distorções cognitivas sobre custos irrecuperáveis (falácia dos custos irrecuperáveis) é um dos muitos preconceitos cognitivos prejudiciais que as pessoas se tornam vítimas. Isso se refere à nossa tendência de continuar a dedicar tempoe recursos para uma causa perdida, porque já gastamos - nos afogamos - muito tempo em busca. A falácia de baixo custo se aplica a permanecer em um emprego ruim por mais tempo do que deveríamos, trabalhando servilmente em um projeto mesmo quando estiver claro que não funcionará e, sim, continuando a usar a biblioteca de plotagem chata e desatualizada - matplotlib - quando houver alternativas mais eficientes, interativas e mais envolventes.
Nos últimos meses, percebi que a única razão pela qual estou usando o matplotlib é pelas centenas de horas que passei aprendendo a sintaxe complexa . Essas complexidades levam a horas de frustração ao descobrir no StackOverflow como formatar datas ou adicionar um segundo eixo Y. Felizmente, este é um ótimo momento para plotar gráficos em Python e, depois de explorar as opções , o vencedor claro - em termos de facilidade de uso, documentação e funcionalidade - é plausível . Neste artigo, vamos nos aprofundar na plotagem, aprendendo a criar gráficos melhores em menos tempo - geralmente com uma única linha de código.
Todo o código deste artigo está disponível no GitHub . Todos os gráficos são interativos e podem ser visualizados no NBViewer .
Visão geral do Plotly
Pacote plotly para Python - uma biblioteca de software de fonte aberta, construída sobre plotly.js , que, por sua vez, é construído em d3.js . Nós estaremos usando um wrapper sobre plotly chamados abotoaduras projetado para trabalhar com o Pandas DataFrame.So, nossa pilha abotoaduras> plotly> plotly.js> d3.js - Isso significa que obter eficiência na programação Python com incrível interativo capacidades gráficas d3 .
( Plotly em si é uma empresa gráficacom vários produtos e ferramentas de código aberto. A biblioteca Python é gratuita e podemos criar gráficos ilimitados offline, além de até 25 gráficos online para compartilhar com o mundo .)
Todo o trabalho neste artigo foi feito no Jupyter Notebook com plotagem + abotoaduras desligada. Depois de instalar plotly e abotoaduras,
pip install cufflinks plotly importe o seguinte para executar no Jupiter:
# Standard plotly imports
import plotly.plotly as py
import plotly.graph_objs as go
from plotly.offline import iplot, init_notebook_mode
# Using plotly + cufflinks in offline mode
import cufflinks
cufflinks.go_offline(connected=True)
init_notebook_mode(connected=True)Distribuições de variável única: histogramas e gráficos de caixas
Gráficos de variável única - unidimensional é a maneira padrão de iniciar uma análise, e um histograma é um gráfico de transição ( embora com alguns problemas ) para plotar um gráfico de distribuição. Aqui, usando minhas estatísticas médias de artigos (você pode ver como obter suas próprias estatísticas aqui ou usar as minhas ), vamos fazer um histograma interativo do número de claps de artigos (
dfeste é o dataframe padrão do Pandas):
df['claps'].iplot(kind='hist', xTitle='claps',
yTitle='count', title='Claps Distribution')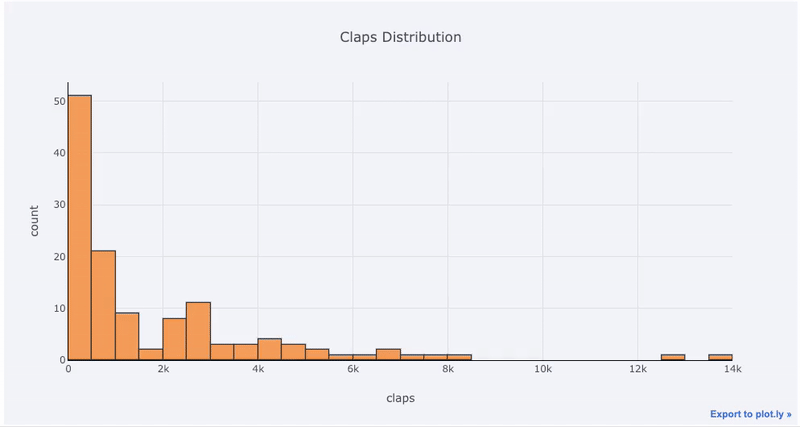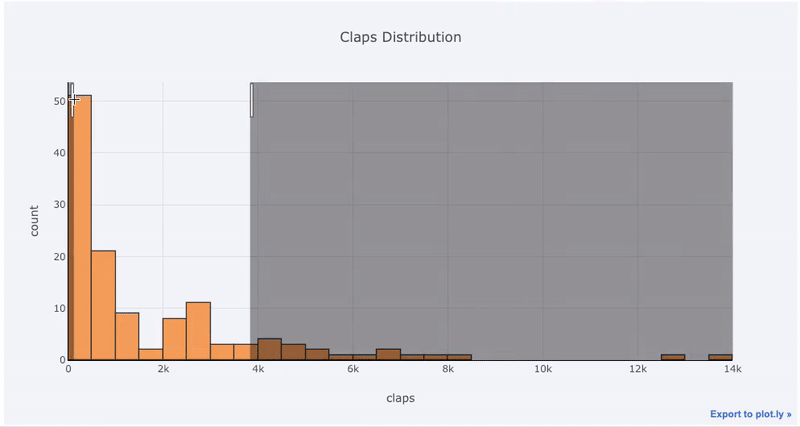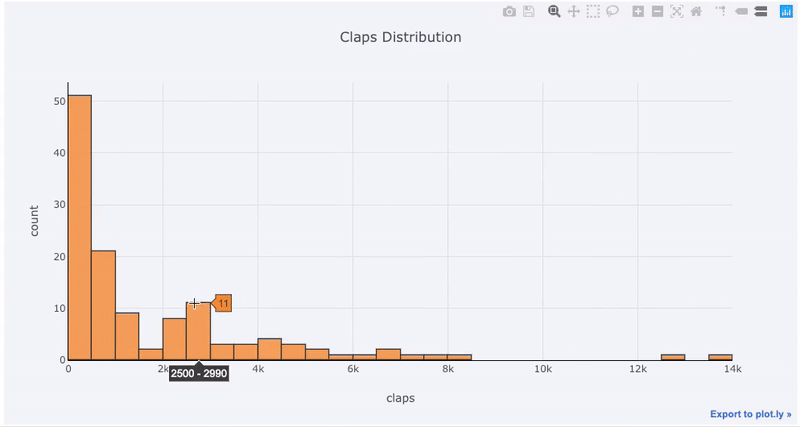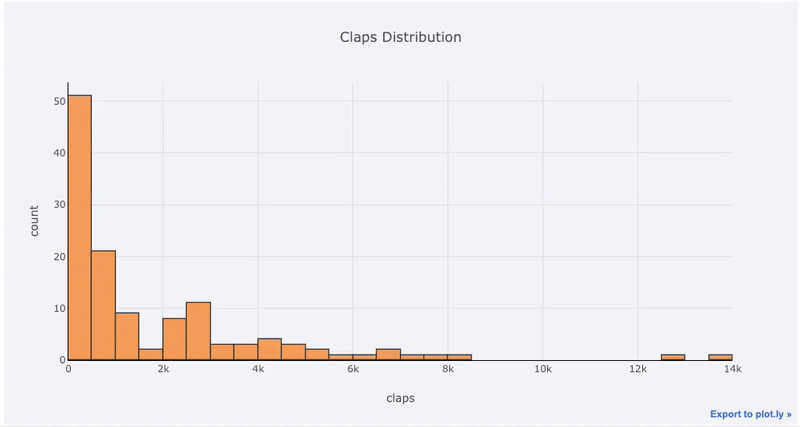
Para aqueles que estão acostumados
matplotlib, basta adicionar mais uma letra (em iplotvez de plot) e obter um gráfico muito mais bonito e interativo! Podemos clicar nos dados para obter mais informações, aumentar o zoom em partes do gráfico e, como veremos mais adiante, selecionar categorias diferentes.
Se queremos traçar histogramas sobrepostos, é igualmente fácil:
df[['time_started', 'time_published']].iplot(
kind='hist',
histnorm='percent',
barmode='overlay',
xTitle='Time of Day',
yTitle='(%) of Articles',
title='Time Started and Time Published')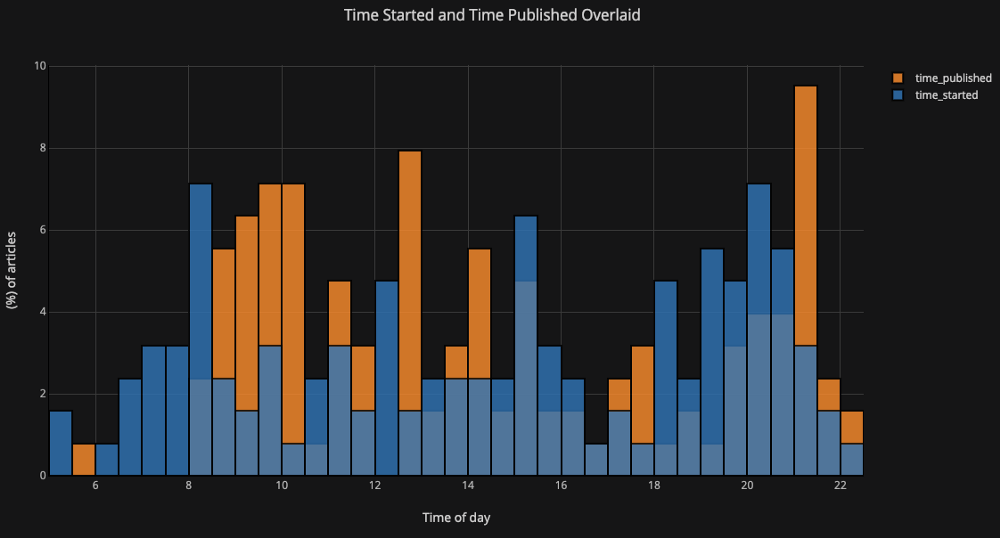
Com um pouco de manipulação
Pandas, podemos fazer um gráfico de barras:
# Resample to monthly frequency and plot
df2 = df[['view','reads','published_date']].\
set_index('published_date').\
resample('M').mean()
df2.iplot(kind='bar', xTitle='Date', yTitle='Average',
title='Monthly Average Views and Reads')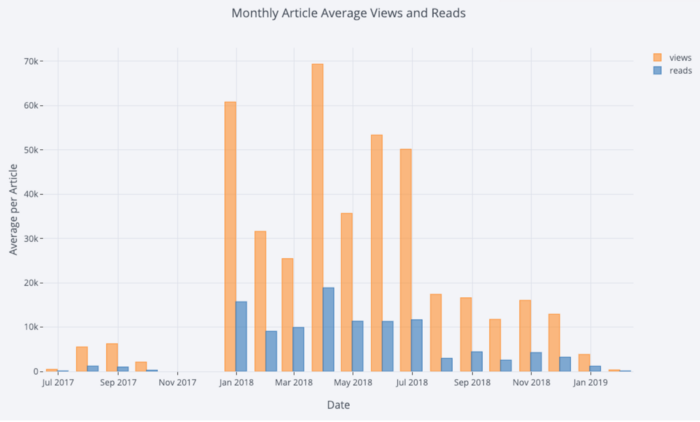
como vimos, podemos combinar o poder dos pandas com plotagem + abotoaduras. Para traçar a distribuição dos fãs por publicação, usamos
pivot, em seguida, plotamos:
df.pivot(columns='publication', values='fans').iplot(
kind='box',
yTitle='fans',
title='Fans Distribution by Publication')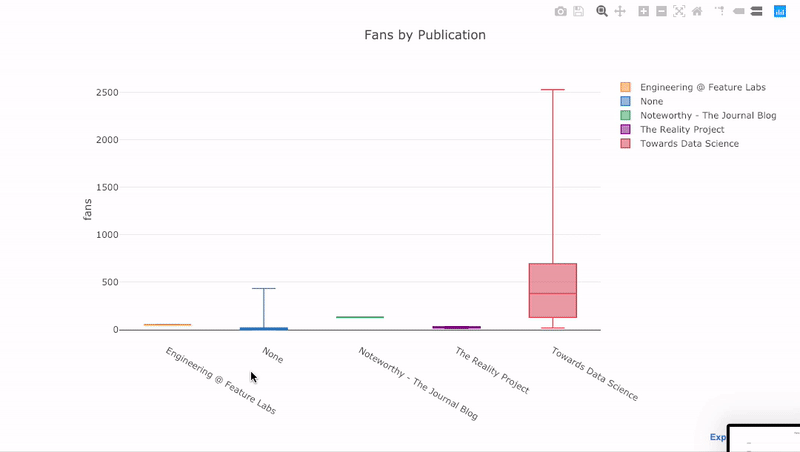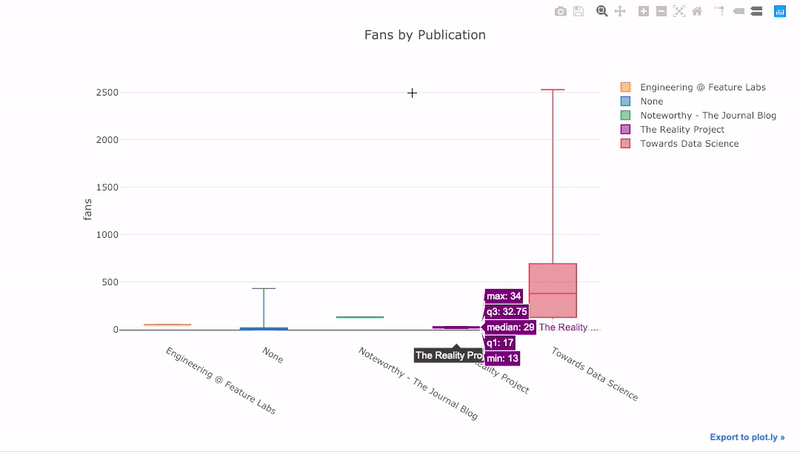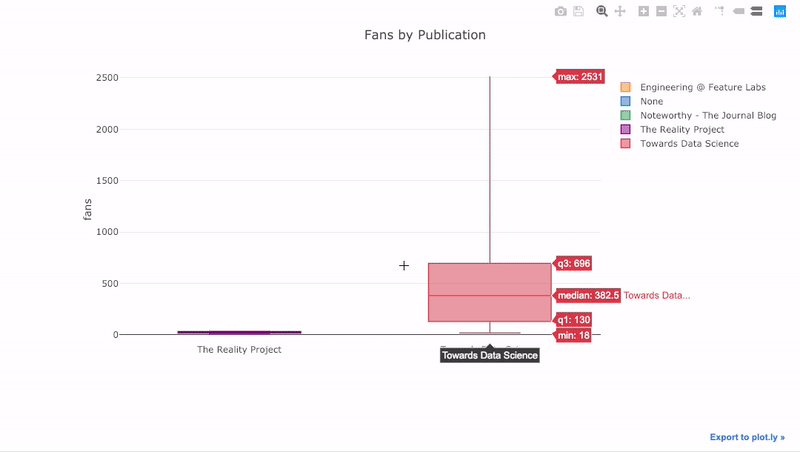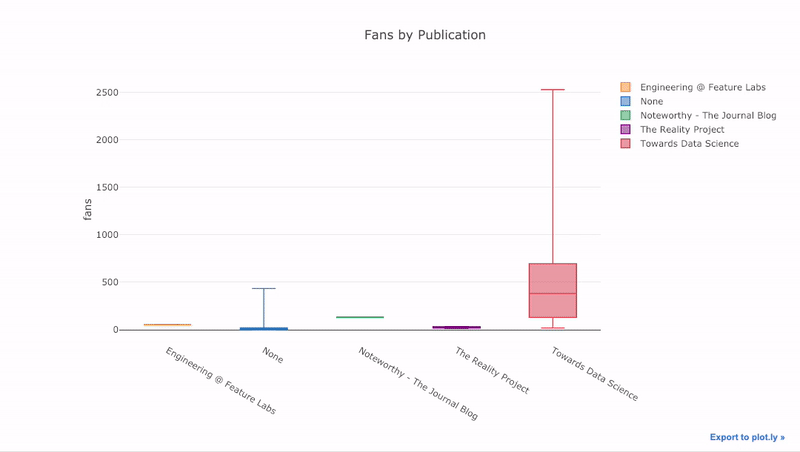
Os benefícios da interatividade são que podemos explorar e hospedar os dados como acharmos melhor. Há muita informação na caixa de jangada e, sem a capacidade de ver os números, sentiremos falta dela!
Gráfico de dispersão
O gráfico de dispersão é o coração da maioria das análises. Isso nos permite ver a evolução de uma variável ao longo do tempo ou o relacionamento entre duas (ou mais) variáveis.
Séries temporais
Muitos dados reais possuem um elemento de tempo. Felizmente, os botões de punho foram projetados com a visualização de séries temporais em mente. Vamos enquadrar os dados dos meus artigos do TDS e ver como as tendências mudaram.
Create a dataframe of Towards Data Science Articles
tds = df[df['publication'] == 'Towards Data Science'].\
set_index('published_date')
# Plot read time as a time series
tds[['claps', 'fans', 'title']].iplot(
y='claps', mode='lines+markers', secondary_y = 'fans',
secondary_y_title='Fans', xTitle='Date', yTitle='Claps',
text='title', title='Fans and Claps over Time')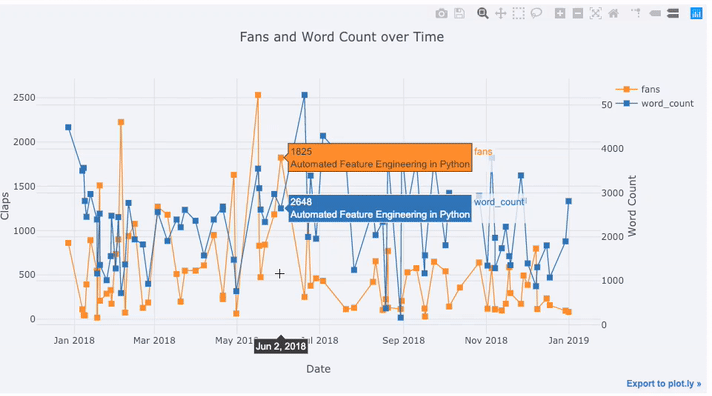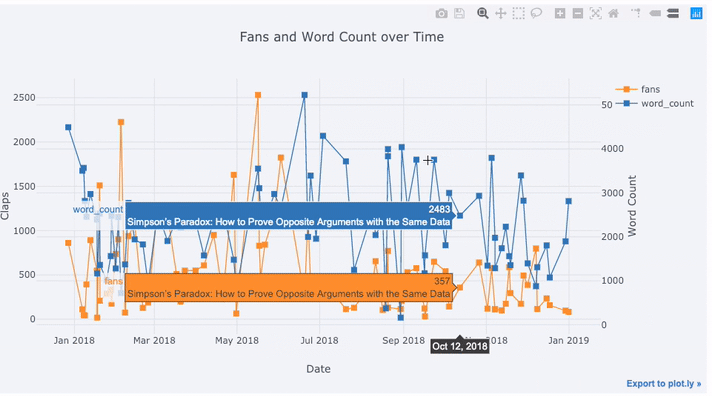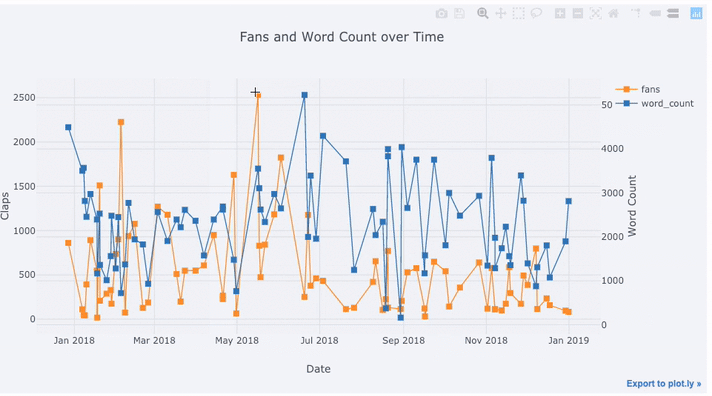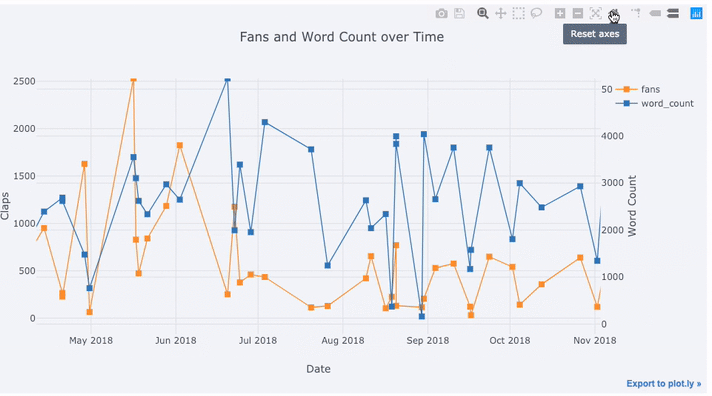
Vemos algumas coisas diferentes aqui:
- Obter automaticamente séries temporais bem formatadas no eixo x
- Adicionando um eixo y secundário porque nossas variáveis têm intervalos diferentes
- Exibindo títulos de artigos ao passar o mouse
Para mais informações, também podemos adicionar anotações de texto com bastante facilidade:
tds_monthly_totals.iplot(
mode='lines+markers+text',
text=text,
y='word_count',
opacity=0.8,
xTitle='Date',
yTitle='Word Count',
title='Total Word Count by Month')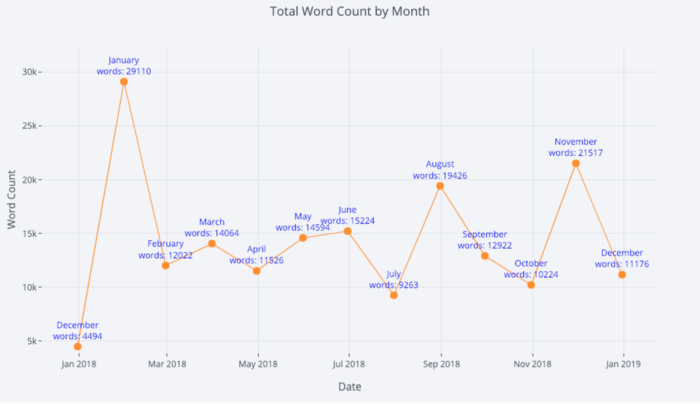
Para um gráfico de dispersão de duas variáveis colorido com a terceira variável categórica, usamos:
df.iplot(
x='read_time',
y='read_ratio',
# Specify the category
categories='publication',
xTitle='Read Time',
yTitle='Reading Percent',
title='Reading Percent vs Read Ratio by Publication')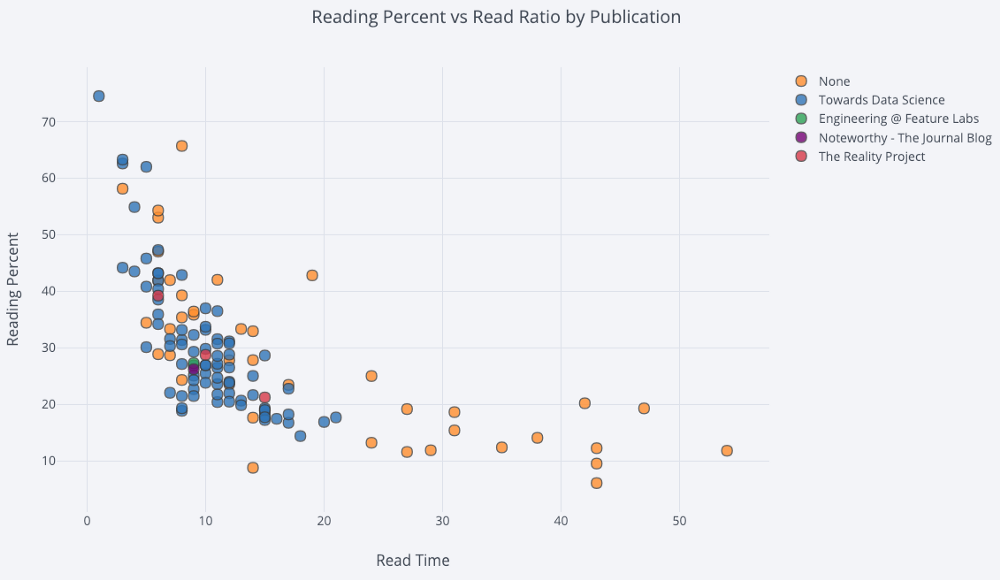
Vamos complicar um pouco as coisas usando um eixo de log, especificado como layout de plotagem - (consulte a documentação de Plotly para especificações de layout) e especificando o tamanho das bolhas de uma variável numérica:
tds.iplot(
x='word_count',
y='reads',
size='read_ratio',
text=text,
mode='markers',
# Log xaxis
layout=dict(
xaxis=dict(type='log', title='Word Count'),
yaxis=dict(title='Reads'),
title='Reads vs Log Word Count Sized by Read Ratio'))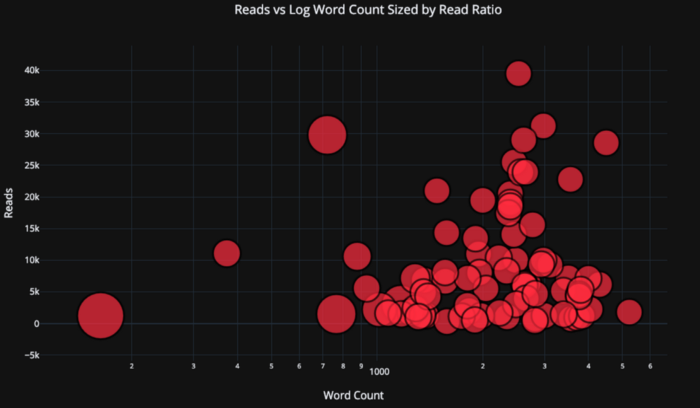
Com um pouco de trabalho ( consulte o Bloco de notas para obter detalhes ), podemos até colocar quatro variáveis ( não recomendadas ) em um gráfico!
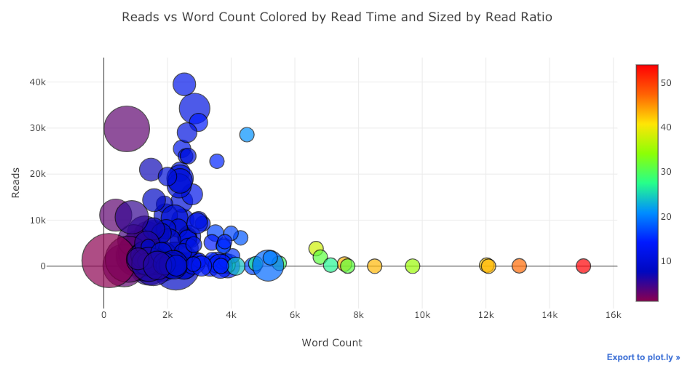
Como antes, podemos combinar Pandas com plotagem + botões de punho para gráficos úteis
df.pivot_table(
values='views', index='published_date',
columns='publication').cumsum().iplot(
mode='markers+lines',
size=8,
symbol=[1, 2, 3, 4, 5],
layout=dict(
xaxis=dict(title='Date'),
yaxis=dict(type='log', title='Total Views'),
title='Total Views over Time by Publication'))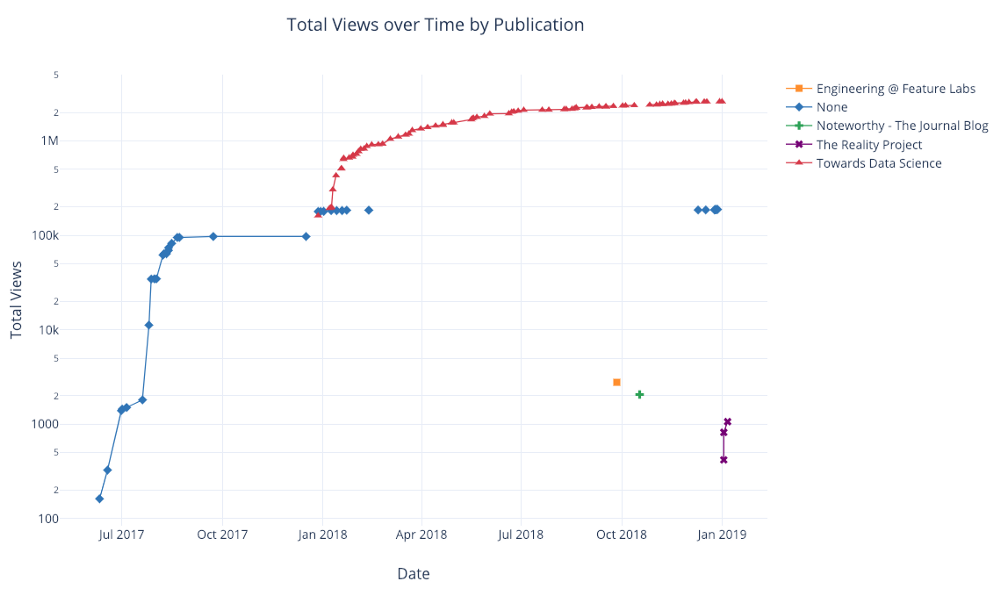
Para mais exemplos de funcionalidade, consulte o caderno ou a documentação . Podemos adicionar anotações de texto, linhas de referência e linhas de melhor ajuste a nossos diagramas com uma linha de código e ainda com todas as interações.
Gráficos avançados
Passamos agora a alguns gráficos que você provavelmente não usará com tanta frequência, mas que podem ser bastante impressionantes. Usaremos plot_factory figurativa para fazer até mesmo esses haffics incríveis em uma linha.
Matriz de Dispersão
Quando queremos explorar relações entre muitas variáveis, a matriz de dispersão (também chamada splom) é uma ótima opção:
import plotly.figure_factory as ff
figure = ff.create_scatterplotmatrix(
df[['claps', 'publication', 'views',
'read_ratio','word_count']],
diag='histogram',
index='publication')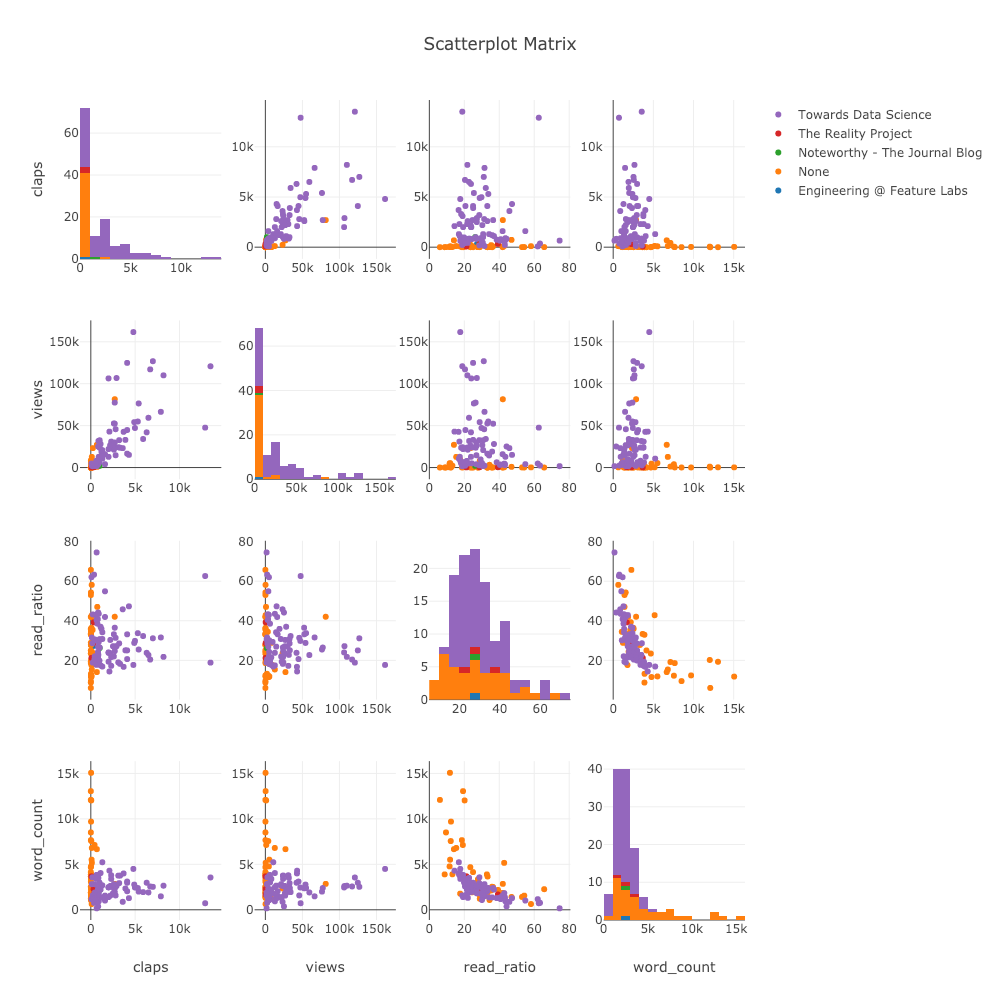
Mesmo este gráfico é totalmente interativo, permitindo-nos explorar os dados.
Mapa de Calor de Correlação
Para visualizar correlações entre variáveis numéricas, calculamos as correlações e, em seguida, fazemos um mapa de calor anotado:
corrs = df.corr()
figure = ff.create_annotated_heatmap(
z=corrs.values,
x=list(corrs.columns),
y=list(corrs.index),
annotation_text=corrs.round(2).values,
showscale=True)
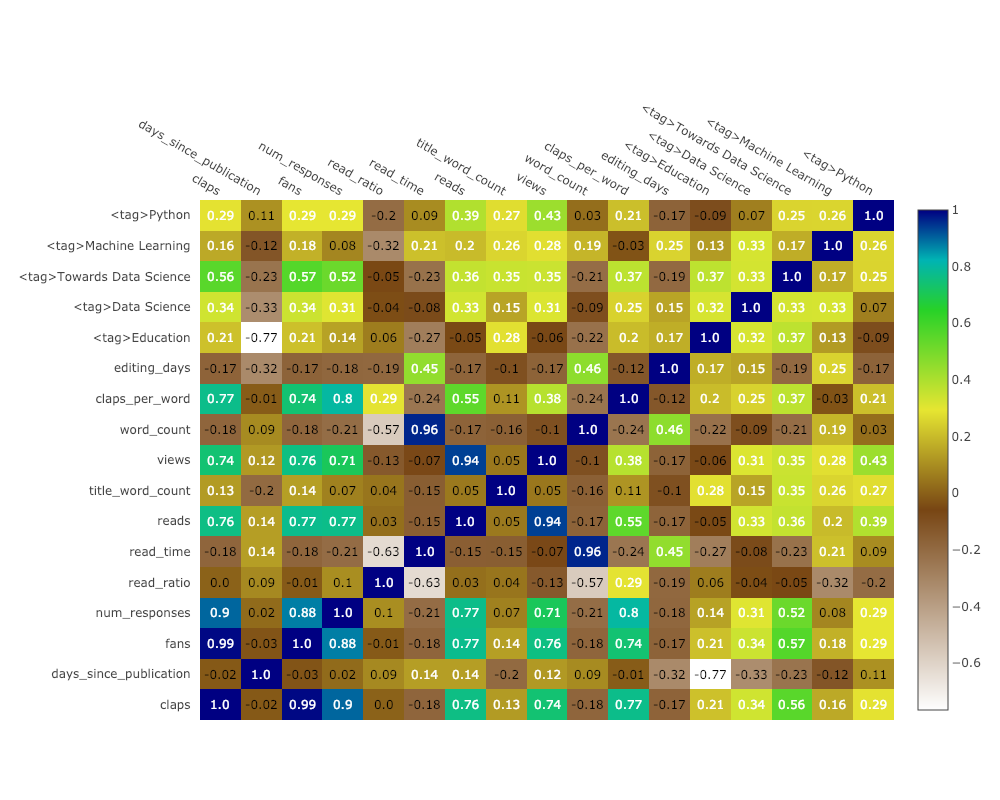
A lista de gráficos continua e continua. Os botões de punho também têm vários temas que podemos usar para obter uma aparência completamente diferente sem nenhum esforço. Por exemplo, abaixo, temos um gráfico de proporção no tema "espaço" e um gráfico de dispersão em "ggplot":
também temos gráficos 3D (superfícies e gráficos de bolhas):
para quem quiser , você pode até fazer um gráfico de pizza:
Editando no Plotly Chart Studio
Ao criar esses gráficos no NoteBook Jupiter, você notará um pequeno link no canto inferior direito do gráfico “Exportar para plot.ly”; se você clicar nesse link, será direcionado ao Chart Studio, onde poderá ajustar seu gráfico para a apresentação final. Você pode adicionar anotações, especificar cores e geralmente limpar tudo para obter um ótimo gráfico. Em seguida, você pode publicar sua programação na Internet para que qualquer pessoa possa encontrá-la por referência.
Abaixo estão dois gráficos que aprimorei no Chart Studio:
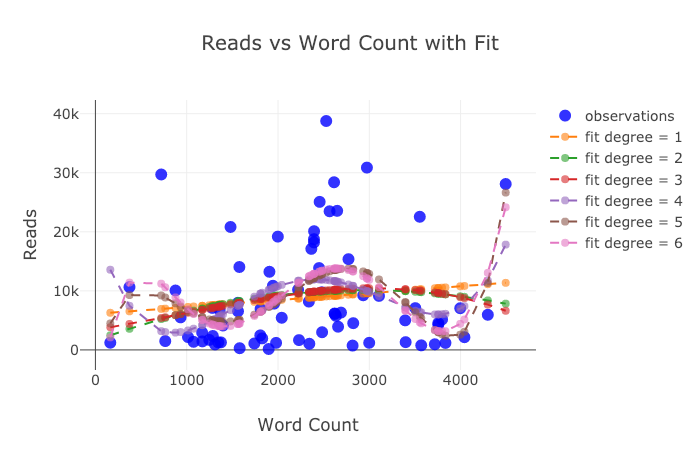
Apesar do que foi dito aqui, ainda não exploramos todos os recursos da biblioteca! Aconselho você a olhar para a documentação de plotagem e a documentação dos botões de punho para obter gráficos mais incríveis.
conclusões
A pior parte do equívoco subvalorizado é que você só percebe quanto tempo perdeu após sair. Felizmente, agora que cometi o erro de ficar com o matploblib por muito tempo, você não precisa!
Quando pensamos em bibliotecas de plotagem, há várias coisas que queremos:
- Gráficos de uma linha para exploração rápida
- Substituição / exploração interativa de dados
- A capacidade de pesquisar detalhes conforme necessário
- Configuração fácil para apresentação final
No momento, a melhor opção para fazer tudo isso em Python é trama. Plotly nos permite fazer visualizações rapidamente e nos ajuda a entender melhor nossos dados através da interatividade. Além disso, convenhamos, o mapeamento deve ser uma das partes mais agradáveis da ciência de dados! Com outras bibliotecas, a plotagem se tornou uma tarefa tediosa, mas com a plotagem, há a alegria de fazer uma grande figura novamente!

Descubra os detalhes de como obter uma profissão de alto nível do zero ou subir de nível em habilidades e salário fazendo os cursos on-line pagos do SkillFactory:
- Treinamento da profissão em Data Science (12 meses)
- Profissão analítica com qualquer nível inicial (9 meses)
- Curso de Machine Learning (12 semanas)
- «Python -» (9 )
- DevOps (12 )
- - (8 )