A nota descreve um experimento para criar uma cópia pequena de uma empresa altamente técnica de data warehouse. Ou seja, com base em um computador de placa única Raspberry Pi.
O modelo e a arquitetura serão simplificados, mas semelhantes ao armazenamento corporativo. O resultado é uma avaliação da possibilidade de usar o Raspberry Pi no campo de processamento e análise de dados.

# 1
O papel de um participante experiente e forte será desempenhado pela máquina Exadata X5 (uma unidade) da Oracle Corporation.
O processo de processamento de dados inclui as seguintes etapas:
- Leitura de um arquivo de 10,3 GB - 350 milhões de registros em 90 minutos.
- Processamento e limpeza de dados - 2 consultas SQL e 15 minutos (com criptografia de dados pessoais 180 minutos).
- Carregando medidas - 10 minutos.
- Download de tabelas de fatos com 20 milhões de novos registros - 5 consultas SQL e 35 minutos.
Integração total de 350 milhões de registros em 2,5 horas, o que equivale a 2,3 milhões de registros por minuto ou aproximadamente 39 mil registros de dados brutos por segundo.
Número 2
O oponente experimental será o Raspberry Pi 3 Modelo B + com um processador de 4 GHz e 1,4 GHz.
Sqlite3 é usado como armazenamento, os arquivos são lidos usando PHP. Os arquivos e o banco de dados estão em um cartão SD classe 10 de 32 GB em um leitor embutido. O backup é criado em uma unidade flash de 64 GB conectada ao USB.
O modelo de dados no banco de dados relacional sqlite3 e nos relatórios são descritos no artigo sobre armazenamento pequeno .
Modelo de dados
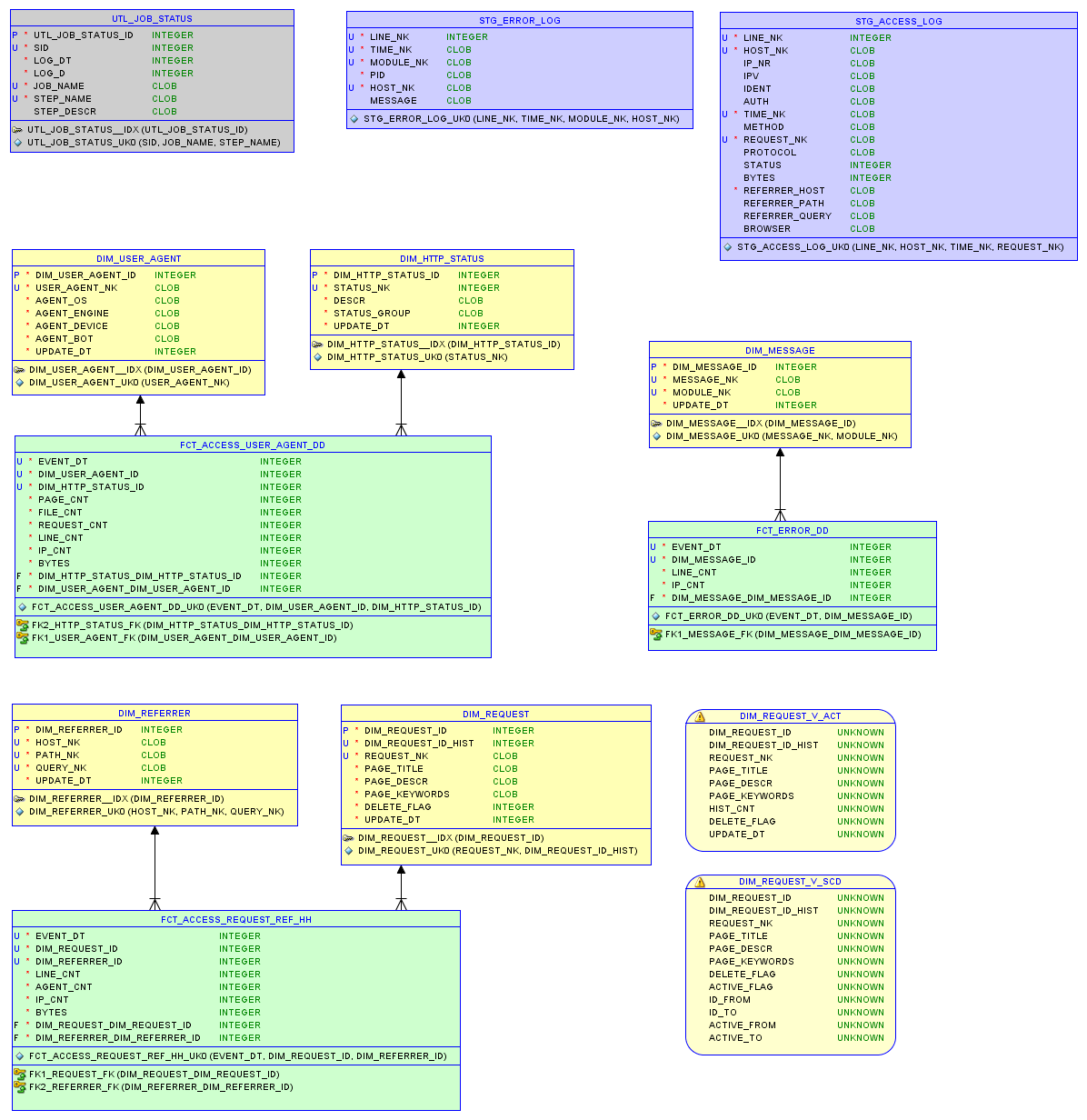
Teste um
O arquivo access.log original tem 37 MB e 200.000 entradas.
- Demorou 340 segundos para ler o log e gravar no banco de dados.
- Carregar medições com 5 mil registros levou 5 segundos.
- Carregando tabelas de fatos com 90 mil novos registros - 32 segundos.
No total , a integração de 200 mil registros levou quase 7 minutos, o que equivale a 28 mil registros por minuto ou 470 registros de dados brutos por segundo. O banco de dados ocupa 7,5 MB; Apenas 8 consultas SQL para processamento de dados.
Segundo teste
Arquivo do site mais ativo. O arquivo access.log original tem 67 MB e entradas de 290K.
- Demorou 670 segundos para ler o log e gravar no banco de dados.
- Carregar medições com 25 mil registros levou 8 segundos.
- Carregando tabelas de fatos com 240 mil novos registros - 80 segundos.
No total , a integração de 290 mil registros levou pouco mais de 12 minutos, o que equivale a 23 mil registros por minuto ou 380 registros de dados brutos por segundo. O banco de dados tem 22,9 MB
Resultado
Para obter dados na forma de um modelo que permita uma análise eficaz, são necessários recursos computacionais e materiais significativos e tempo, em qualquer caso.
Por exemplo, uma unidade Exadata custa mais de 100 mil. Um Raspberry Pi custa 60 unidades.
Eles não podem ser comparados linearmente, pois com o aumento do volume de dados e dos requisitos de confiabilidade, surgem dificuldades.
No entanto, se imaginarmos um caso em que mil Raspberry Pi funcionem em paralelo, com base no experimento, eles processarão cerca de 400 mil registros de dados brutos por segundo.
E se a solução para o Exadata for otimizada para 60 ou 100 mil registros por segundo, isso será notavelmente menor que 400 mil. Isso confirma a sensação interna de que os preços das soluções corporativas são muito altos.
De qualquer forma, o Raspberry Pi é excelente para lidar com dados e modelos relacionais na escala apropriada.
Ligação
O Raspberry Pi doméstico foi configurado como um servidor web. Vou descrever esse processo no próximo post.
Você pode experimentar o desempenho do Raspberry Pi e o arquivo access.log no endereço . O modelo de banco de dados (DDL), os procedimentos de carregamento (ETL) e o próprio banco de dados podem ser baixados a partir daí. A idéia é obter rapidamente uma idéia do estado do site a partir do log com dados das últimas semanas.
Alterações
Graças aos comentários, o erro ao carregar o arquivo Exadata foi corrigido e os números na nota foram corrigidos. Sqlloader é usado para leitura, algum bug removeu os parâmetros BINDSIZE e ROWS. Devido à inicialização instável da unidade remota, o método convencional foi escolhido em vez do caminho direto, o que poderia aumentar a velocidade em outros 30-50%.