Ab Initio tem muitas transformações clássicas e incomuns que podem ser estendidas com seu próprio PDL. Para uma empresa de pequeno porte, é provável que uma ferramenta tão poderosa seja redundante e a maioria de seus recursos pode ser cara e desnecessária. Mas se a sua balança estiver próxima da do Sberbank, o Ab Initio pode ser interessante para você.
Ajuda os negócios a acumular globalmente conhecimento e desenvolver o ecossistema, e o desenvolvedor - a aumentar suas habilidades em ETL, a extrair conhecimento no shell, oferece uma oportunidade de dominar a linguagem PDL, fornece uma imagem visual dos processos de carregamento, simplifica o desenvolvimento devido à abundância de componentes funcionais.
Neste post, falarei sobre os recursos do Ab Initio e apresentarei características comparativas de seu trabalho com o Hive e o GreenPlum.
- MDW GreenPlum
- Ab Initio Hive GreenPlum
- Ab Initio GreenPlum Near Real Time
A funcionalidade deste produto é muito ampla e leva muito tempo para aprender. No entanto, com as habilidades de trabalho adequadas e as configurações de desempenho corretas, os resultados do processamento de dados são bastante impressionantes. O uso do Ab Initio para um desenvolvedor pode proporcionar uma experiência interessante. Esta é uma nova visão do desenvolvimento de ETL, um híbrido entre um ambiente visual e o desenvolvimento de download em uma linguagem semelhante a script.
As empresas desenvolvem seus ecossistemas e essa ferramenta é útil mais do que nunca. Com a ajuda do Ab Initio, você pode acumular conhecimento sobre seus negócios atuais e usá-lo para expandir novos e antigos negócios. Alternativas ao Ab Initio podem ser chamadas a partir dos ambientes de desenvolvimento visual Informatica BDM e de ambientes não visuais - Apache Spark.
Descrição do Ab Initio
O Ab Initio, como outras ferramentas ETL, é um conjunto de produtos.

Ab Initio GDE (Ambiente de Desenvolvimento Gráfico) é um ambiente para um desenvolvedor no qual ele configura transformações de dados e as conecta a fluxos de dados na forma de setas. Nesse caso, esse conjunto de transformações é chamado de gráfico: As

conexões de entrada e saída de componentes funcionais são portas e contêm campos calculados nas transformações. Vários gráficos conectados por fluxos na forma de setas na ordem de sua execução são chamados de plano.
Existem várias centenas de componentes funcionais, o que é muito. Muitos deles são altamente especializados. O Ab Initio possui uma gama mais ampla de transformações clássicas do que outras ferramentas ETL. Por exemplo, Join possui várias saídas. Além do resultado da conexão de conjuntos de dados, você pode obter os registros de saída dos conjuntos de dados de entrada, por chaves às quais não foi possível conectar. Também é possível obter rejeições, erros e um log da operação de transformação, que pode ser lida na mesma coluna que um arquivo de texto e processada por outras transformações:

ou, por exemplo, você pode materializar o receptor de dados na forma de uma tabela e ler dados dele na mesma coluna.
Existem transformações originais. Por exemplo, a transformação de Varredura tem a mesma funcionalidade que as funções analíticas. Existem transformações com nomes auto-explicativos: criar dados, ler Excel, normalizar, classificar dentro de grupos, executar programa, executar SQL, associar-se ao banco de dados etc. Os gráficos podem usar parâmetros de tempo de execução, incluindo a transferência de parâmetros do sistema operacional ou para o sistema operacional ... Arquivos com um conjunto pronto de parâmetros passados para o gráfico são chamados de conjuntos de parâmetros (psets).
Como esperado, o Ab Initio GDE possui seu próprio repositório chamado EME (Enterprise Meta Environment). Os desenvolvedores têm a capacidade de trabalhar com versões locais do código e verificar seus desenvolvimentos no repositório central.
É possível, durante a execução ou após a execução do gráfico, clicar em qualquer fluxo que conecte as transformações e examinar os dados que passaram entre essas transformações:

Também é possível clicar em qualquer fluxo e ver os detalhes do rastreamento - em quantos paralelos a transformação funcionou, quantas linhas e bytes em que paralelos são carregados:

É possível dividir a execução do gráfico em fases e marcar que algumas transformações devem ser executadas primeiro (na fase zero), seguidas na primeira fase, seguidas na segunda fase, etc.
Para cada transformação, você pode escolher o layout chamado (onde será executado): sem paralelos ou em threads paralelos, cujo número pode ser definido. Ao mesmo tempo, os arquivos temporários criados pelo Ab Initio durante o trabalho de transformações podem ser colocados no sistema de arquivos do servidor e no HDFS.
Em cada transformação, com base no modelo padrão, você pode criar seu próprio script na linguagem PDL, que é um pouco como um shell.
Com a ajuda da linguagem PDL, você pode estender a funcionalidade das transformações e, em particular, gerar dinamicamente (em tempo de execução) gerar fragmentos de código arbitrários, dependendo dos parâmetros de tempo de execução.
Além disso, o Ab Initio possui uma integração bem desenvolvida com o sistema operacional por meio do shell. Especificamente, o Sberbank usa linux ksh. Você pode trocar variáveis com o shell e usá-las como parâmetros gráficos. Você pode chamar a execução de gráficos Ab Initio a partir do shell e administrar o Ab Initio.
Além do Ab Initio GDE, a entrega inclui muitos outros produtos. Existe um sistema operacional com uma reivindicação de ser chamado de sistema operacional. Há Control> Center onde você pode agendar e monitorar fluxos de download. Existem produtos para desenvolver o desenvolvimento em um nível mais primitivo do que o Ab Initio GDE permite.
Descrição da estrutura MDW e trabalho sobre sua customização para GreenPlum
Juntamente com seus produtos, o fornecedor fornece o produto MDW (Metadata Driven Warehouse), que é um configurador gráfico projetado para ajudar nas tarefas típicas de preenchimento de data warehouses ou cofres de dados.
Ele contém analisadores de metadados personalizados (específicos do projeto) e geradores de código prontos para uso.
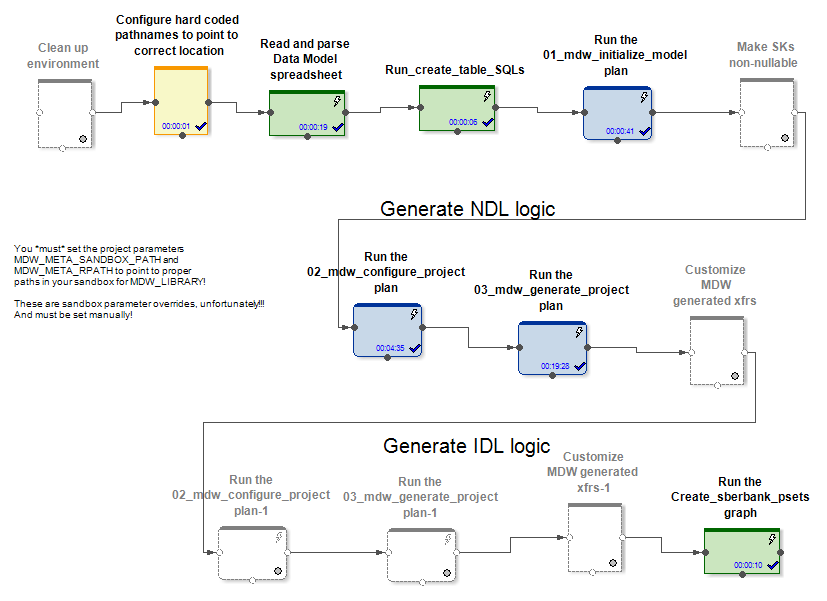
Na entrada, o MDW recebe um modelo de dados, um arquivo de configuração para configurar uma conexão com o banco de dados (Oracle, Teradata ou Hive) e algumas outras configurações. A parte específica do projeto, por exemplo, implanta o modelo no banco de dados. A parte em caixa do produto gera gráficos e arquivos de configuração para eles ao carregar dados nas tabelas de modelos. Isso cria gráficos (e psets) para vários modos de inicialização e trabalho incremental na atualização de entidades.
Nos casos Hive e RDBMS, diferentes gráficos de inicialização e atualização incremental de dados são gerados.
No caso do Hive, os dados delta recebidos são unidos pelo Ab Initio Join aos dados que estavam na tabela antes da atualização. Os carregadores de dados no MDW (no Hive e no RDBMS) não apenas inserem novos dados do delta, mas também fecham os períodos de validade dos dados para as chaves primárias das quais o delta foi recebido. Além disso, você deve reescrever a parte inalterada dos dados. Mas isso precisa ser feito, pois o Hive não possui operações de exclusão ou atualização.
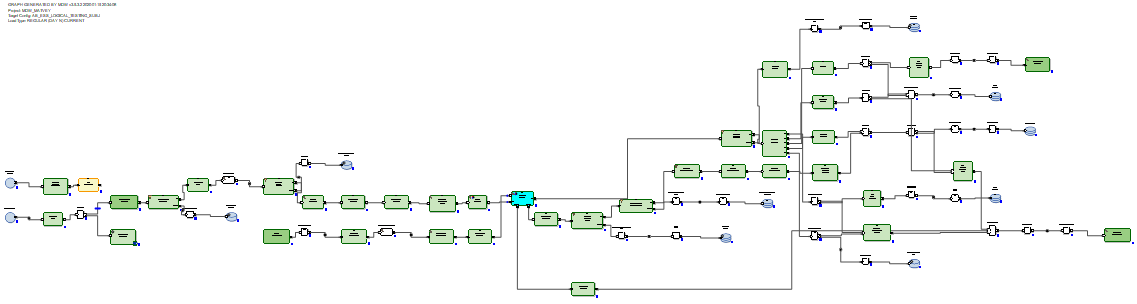
No caso do RDBMS, os gráficos de atualização de dados incrementais parecem mais ideais porque o RDBMS possui recursos reais de atualização.
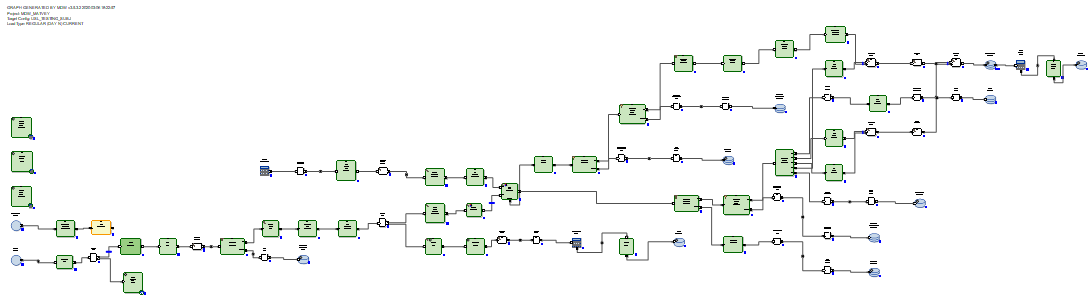
O delta recebido é carregado em uma tabela intermediária no banco de dados. Depois disso, o delta é conectado aos dados que estavam na tabela antes da atualização. E isso é feito por meio do SQL através da consulta SQL gerada. Em seguida, usando os comandos delete + insert SQL, novos dados do delta são inseridos na tabela de destino e os períodos de relevância dos dados são fechados, de acordo com as chaves primárias das quais o delta foi recebido.
Não há necessidade de reescrever dados inalterados.
Assim, chegamos à conclusão de que, no caso do Hive, o MDW deve reescrever a tabela inteira, porque o Hive não possui uma função de atualização. E nada melhor do que uma reescrita completa dos dados durante a atualização não é inventada. No caso do RDBMS, pelo contrário, os criadores do produto consideraram necessário confiar na conexão e atualização de tabelas usando SQL.
Para um projeto no Sberbank, criamos uma nova implementação reutilizável do carregador de banco de dados GreenPlum. Isso foi feito com base na versão que o MDW gera para o Teradata. Foi a Teradata, não a Oracle, que surgiu melhor e mais próxima disso. também é um sistema MPP. A maneira de trabalhar, bem como a sintaxe do Teradata e do GreenPlum, foram semelhantes.
Exemplos de diferenças críticas para o MDW entre diferentes RDBMS são os seguintes. No GreenPlum, diferentemente do Teradata, ao criar tabelas, você precisa escrever uma cláusula
distributed byGravações Teradata
delete <table> alle no GreenePlum eles escrevem
delete from <table>Oracle grava para fins de otimização
delete from t where rowid in (< t >)e Teradata e GreenPlum escrevem
delete from t where exists (select * from delta where delta.pk=t.pk)Também observamos que, para o Ab Initio funcionar com o GreenPlum, era necessário instalar o cliente GreenPlum em todos os nós do cluster do Ab Initio. Isso ocorre porque nos conectamos ao GreenPlum simultaneamente a partir de todos os nós em nosso cluster. E para que a leitura do GreenPlum seja paralela e cada encadeamento paralelo do Ab Initio leia sua própria parte dos dados do GreenPlum, foi necessário colocar uma construção entendida pelo Ab Initio na seção "where" das consultas SQL
where ABLOCAL()e determine o valor dessa construção especificando a leitura de parâmetros no banco de dados de transformação
ablocal_expr=«string_concat("mod(t.", string_filter_out("{$TABLE_KEY}","{}"), ",", (decimal(3))(number_of_partitions()),")=", (decimal(3))(this_partition()))»que compila para algo como
mod(sk,10)=3, ou seja, você precisa informar ao GreenPlum um filtro explícito para cada partição. Para outros bancos de dados (Teradata, Oracle), o Ab Initio pode fazer essa paralelização automaticamente.
Características comparativas de desempenho do Ab Initio para trabalhar com Hive e GreenPlum
Foi realizado um experimento no Sberbank para comparar o desempenho dos gráficos gerados pelo MDW em relação ao Hive e em relação ao GreenPlum. Como parte do experimento, no caso do Hive, havia 5 nós no mesmo cluster que o Ab Initio e, no caso do GreenPlum, havia 4 nós em um cluster separado. Essa. A Hive tinha alguma vantagem de hardware sobre o GreenPlum.
Analisamos dois pares de gráficos que executam a mesma tarefa de atualizar dados no Hive e no GreenPlum. Os gráficos gerados pelo configurador MDW foram lançados:
- carregamento de inicialização + carregamento incremental de dados gerados aleatoriamente na tabela Hive
- carga inicializada + carga incremental de dados gerados aleatoriamente na mesma tabela GreenPlum
Nos dois casos (Hive e GreenPlum) lançaram downloads em 10 threads paralelos no mesmo cluster Ab Initio. O Ab Initio salvou dados intermediários para cálculos no HDFS (em termos de Ab Initio, o layout do MFS usando o HDFS foi usado). Uma linha de dados gerados aleatoriamente ocupava 200 bytes nos dois casos.
O resultado é o seguinte:
Hive:
| Inicializando o carregamento no Hive | |||
| Linhas inseridas | 6.000.000 | 60.000.000 | 600.000.000 |
| Duração da
carga de inicialização em segundos |
41. | 203 | 1 601 |
| Carregamento incremental no Hive | |||
| O número de linhas na
tabela de destino no início do experimento |
6.000.000 | 60.000.000 | 600.000.000 |
| Número de linhas delta aplicadas à
tabela de destino durante o experimento |
6.000.000 | 6.000.000 | 6.000.000 |
| Duração incremental do
download em segundos |
88 | 299 | 2541 |
GreenPlum:
| GreenPlum | |||
| 6 000 000 | 60 000 000 | 600 000 000 | |
|
|
72 | 360 | 3 631 |
| GreenPlum | |||
| ,
|
6 000 000 | 60 000 000 | 600 000 000 |
| ,
|
6 000 000 | 6 000 000 | 6 000 000 |
|
|
159 | 199 | 321 |
Vemos que a velocidade de inicialização do carregamento no Hive e no GreenPlum linearmente depende da quantidade de dados e, por razões de melhor hardware, é um pouco mais rápido para o Hive do que para o GreenPlum.
O carregamento incremental no Hive também depende linearmente da quantidade de dados carregados anteriormente na tabela de destino e é bastante lento à medida que a quantidade aumenta. Isso ocorre devido à necessidade de sobrescrever completamente a tabela de destino. Isso significa que aplicar pequenas alterações em tabelas enormes não é um bom caso de uso para o Hive.
O carregamento incremental no GreenPlum depende pouco da quantidade de dados carregados anteriormente disponíveis na tabela de destino e é bastante rápido. Isso aconteceu graças ao SQL Joins e à arquitetura GreenPlum, que permite a operação de exclusão.
Portanto, o GreenPlum injeta o delta usando o método delete + insert, enquanto o Hive não possui operações de exclusão ou atualização; portanto, toda a matriz de dados teve que ser reescrita inteiramente durante uma atualização incremental. O mais indicativo é a comparação das células destacadas em negrito, pois corresponde à variante mais frequente da operação de downloads com uso intensivo de recursos. Vemos que o GreenPlum ganhou 8 vezes sobre o Hive neste teste.
Ab Initio com GreenPlum em quase tempo real
Nesta experiência, testaremos a capacidade do Ab Initio de atualizar a tabela GreenPlum com blocos de dados gerados aleatoriamente quase em tempo real. Considere a tabela GreenPlum dev42_1_db_usl.TESTING_SUBJ_org_finval, com a qual trabalharemos.
Usaremos três gráficos Ab Initio para trabalhar com ele:
1) Gráfico Create_test_data.mp - cria arquivos com dados no HDFS para 6.000.000 de linhas em 10 fluxos paralelos. Os dados são aleatórios, sua estrutura é organizada para inserção em nossa tabela
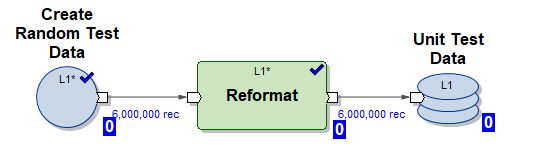

2) Gráfico mdw_load.day_one.current.dev42_1_db_usl_testing_subj_org_finval.pset - gráfico MDW gerado para inicializar a inserção de dados em nossa tabela em 10 threads paralelos (dados de teste gerados pelo gráfico (1) são usados)

3) Gráfico mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset - gráfico MDW gerado para atualização incremental de nossa tabela em 10 encadeamentos paralelos usando uma parte dos dados de entrada novos (delta) gerados pelo gráfico (1)

Execute o seguinte script no modo NRT:
- gerar 6.000.000 de linhas de teste
- inicialize a carga, insira 6.000.000 de linhas de teste na tabela vazia
- repita o download incremental 5 vezes
- gerar 6.000.000 de linhas de teste
- faça uma inserção incremental de 6.000.000 de linhas de teste na tabela (nesse caso, os dados antigos são carimbados com o tempo de expiração valid_to_ts e dados mais recentes com a mesma chave primária)
Esse cenário emula o modo de operação real de um determinado sistema de negócios - uma porção bastante grande de novos dados aparece em tempo real e entra imediatamente no GreenPlum.
Agora, vamos ver o log do script:
Inicie Create_test_data.input.pset em 2020-06-04
11:49:11 Conclua Create_test_data.input.pset em 2020-06-04 11:49:37
Inicie mdw_load.day_one.current.dev42_1_db_usl_testing_subj_org_finval.pset em 2020-06-04 11:49:37
Concluir mdw_load.day_one.current.dev42_1_db_usl_testing_subj_org_finval.pset em 2020-06-04 11:50:42
Iniciar Create_test_data.input.pset em 2020-06-04 11:50:42
Concluir Create_test_data.input.pset em 2020-06-04 11:51:06
Inicie mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset em 2020-06-04 11:51:06
Finish mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset at 2020-06-04 11:53:41
Start Create_test_data.input.pset at 2020-06-04 11:53:41
Finish Create_test_data.input.pset at 2020-06-04 11:54:04
Start mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset at 2020-06-04 11:54:04
Finish mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset at 2020-06-04 11:56:51
Start Create_test_data.input.pset at 2020-06-04 11:56:51
Finish Create_test_data.input.pset at 2020-06-04 11:57:14
Start mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset at 2020-06-04 11:57:14
Finish mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset at 2020-06-04 11:59:55
Iniciar Create_test_data.input.pset em 2020-06-04 11:59:55
Concluir Create_test_data.input.pset em 2020-06-04 12:00:23
Iniciar mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset em 2020-06-04 12:00:23
Conclua mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset em 2020-06-04 12:03:23
Inicie o Create_test_data.input.pset em 2020-06-04 12:03:23
Conclua Create_test_data.input.pset em 2020-06-04 12:03:49
Iniciar mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset em 2020-06-04 12:03:49
Concluir mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset em 2020-06-04 12:03:49 : 46 A
imagem fica assim:
| Gráfico | Hora de início | Hora de término | comprimento |
|---|---|---|---|
| Create_test_data.input.pset | 06/04/2020 11:49:11 | 06/04/2020 11:49:37 | 00:00:26 |
| mdw_load.day_one.current.
dev42_1_db_usl_testing_subj_org_finval.pset |
06/04/2020 11:49:37 | 06/04/2020 11:50:42 | 00:01:05 |
| Create_test_data.input.pset | 06/04/2020 11:50:42 | 06/04/2020 11:51:06 | 00:00:24 |
| mdw_load.regular.current.
dev42_1_db_usl_testing_subj_org_finval.pset |
06/04/2020 11:51:06 | 06/04/2020 11:53:41 | 00:02:35 |
| Create_test_data.input.pset | 06/04/2020 11:53:41 | 06/04/2020 11:54:04 | 00:00:23 |
| mdw_load.regular.current.
dev42_1_db_usl_testing_subj_org_finval.pset |
06/04/2020 11:54:04 | 06/04/2020 11:56:51 | 00:02:47 |
| Create_test_data.input.pset | 06/04/2020 11:56:51 | 06/04/2020 11:57:14 | 00:00:23 |
| mdw_load.regular.current.
dev42_1_db_usl_testing_subj_org_finval.pset |
06/04/2020 11:57:14 | 06/04/2020 11:59:55 | 00:02:41 |
| Create_test_data.input.pset | 06/04/2020 11:59:55 | 06/04/2020 12:00:23 | 00:00:28 |
| mdw_load.regular.current.
dev42_1_db_usl_testing_subj_org_finval.pset |
06/04/2020 12:00:23 | 06/04/2020 12:03:23 PM | 00:03:00 |
| Create_test_data.input.pset | 06/04/2020 12:03:23 PM | 06/04/2020 12:03:49 PM | 00:00:26 |
| mdw_load.regular.current.
dev42_1_db_usl_testing_subj_org_finval.pset |
06/04/2020 12:03:49 PM | 06/04/2020 12:06:46 PM | 00:02:57 |
Vemos que 6.000.000 de linhas de incremento são processadas em 3 minutos, o que é bastante rápido.
Os dados na tabela de destino foram distribuídos da seguinte maneira:
select valid_from_ts, valid_to_ts, count(1), min(sk), max(sk) from dev42_1_db_usl.TESTING_SUBJ_org_finval group by valid_from_ts, valid_to_ts order by 1,2;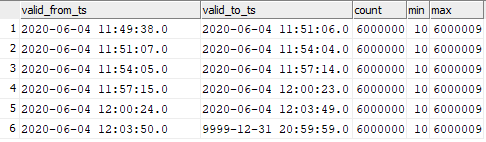
Você pode ver a correspondência dos dados inseridos nos momentos do lançamento do gráfico.
Isso significa que você pode iniciar o carregamento incremental de dados no GreenPlum no Ab Initio com uma frequência muito alta e observar uma alta velocidade de inserção desses dados no GreenPlum. Obviamente, não será possível iniciar uma vez por segundo, pois o Ab Initio, como qualquer ferramenta ETL, leva tempo para "girar" na inicialização.
Conclusão
Agora o Ab Initio é usado no Sberbank para criar a ESS (Unified Semantic Data Layer). Este projeto envolve a construção de uma única versão do estado de várias entidades comerciais bancárias. As informações são provenientes de várias fontes, das quais réplicas são preparadas no Hadoop. Com base nas necessidades dos negócios, um modelo de dados é preparado e as transformações de dados são descritas. O Ab Initio carrega informações para o ECC e os dados carregados não são apenas do interesse dos negócios em si, mas também servem como uma fonte para a construção de data marts. Ao mesmo tempo, a funcionalidade do produto permite o uso de vários sistemas (Hive, Greenplum, Teradata, Oracle) como um receptor, o que possibilita a preparação fácil de dados para os negócios nos vários formatos necessários.
Os recursos da Ab Initio são amplos, por exemplo, a estrutura MDW incluída possibilita a criação de dados históricos técnicos e de negócios prontos para uso. Para os desenvolvedores, o Ab Initio oferece a oportunidade de “não reinventar a roda”, mas usar muitos dos componentes funcionais disponíveis, que são, de fato, bibliotecas necessárias ao trabalhar com dados.
O autor é um especialista da comunidade profissional Sberbank SberProfi DWH / BigData. A comunidade profissional SberProfi DWH / BigData é responsável pelo desenvolvimento de competências em áreas como o ecossistema Hadoop, Teradata, Oracle DB, GreenPlum, além das ferramentas de BI Qlik, SAP BO, Tableau, etc.