do Spark ("cluster" é usado para envio de faísca padrão, "cliente" para Spark Operator e versões posteriores do Spark);
spark.kubernetes.container.image A imagem Docker usada para executar os pods.
spark.master - URL da API Kubernetes (o externo é especificado para que a chamada ocorra a partir da máquina local);
local: // é o caminho para o executável Spark dentro da imagem Docker.
Vá para o projeto OKD correspondente e estude os pods criados - https: // {OKD-WEBUI-URL} / console / project / {project} / browse / pods.
Para simplificar o processo de desenvolvimento, outra opção pode ser usada, na qual uma imagem Spark de base comum é criada, usada por todas as tarefas para iniciar, e os instantâneos dos arquivos executáveis são publicados em um armazenamento externo (por exemplo, Hadoop) e especificados como um link ao chamar o spark-submit. Nesse caso, você pode executar diferentes versões de tarefas do Spark sem reconstruir imagens do Docker, usando, por exemplo, WebHDFS para publicar imagens. Enviamos uma solicitação para criar um arquivo (aqui {host} é o host do serviço WebHDFS, {port} é a porta do serviço WebHDFS, {path-to-file-on-hdfs} é o caminho desejado para o arquivo no HDFS):
curl -i -X PUT "http://{host}:{port}/webhdfs/v1/{path-to-file-on-hdfs}?op=CREATE
Isso receberá uma resposta do formulário (aqui {local} é o URL que deve ser usado para baixar o arquivo):
HTTP/1.1 307 TEMPORARY_REDIRECT
Location: {location}
Content-Length: 0
Carregue o arquivo executável Spark no HDFS (aqui {path-to-local-file} é o caminho para o executável Spark no host atual):
curl -i -X PUT -T {path-to-local-file} "{location}"
Depois disso, podemos fazer o spark-submit usando o arquivo Spark carregado para HDFS (aqui {class-name} é o nome da classe que precisa ser iniciada para completar a tarefa):
/opt/spark/bin/spark-submit --name spark-test --class {class-name} --conf spark.executor.instances=3 --conf spark.kubernetes.authenticate.driver.serviceAccountName=spark --conf spark.kubernetes.namespace={project} --conf spark.submit.deployMode=cluster --conf spark.kubernetes.container.image={docker-registry-url}/{repo}/{image-name}:{tag} --conf spark.master=k8s://https://{OKD-API-URL} hdfs://{host}:{port}/{path-to-file-on-hdfs}
Ao mesmo tempo, deve-se observar que, para acessar o HDFS e permitir que a tarefa funcione, pode ser necessário alterar o Dockerfile e o script entrypoint.sh - adicione uma diretiva ao Dockerfile para copiar bibliotecas dependentes para o diretório / opt / spark / jars e incluir o arquivo de configuração HDFS em SPARK_CLASSPATH no entrypoint. sh.
Segundo caso de uso - Apache Livy
Além disso, quando a tarefa é desenvolvida e é necessário testar o resultado obtido, surge a questão de iniciá-la dentro do processo de CI / CD e rastrear o status de sua execução. Claro, você pode executá-lo com uma chamada local de envio de faísca, mas isso complica a infraestrutura de CI / CD, pois requer a instalação e configuração do Spark nos agentes / executores de servidor CI e configuração de acesso à API Kubernetes. Para este caso, a implementação de destino optou por usar o Apache Livy como a API REST para executar tarefas Spark hospedadas no cluster Kubernetes. Ele pode ser usado para iniciar tarefas Spark no cluster Kubernetes usando solicitações cURL regulares, que são facilmente implementadas com base em qualquer solução de CI, e sua colocação dentro do cluster Kubernetes resolve o problema de autenticação ao interagir com a API Kubernetes.
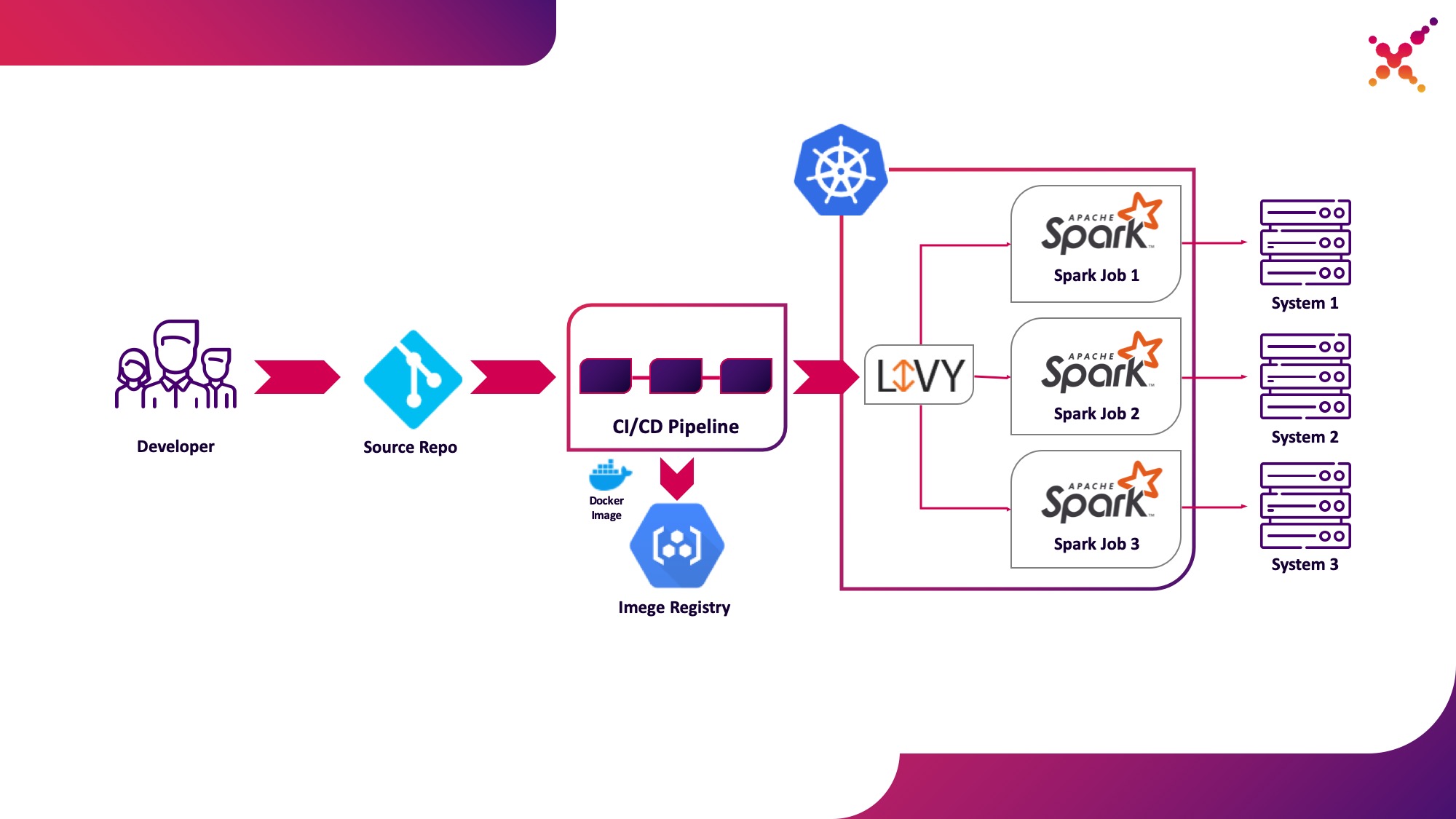
Vamos destacá-lo como o segundo caso de uso - executando tarefas do Spark como parte do processo de CI / CD em um cluster Kubernetes em um loop de teste.
Um pouco sobre o Apache Livy - ele funciona como um servidor HTTP que fornece uma interface da Web e uma API RESTful que permite executar remotamente o spark-submit passando os parâmetros necessários. Tradicionalmente, ele foi enviado como parte da distribuição HDP, mas também pode ser implantado em OKD ou qualquer outra instalação do Kubernetes usando o manifesto apropriado e um conjunto de imagens do Docker, como este - github.com/ttauveron/k8s-big-data-experiments/tree/master /livy-spark-2.3 . Para nosso caso, uma imagem Docker semelhante foi construída, incluindo Spark versão 2.4.5 do seguinte Dockerfile:
FROM java:8-alpine
ENV SPARK_HOME=/opt/spark
ENV LIVY_HOME=/opt/livy
ENV HADOOP_CONF_DIR=/etc/hadoop/conf
ENV SPARK_USER=spark
WORKDIR /opt
RUN apk add --update openssl wget bash && \
wget -P /opt https://downloads.apache.org/spark/spark-2.4.5/spark-2.4.5-bin-hadoop2.7.tgz && \
tar xvzf spark-2.4.5-bin-hadoop2.7.tgz && \
rm spark-2.4.5-bin-hadoop2.7.tgz && \
ln -s /opt/spark-2.4.5-bin-hadoop2.7 /opt/spark
RUN wget http://mirror.its.dal.ca/apache/incubator/livy/0.7.0-incubating/apache-livy-0.7.0-incubating-bin.zip && \
unzip apache-livy-0.7.0-incubating-bin.zip && \
rm apache-livy-0.7.0-incubating-bin.zip && \
ln -s /opt/apache-livy-0.7.0-incubating-bin /opt/livy && \
mkdir /var/log/livy && \
ln -s /var/log/livy /opt/livy/logs && \
cp /opt/livy/conf/log4j.properties.template /opt/livy/conf/log4j.properties
ADD livy.conf /opt/livy/conf
ADD spark-defaults.conf /opt/spark/conf/spark-defaults.conf
ADD entrypoint.sh /entrypoint.sh
ENV PATH="/opt/livy/bin:${PATH}"
EXPOSE 8998
ENTRYPOINT ["/entrypoint.sh"]
CMD ["livy-server"]
A imagem gerada pode ser construída e carregada em seu repositório Docker existente, por exemplo, o repositório interno OKD. Para implantá-lo, o seguinte manifesto é usado ({registry-url} é a URL do registro da imagem Docker, {image-name} é o nome da imagem Docker, {tag} é a tag da imagem Docker, {livy-url} é a URL desejada onde o servidor estará acessível. Livy; o manifesto "Route" é usado se o Red Hat OpenShift for usado como a distribuição do Kubernetes; caso contrário, o manifesto de entrada ou serviço correspondente do tipo NodePort é usado):
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
component: livy
name: livy
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
component: livy
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels:
component: livy
spec:
containers:
- command:
- livy-server
env:
- name: K8S_API_HOST
value: localhost
- name: SPARK_KUBERNETES_IMAGE
value: 'gnut3ll4/spark:v1.0.14'
image: '{registry-url}/{image-name}:{tag}'
imagePullPolicy: Always
name: livy
ports:
- containerPort: 8998
name: livy-rest
protocol: TCP
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /var/log/livy
name: livy-log
- mountPath: /opt/.livy-sessions/
name: livy-sessions
- mountPath: /opt/livy/conf/livy.conf
name: livy-config
subPath: livy.conf
- mountPath: /opt/spark/conf/spark-defaults.conf
name: spark-config
subPath: spark-defaults.conf
- command:
- /usr/local/bin/kubectl
- proxy
- '--port'
- '8443'
image: 'gnut3ll4/kubectl-sidecar:latest'
imagePullPolicy: Always
name: kubectl
ports:
- containerPort: 8443
name: k8s-api
protocol: TCP
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
serviceAccount: spark
serviceAccountName: spark
terminationGracePeriodSeconds: 30
volumes:
- emptyDir: {}
name: livy-log
- emptyDir: {}
name: livy-sessions
- configMap:
defaultMode: 420
items:
- key: livy.conf
path: livy.conf
name: livy-config
name: livy-config
- configMap:
defaultMode: 420
items:
- key: spark-defaults.conf
path: spark-defaults.conf
name: livy-config
name: spark-config
---
apiVersion: v1
kind: ConfigMap
metadata:
name: livy-config
data:
livy.conf: |-
livy.spark.deploy-mode=cluster
livy.file.local-dir-whitelist=/opt/.livy-sessions/
livy.spark.master=k8s://http://localhost:8443
livy.server.session.state-retain.sec = 8h
spark-defaults.conf: 'spark.kubernetes.container.image "gnut3ll4/spark:v1.0.14"'
---
apiVersion: v1
kind: Service
metadata:
labels:
app: livy
name: livy
spec:
ports:
- name: livy-rest
port: 8998
protocol: TCP
targetPort: 8998
selector:
component: livy
sessionAffinity: None
type: ClusterIP
---
apiVersion: route.openshift.io/v1
kind: Route
metadata:
labels:
app: livy
name: livy
spec:
host: {livy-url}
port:
targetPort: livy-rest
to:
kind: Service
name: livy
weight: 100
wildcardPolicy: None
Após sua aplicação e lançamento bem-sucedido do pod, a interface gráfica do Livy está disponível no link: http: // {livy-url} / ui. Com Livy, podemos publicar nossa tarefa Spark usando uma solicitação REST, por exemplo, do Postman. Um exemplo de coleção com solicitações é apresentado a seguir (na matriz "args", argumentos de configuração com variáveis necessárias para a operação da tarefa iniciada podem ser passados):
{
"info": {
"_postman_id": "be135198-d2ff-47b6-a33e-0d27b9dba4c8",
"name": "Spark Livy",
"schema": "https://schema.getpostman.com/json/collection/v2.1.0/collection.json"
},
"item": [
{
"name": "1 Submit job with jar",
"request": {
"method": "POST",
"header": [
{
"key": "Content-Type",
"value": "application/json"
}
],
"body": {
"mode": "raw",
"raw": "{\n\t\"file\": \"local:///opt/spark/examples/target/scala-2.11/jars/spark-examples_2.11-2.4.5.jar\", \n\t\"className\": \"org.apache.spark.examples.SparkPi\",\n\t\"numExecutors\":1,\n\t\"name\": \"spark-test-1\",\n\t\"conf\": {\n\t\t\"spark.jars.ivy\": \"/tmp/.ivy\",\n\t\t\"spark.kubernetes.authenticate.driver.serviceAccountName\": \"spark\",\n\t\t\"spark.kubernetes.namespace\": \"{project}\",\n\t\t\"spark.kubernetes.container.image\": \"{docker-registry-url}/{repo}/{image-name}:{tag}\"\n\t}\n}"
},
"url": {
"raw": "http://{livy-url}/batches",
"protocol": "http",
"host": [
"{livy-url}"
],
"path": [
"batches"
]
}
},
"response": []
},
{
"name": "2 Submit job without jar",
"request": {
"method": "POST",
"header": [
{
"key": "Content-Type",
"value": "application/json"
}
],
"body": {
"mode": "raw",
"raw": "{\n\t\"file\": \"hdfs://{host}:{port}/{path-to-file-on-hdfs}\", \n\t\"className\": \"{class-name}\",\n\t\"numExecutors\":1,\n\t\"name\": \"spark-test-2\",\n\t\"proxyUser\": \"0\",\n\t\"conf\": {\n\t\t\"spark.jars.ivy\": \"/tmp/.ivy\",\n\t\t\"spark.kubernetes.authenticate.driver.serviceAccountName\": \"spark\",\n\t\t\"spark.kubernetes.namespace\": \"{project}\",\n\t\t\"spark.kubernetes.container.image\": \"{docker-registry-url}/{repo}/{image-name}:{tag}\"\n\t},\n\t\"args\": [\n\t\t\"HADOOP_CONF_DIR=/opt/spark/hadoop-conf\",\n\t\t\"MASTER=k8s://https://kubernetes.default.svc:8443\"\n\t]\n}"
},
"url": {
"raw": "http://{livy-url}/batches",
"protocol": "http",
"host": [
"{livy-url}"
],
"path": [
"batches"
]
}
},
"response": []
}
],
"event": [
{
"listen": "prerequest",
"script": {
"id": "41bea1d0-278c-40c9-ad42-bf2e6268897d",
"type": "text/javascript",
"exec": [
""
]
}
},
{
"listen": "test",
"script": {
"id": "3cdd7736-a885-4a2d-9668-bd75798f4560",
"type": "text/javascript",
"exec": [
""
]
}
}
],
"protocolProfileBehavior": {}
}
Vamos executar a primeira solicitação da coleção, vá para a interface do OKD e verifique se a tarefa foi iniciada com sucesso - https: // {OKD-WEBUI-URL} / console / project / {project} / browse / pods. Nesse caso, uma sessão aparecerá na interface do Livy (http: // {livy-url} / ui), dentro da qual, usando a API do Livy ou a interface gráfica, você pode acompanhar o andamento da tarefa e estudar os logs da sessão.
Agora vamos mostrar como Livy funciona. Para fazer isso, vamos examinar os registros do contêiner Livy dentro do pod com o servidor Livy - https: // {OKD-WEBUI-URL} / console / project / {project} / browse / pods / {livy-pod-name}? Tab = logs. A partir deles, você pode ver que ao chamar a API REST do Livy em um contêiner denominado "livy", um envio de faísca é executado, semelhante ao que usamos acima (aqui {livy-pod-name} é o nome do pod criado com o servidor Livy). A coleção também fornece uma segunda solicitação que permite executar tarefas com hospedagem remota do executável Spark usando o servidor Livy.
Terceiro caso de uso - Operador Spark
Agora que a tarefa foi testada, surge a questão de executá-la regularmente. A maneira nativa de executar tarefas regularmente no cluster Kubernetes é a entidade CronJob e você pode usá-la, mas, no momento, o uso de operadores para controlar aplicativos no Kubernetes é muito popular e, para o Spark, há um operador bastante maduro que, entre outras coisas, é usado em soluções de nível empresarial (por exemplo, plataforma Lightbend FastData). Recomendamos usá-lo - a versão estável atual do Spark (2.4.5) tem opções bastante limitadas para configurar o lançamento de tarefas do Spark no Kubernetes, enquanto na próxima versão principal (3.0.0) o suporte total para o Kubernetes é anunciado, mas sua data de lançamento permanece desconhecida. O Spark Operator compensa essa lacuna adicionando parâmetros de configuração importantes (por exemplo,montagem do ConfigMap com configuração de acesso ao Hadoop em pods Spark) e a capacidade de executar regularmente a tarefa em uma programação.
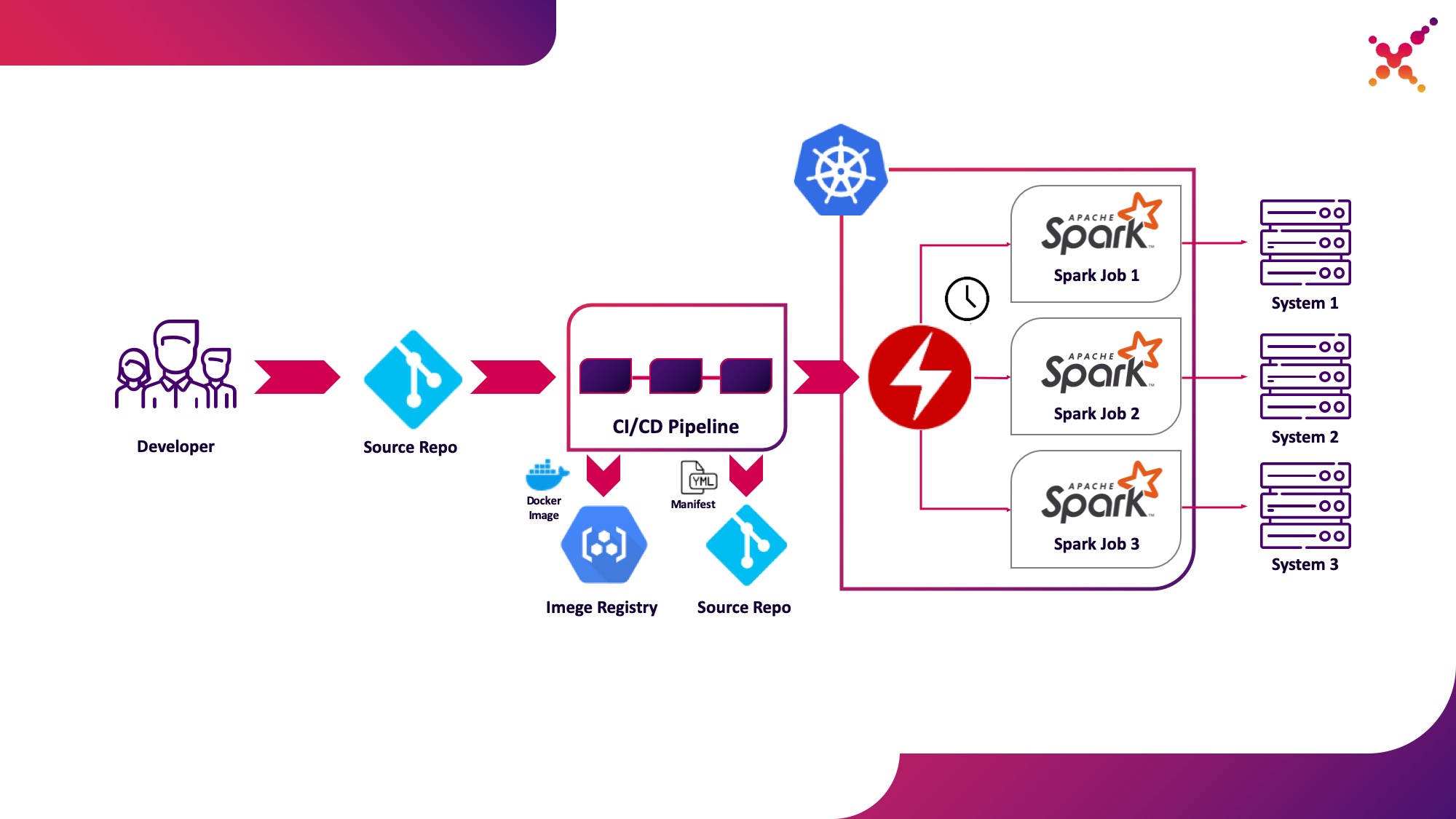
Vamos destacá-lo como o terceiro caso de uso - executar regularmente tarefas do Spark em um cluster do Kubernetes em um loop de produção.
O Spark Operator é de código aberto e desenvolvido como parte do Google Cloud Platform - github.com/GoogleCloudPlatform/spark-on-k8s-operator . Sua instalação pode ser feita de 3 formas:
- Como parte da instalação da Lightbend FastData Platform / Cloudflow;
- Com Helm:
helm repo add incubator http://storage.googleapis.com/kubernetes-charts-incubator helm install incubator/sparkoperator --namespace spark-operator
- (https://github.com/GoogleCloudPlatform/spark-on-k8s-operator/tree/master/manifest). — Cloudflow API v1beta1. , Spark Git API, , «v1beta1-0.9.0-2.4.0». CRD, «versions»:
oc get crd sparkapplications.sparkoperator.k8s.io -o yaml
Se o operador estiver instalado corretamente, um pod ativo com o operador Spark (por exemplo, cloudflow-fdp-sparkoperator no espaço do Cloudflow para instalar o Cloudflow) aparecerá no projeto correspondente e o tipo de recurso do Kubernetes correspondente chamado "sparkapplications" aparecerá. Você pode examinar os aplicativos Spark disponíveis com o seguinte comando:
oc get sparkapplications -n {project}
Para executar tarefas com o Spark Operator, você precisa fazer três coisas:
- criar uma imagem Docker que inclui todas as bibliotecas necessárias, bem como configuração e arquivos executáveis. Na imagem de destino, esta é uma imagem criada no estágio de CI / CD e testada em um cluster de teste;
- publicar a imagem do Docker no registro acessível a partir do cluster Kubernetes;
- «SparkApplication» . (, github.com/GoogleCloudPlatform/spark-on-k8s-operator/blob/v1beta1-0.9.0-2.4.0/examples/spark-pi.yaml). :
- «apiVersion» API, ;
- «metadata.namespace» , ;
- «spec.image» Docker ;
- «spec.mainClass» Spark, ;
- «spec.mainApplicationFile» jar ;
- o dicionário "spec.sparkVersion" deve indicar a versão do Spark usada;
- o dicionário "spec.driver.serviceAccount" deve conter uma conta de serviço dentro do namespace Kubernetes apropriado que será usado para iniciar o aplicativo;
- o dicionário "spec.executor" deve indicar a quantidade de recursos alocados à aplicação;
- o dicionário "spec.volumeMounts" deve especificar o diretório local no qual os arquivos de tarefas locais do Spark serão criados.
Um exemplo de geração de manifesto (aqui, {spark-service-account} é uma conta de serviço dentro do cluster Kubernetes para executar tarefas Spark):
apiVersion: "sparkoperator.k8s.io/v1beta1"
kind: SparkApplication
metadata:
name: spark-pi
namespace: {project}
spec:
type: Scala
mode: cluster
image: "gcr.io/spark-operator/spark:v2.4.0"
imagePullPolicy: Always
mainClass: org.apache.spark.examples.SparkPi
mainApplicationFile: "local:///opt/spark/examples/jars/spark-examples_2.11-2.4.0.jar"
sparkVersion: "2.4.0"
restartPolicy:
type: Never
volumes:
- name: "test-volume"
hostPath:
path: "/tmp"
type: Directory
driver:
cores: 0.1
coreLimit: "200m"
memory: "512m"
labels:
version: 2.4.0
serviceAccount: {spark-service-account}
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
executor:
cores: 1
instances: 1
memory: "512m"
labels:
version: 2.4.0
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
Este manifesto especifica uma conta de serviço para a qual, antes de publicar o manifesto, você precisa criar as vinculações de função necessárias que fornecem os direitos de acesso necessários para o aplicativo Spark interagir com a API Kubernetes (se necessário). Em nosso caso, o aplicativo precisa dos direitos para criar pods. Vamos criar a vinculação de função necessária:
oc adm policy add-role-to-user edit system:serviceaccount:{project}:{spark-service-account} -n {project}
Também é importante notar que a especificação desse manifesto pode especificar o parâmetro hadoopConfigMap, que permite especificar um ConfigMap com uma configuração Hadoop sem ter que primeiro colocar o arquivo correspondente na imagem Docker. Também é adequado para o lançamento regular de tarefas - usando o parâmetro "agendamento", um agendamento para o lançamento desta tarefa pode ser especificado.
Depois disso, salvamos nosso manifesto no arquivo spark-pi.yaml e o aplicamos ao nosso cluster Kubernetes:
oc apply -f spark-pi.yaml
Isso criará um objeto do tipo "sparkapplications":
oc get sparkapplications -n {project}
> NAME AGE
> spark-pi 22h
Isso criará um pod com um aplicativo, o status do qual será exibido nos "sparkapplications" criados. Ele pode ser visualizado com o seguinte comando:
oc get sparkapplications spark-pi -o yaml -n {project}
Após a conclusão da tarefa, o POD fará a transição para o status "Concluído", que também será atualizado para "sparkapplications". Os registros do aplicativo podem ser visualizados em um navegador ou usando o seguinte comando (aqui {sparkapplications-pod-name} é o nome do pod da tarefa em execução):
oc logs {sparkapplications-pod-name} -n {project}
As tarefas do Spark também podem ser gerenciadas usando o utilitário especializado sparkctl. Para instalá-lo, clonamos o repositório com seu código-fonte, instalamos Go e construímos este utilitário:
git clone https://github.com/GoogleCloudPlatform/spark-on-k8s-operator.git
cd spark-on-k8s-operator/
wget https://dl.google.com/go/go1.13.3.linux-amd64.tar.gz
tar -xzf go1.13.3.linux-amd64.tar.gz
sudo mv go /usr/local
mkdir $HOME/Projects
export GOROOT=/usr/local/go
export GOPATH=$HOME/Projects
export PATH=$GOPATH/bin:$GOROOT/bin:$PATH
go -version
cd sparkctl
go build -o sparkctl
sudo mv sparkctl /usr/local/bin
Vamos examinar a lista de tarefas em execução do Spark:
sparkctl list -n {project}
Vamos criar uma descrição para a tarefa Spark:
vi spark-app.yaml
apiVersion: "sparkoperator.k8s.io/v1beta1"
kind: SparkApplication
metadata:
name: spark-pi
namespace: {project}
spec:
type: Scala
mode: cluster
image: "gcr.io/spark-operator/spark:v2.4.0"
imagePullPolicy: Always
mainClass: org.apache.spark.examples.SparkPi
mainApplicationFile: "local:///opt/spark/examples/jars/spark-examples_2.11-2.4.0.jar"
sparkVersion: "2.4.0"
restartPolicy:
type: Never
volumes:
- name: "test-volume"
hostPath:
path: "/tmp"
type: Directory
driver:
cores: 1
coreLimit: "1000m"
memory: "512m"
labels:
version: 2.4.0
serviceAccount: spark
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
executor:
cores: 1
instances: 1
memory: "512m"
labels:
version: 2.4.0
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
Vamos executar a tarefa descrita usando o sparkctl:
sparkctl create spark-app.yaml -n {project}
Vamos examinar a lista de tarefas em execução do Spark:
sparkctl list -n {project}
Vamos examinar a lista de eventos da tarefa iniciada do Spark:
sparkctl event spark-pi -n {project} -f
Vamos examinar o status da tarefa em execução do Spark:
sparkctl status spark-pi -n {project}
Concluindo, gostaria de considerar as desvantagens descobertas de operar a versão estável atual do Spark (2.4.5) no Kubernetes:
- , , — Data Locality. YARN , , ( ). Spark , , , . Kubernetes , . , , , , Spark . , Kubernetes (, Alluxio), Kubernetes.
- — . , Spark , Kerberos ( 3.0.0, ), Spark (https://spark.apache.org/docs/2.4.5/security.html) YARN, Mesos Standalone Cluster. , Spark, — , , . root, , UID, ( PodSecurityPolicies ). Docker, Spark , .
- A execução de tarefas do Spark com o Kubernetes ainda está oficialmente em modo experimental e pode haver mudanças significativas nos artefatos usados (arquivos de configuração, imagens base do Docker e scripts de inicialização) no futuro. De fato, ao preparar o material, as versões 2.3.0 e 2.4.5 foram testadas, o comportamento foi significativamente diferente.
Vamos esperar por atualizações - uma nova versão do Spark (3.0.0) foi lançada recentemente, que trouxe mudanças tangíveis ao trabalho do Spark no Kubernetes, mas manteve o status experimental de suporte para este gerenciador de recursos. Talvez as próximas atualizações realmente tornem possível recomendar totalmente o abandono do YARN e a execução de tarefas do Spark no Kubernetes, sem temer pela segurança do seu sistema e sem a necessidade de refinar componentes funcionais de forma independente.
Fin.