Neste artigo, você aprenderá
- O que é CNN e como funciona
- O que é um mapa de recursos
- O que é pooling máximo
- Funções de perda para várias tarefas de aprendizagem profunda
Pequena introdução
Esta série de artigos tem como objetivo fornecer uma compreensão intuitiva de como funciona o aprendizado profundo, quais são as tarefas, arquiteturas de rede, por que uma é melhor que a outra. Haverá poucas coisas específicas no espírito de "como implementá-lo". Entrar em cada detalhe torna o material muito complexo para a maioria do público. Já foi escrito sobre como funciona o gráfico de computação ou como funciona a retropropagação através de camadas convolucionais. E, o mais importante, está escrito muito melhor do que eu explicaria.
No artigo anterior, discutimos FCNN - o que é e quais são os problemas. A solução para esses problemas está na arquitetura de redes neurais convolucionais.
Redes Neurais Convolucionais (CNN)
Rede neural convolucional. É parecido com isto (arquitetura vgg-16):
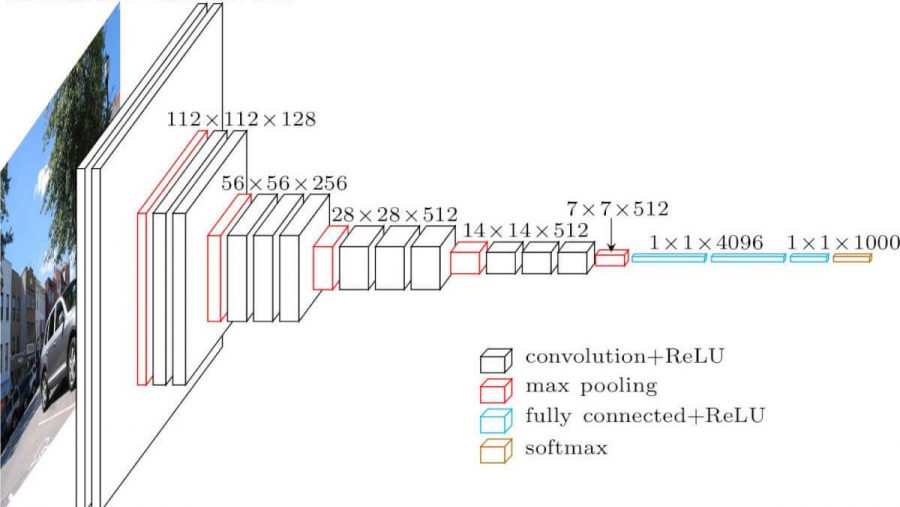
Quais são as diferenças de uma rede totalmente em malha? As camadas ocultas agora têm uma operação de convolução.
É assim que a convolução se parece:

Nós apenas pegamos uma imagem (por enquanto - canal único), pegamos um kernel de convolução (matriz), consistindo em nossos parâmetros de treinamento, "sobrepomos" o kernel (geralmente 3x3) na imagem, realizamos a multiplicação por elemento de todos os valores de pixel da imagem que atingiu o kernel. Então, tudo isso é resumido (você também precisa adicionar o parâmetro de polarização - deslocamento) e obteremos alguns números. Este número é o elemento da camada de saída. Movemos esse núcleo ao longo de nossa imagem com algum passo (passo largo) e obtemos os próximos elementos. Uma nova matriz é construída a partir de tais elementos, e o próximo kernel de convolução é aplicado a ela (após aplicar a função de ativação a ela). No caso em que a imagem de entrada é de três canais, o kernel de convolução também é de três canais - um filtro.
Mas nem tudo é tão simples aqui. Essas matrizes que obtemos após a convolução são chamadas de mapas de características, porque armazenam algumas características das matrizes anteriores, mas em alguma outra forma. Na prática, vários filtros de convolução são usados ao mesmo tempo. Isso é feito para "trazer" o máximo de recursos possível para a próxima camada de convolução. A cada camada da convolução, nossos recursos, que estavam na imagem de entrada, são apresentados cada vez mais em formas abstratas.
Mais algumas notas:
- Após dobrar, nosso mapa de recursos fica menor (em largura e altura). Às vezes, para reduzir a largura e a altura mais fracas, ou para não reduzi-la de todo (mesma convolução), use o método de preenchimento de zero - preenchendo com zeros "ao longo do contorno" do mapa de recursos de entrada.
- Após a camada convolucional mais recente, as tarefas de classificação e regressão usam várias camadas totalmente conectadas.
Por que é melhor do que FCNN
- Agora podemos ter menos parâmetros treináveis entre as camadas
- Agora, quando extraímos características da imagem, levamos em consideração não apenas um único pixel, mas também pixels próximos a ele (identificando certos padrões na imagem)
Pooling máximo
Ele se parece com isto:
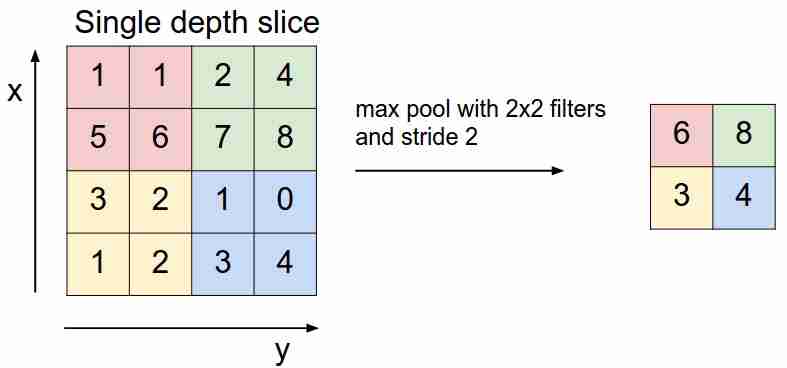
Nós "deslizamos" sobre nosso mapa de recursos com um filtro e selecionamos apenas os recursos mais importantes (em termos do sinal de entrada, como algum valor), diminuindo a dimensão do mapa de recursos. Também existe o agrupamento médio (ponderado), quando calculamos a média dos valores que caem no filtro, mas na prática é o agrupamento máximo que é mais aplicável.
- Esta camada não tem parâmetros treináveis
Funções de perda
Alimentamos a rede X para a entrada, alcançamos a saída, calculamos o valor da função de perda, executamos o algoritmo de retropropagação - é assim que as redes neurais modernas aprendem (por enquanto, estamos falando apenas de aprendizagem supervisionada).
Diferentes funções de perda são usadas dependendo das tarefas que as redes neurais resolvem:
- Problema de regressão . Geralmente, eles usam a função do erro quadrático médio (MSE).
- Problema de classificação . Eles usam principalmente a perda de entropia cruzada.
Não consideramos outras tarefas ainda - isso será discutido nos próximos artigos. Por que exatamente tais funções para tais tarefas? Aqui você precisa inserir a estimativa de máxima verossimilhança e matemática. Quem se importa - eu escrevi sobre isso aqui .
Conclusão
Também quero chamar sua atenção para duas coisas usadas em arquiteturas de rede neural, incluindo as convolucionais - dropout (você pode ler aqui ) e normalização em lote . Eu recomendo fortemente a leitura.
No próximo artigo analisaremos as arquiteturas CNN, entenderemos porque uma é melhor que a outra.