Portanto, quando ocorre um consumo anormal de recursos (CPU, memória, disco, rede, ...) em um dos milhares de servidores controlados , é necessário descobrir "quem é a culpa e o que fazer".
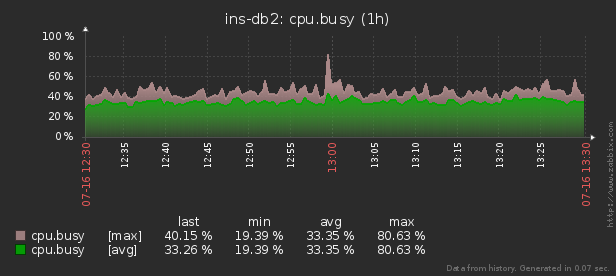
Existe um utilitário pidstat para monitoramento em tempo real do uso de recursos do servidor Linux "no momento" . Ou seja, se os picos de carga forem periódicos, eles podem ser "hachurados" diretamente no console. Mas queremos analisar esses dados após o fato , tentando encontrar o processo que criou a carga máxima nos recursos.
Ou seja, gostaria de poder olhar para os dados coletados anteriormente vários relatórios bonitos com agrupamento e detalhamento em um intervalo como estes:
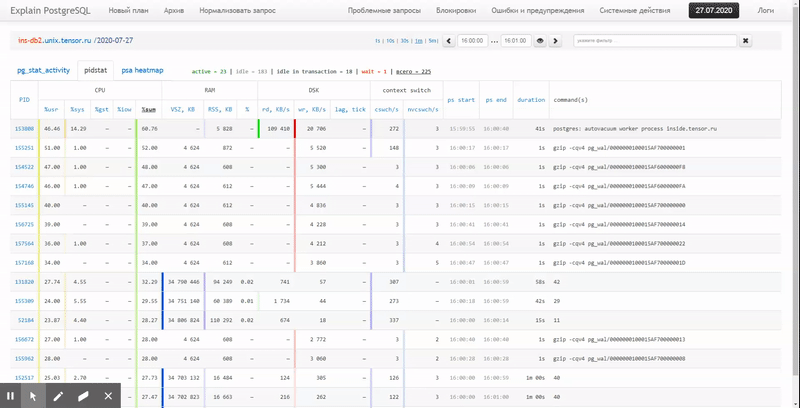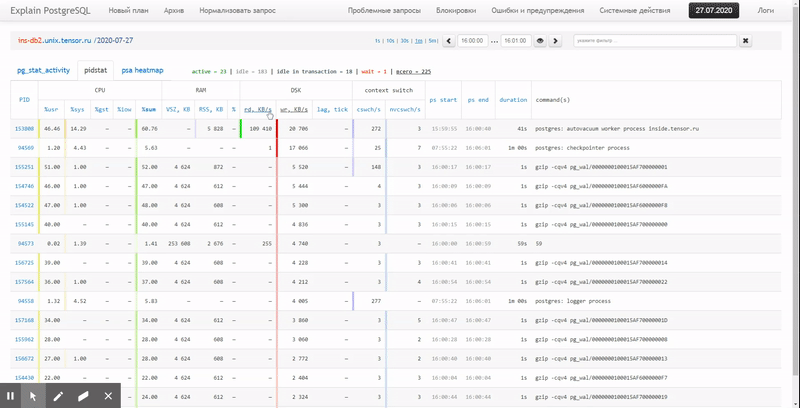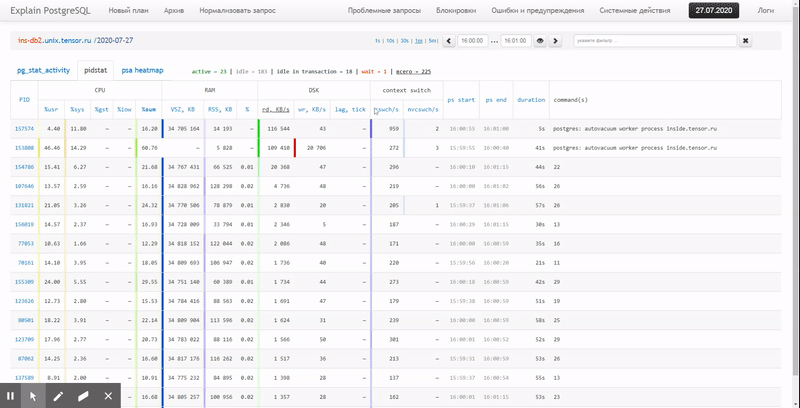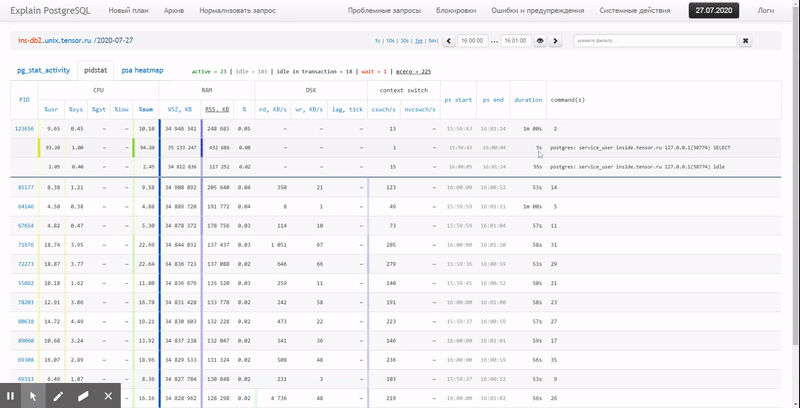
Neste artigo, vamos considerar como tudo isso pode ser economicamente localizado no banco de dados e como coletar de forma mais eficaz um relatório desses dados usando funções de janela e GRUPO SETS .
Primeiro, vamos ver que tipo de dados podemos extrair se levarmos "tudo ao máximo":
pidstat -rudw -lh 1| Tempo | UID | PID | % usr | % sistema | % convidado | % CPU | CPU | minflt / s | majflt / s | VSZ | Rss | % MEM | kB_rd / s | kB_wr / s | kB_ccwr / s | cswch / s | nvcswch / s | Comando |
| 1594893415 | 0 | 1 | 0,00 | 13,08 | 0,00 | 13,08 | 52 | 0,00 | 0,00 | 197312 | 8512 | 0,00 | 0,00 | 0,00 | 0,00 | 0,00 | 7,48 | / usr / lib / systemd / systemd --switched-root --system --deserialize 21 |
| 1594893415 | 0 | nove | 0,00 | 0,93 | 0,00 | 0,93 | 40 | 0,00 | 0,00 | 0 | 0 | 0,00 | 0,00 | 0,00 | 0,00 | 350,47 | 0,00 | rcu_sched |
| 1594893415 | 0 | treze | 0,00 | 0,00 | 0,00 | 0,00 | 1 | 0,00 | 0,00 | 0 | 0 | 0,00 | 0,00 | 0,00 | 0,00 | 1,87 | 0,00 | migração / 11,87 |
Todos esses valores são divididos em várias classes. Alguns deles mudam constantemente (CPU e atividade do disco), outros raramente (alocação de memória), e o Comando não apenas raramente muda dentro do mesmo processo, mas também se repete regularmente em diferentes PIDs.
Estrutura de base
Para simplificar, vamos nos limitar a uma métrica para cada "classe" que salvaremos:% CPU, RSS e Comando.
Como sabemos de antemão que Command é repetido regularmente, vamos simplesmente movê-lo para um dicionário de tabela separado, onde o hash MD5 atuará como a chave UUID:
CREATE TABLE diccmd(
cmd
uuid
PRIMARY KEY
, data
varchar
);E para os próprios dados, uma tabela deste tipo é adequada para nós:
CREATE TABLE pidstat(
host
uuid
, tm
integer
, pid
integer
, cpu
smallint
, rss
bigint
, cmd
uuid
);Deixe-me chamar sua atenção para o fato de que, como a% CPU sempre chega até nós com uma precisão de 2 casas decimais e certamente não excede 100,00, podemos facilmente multiplicá-la por 100 e adicionar
smallint. Por um lado, isso nos poupará dos problemas de precisão da contabilidade durante as operações, por outro lado, é ainda melhor armazenar apenas 2 bytes em comparação com 4 bytes realou 8 bytes double precision.
Você pode ler mais sobre maneiras de empacotar registros de maneira eficiente no armazenamento PostgreSQL no artigo "Economize um bom centavo em grandes volumes" e sobre como aumentar a taxa de transferência do banco de dados para escrita - em "Escrevendo em sublight: 1 host, 1 dia, 1 TB" .
Armazenamento "gratuito" de NULLs
Para salvar a performance do subsistema de disco de nosso banco de dados e o tamanho do banco de dados, tentaremos representar o máximo de dados possível na forma de NULL - seu armazenamento é praticamente "gratuito", já que leva apenas um bocado no cabeçalho do registro.
Mais informações sobre a mecânica interna de representação de registros no PostgreSQL podem ser encontradas na palestra de Nikolai Shaplov em PGConf.Russia 2016 "O que há dentro disso: armazenamento de dados em um nível baixo . " O slide # 16 é dedicado ao armazenamento NULL .Vamos dar uma olhada mais de perto nos tipos de nossos dados:
- CPU / DSK
muda constantemente, mas muitas vezes muda para zero - então é benéfico escrever NULL em vez de 0 na base . - RSS / CMD
muda muito raramente - portanto, escreveremos NULL em vez de repetições no mesmo PID.
Acontece uma imagem como esta, se você olhar para ela no contexto de um PID específico:

É claro que se nosso processo começar a executar outro comando, então o valor da memória usada provavelmente também será diferente de antes - portanto, concordaremos que ao alterar o CMD, o valor do RSS também será corrigir independentemente do valor anterior.
Ou seja , uma entrada com um valor CMD preenchido também tem um valor RSS . Vamos nos lembrar desse momento, ele ainda será útil para nós.
Elaborando um belo relatório
Agora, vamos montar uma consulta que nos mostrará os consumidores de recursos de um host específico em um intervalo de tempo específico.
Mas vamos fazer isso imediatamente com o uso mínimo de recursos - semelhante ao artigo sobre SELF JOIN e funções de janela .
Usando parâmetros de entrada
Para não especificar os valores dos parâmetros do relatório (ou $ 1 / $ 2) em vários lugares durante a consulta SQL, selecionaremos o CTE do único campo json no qual esses parâmetros estão localizados por chaves:
--
WITH args AS (
SELECT
json_object(
ARRAY[
'dtb'
, extract('epoch' from '2020-07-16 10:00'::timestamp(0)) -- timestamp integer
, 'dte'
, extract('epoch' from '2020-07-16 10:01'::timestamp(0))
, 'host'
, 'e828a54d-7e8a-43dd-b213-30c3201a6d8e' -- uuid
]::text[]
)
)
Recuperando dados brutos
Como não inventamos nenhum agregado complexo, a única maneira de analisar os dados é lê-los. Para isso, precisamos de um índice óbvio:
CREATE INDEX ON pidstat(host, tm);-- ""
, src AS (
SELECT
*
FROM
pidstat
WHERE
host = ((TABLE args) ->> 'host')::uuid AND
tm >= ((TABLE args) ->> 'dtb')::integer AND
tm < ((TABLE args) ->> 'dte')::integer
)
Análise de agrupamento de chaves
Para cada PID encontrado, determinamos o intervalo de sua atividade e tomamos o CMD do primeiro registro nesse intervalo.
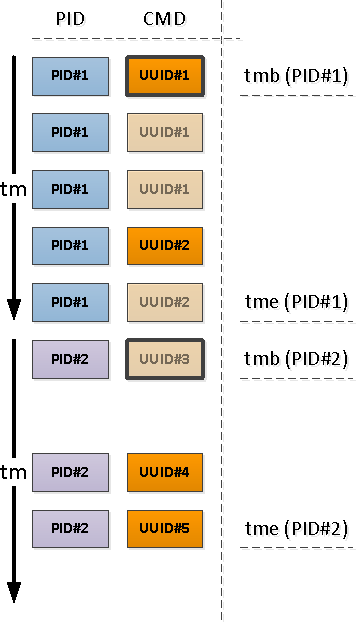
Para fazer isso, usaremos a exclusividade por meio de
DISTINCT ONfunções de janela:
--
, pidtm AS (
SELECT DISTINCT ON(pid)
host
, pid
, cmd
, min(tm) OVER(w) tmb --
, max(tm) OVER(w) tme --
FROM
src
WINDOW
w AS(PARTITION BY pid)
ORDER BY
pid
, tm
)
Limites de atividade do processo
Observe que em relação ao início do nosso intervalo, o primeiro registro que surge pode ser aquele que já tem um campo CMD preenchido (PID # 1 na imagem acima), ou com NULL, indicando a continuação do valor "acima" preenchido na cronologia (PID # 2 )
Aqueles dos PIDs que ficaram sem CMD como resultado da operação anterior começaram antes do início do nosso intervalo, o que significa que esses "inícios" precisam ser encontrados:

pois sabemos com certeza que o próximo segmento de atividade começa com um valor CMD preenchido (e há um RSS preenchido, o que significa ), o índice condicional nos ajudará aqui:
CREATE INDEX ON pidstat(host, pid, tm DESC) WHERE cmd IS NOT NULL;-- ""
, precmd AS (
SELECT
t.host
, t.pid
, c.tm
, c.rss
, c.cmd
FROM
pidtm t
, LATERAL(
SELECT
*
FROM
pidstat -- , SELF JOIN
WHERE
(host, pid) = (t.host, t.pid) AND
tm < t.tmb AND
cmd IS NOT NULL --
ORDER BY
tm DESC
LIMIT 1
) c
WHERE
t.cmd IS NULL -- ""
)
Se quisermos (e quisermos) saber a hora de término da atividade do segmento, então para cada PID teremos que usar uma "mão dupla" para determinar o limite inferior.
Já usamos uma técnica semelhante nos Antipadrões do PostgreSQL: Navegando no Registro .

--
, pstcmd AS (
SELECT
host
, pid
, c.tm
, NULL::bigint rss
, NULL::uuid cmd
FROM
pidtm t
, LATERAL(
SELECT
tm
FROM
pidstat
WHERE
(host, pid) = (t.host, t.pid) AND
tm > t.tme AND
tm < coalesce((
SELECT
tm
FROM
pidstat
WHERE
(host, pid) = (t.host, t.pid) AND
tm > t.tme AND
cmd IS NOT NULL
ORDER BY
tm
LIMIT 1
), x'7fffffff'::integer) -- MAX_INT4
ORDER BY
tm DESC
LIMIT 1
) c
)
Conversão JSON de formatos de postagem
Observe que selecionamos
precmd/pstcmdapenas os campos que afetam as linhas subsequentes e qualquer CPU / DSK que está mudando constantemente - não Portanto, o formato dos registros na tabela original e esses CTEs são diferentes para nós. Sem problemas!
- row_to_json - transforma cada registro com campos em um objeto json
- array_agg - coleta todas as entradas em '{...}' :: json []
- array_to_json - converte array-from-JSON em array JSON '[...]' :: json
- json_populate_recordset - gera uma seleção de uma determinada estrutura de uma matriz JSON
Aqui usamos uma única chamada emColamos os "começos" e "fins" encontrados em uma pilha comum e adicionamos ao conjunto original de registros:json_populate_recordsetvez de múltiplajson_populate_record, porque é banal e muito mais rápido.
--
, uni AS (
TABLE src
UNION ALL
SELECT
*
FROM
json_populate_recordset( --
NULL::pidstat
, (
SELECT
array_to_json(array_agg(row_to_json(t))) --
FROM
(
TABLE precmd
UNION ALL
TABLE pstcmd
) t
)
)
)
Preenchendo lacunas nulas
Vamos usar o modelo discutido no artigo "SQL HowTo: Build Chains with Window Functions" .Primeiro, vamos selecionar os grupos "repetir":
--
, grp AS (
SELECT
*
, count(*) FILTER(WHERE cmd IS NOT NULL) OVER(w) grp -- CMD
, count(*) FILTER(WHERE rss IS NOT NULL) OVER(w) grpm -- RSS
FROM
uni
WINDOW
w AS(PARTITION BY pid ORDER BY tm)
)
Além disso, de acordo com o CMD e o RSS, os grupos serão independentes uns dos outros, por isso podem ter a seguinte aparência:
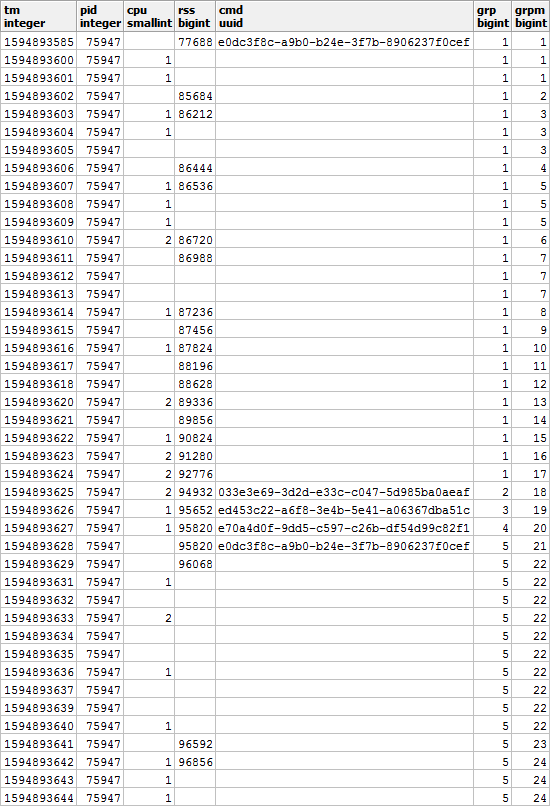
Preencha as lacunas no RSS e calcule a duração de cada segmento para levar em conta corretamente a distribuição da carga ao longo do tempo:
--
, rst AS (
SELECT
*
, CASE
WHEN least(coalesce(lead(tm) OVER(w) - 1, tm), ((TABLE args) ->> 'dte')::integer - 1) >= greatest(tm, ((TABLE args) ->> 'dtb')::integer) THEN
least(coalesce(lead(tm) OVER(w) - 1, tm), ((TABLE args) ->> 'dte')::integer - 1) - greatest(tm, ((TABLE args) ->> 'dtb')::integer) + 1
END gln --
, first_value(rss) OVER(PARTITION BY pid, grpm ORDER BY tm) _rss -- RSS
FROM
grp
WINDOW
w AS(PARTITION BY pid, grp ORDER BY tm)
)
Multi-agrupamento com GROUPING SETS
Como queremos ver como resultado as informações resumidas de todo o processo e seu detalhamento por diferentes segmentos de atividade, usaremos o agrupamento por vários conjuntos de chaves de uma vez usando GROUPING SETS :
--
, gs AS (
SELECT
pid
, grp
, max(grp) qty -- PID
, (array_agg(cmd ORDER BY tm) FILTER(WHERE cmd IS NOT NULL))[1] cmd -- " "
, sum(cpu) cpu
, avg(_rss)::bigint rss
, min(tm) tmb
, max(tm) tme
, sum(gln) gln
FROM
rst
GROUP BY
GROUPING SETS((pid, grp), pid)
)
O caso de uso (array_agg(... ORDER BY ..) FILTER(WHERE ...))[1]nos permite obter o primeiro valor não vazio (mesmo que não seja o primeiro) de todo o conjunto diretamente durante o agrupamento, sem gestos adicionais .A opção de obter várias seções da amostra alvo ao mesmo tempo é muito conveniente para gerar vários relatórios com detalhamento, de forma que todos os dados detalhados não precisem ser reconstruídos, mas sim que apareçam na UI junto com a amostra principal.
Dicionário em vez de JOIN
Crie um "dicionário" CMD para todos os segmentos encontrados:
Você pode ler mais sobre a técnica de "masterização" no artigo "Antipadrões do PostgreSQL: Vamos fazer um JOIN pesado com um dicionário" .
-- CMD
, cmdhs AS (
SELECT
json_object(
array_agg(cmd)::text[]
, array_agg(data)
)
FROM
diccmd
WHERE
cmd = ANY(ARRAY(
SELECT DISTINCT
cmd
FROM
gs
WHERE
cmd IS NOT NULL
))
)
E agora nós o usamos
JOIN, obtendo os dados "bonitos" finais:
SELECT
pid
, grp
, CASE
WHEN grp IS NOT NULL THEN -- ""
cmd
END cmd
, (nullif(cpu::numeric / gln, 0))::numeric(32,2) cpu -- CPU ""
, nullif(rss, 0) rss
, tmb --
, tme --
, gln --
, CASE
WHEN grp IS NULL THEN --
qty
END cnt
, CASE
WHEN grp IS NOT NULL THEN
(TABLE cmdhs) ->> cmd::text --
END command
FROM
gs
WHERE
grp IS NOT NULL OR -- ""
qty > 1 --
ORDER BY
pid DESC
, grp NULLS FIRST;
Finalmente, vamos ter certeza de que toda a nossa consulta se tornou bastante leve quando executada:

[veja explain.tensor.ru]
Apenas 44ms e 33 MB de dados foram lidos!