Pré-requisitos
A tarefa de procurar uma frase em um texto paginado é reduzida para calcular o coeficiente de relevância para cada uma das páginas e depois classificar a lista em ordem decrescente do coeficiente.
No processo de cálculo de acordo com a abordagem básica, cada página é submetida à análise símbolo a símbolo, e aqui está a possibilidade de otimização.

Ao calcular o coeficiente, são analisados grupos de caracteres correspondentes de seqüências de caracteres e dados de pesquisa, enquanto grupos podem ser formados apenas com palavras. Por outro lado, considerando o problema de superestimar a importância de palavras “longas” (na parte 2 ), como uma solução possível, “ calcular a relevância de uma frase de pesquisa como uma média das relevância das palavras incluídas nela, calculadas de forma independente ”, foi proposto . O uso de um índice produzirá um resultado equivalente a essa abordagem específica.
Índice
A idéia de indexação não é nova e é a seguinte - devido ao fato de as palavras no texto serem repetidas, a quantidade de cálculos pode ser reduzida. Para fazer isso, o texto no qual a pesquisa será realizada deve primeiro gerar um índice. No caso mais simples, o índice é uma tabela de todas as palavras no texto que, além de palavras, contém dados sobre as páginas em que ocorrem. Fragmento da tabela de índice com base no texto da novela de L.N. A "Guerra e Paz" de Tolstoi (no total, contém cerca de 50 mil palavras), é mostrada na figura.

Diretamente no processo de processamento de uma solicitação, a cadeia de pesquisa é primeiro dividida em palavras. Além disso, para cada uma das palavras da sequência de pesquisa, a relevância é calculada com cada uma das palavras no índice . Os resultados do cálculo são acumulados emtabela de resultados preliminares contendo as colunas "Palavra da cadeia de caracteres de pesquisa", "Palavra do índice", "Fator de relevância", "Número da página". A tabela contém apenas as linhas do índice, o coeficiente de relevância para o qual as palavras excederam o limite especificado. Ou seja, cada linha do índice com uma palavra correspondente gera linhas na tabela de resultados preliminares iguais ao número de páginas de texto nas quais essa palavra ocorre. Abaixo está um fragmento da tabela de resultados preliminares para a busca pela frase "Noite em Anna Pavlovna Sherer's".

Em seguida, a tabela de resultados preliminares é classificada por colunas Número da página , Pesquisar palavra da string , Fator(descendente).

Ao percorrer as linhas da tabela classificada, para cada uma das páginas e para cada palavra da sequência de pesquisa, a palavra mais relevante desta página é identificada - graças à classificação descrita acima, esta é a primeira palavra para cada combinação Número da página - Pesquisa da palavra da sequência . O restante das linhas é descartado por combinação.
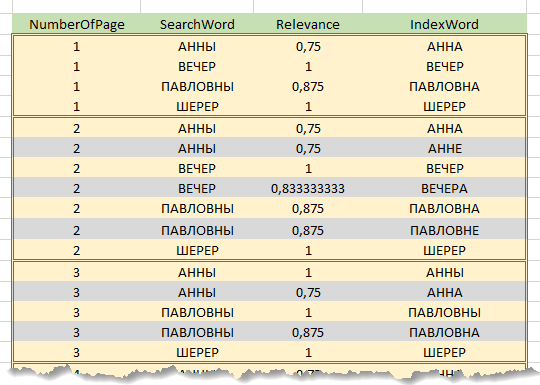
Assim, para cada página de texto incluída na tabela de resultados preliminares , para cada palavra na cadeia de pesquisa, serão encontradas as palavras mais relevantes desta página com os coeficientes correspondentes. A soma dos coeficientes de palavras encontradas na página, referente ao número de palavras na barra de pesquisa, fornecerá o coeficiente de relevância para a página.

Por exemplo, na figura acima, a pesquisa é realizada pela linha "Evening at Anna Pavlovna Sherer" (a preposição "y" não é levada em consideração), as linhas destacadas em cinza são descartadas durante o desvio. O coeficiente de relevância para a página 1 será (0,75 + 1 + 0,875 + 1) / 4 = 0,906, para a página 2 - 0,906, para 3 - 0,75.
Benefícios
Se você não levar em conta o tempo gasto na indexação, cujos resultados são reutilizados e levar em conta que a quantidade total de computação, a avaliação do que é reproduzido na parte 1. , um múltiplo do comprimento da cadeia de dados:
 ;
;
podemos dizer que o ganho do uso do índice será múltiplo da proporção:
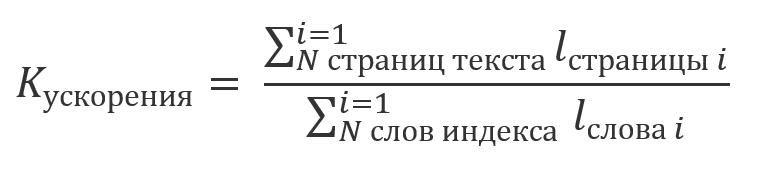
por exemplo, no stand de demonstração textradar.ru , o texto do romance "Guerra e Paz" é dividido em 1488 páginas de 2000 caracteres cada. O número total de símbolos nas palavras do índice, consistindo em 52156 elementos, é 434060. Ou seja, o ganho da indexação será de cerca de 7:

Como os resultados obtidos usando a indexação são equivalentes aos resultados obtidos sem uma das abordagens descritas anteriormente, torna-se possível processar em conjunto os resultados da pesquisa para as partes indexadas e não indexadas do texto. Devido ao fato de a indexação ser uma operação relativamente cara e geralmente realizada em uma programação, é possível que uma parte do texto seja indexada e algumas ainda não o sejam. Nesse caso, a economia na quantidade de computação será um múltiplo da parte do texto indexado em seu tamanho total:
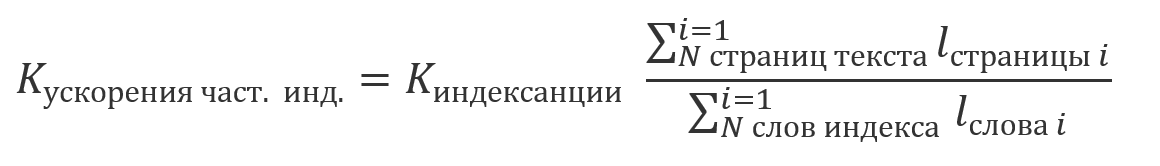
Além de melhorar a velocidade da pesquisa, o uso de um índice abre várias outras possibilidades. Por exemplo, usando estatísticas obtidas da indexação, você pode aumentar a importância de palavras raras e destacar as páginas de texto nas quais as palavras significativas da frase de pesquisa são encontradas com mais frequência. Você também pode estender a tabela de índice com sinônimos.
Isso conclui o ciclo de publicações dedicadas à descrição do TextRadar. Obrigado a todos pelo interesse e comentários valiosos que nos permitiram ir além do planejado originalmente.
Os resultados da aplicação das abordagens descritas podem ser vistos no estande de demonstração implementado no site textradar.ru . A implementação (C # ASP.NET MVC) pode ser encontrada aqui .