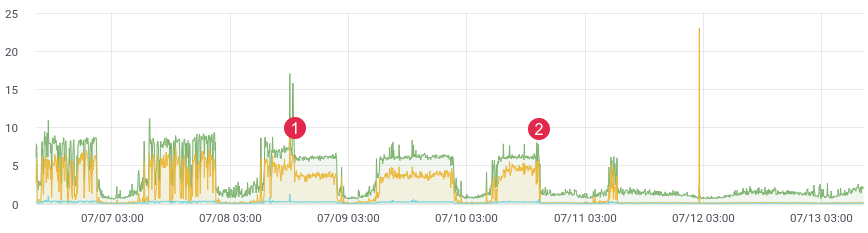
Aproximadamente. latência / tempo.
Provavelmente, todos enfrentam a tarefa de criar perfis de código na produção. O xhprof do Facebook faz isso bem. Você perfila, por exemplo, 1/1000 solicitações e vê a foto no momento. Após cada lançamento, o produto vem rodando e diz "era melhor e mais rápido antes do lançamento". Você não tem dados históricos e não pode provar nada. E se você pudesse?
Não faz muito tempo, reescrevemos uma parte problemática do código e esperávamos um forte ganho de desempenho. Nós escrevemos testes de unidade, fizemos testes de carga, mas como o código se comportará sob carga ativa? Afinal, sabemos que o teste de carga nem sempre exibe dados reais e, após a implantação, você precisa obter feedback rapidamente de seu código. Se você está coletando dados, então, após o lançamento, 10-15 minutos são suficientes para você entender a situação no ambiente de combate.
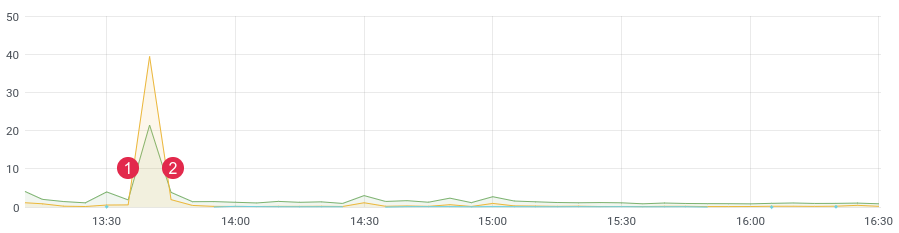
Aproximadamente. latência / tempo. (1) implantação, (2) reversão
Pilha
Para nossa tarefa, pegamos um banco de dados ClickHouse colunar (abreviado como kx). Velocidade, escalabilidade linear, compressão de dados e nenhum deadlock foram os principais motivos para essa escolha. Agora é uma das principais bases do projeto.
Na primeira versão, escrevemos mensagens para a fila e, já pelos consumidores, as escrevemos para ClickHouse. O atraso chegou a 3-4 horas (sim, ClickHouse é lento para inserir um por umregistros). O tempo passou e foi preciso mudar alguma coisa. Não adiantava responder às notificações com tanto atraso. Em seguida, escrevemos um comando de coroa que selecionou o número necessário de mensagens da fila e enviou um lote para o banco de dados, em seguida, marcou o processamento na fila. Nos primeiros meses estava tudo bem, até que os problemas começaram aqui. Havia muitos eventos, dados duplicados começaram a aparecer no banco de dados, as filas não eram usadas para o propósito pretendido (elas se tornaram um banco de dados) e o comando crown não mais lidava com a gravação no ClickHouse. Durante esse tempo, algumas dezenas de tabelas foram adicionadas ao projeto, que tiveram que ser gravadas em lotes em kx. A velocidade de processamento caiu. A solução foi a mais simples e rápida possível. Isso nos levou a escrever código com listas no redis. A ideia é esta: escrevemos mensagens no final da lista,Com o comando coroa, formamos um pacote e enviamos para a fila. Em seguida, os consumidores analisam a fila e gravam um monte de mensagens em kx.
Temos : ClickHouse, Redis e uma fila (qualquer - rabbitmq, kafka, beanstalkd ...)
Redis e listas
Até um certo tempo, o Redis era usado como cache, mas isso está mudando. A base tem uma grande funcionalidade e para nossa tarefa apenas 3 comandos são necessários : rpush , lrange e ltrim .
Usaremos o comando rpush para gravar dados no final da lista. No comando crown, leia os dados usando lrange e envie para a fila, se conseguimos enviar para a fila, então precisamos deletar os dados selecionados usando ltrim.
Da teoria à prática. Vamos criar uma lista simples.

Temos uma lista de três mensagens, vamos adicionar um pouco mais ...
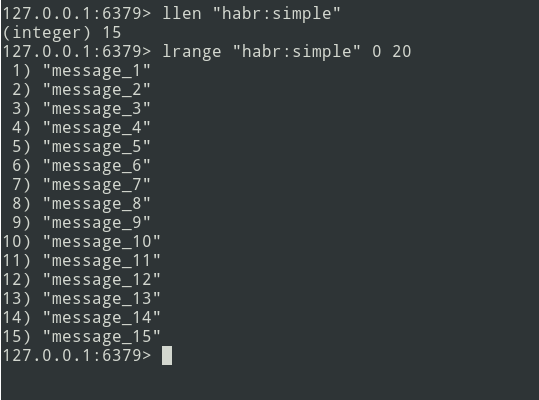
Novas mensagens são adicionadas ao final da lista. Usando o comando lrange, selecione o lote (que seja = 5 mensagens).
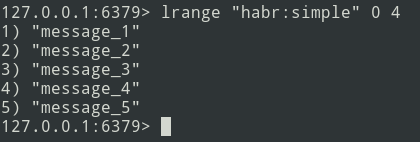
Em seguida, enviamos o pacote para a fila. Agora você precisa remover este pacote do Redis para não enviá-lo novamente.
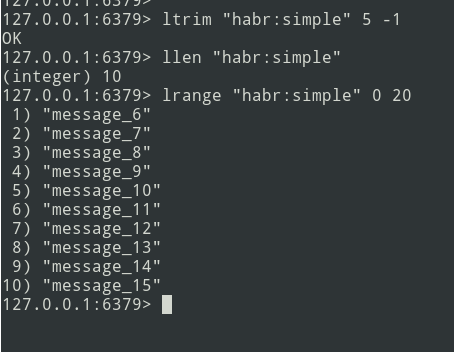
Existe um algoritmo, vamos começar a implementação.
Implementação
Vamos começar com a tabela ClickHouse. Não me preocupei muito e defini tudo no tipo String .
create table profile_logs
(
hostname String, // ,
project String, //
version String, //
userId Nullable(String),
sessionId Nullable(String),
requestId String, //
requestIp String, // ip
eventName String, //
target String, // URL
latency Float32, // (latency=endTime - beginTime)
memoryPeak Int32,
date Date,
created DateTime
)
engine = MergeTree(date, (date, project, eventName), 8192);O evento será assim:
{
"hostname": "debian-fsn1-2",
"project": "habr",
"version": "7.19.1",
"userId": null,
"sessionId": "Vv6ahLm0ZMrpOIMCZeJKEU0CTukTGM3bz0XVrM70",
"requestId": "9c73b19b973ca460",
"requestIp": "46.229.168.146",
"eventName": "app:init",
"target": "/",
"latency": 0.01384348869323730,
"memoryPeak": 2097152,
"date": "2020-07-13",
"created": "2020-07-13 13:59:02"
}A estrutura está definida. Para calcular a latência , precisamos de um período de tempo. Nós beliscamos usando a função microtime :
$beginTime = microtime(true);
//
$latency = microtime(true) - $beginTime;Para simplificar a implementação, usaremos o framework laravel e a biblioteca laravel-entry . Adicione um modelo (tabela profile_logs):
class ProfileLog extends \Bavix\Entry\Models\Entry
{
protected $fillable = [
'hostname',
'project',
'version',
'userId',
'sessionId',
'requestId',
'requestIp',
'eventName',
'target',
'latency',
'memoryPeak',
'date',
'created',
];
protected $casts = [
'date' => 'date:Y-m-d',
'created' => 'datetime:Y-m-d H:i:s',
];
}Vamos escrever um método tick ( criei um serviço ProfileLogService ) que escreverá mensagens no Redis. Pegamos a hora atual (nosso beginTime) e gravamos na variável $ currentTime:
$currentTime = \microtime(true);Se o tick para um evento for chamado pela primeira vez, grave-o na matriz tick e finalize o método:
if (empty($this->ticks[$eventName])) {
$this->ticks[$eventName] = $currentTime;
return;
}Se o tick for chamado novamente, escreveremos a mensagem para o Redis usando o método rpush:
$tickTime = $this->ticks[$eventName];
unset($this->ticks[$eventName]);
Redis::rpush('events:profile_logs', \json_encode([
'hostname' => \gethostname(),
'project' => 'habr',
'version' => \app()->version(),
'userId' => Auth::id(),
'sessionId' => \session()->getId(),
'requestId' => \bin2hex(\random_bytes(8)),
'requestIp' => \request()->getClientIp(),
'eventName' => $eventName,
'target' => \request()->getRequestUri(),
'latency' => $currentTime - $tickTime,
'memoryPeak' => \memory_get_usage(true),
'date' => $tickTime,
'created' => $tickTime,
]));A variável $ this-> ticks não é estática. Você precisa registrar o serviço como um singleton.
$this->app->singleton(ProfileLogService::class);O tamanho do lote ( $ batchSize ) é configurável, é recomendável especificar um valor pequeno (por exemplo, 10.000 itens). Se surgirem problemas (por exemplo, ClickHouse não está disponível), a fila começará a falhar e você precisará depurar os dados.
Vamos escrever um comando de coroa:
$batchSize = 10000;
$key = 'events:profile_logs'
do {
$bulkData = Redis::lrange($key, 0, \max($batchSize - 1, 0));
$count = \count($bulkData);
if ($count) {
// json, decode
foreach ($bulkData as $itemKey => $itemValue) {
$bulkData[$itemKey] = \json_decode($itemValue, true);
}
// ch
\dispatch(new BulkWriter($bulkData));
// redis
Redis::ltrim($key, $count, -1);
}
} while ($count >= $batchSize);Você pode gravar dados imediatamente no ClickHouse, mas o problema reside no fato de que o kronor funciona no modo de thread único. Portanto, iremos por outro caminho - com o comando iremos formar pacotes e enviá-los para a fila para subsequente gravação multithread no ClickHouse. O número de consumidores pode ser regulado - isso vai agilizar o envio de mensagens.
Vamos continuar escrevendo para um consumidor:
class BulkWriter implements ShouldQueue
{
use Dispatchable, InteractsWithQueue, Queueable, SerializesModels;
protected $bulkData;
public function __construct(array $bulkData)
{
$this->bulkData = $bulkData;
}
public function handle(): void
{
ProfileLog::insert($this->bulkData);
}
}
}Assim, desenvolve-se a formação dos packs, o envio para a fila e o consumidor - pode começar a traçar:
app(ProfileLogService::class)->tick('post::paginate');
$posts = Post::query()->paginate();
$response = view('posts', \compact('posts'));
app(ProfileLogService::class)->tick('post::paginate');
return $response;Se tudo for feito corretamente, os dados devem estar no Redis. Iremos confundir o comando coroa e enviar os pacotes para a fila, e o consumidor irá inseri-los no banco de dados.
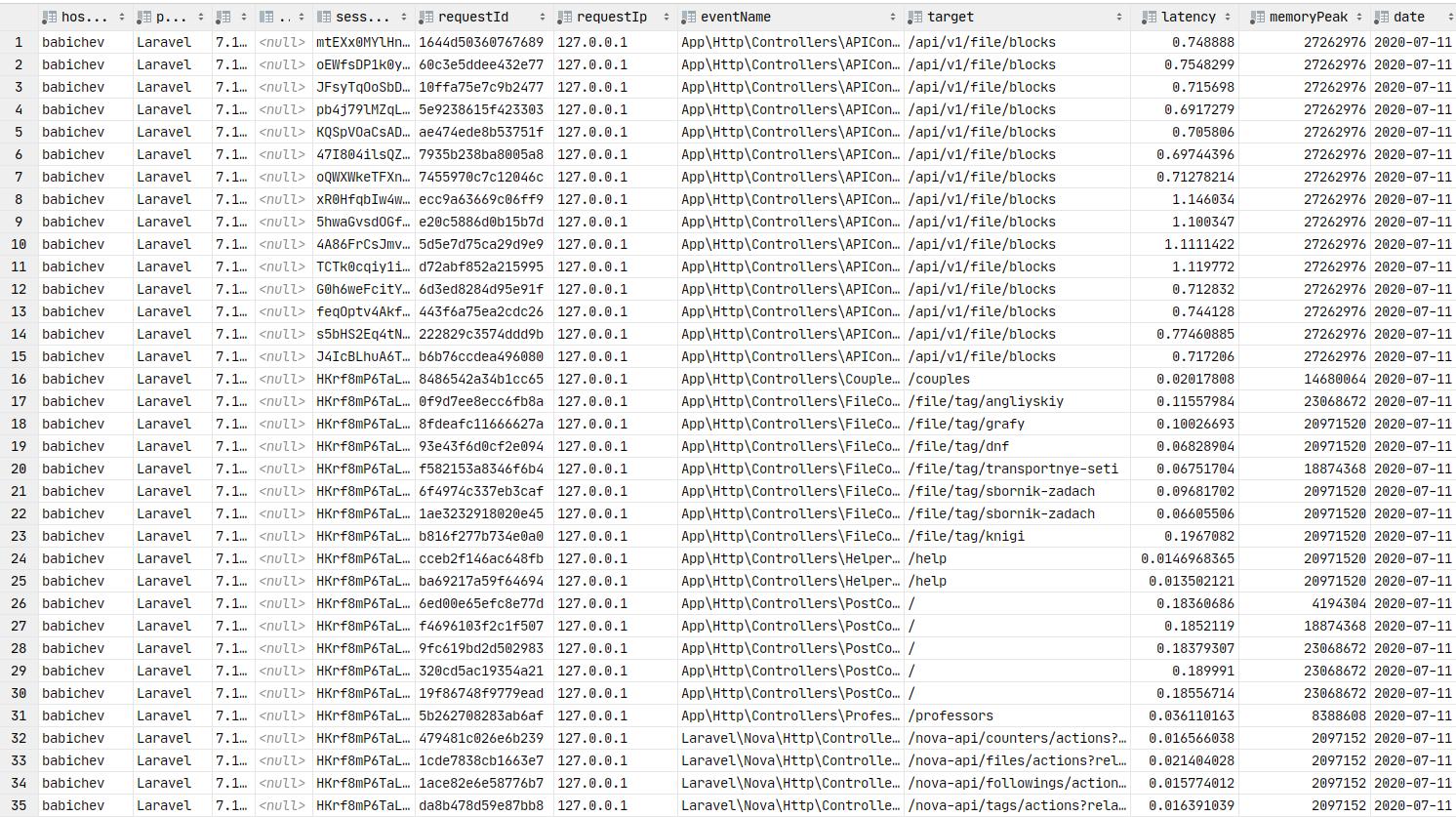
Dados no banco de dados. Você pode construir gráficos.
Grafana
Agora, vamos passar para a apresentação gráfica dos dados, que é um elemento-chave deste artigo. Você precisa instalar o grafana . Vamos pular o processo de instalação para assemblies do tipo debain, você pode usar o link para a documentação . Normalmente, a etapa de instalação resume-se ao apt install grafana .
No ArchLinux, a instalação se parece com isto:
yaourt -S grafana
sudo systemctl start grafanaO serviço foi iniciado. URL: http: // localhost: 3000
Agora você precisa instalar o plug - in da fonte de dados ClickHouse :
sudo grafana-cli plugins install vertamedia-clickhouse-datasourceSe você instalou o grafana 7+, o ClickHouse não funcionará. Você precisa fazer alterações na configuração:
sudo vi /etc/grafana.iniVamos encontrar a linha:
;allow_loading_unsigned_plugins =Vamos substituí-lo por este:
allow_loading_unsigned_plugins=vertamedia-clickhouse-datasourceVamos salvar e reiniciar o serviço:
sudo systemctl restart grafanaFeito. Agora podemos ir para a grafana .
Login: admin / senha: admin por padrão.

Após a autorização bem-sucedida, clique na engrenagem. Na janela pop-up que se abre, selecione Fontes de dados, adicione uma conexão ao ClickHouse.
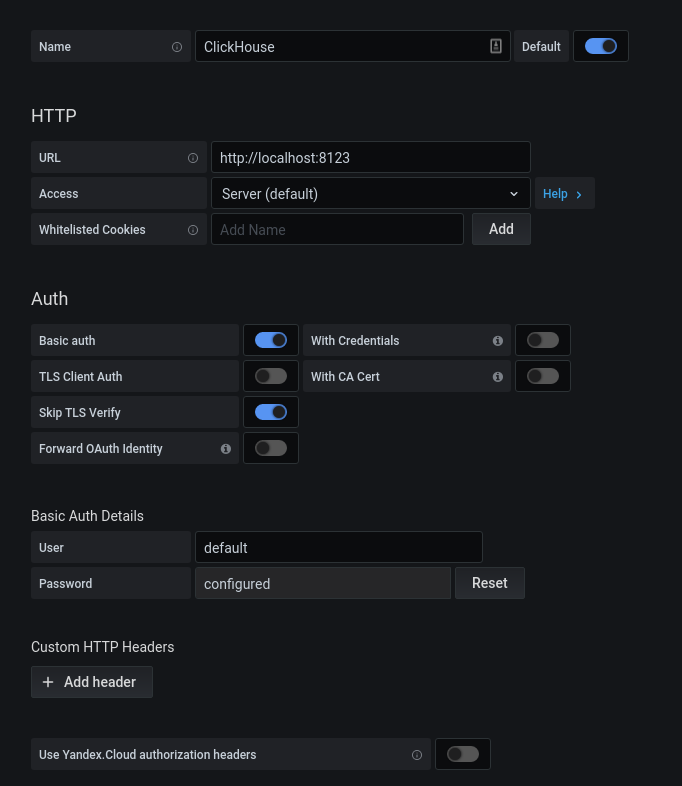
Preenchemos a configuração kx. Clique no botão "Salvar e Testar", recebemos uma mensagem sobre uma conexão bem-sucedida.
Agora vamos adicionar um novo painel:
Adicionar um painel:

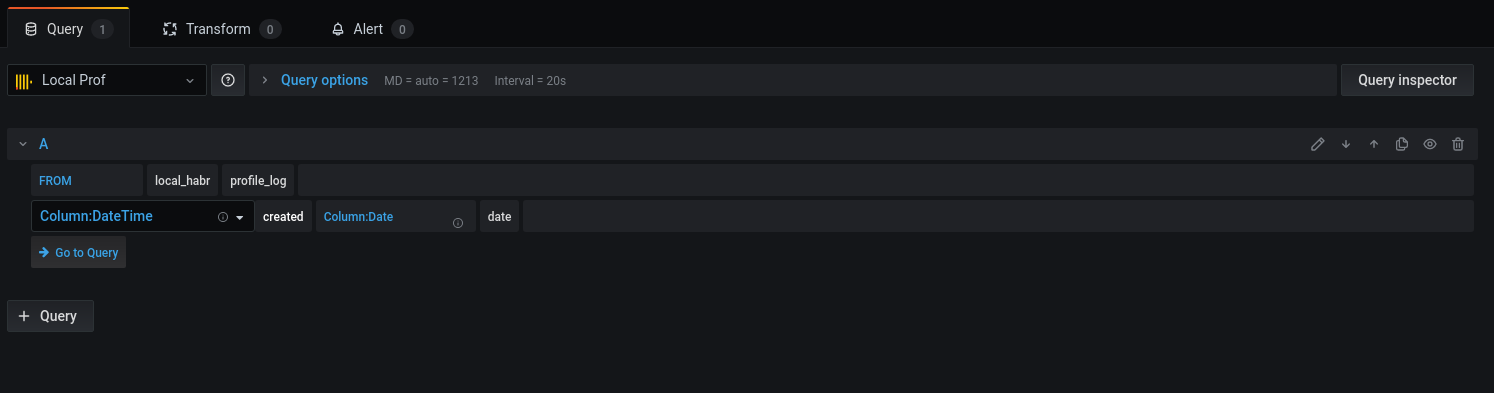
Selecione a base e as colunas correspondentes para trabalhar com datas:
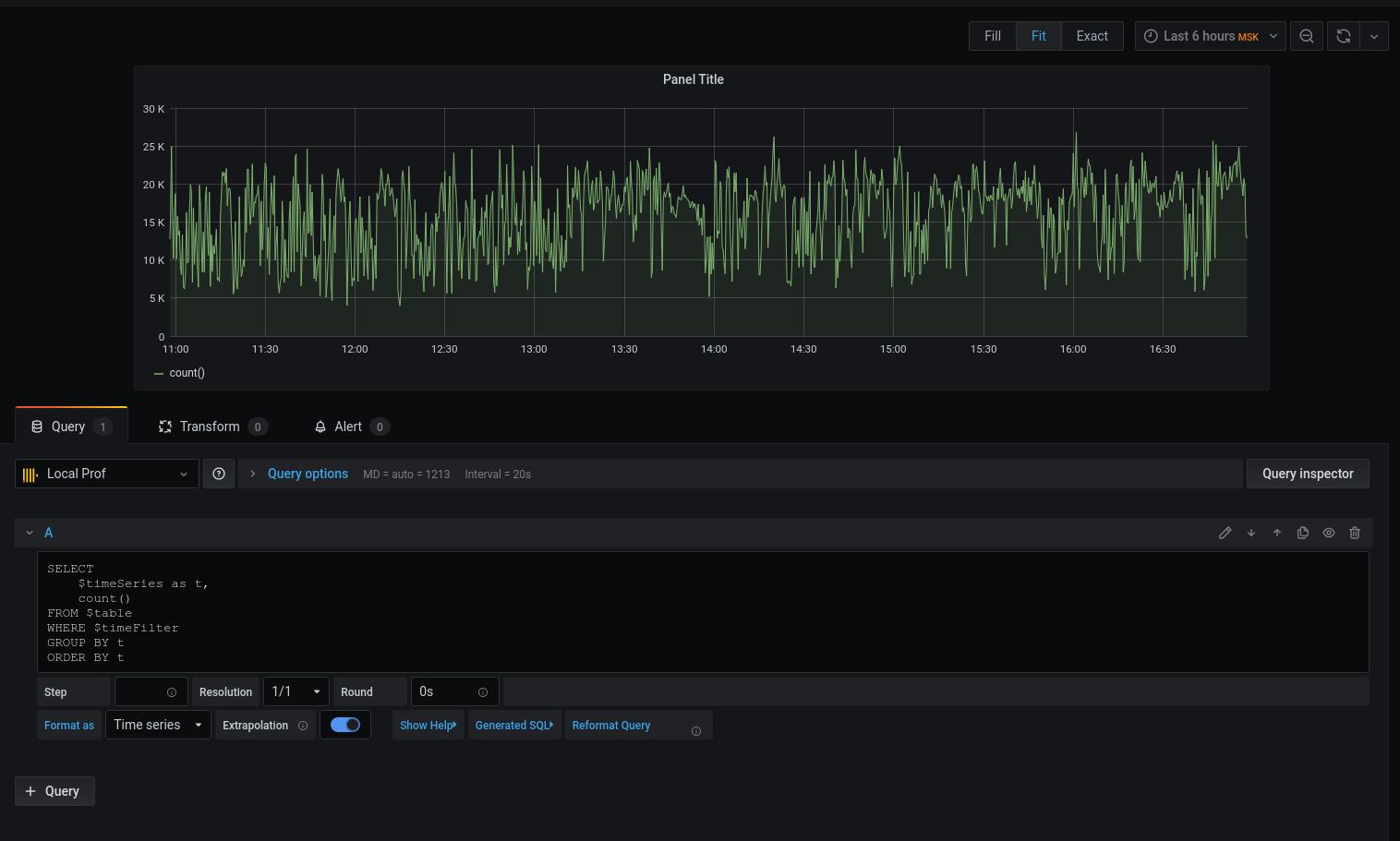
Vamos passar para a consulta:
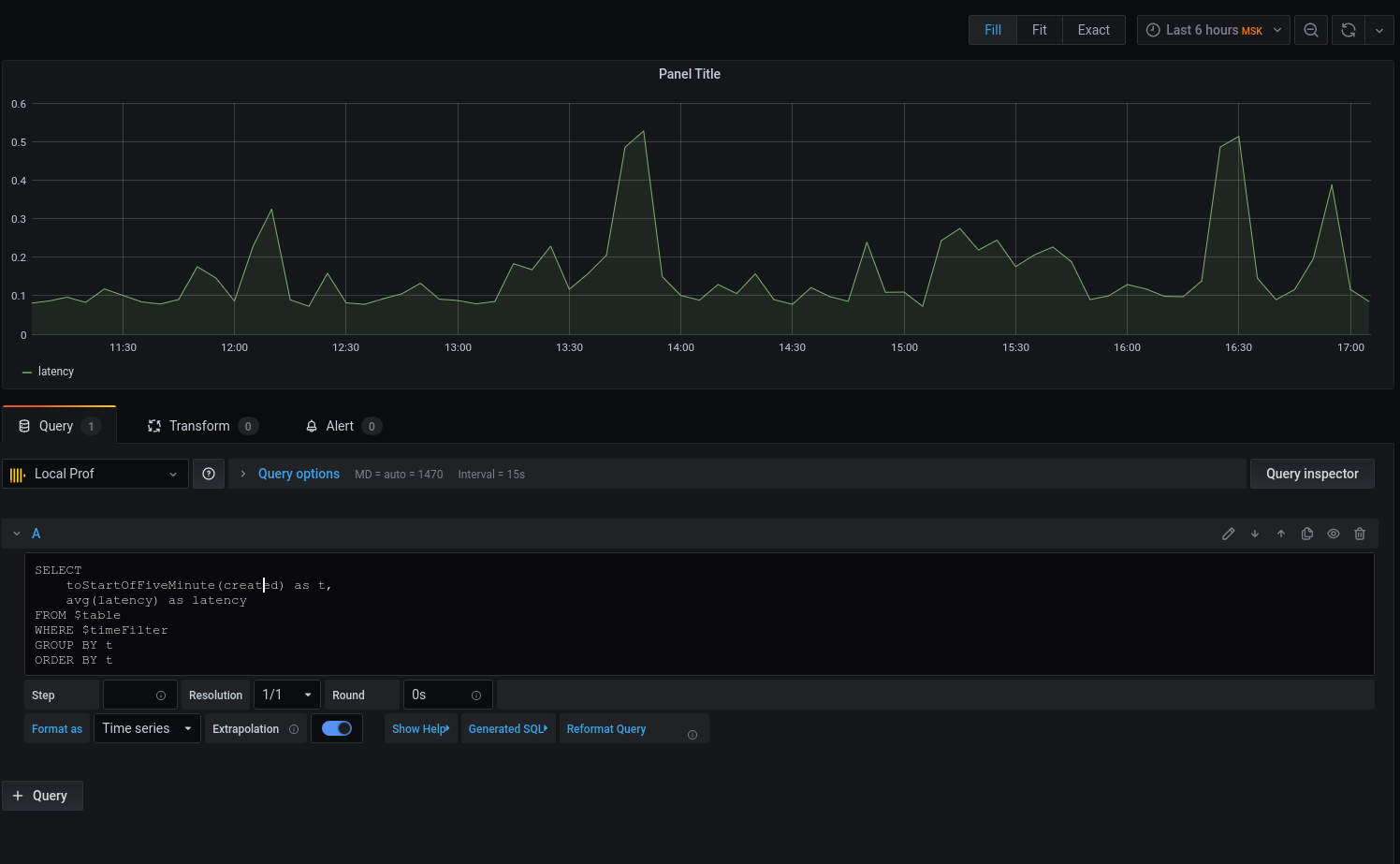
Temos um gráfico, mas quero detalhes. Vamos imprimir a latência média arredondando a data com a hora até o início do intervalo de cinco minutos :
Agora os dados selecionados são exibidos no gráfico, podemos nos concentrar neles. Para alertas, configure gatilhos, agrupe por eventos e muito mais.
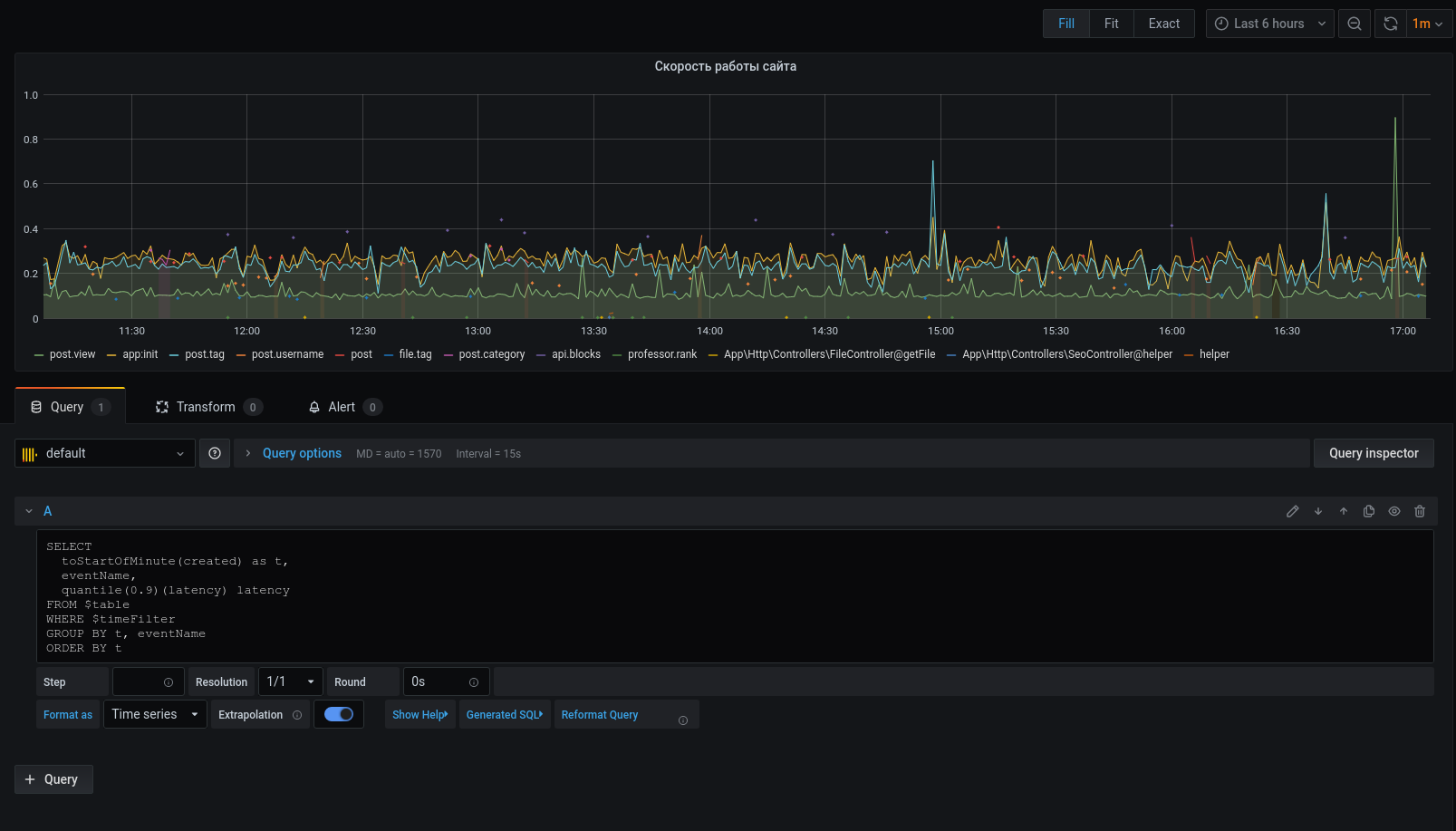
O profiler não é de forma alguma um substituto para as ferramentas: xhprof (facebook) , xhprof (tideways) , liveprof de (Badoo) . E apenas os complementa.
Todo o código-fonte está no github - modelo de perfil , serviço , BulkWriteCommand , BulkWriterJob e middleware ( 1 , 2 ).
Instalando o pacote:
composer req bavix/laravel-profConfigurando conexões (config / database.php), adicione clickhouse:
'bavix::clickhouse' => [
'driver' => 'bavix::clickhouse',
'host' => env('CH_HOST'),
'port' => env('CH_PORT'),
'database' => env('CH_DATABASE'),
'username' => env('CH_USERNAME'),
'password' => env('CH_PASSWORD'),
],
Início do trabalho:
use Bavix\Prof\Services\ProfileLogService;
// ...
app(ProfileLogService::class)->tick('event-name');
//
app(ProfileLogService::class)->tick('event-name');Para enviar um lote à fila, você precisa adicionar um comando ao cron:
* * * * * php /var/www/site.com/artisan entry:bulkVocê também precisa executar um consumidor:
php artisan queue:work --sleep=3 --tries=3Recomenda-se configurar o supervisor . Config (5 consumidores):
[program:bulk_write]
process_name=%(program_name)s_%(process_num)02d
command=php /var/www/site.com/artisan queue:work --sleep=3 --tries=3
autostart=true
autorestart=true
user=www-data
numprocs=5
redirect_stderr=true
stopwaitsecs=3600
UPD:
1. ClickHouse pode extrair dados nativamente da fila kafka . Obrigado,sdm