
Do ponto de vista arquitetônico, a plataforma IoT requer que as seguintes tarefas sejam resolvidas:
- A quantidade de dados recebidos, recebidos e processados requer alta largura de banda, armazenamento e capacidade de computação.
- Os dispositivos podem ser distribuídos em uma ampla área geográfica
- As empresas exigem que sua arquitetura esteja em constante evolução para que novos serviços possam ser oferecidos aos clientes.
Uma das características da plataforma IoT é a independência entre objetos e sinais, o que permite cálculos paralelos, aumentando a produtividade.
Os dados dos sensores são coletados de fontes: PLC, DCS, microcontroladores, etc. e podem ser armazenados no domínio do tempo para evitar perda de dados devido a problemas de conexão. Os dados podem ser séries temporais (eventos), dados semiestruturados (logs e binários) ou dados não estruturados (imagens). Os dados e eventos da série temporal são coletados com frequência (a cada segundo a vários minutos). Eles são então enviados pela rede e armazenados em um data lake centralizado e em um banco de dados de série temporal TSDB. O data lake pode ser baseado em nuvem, data center local ou armazenamento de terceiros.
Os dados podem ser processados imediatamente usando uma análise de fluxo de dados chamada "caminho ativo" com um mecanismo de verificação de regra baseado em setpoint simples ou inteligente. A análise avançada pode incluir gêmeos digitais, aprendizado de máquina, aprendizado profundo ou análises baseadas em física. Esse sistema pode processar uma grande quantidade de dados (de dez minutos a um mês) de diferentes sensores. Esses dados são armazenados em armazenamento intermediário. Essa análise é chamada de "caminho frio" e geralmente é iniciada pelo planejador ou quando os dados estão disponíveis e exigem muitos recursos de computação. A análise avançada geralmente precisa de informações adicionais, como o modelo do veículo monitorado e atributos operacionais, que podem ser encontrados no registro de ativos.O registro de ativos contém informações sobre o tipo de ativo, incluindo seu nome, número de série, nome simbólico, localização, capacidades operacionais, o histórico das peças em que consiste e a função que desempenha no processo de fabricação. No registro de ativos, podemos armazenar uma lista das dimensões de cada ativo, nome lógico, unidade de medida e intervalo de limites. No setor industrial, essa informação estática é essencial para um modelo analítico correto.No setor industrial, essa informação estática é essencial para um modelo analítico correto.No setor industrial, essa informação estática é essencial para um modelo analítico correto.
Razões para desenvolver uma plataforma personalizada:
- Retorno sobre o investimento: pequeno orçamento;
- Tecnologia: uso de tecnologia independente do fornecedor;
- Confidencialidade de dados;
- Integração: a necessidade de desenvolver um nível de integração com uma plataforma nova ou desatualizada;
- Outras restrições.
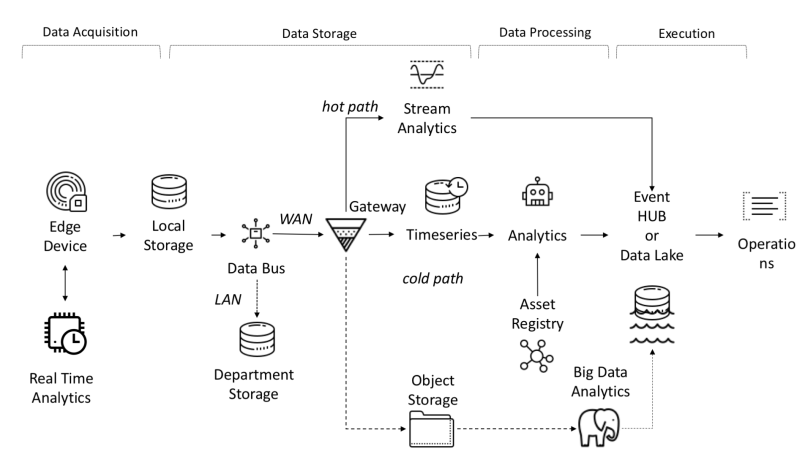
Fluxo de dados ponta a ponta no I-IoT
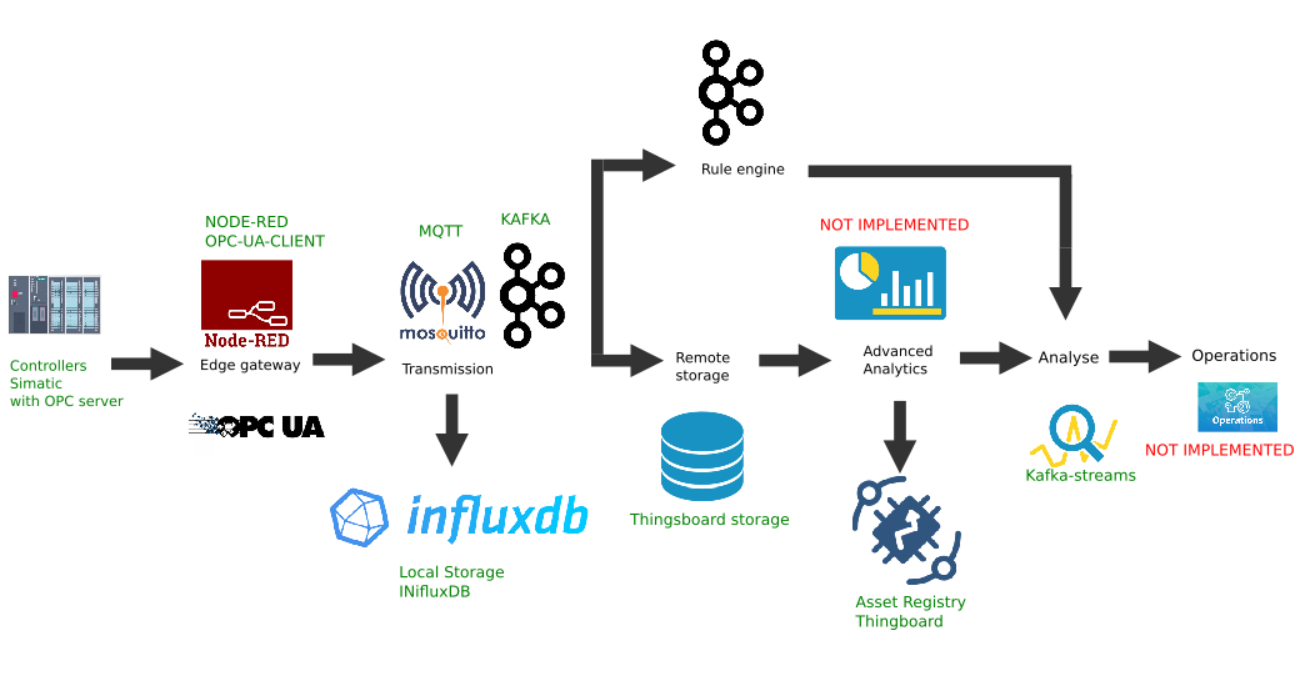
Exemplo de implementação personalizada da plataforma Edge
Esta figura mostra a implementação dos seguintes links de plataforma:
- Fonte de dados: como exemplo, um simulador de controlador Simatic PLCSIM Advanced com um servidor OPC ativado é selecionado, conforme descrito no artigo anterior;
- A popular plataforma Node-Red com o plugin node-red-contrib-opcua instalado foi escolhida como o gateway de borda ;
- O broker MQTT Mosquitto é usado como um dispatcher para transferência de dados entre outros links no fluxo;
- Apache Kafka é usado como uma plataforma de streaming distribuída que serve como analítica de hot path usando kafka-streams.
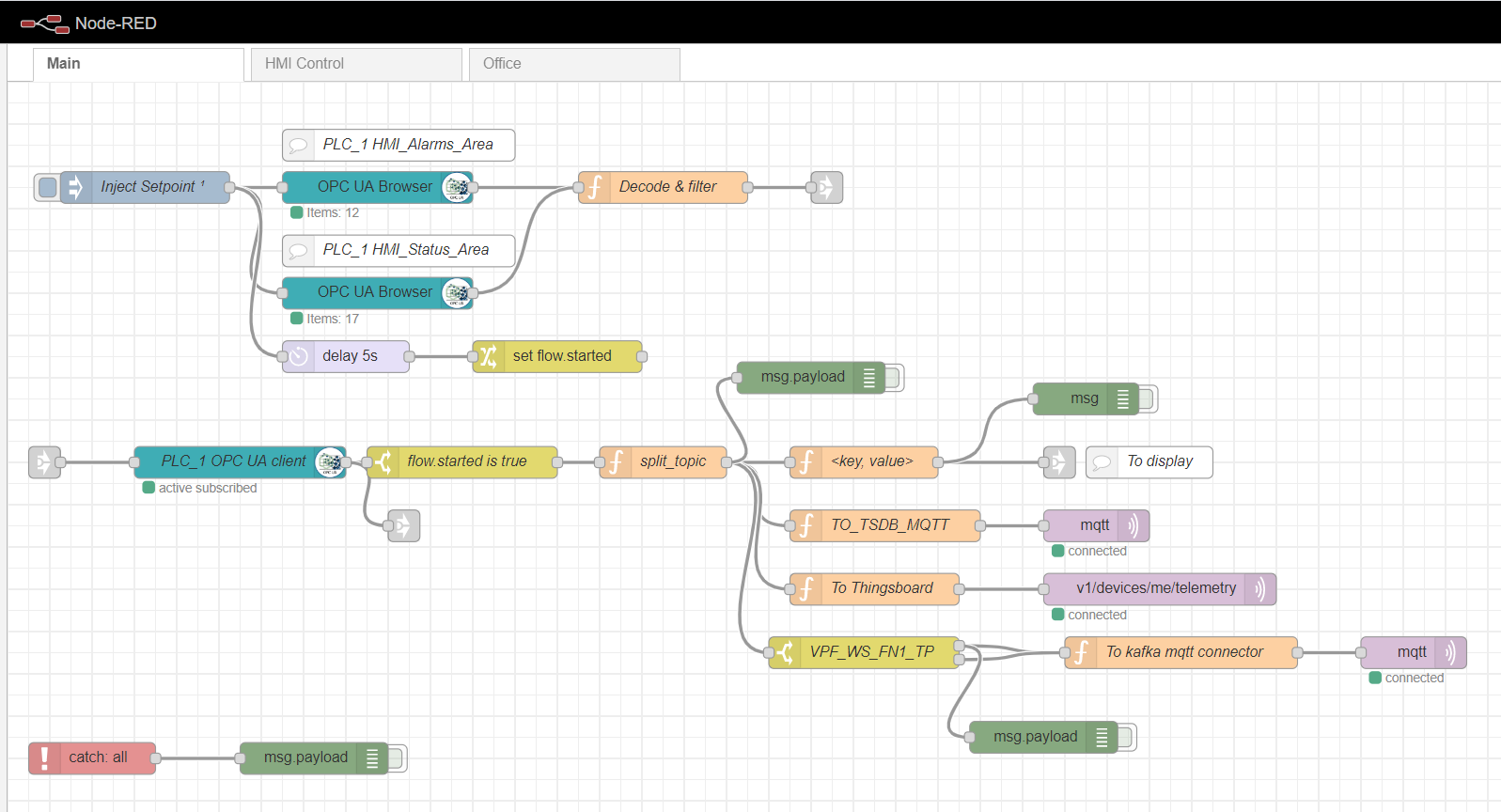
Gateway Node-red Edge
Como um gateway de computação de ponta, usaremos o Node-red, uma plataforma customizada simples que possui muitos plug-ins diferentes. O papel do adaptador industrial é desempenhado pelo plugin node-red-contrib-opcua. Para coleta múltipla de dados do controlador pelo método de assinatura, os nós são usados: OpcUa-Browser e OpcUa-client. No nó do navegador OPC, são configurados a url do servidor OPC (endpoint) e o tópico, que especifica o namespace e o nome do bloco de dados legível, por exemplo: ns = 3; s = "HMI_Alarms_Area". No nó cliente OPC, o url do OPC Server também é especificado, o SUBSCRIBE e o intervalo de atualização de dados são definidos como a Ação.
Fluxo principal de nó vermelho
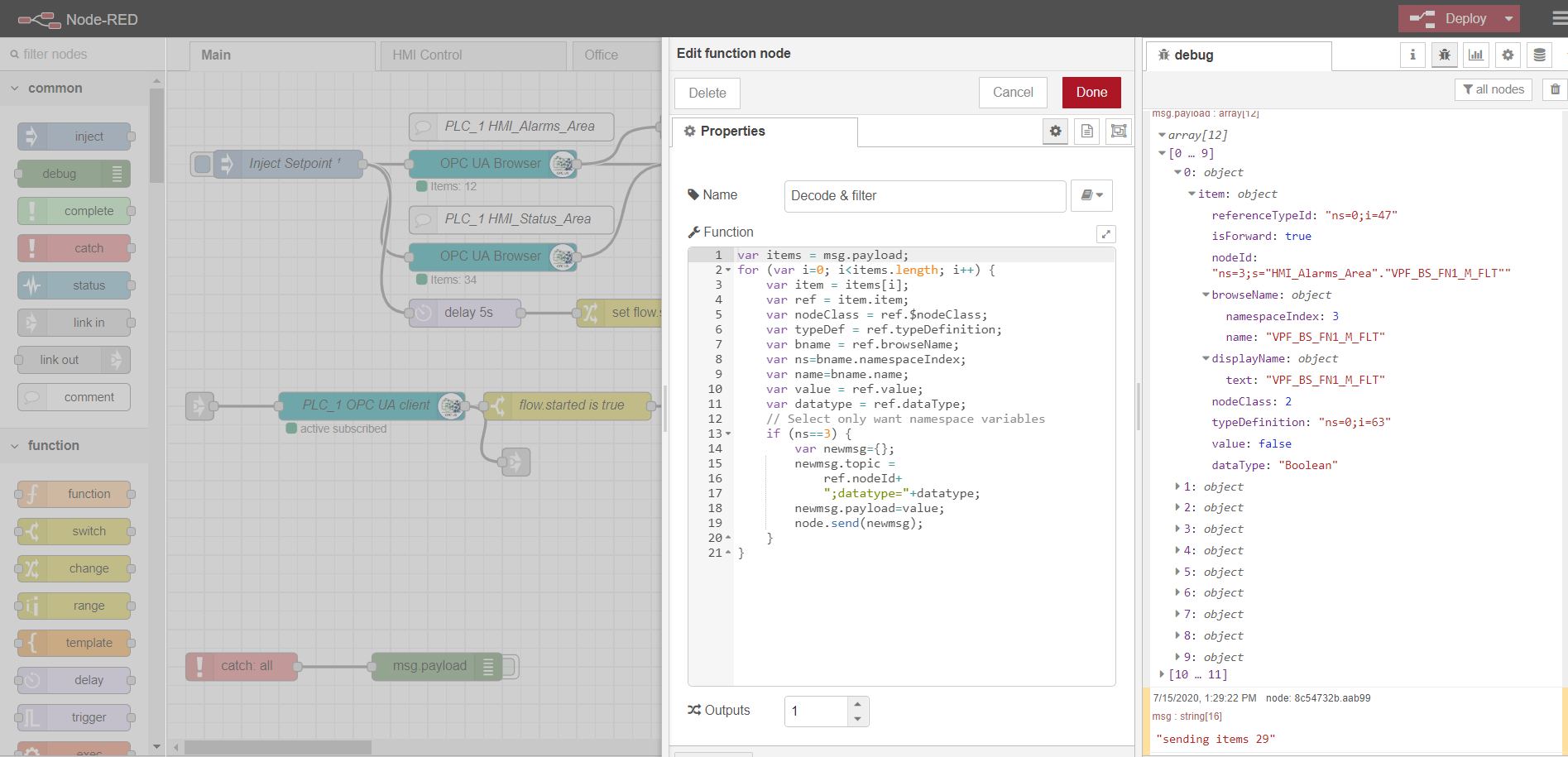
Configurando o nó do navegador OPC

OPC-client

Para assinar a leitura de múltiplos dados, é necessário preparar e baixar tags do controlador, de acordo com o protocolo OPC. Para fazer isso, primeiro, um nó de injeção é usado com a caixa de seleção apenas uma vez, que dispara uma leitura única de blocos de dados especificados nos nós do navegador OPC. Os dados são então processados pela função Decodificar e filtrar. Depois disso, o nó cliente OPC assina e lê os dados de alteração do controlador. O processamento adicional do fluxo depende da implementação e dos requisitos específicos. Em meu exemplo, eu processo os dados para enviá-los posteriormente ao broker MQTT para diferentes tópicos.
As guias HMI control e Office são uma implementação HMI simples baseada em Scadavis.io e um painel de controle de nó vermelho, conforme descrito anteriormente no artigo .
Um exemplo de análise de dados de um nó do navegador OPC:
var items = msg.payload;
for (var i=0; i<items.length; i++) {
var item = items[i];
var ref = item.item;
var nodeClass = ref.$nodeClass;
var typeDef = ref.typeDefinition;
var bname = ref.browseName;
var ns=bname.namespaceIndex;
var name=bname.name;
var value = ref.value;
var datatype = ref.dataType;
// Select only want namespace variables
if (ns==3) {
var newmsg={};
newmsg.topic =
ref.nodeId+
";datatype="+datatype;
newmsg.payload=value;
node.send(newmsg);
}
}
Corretor MQTT
Qualquer implementação pode ser usada como um corretor. No meu caso, o broker Mosquitto já está instalado e configurado . O corretor executa a função de transporte de dados entre o gateway do Edge e outros participantes da plataforma. Existem exemplos com balanceamento de carga e arquitetura distribuída ( como aqui ). Nesse caso, nos restringiremos a um corretor mqtt com transferência de dados sem criptografia.
Armazenamento local de dados de série temporal
É conveniente registrar e armazenar dados de série temporal no banco de dados de série temporal NoSql. A pilha InfluxData funciona bem para nossos propósitos . Precisamos de quatro serviços desta pilha:
InfluxDB é um banco de dados de série temporal de código aberto que faz parte da pilha TICK (Telegraf, InfluxDB, Chronograf, Kapacitor). Projetado para processamento de dados de alta carga e fornece linguagem de consulta semelhante a SQL InfluxQL para interagir com os dados.
Telegraf é um agente para coletar e enviar métricas e eventos para o InfluxDB de sistemas IoT externos, sensores, etc. Ele é configurado para coletar dados de tópicos mqtt.
Kapacitor é um mecanismo de dados embutido para InfluxDB 1.xe um componente integrado na plataforma InfluxDB. Este serviço pode ser configurado para monitorar vários setpoints e alarmes, bem como instalar um manipulador para envio de eventos para sistemas externos como Kafka, e-mail, etc.
Chronograf é a interface do usuário e o componente administrativo da plataforma InfluxDB. Usado para criar rapidamente painéis de controle com visualização em tempo real.
Todos os componentes da pilha podem ser executados localmente ou configurar um contêiner do Docker.
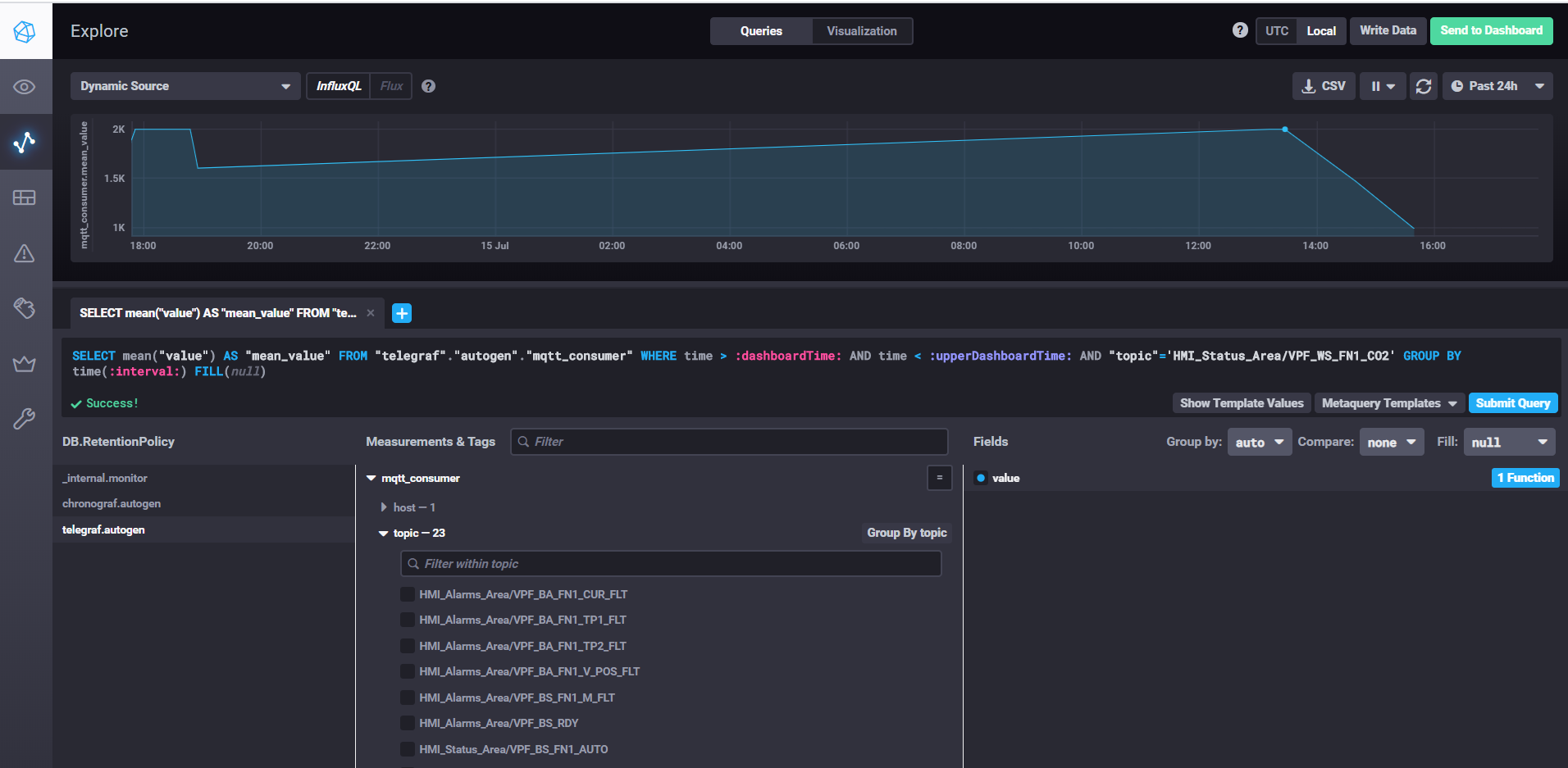
Buscando dados e personalizando painéis com Chronograf
Para iniciar o InfluxDB, basta executar o comando influxd, nas configurações influxdb.conf você pode especificar o local de armazenamento e outras propriedades, por padrão os dados são armazenados no diretório do usuário no diretório .influxdb.
Para iniciar o telegraf, você precisa executar o comando telegraf -config telegraf.conf, onde você pode especificar as fontes de métricas e eventos nas configurações, em nosso exemplo para mqtt é assim:
# # Read metrics from MQTT topic(s)
[[inputs.mqtt_consumer]]
servers = ["tcp://192.168.1.107:1883"]
qos = 0
topics = ["HMI_Status_Area/#", "HMI_Alarms_Area/#"]
data_format = "value"
data_type = "float"
Na propriedade dos servidores, especificamos o url para o corretor mqtt, qos pode deixar 0 se for o suficiente para gravar dados sem confirmação. Na propriedade de tópicos, especifique as máscaras mqtt de tópicos dos quais leremos os dados. Por exemplo, HMI_Status_Area / # significa que lemos todos os tópicos que possuem o prefixo HMI_Status_Area. Assim, o telegraf para cada tópico criará sua própria métrica no banco de dados, onde gravará os dados.
Para iniciar o kapacitor, você precisa executar o comando kapacitord -config kapacitor.conf. As propriedades podem ser deixadas como padrão e outras configurações podem ser feitas com o cronógrafo.
Para iniciar o cronógrafo, basta executar o comando cronograf de mesmo nome. A interface da web estará disponível localhost : 8888 /
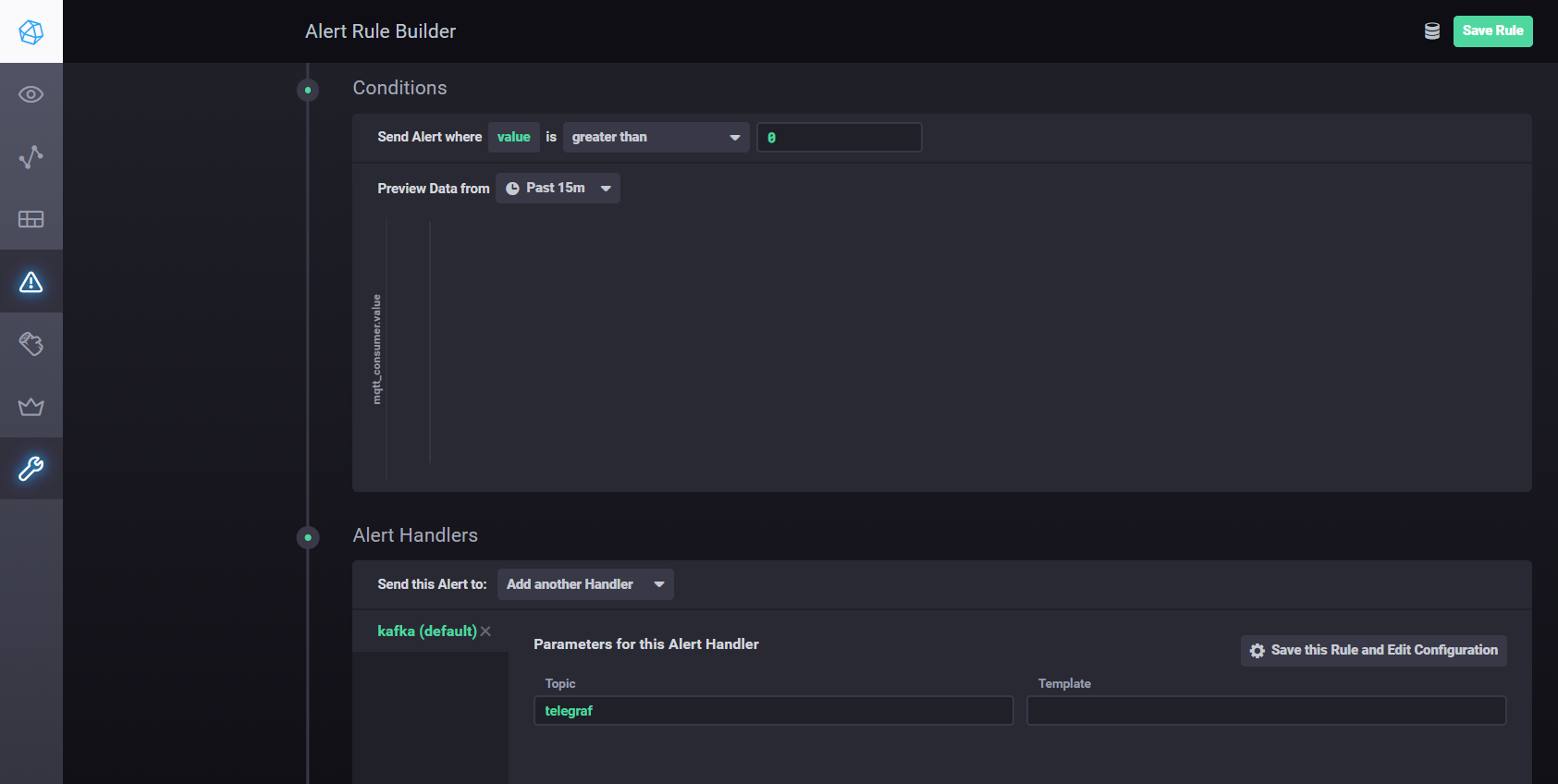
Para definir as configurações e alarmes usando Kapacitor, você pode usarmanual . Resumindo - você precisa ir até a aba Alerting no Chronograf e criar uma nova regra usando o botão Build Alert Rule, a interface é intuitiva, tudo é feito visualmente. Para configurar o envio de resultados de processamento para kafka, etc. você precisa adicionar um manipulador na seção Condições
Configurações do manipulador Kapacitor
Streaming Distribuído com Apache Kafka
Para a arquitetura proposta, é necessário separar a coleta de dados do processamento, melhorando a escalabilidade e a independência das camadas. Podemos usar uma fila para atingir esse objetivo. A implementação pode ser Java Message Service (JMS) ou Advanced Message Queuing Protocol (AMQP), mas neste caso usaremos Apache Kafka. O Kafka é compatível com a maioria das plataformas analíticas, tem alto desempenho e escalabilidade e uma boa biblioteca de fluxos Kafka.
Você pode usar o plugin Node-red node-red-contrib-kafka-manager para interagir com Kafka . Mas, levando em consideração a separação entre coleta e processamento de dados, instalaremos o plugin MQTT, que se inscreve nos tópicos do Mosquitto. O plugin MQTT está disponível aqui .
Para configurar o conector, copie as bibliotecas kafka-connect-mqtt-1.1-SNAPSHOT.jar e org.eclipse.paho.client.mqttv3-1.0.2.jar (ou outra versão) para o diretório kafka / libs /. Em seguida, no diretório / config, você precisa criar um arquivo de propriedades mqtt.properties com o seguinte conteúdo:
name=mqtt
connector.class=com.evokly.kafka.connect.mqtt.MqttSourceConnector
tasks.max=1
kafka.topic=streams-measures
mqtt.client_id=mqtt-kafka-123456789
mqtt.clean_session=true
mqtt.connection_timeout=30
mqtt.keep_alive_interval=60
mqtt.server_uris=tcp://192.168.1.107:1883
mqtt.topic=mqtt
Tendo lançado anteriormente o zookeeper-server e o kafka-server, podemos iniciar o conector usando o comando:
connect-standalone.bat …\config\connect-standalone.properties …\config\mqtt.properties
A partir do tópico mqtt (mqtt.topic = mqtt), os dados serão gravados no tópico streams-mede Kafka (kafka.topic = streams-mede).
Como um exemplo simples, você pode criar um projeto maven usando a biblioteca kafka-streams.
Usando kafka-streams, você pode implementar vários serviços e cenários para análise dinâmica e processamento de dados de streaming.
Um exemplo de comparação da temperatura atual com o setpoint do período.
StreamsBuilder builder = new StreamsBuilder();
KStream<String, String> source = builder.stream("streams-measures");
KStream<Windowed<String>, String> max = source
.selectKey((String key, String value) -> {
return getKey(key, value);
}
)
.groupByKey()
.windowedBy(TimeWindows.of(Duration.ofSeconds(WINDOW_SIZE)))
.reduce((String value1, String value2) -> {
double v1=getValue(value1);
double v2=getValue(value2);
if ( v1 > v2)
return value1;
else
return value2;
}
)
.toStream()
.filter((Windowed<String> key, String value) -> {
String measure = tagMapping.get(key.key());
double parsedValue = getValue(value);
if (measure!=null) {
Double threshold = excursion.get(measure);
if (threshold!=null) {
if(parsedValue > threshold) {
log.info(String.format("%s : %s; Threshold: %s", key.key(), parsedValue, threshold));
return true;
}
return false;
}
} else {
log.severe("UNKNOWN MEASURE! Did you mapped? : " + key.key());
}
return false;
}
);
final Serde<String> STRING_SERDE = Serdes.String();
final Serde<Windowed<String>> windowedSerde = Serdes.serdeFrom(
new TimeWindowedSerializer<>(STRING_SERDE.serializer()),
new TimeWindowedDeserializer<>(STRING_SERDE.deserializer(), TimeWindows.of(Duration.ofSeconds(WINDOW_SIZE)).size()));
// the output
max.to("excursion", Produced.with(windowedSerde, Serdes.String()));
Registro de ativos
O registro de ativos, na verdade, não é um componente estrutural da plataforma Edge e faz parte do ambiente de IoT em nuvem. Mas este exemplo mostra como Edge e Cloud interagem.
Como registro de ativos, usaremos a popular plataforma ThingsBoard IoT, cuja interface também é bastante intuitiva. A instalação é possível com dados de demonstração. A plataforma pode ser instalada localmente, no docker ou usando um ambiente de nuvem pronto .
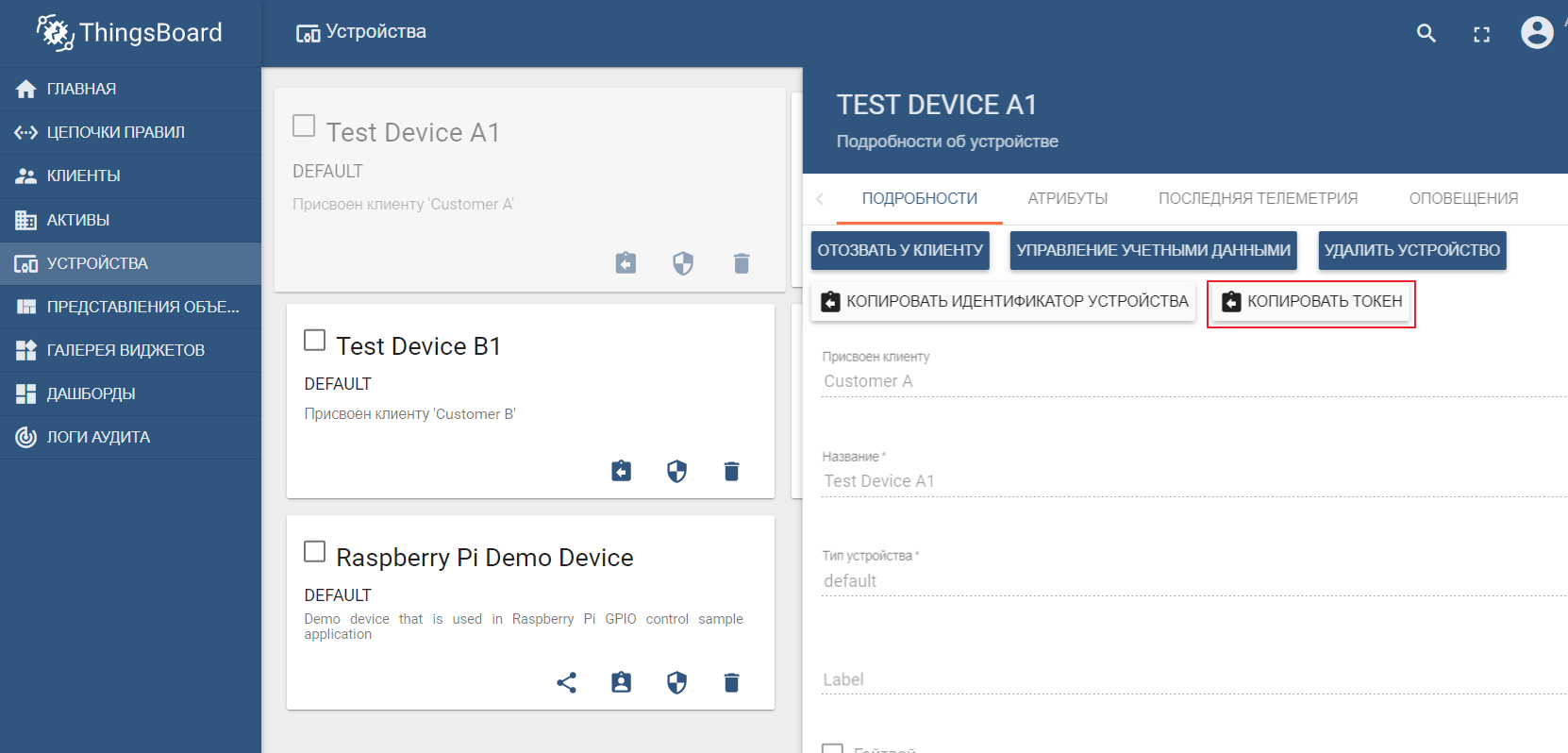
O conjunto de dados de demonstração inclui dispositivos de teste (você pode facilmente criar um novo) para os quais você pode enviar valores. Por padrão, o ThingsBoard começa com seu próprio corretor mqtt, ao qual você precisa se conectar e enviar dadosno formato json. Digamos que desejamos enviar dados para o ThingsBoard do TEST DEVICE A1. Para fazer isso, precisamos nos conectar ao corretor ThingBoard em localhost: 1883 usando A1_TEST_TOKEN como um login, que pode ser copiado das configurações do dispositivo. Em seguida, podemos publicar os dados no tópico v1 / devices / me / telemetry: {“temperatura”: 26}
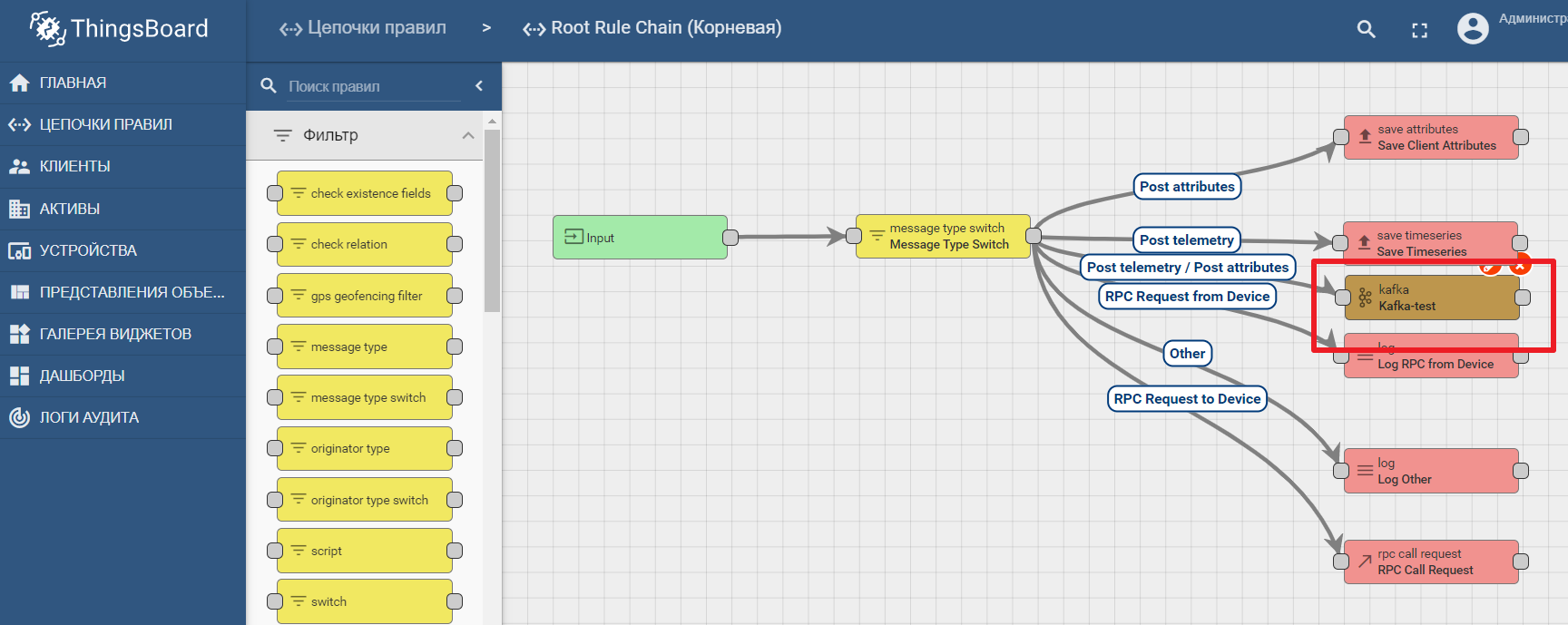
A documentação da plataforma contém um manual para configurar transferência de dados e análise de processamento em Kafka - análise de dados IoT usando Kafka, Kafka Streams e ThingsBoard
Um exemplo de uso de um nó kafka no Thingsboard
Conclusão
Modernas tecnologias de TI e protocolos abertos permitem projetar sistemas de qualquer complexidade. A plataforma de ponta é o ponto de conexão entre o ambiente industrial e a plataforma IoT baseada em nuvem. Ele pode ser decomposto em macrocomponentes, entre os quais o gateway de borda desempenha um papel fundamental, responsável por encaminhar os dados dos dispositivos para o hub de dados IoT. Ferramentas abertas de streaming de dados permitem análises eficientes e computação de ponta.