As cachoeiras são impressionantes por sua própria natureza, por isso não é surpresa que os engenheiros estejam um pouco obcecados por elas. O antigo padrão DOD-STD-2167A recomendava o uso do modelo em cascata, e minha formação em engenharia herdada foi baseada no modelo Phase-Gate , que na minha opinião é bastante semelhante ao modelo em cascata. Por outro lado, aqueles que estudaram ciência da computação na universidade provavelmente sabem que o modelo em cascata é de alguma forma um antipadrão . Nossos amigos na torre acadêmica de marfim nos dizem que não, não, AgileÉ o caminho para o sucesso e parece que a indústria provou que essa afirmação é verdadeira.
Então, o que um desenvolvedor deve escolher entre o modelo em cascata antigo e o novo Agile? A equação muda quando se trata de desenvolver algoritmos? Ou algum software crítico de segurança?
Como sempre na vida, a resposta está em algum lugar no meio.
Híbrido, espiral e padrão V
Desenvolvimento híbrido é a resposta que fica no meio. Onde o modelo em cascata não permite voltar atrás e alterar os requisitos, o modelo híbrido permite. E onde o Agile tem problemas com o design inicial, o desenvolvimento híbrido deixa espaço para isso. Além disso, o desenvolvimento híbrido visa reduzir o número de defeitos no produto final, o que provavelmente queremos quando projetamos algoritmos para aplicativos críticos de segurança.
Parece bom, mas quão eficaz é?
Para responder a essa pergunta, apostamos no desenvolvimento híbrido enquanto trabalhamos no algoritmo de localização NDT.. A localização é uma parte essencial de qualquer pilha autônoma que vai além do controle reativo puro. Se você não acredita em mim ou não está familiarizado com a localização, recomendo que você dê uma olhada em alguns dos documentos de design que foram desenvolvidos por esse processo.
Então, o que é desenvolvimento híbrido em poucas palavras? Do meu ponto de vista amador, eu diria que este é um modelo ideal em forma de V , ou espiral . Você planeja, projeta, implementa e testa e, em seguida, repete todo o processo com base nas lições aprendidas e no novo conhecimento adquirido durante esse período.
Uso pratico
Mais especificamente, nós, com o grupo de trabalho NDT da Autoware.Auto, concluímos nossa primeira descida pela cascata esquerda do modelo V (ou seja, fizemos a primeira iteração na fase de design) em preparação para o Autoware Hackathon em Londres (administrado pela Parkopedia !). Nossa primeira passagem pela fase de design consistiu nas seguintes etapas:
- Revisão da literatura
- Visão geral das implementações existentes
- Projetando componentes de alto nível, casos de uso e requisitos
- Análise de falhas
- Definição de métricas
- Arquitetura e design da API
Você pode dar uma olhada em cada um dos documentos resultantes, se estiver interessado em algo semelhante, mas no restante deste post, tentarei detalhar alguns deles e também explicar o que e o porquê disso em cada um desses estágios.
Revisão da literatura e implementações existentes
O primeiro passo em qualquer empreendimento decente (que é como eu classificaria uma implementação NDT) é ver o que outras pessoas fizeram. Afinal, os seres humanos são seres sociais, e todas as nossas realizações estão sobre os ombros dos gigantes.
Além de alusões, há duas áreas importantes a considerar ao considerar a “arte do passado”: literatura acadêmica e realizações funcionais.
É sempre útil olhar para o que os pobres alunos de pós-graduação estavam trabalhando no meio da fome. Na melhor das hipóteses, você descobrirá que existe um algoritmo perfeitamente excelente que você pode implementar em vez do seu. Na pior das hipóteses, você entenderá o espaço e a variação das soluções (o que pode ajudar a arquitetura da informação) e também poderá aprender sobre alguns dos fundamentos teóricos do algoritmo (e, portanto, quais invariantes você deve observar ).
Por outro lado, é igualmente útil analisar o que as outras pessoas estão fazendo - afinal, é sempre mais fácil começar a fazer algo com um prompt de início. Não apenas você pode emprestar boas idéias de arquitetura de graça, mas também pode descobrir algumas das suposições e truques sujos que podem ser necessários para que o algoritmo funcione na prática (e você pode até integrá-los totalmente à sua arquitetura).
De nossa revisão da literatura sobre NDT , reunimos as seguintes informações úteis:
- A família de algoritmos NDT possui várias variações:
- P2D
- D2D
- Limitado
- Semântica - Existem vários truques sujos que podem ser usados para melhorar o desempenho do algoritmo.
- O NDT é geralmente comparado ao ICP
- O NDT é um pouco mais rápido e um pouco mais confiável.
- O NDT opera de forma confiável (tem uma alta taxa de sucesso) dentro de uma área definida
Nada incrível, mas essas informações podem ser salvas para uso posterior, tanto no design quanto na implementação.
Da mesma forma, de nossa visão geral das implementações existentes, vimos não apenas etapas concretas, mas também algumas estratégias interessantes de inicialização.
Casos de uso, requisitos e mecanismos
Uma parte integrante de qualquer processo de desenvolvimento de design ou planejamento é abordar o problema que você está tentando resolver em alto nível. Em um sentido amplo, do ponto de vista da segurança funcional (que, confesso, estou longe de ser um especialista), a "visão de alto nível do problema" é organizada aproximadamente da seguinte maneira:
- Quais casos de uso você está tentando resolver?
- Quais são os requisitos (ou limitações) de uma solução para satisfazer os casos de uso acima?
- Quais mecanismos atendem aos requisitos acima?
O processo descrito acima fornece uma visão disciplinada de alto nível do problema e gradualmente se torna mais detalhado.
Para ter uma idéia de como isso pode ser, dê uma olhada no documento do projeto de localização de alto nível que reunimos em preparação para o desenvolvimento da NDT. Se você não estiver com disposição para ler antes de dormir, continue lendo.
Casos de uso
Gosto de três abordagens pensadas para casos de uso (atenção, não sou especialista em segurança funcional):
- O que o componente deve fazer? (lembre-se do SOTIF !)
- Quais são as maneiras pelas quais posso inserir entradas em um componente? (casos de uso de entrada, eu gostaria de chamá-los a montante)
- Quais são as maneiras de obter a saída? (casos de uso de fim de semana ou de cima para baixo)
- Pergunta bônus: Em que arquiteturas de sistema inteiro esse componente pode residir?
Juntando tudo, criamos o seguinte:
- A maioria dos algoritmos pode usar localização, mas no final pode ser dividida em tipos que funcionam localmente e globalmente.
- Os algoritmos locais precisam de continuidade em seu histórico de transformações.
- Quase qualquer sensor pode ser usado como fonte de dados de localização.
- Precisamos de uma maneira de inicializar e solucionar problemas de nossos métodos de localização.
Além dos vários casos de uso em que você pode pensar, também gosto de pensar em alguns casos de uso comuns que são muito rigorosos. Para fazer isso, tenho a opção (ou tarefa) de uma viagem off-road completamente não tripulada, passando por vários túneis com tráfego em uma caravana. Existem alguns aborrecimentos nesse caso de uso, como acúmulo de erros de odometria, erros de ponto flutuante, correções de localização e interrupções.
Exigências
O objetivo de desenvolver casos de uso, além de generalizar qualquer problema que você está tentando resolver, é definir requisitos. Para que um caso de uso ocorra (ou seja satisfeito), provavelmente existem alguns fatores que devem ser realizados ou possíveis. Em outras palavras, cada caso de uso possui um conjunto específico de requisitos.
No final, os requisitos gerais para um sistema de localização não são tão assustadores:
- Fornecer transformações para algoritmos locais
- Fornecer transformações para algoritmos globais
- Forneça o mecanismo para a inicialização de algoritmos de localização relativa
- Garanta que as conversões não se espalhem
- Garanta a conformidade com o REP105
Os especialistas qualificados em segurança funcional provavelmente formularão muitos outros requisitos. O valor deste trabalho reside no fato de formularmos claramente certos requisitos (ou restrições) para o nosso design, que, como mecanismos, satisfarão nossos requisitos para a operação do algoritmo.
Mecanismos
O resultado final de qualquer tipo de análise deve ser um conjunto prático de lições ou materiais. Se, como resultado da análise, não podemos usar o resultado (mesmo que negativo!), A análise foi desperdiçada.
No caso de um documento de engenharia de alto nível, estamos falando de um conjunto de mecanismos ou de uma construção que encapsula esses mecanismos, que podem se adequar adequadamente aos nossos casos de uso.
Esse design específico de localização de alto nível permitiu o conjunto de componentes, interfaces e comportamentos de software que compõem a arquitetura do sistema de localização. Um diagrama de blocos simples da arquitetura proposta é mostrado abaixo.
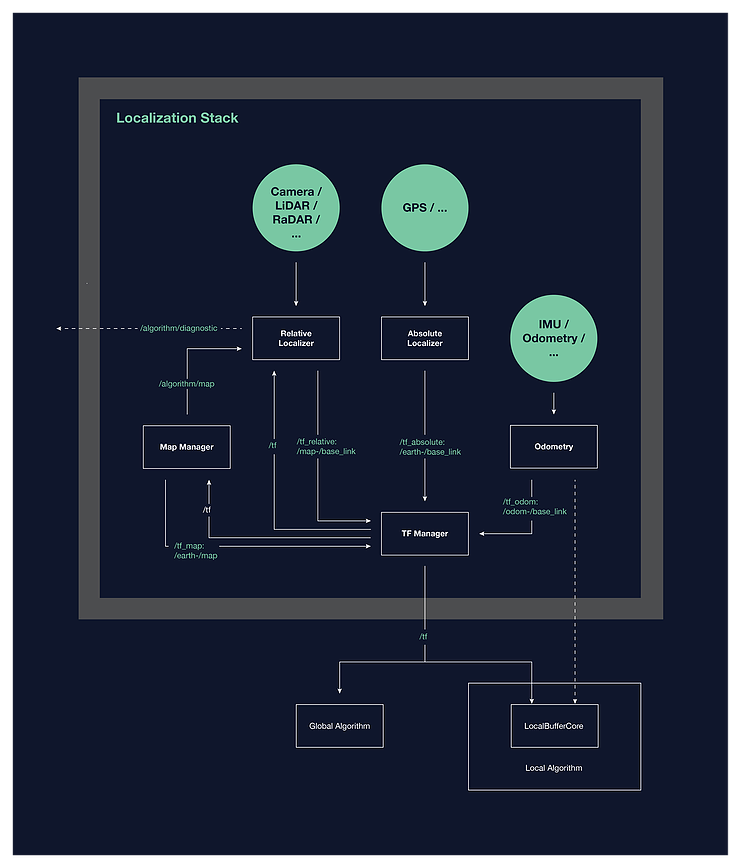
Se você estiver interessado em mais informações sobre arquitetura ou design, recomendo que você leiao texto completo do documento .
Análise de falhas
Como estamos construindo componentes em sistemas críticos de segurança, as falhas são algo que devemos tentar evitar ou pelo menos mitigar. Portanto, antes de tentarmos projetar ou construir qualquer coisa, devemos pelo menos estar cientes de como as coisas podem quebrar.
Ao analisar falhas, como na maioria dos casos, é útil observar um componente de vários ângulos. Para analisar as falhas do algoritmo NDT, o consideramos de duas maneiras diferentes: como um mecanismo de localização geral (relativo) e, especificamente, como uma instância do algoritmo NDT.
Quando visto do ponto de vista do mecanismo de localização, o principal modo de falha é formulado da seguinte maneira - "o que fazer se a entrada estiver com dados incorretos?" De fato, do ponto de vista de um componente individual, pouco pode ser feito, exceto para realizar uma verificação básica da adequação do sistema. No nível do sistema, você tem opções adicionais (por exemplo, habilitando recursos de segurança).
Considerando o NDT como um algoritmo isolado, é útil abstrair do algoritmo destacando o número apropriado de aspectos. Será útil prestar atenção à versão em pseudocódigo do algoritmo (isso ajudará você, o desenvolvedor, a entender melhor o algoritmo). Nesse caso, analisamos o algoritmo em detalhes e estudamos todas as situações em que ele pode quebrar.
Um erro de implementação é uma falha perfeitamente razoável, embora possa ser corrigido com o teste apropriado. Algumas nuances sobre algoritmos numéricos começaram a aparecer um pouco mais frequentemente e com mais insidiosidade. Em particular, estamos falando sobre encontrar matrizes inversas ou, mais geralmente, resolver sistemas de equações lineares, o que pode levar a erros numéricos. Este é um cenário de falha muito sensível e deve ser tratado.
Outras duas falhas importantes que também identificamos são verificar se certas expressões não são ilimitadas em magnitude (controle de precisão de ponto flutuante) e verificar se a magnitude ou tamanho das entradas é constantemente monitorado.
No total, desenvolvemos 15 recomendações. Eu recomendaria que você se familiarizasse com eles.
Acrescentarei também que, embora não tenhamos usado esse método, a análise da árvore de falhas é uma excelente ferramenta para estruturar e quantificar o problema da análise de falhas.
Definição de métricas
"O que é medido é administrável"Infelizmente, no desenvolvimento profissional, não basta dar de ombros e dizer "pronto" quando você está cansado de trabalhar em alguma coisa. Basicamente, qualquer pacote de trabalho (que, novamente, é um desenvolvimento NDT) requer critérios de aceitação que devem ser acordados pelo cliente e pelo fornecedor (se você é o cliente e o vendedor, pule esta etapa). Toda a jurisprudência existe para apoiar esses aspectos, mas como engenheiros, podemos simplesmente eliminar os intermediários criando métricas para determinar a disponibilidade de nossos componentes. Afinal, os números são (principalmente) inequívocos e irrefutáveis.
- Frase popular de gerentes
Mesmo que os critérios de aceitação sejam desnecessários ou irrelevantes, ainda é bom ter um conjunto de métricas bem definido que caracterize e melhore a qualidade e o desempenho de um projeto. No final, o que está sendo medido é controlável.
Para nossa implementação de NDT, dividimos as métricas em quatro grandes grupos:
- Métricas gerais de qualidade de software
- Métricas comuns de qualidade de firmware
- Métricas gerais do algoritmo
- Métricas específicas da localização
Não entrarei em detalhes porque essas métricas são todas relativamente padrão. O importante é que as métricas tenham sido definidas e identificadas para o nosso problema específico, que é aproximadamente o que podemos alcançar como desenvolvedores de um projeto de código aberto. Por fim, a barra de aceitação deve ser determinada com base nas especificidades do projeto por aqueles que estão implantando o sistema.
A última coisa que repetirei aqui é que, embora as métricas sejam fantásticas para testar, elas não substituem a verificação do entendimento da implementação e dos requisitos de uso.
Arquitetura e API
Depois de definir meticulosamente o problema que estamos tentando resolver e construir uma compreensão do espaço da solução, podemos finalmente mergulhar na área que limita a implementação.
Ultimamente, sou fã de desenvolvimento orientado a testes . Como a maioria dos engenheiros, eu amo o processo de desenvolvimento, e a ideia de escrever testes me pareceu complicada. Quando comecei a programar profissionalmente, fui em frente e fiz testes após o desenvolvimento (mesmo que meus professores da universidade me dissessem para fazer o oposto). Pesquisamostre que escrever testes antes da implementação tende a resultar em menos bugs, maior cobertura de teste e código geralmente melhor. Talvez o mais importante seja que acredito que o desenvolvimento orientado a testes ajude a resolver o grande problema da implementação de algoritmos.
Com o que se parece?
Em vez de introduzir um ticket monolítico chamado "Implementar NDT" (incluindo testes), que resultará em vários milhares de linhas de código (que não podem ser efetivamente visualizadas e estudadas), você pode dividir o problema em fragmentos mais significativos:
- Escreva classes e métodos públicos para um algoritmo (crie uma arquitetura)
- Escreva testes para o algoritmo usando a API pública (eles devem falhar!).
- Implementar a lógica do algoritmo
Portanto, o primeiro passo é escrever a arquitetura e a API do algoritmo. Vou cobrir os outros passos em outro post.
Embora existam muitos trabalhos que falam sobre como "criar arquitetura", parece-me que projetar arquitetura de software tem algo a ver com magia negra. Pessoalmente, eu gosto de pensar em arquitetura de software como traçar limites entre conceitos e tentar caracterizar os graus de liberdade ao colocar um problema e como resolvê-lo em termos de conceitos.
Quais são, então, os graus de liberdade no END?
Uma revisão da literatura nos diz que existem diferentes maneiras de apresentar varreduras e observações (por exemplo, P2D-NDT e D2D-NDT). Da mesma forma, nosso artigo de engenharia de alto nível diz que temos várias maneiras de representar o mapa (estático e dinâmico), portanto, esse também é um grau de liberdade. A literatura mais recente também sugere que o problema de otimização pode ser revisado. No entanto, comparando a implementação prática e a literatura, vemos que mesmo os detalhes da solução de otimização podem ser diferentes.
E a lista continua.
Com base nos resultados do design inicial, estabelecemos os seguintes conceitos:
- Problemas de otimização
- Soluções de otimização
- Visualização de digitalização
- Visão do mapa
- Sistemas iniciais de geração de hipóteses
- Interfaces de algoritmo e nó
Com alguma subdivisão dentro desses itens.
A expectativa final de uma arquitetura é que ela seja extensível e sustentável. Se nossa arquitetura proposta atende a essa esperança, apenas o tempo dirá.
Mais distante
Após o design, é claro, é hora de implementar. O trabalho oficial sobre a implementação do NDT no Autoware.Auto foi realizado no hackathon Autoware, organizado pela Parkopedia .
Deve-se reiterar que o que foi apresentado neste texto é apenas a primeira passagem na fase de projeto. Conhecidoque nenhum plano de batalha aguenta enfrentar o inimigo, e o mesmo pode ser dito para o design de software. A falha final do modelo em cascata foi realizada no pressuposto de que a especificação e o design eram perfeitos. Escusado será dizer que nem a especificação nem o design são perfeitos, e à medida que a implementação e o teste progridem, serão descobertas falhas e serão necessárias alterações nos designs e documentos descritos aqui.
E tudo bem. Nós, como engenheiros, não somos nosso trabalho ou nos identificamos com ele, e tudo o que podemos tentar fazer é iterar e lutar por sistemas perfeitos. Depois de tudo o que foi dito sobre o desenvolvimento do NDT, acho que demos um bom primeiro passo.
Inscreva-se nos canais:
@TeslaHackers — Tesla-, Tesla
@AutomotiveRu — ,

: